智能制造中RFID多标签快速识别问题的研究
2019-05-08
(山东建筑大学 信息与电气工程学院,济南 250101)
0 引言
所谓RFID,指的是无线射频识别技术(Radio Frequency IDentification),它通过无线电讯号识别特定的目标对象,无需识别系统与目标对象之间有接触,即可实现两者的双向数据通信。与以往应用在工业现场的条形码识别技术相比,RFID技术不受应答对象尺寸大小和形状限制,不易被污染,适应恶劣环境的能力更强,已逐步成为工程机械智能制造领域的核心推动力[1]。
工程机械生产线依托RFID 系统,能够自动且准确地获取生产过程中有关“工序、工件、工人”的信息,实现全过程溯源,提高生产安全和质量。目前,影响工业现场RFID技术应用效果的主要问题就是多标签快速识别问题,该问题直接影响着RFID系统的工作效率,进而影响整个智能制造生产线的工程进度。
现有的RFID防碰撞算法主要分为ALOHA 算法和树形算法两类。其中ALOHA算法原理简单,容易实现,特别是其中一种动态帧时隙ALOHA算法已经具备比较高的吞吐率,但这种算法具有不可避免的随机性,存在标签饥饿现象,即总会有少量标签不能被识别[2]。这在准确性和安全性要求高的工业现场是不被允许的,因此ALOHA算法仅适用于待识别标签数目较少的情景。二进制树算法不存在随机性,解决了标签饥饿问题,但这却以系统的复杂度为代价,对系统识别总时长有显著影响,这就不符合工业现场高实时性的特点。因此二进制树类算法仅适用于待识别标签数目较多,且对识别时间要求不高的情景。查询树算法解决了标签饥饿问题的同时,系统复杂度也不高,但系统识别效率受标签ID的长度影响较为严重,可见该类算法灵活性较低,仅适用于待识别标签ID长度较短的情景[3]。
ALOHA 算法和树形算法都不可避免空时隙或空搜索的存在,造成资源浪费的同时,算法的性能和识别效率都受到很大的影响。这两类算法都无法在短时间内完成大量标签的识别,不能满足工业现场的生产要求。针对上述问题,本文提出一种更具灵活性的改进型算法,该算法建立在查询树算法的基础上,保留了查询树算法的优点的同时,对查询树算法的缺点进行了针对性改进,能够实现多标签快速识别,可运用于工程机械智能制造生产线中。
本文提出的新算法对RFID系统的软硬件没有特殊要求,尤其是不需要电子标签具有历史记录功能,只需要与阅读器传来的查询前缀进行对比,然后判断是否响应该命令即可。
1 曼彻斯特编码方式简述
本文提出的新算法中标签ID采用曼彻斯特编码(ManchesterEncoding)方式编码,也叫做相位编码方式,它是一种同步时针编码方式。该编码方式能在两个或多个标签同时响应阅读器的命令时,精确地识别出发生碰撞的数据的比特位,从而采取相应措施使发生碰撞的标签能被识别。
曼彻斯特编码方式采用半个周期的电平正负跳变来表示1和0,约定由高电平到低电平的跳变为1,由低电平到高电平跳变为0[4]。若同时响应的两个或多个标签的编号中有某一位数据是不同值,则阅读器接收到的上升沿和下降沿之间会相互抵消,呈现没有电平跳变的状态,这是不被允许的,此时阅读器就可以判定这些数据位之间发生了碰撞,如图1所示。
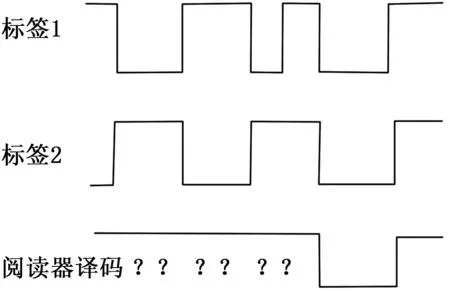
图1 曼彻斯特编码示意图
2 改进型算法过程描述
本文提出的新算法延续了查询树算法的优点,此外,针对查询树算法存在的识别效率受标签编号长度影响的问题进行了改进。即当多个标签发生碰撞时,根据首位碰撞位生成两个新的搜索前缀,而不是机械的在之前的搜索前缀后添加1或0。
该算法中,阅读器自身带有查询前缀栈prefix、数据储存栈string和分组编号栈group;标签带有寄存器count。
2.1 待识别标签分组
本算法主要是实现短时间内大量标签的识别,故为减少标签碰撞发生的可能性,提高系统的识别效率,阅读器将标签ID中数值1的总位数作为分组编号,对场内所有待识别标签进行分组识别。
首先,阅读器发送数值1的总位数请求命令Quest,场内所有标签接收到该命令后,统计自身ID中数值1的个数,将该统计值保存在标签的寄存器count中,并将该统计值编码后发送给阅读器。
为提高数据传输的稳定性,在信道中传输分组编号时不采用传统的二进制编码,而是由标签生成一个比特串,该比特串中位序号与该统计值相同的二进制数位设置为1,其余二进制数位设置为0(若标签编码不包含1,则返回全0比特串)。阅读器接收到该比特串后,还原为1的总位数,将其作为分组编号,压入分组编号栈group中。具体示例如表1所示。

表1 统计值编码示例图
2.2 搜索前缀的生成
传统的查询树算法中,当标签发生数据碰撞时,阅读器直接在之前的搜索前缀后增加一位1或者0,生成新的搜索前缀[5]。这种做法不可避免空搜索的存在,降低了系统的识别效率,同时又使算法的效率很大程度上受标签ID长度的影响。
针对上述问题,本文提出算法中采取了一种更具灵活性的搜索前缀生成方式,即根据首位碰撞位P来生成两个搜索前缀,这就很好地解决了空搜索的问题,一定程度上减少了标签ID长度对系统效率的影响。此外,当前组的待识别标签与搜索前缀匹配成功后,只将自身ID中与搜索前缀相匹配之后的数据发送给阅读器,这就减少了标签与阅读器间的数据通信量,进一步优化了算法的性能[6]。
本算法中生成搜索前缀时应考虑当前组标签进行首轮识别和非首轮识别两种情况[7]。
当前组进行首轮识别时,阅读器的搜索前缀栈中只有空字符串。阅读器接收标签的返回信号,若检测到未发生碰撞,则进入下一组标签的识别;若检测到发生碰撞,则根据首位碰撞位P生成两个新搜索前缀,两个新搜索前缀由标签ID中首位碰撞位P之前的部分与首位碰撞位P组成,且P分别赋值为0或1,阅读器将两个新搜索前缀压入查询前缀栈prefix中,开启下一轮搜索[8]。
当前组进行非首轮识别时,此时搜索前缀栈中定有非空字符串,设栈顶字符串为M。阅读器发送搜索前缀M给当前组标签,标签将自身编号中与搜索前缀M匹配成功之后的字符串发送给阅读器。阅读器接收到字符串后,若检测到没有发生碰撞,则成功识别一个标签,且该标签的ID编号由搜索前缀M与收到的字符串连接组成;若检测到发生碰撞,则根据首位碰撞位P生成两个全新的搜索前缀M1和M2,这两个新搜索前缀由之前的搜索前缀M与接收到的字符串中首位碰撞位P之前的部分以及首位碰撞位 P连接而成,且首位碰撞位P分别赋值0和1。阅读器将两个全新的搜索前缀压入查询前缀栈prefix中,开启新一轮搜索。
2.3 改进型算法步骤介绍
分组完成后,RFID系统正式进入标签识别环节。阅读器从分组编号栈group中取出栈顶元素N1,从查询前缀栈prefix中取出栈顶元素M,向场内待识别标签发送命令(N1,M)。场内所有待识别标签接收到该命令后,寄存器count中分组编号值与N1相同的标签被选中为当前组标签。该组标签中与参数M相匹配的标签响应该命令,发送自身ID编号给阅读器。若此时搜索前缀M为空字符串,当前组所有标签都会响应该命令。
阅读器收到返回的ID编号后,检测是否发生数据碰撞,如果没有发生碰撞,则成功识别一个标签,阅读器从查询前缀栈中取出栈顶元素,进行下一轮识别;如果发生碰撞,则根据首位碰撞位P生成两个新的搜索前缀M1和M2,阅读器将两个新的搜索前缀依次压入查询前缀栈prefix中。重复上述过程直到查询前缀栈为空,就可以结束当前组的识别,之后阅读器从分组编号栈group中取出栈顶元素N2,开启下一组的识别,直到group为空,则没有待识别标签,结束识别过程。以表2中6个标签为例,本文提出的改进型算法的查询树如图2所示。
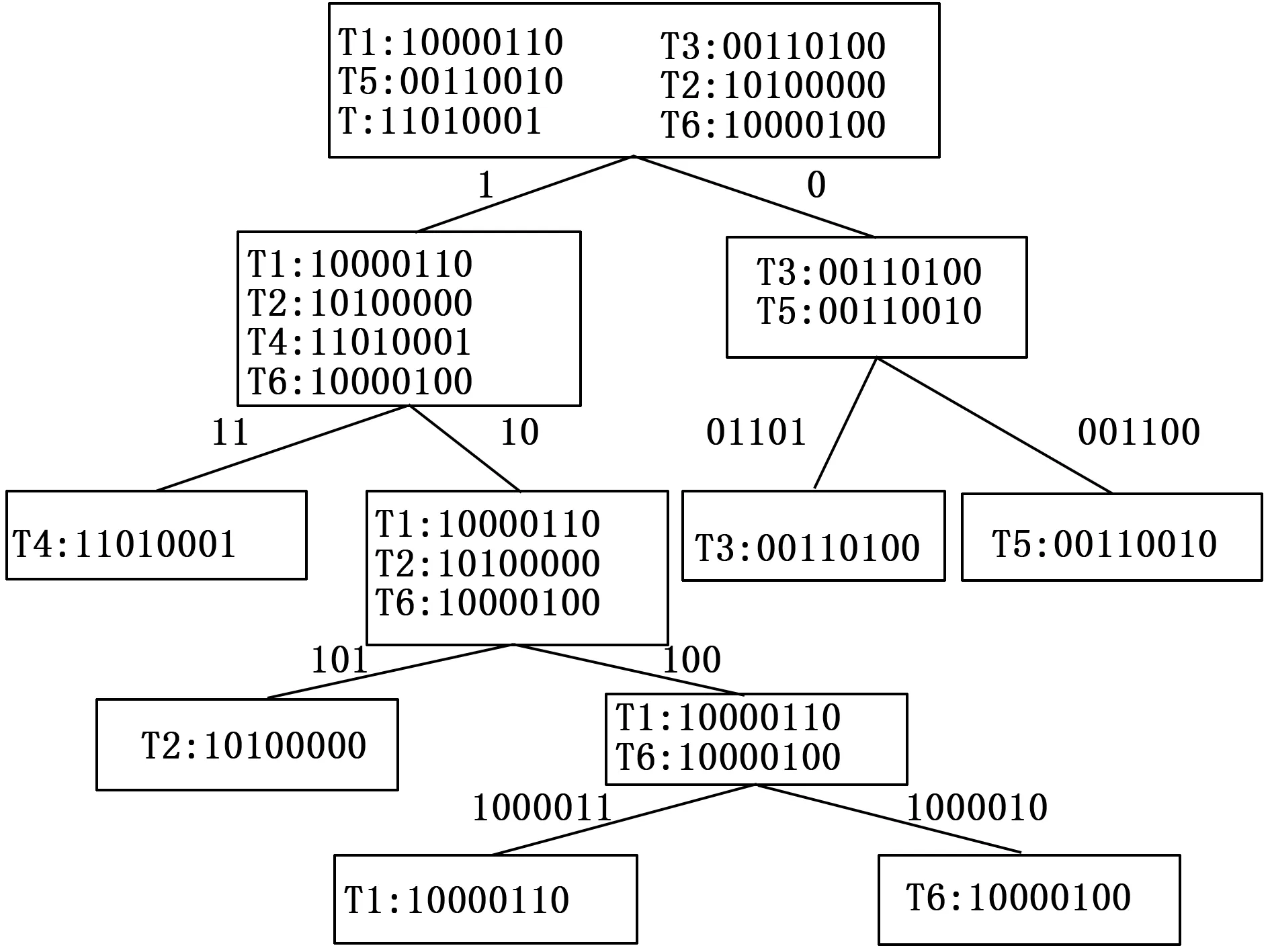
图2 改进型算法查询树示例图
由图2可以看出,本文提出的新算法可以根据首位碰撞位生成两个新的搜索前缀,相比传统查询树算法在之前的搜索前缀后直接添加1或0的做法,有效解决了空搜索的问题,提高了RFID系统的识别效率,且系统效率受标签ID长度的影响程度有所降低。
2.4 RFID防碰撞系统结构综述
本设计中,RFID防碰撞系统硬件部分主要分为电子标签和阅读器[9]。根据前文的算法介绍,本设计中阅读器硬件系统可以分为分组模块和识别模块两大部分。阅读器硬件系统结构图如图3所示。
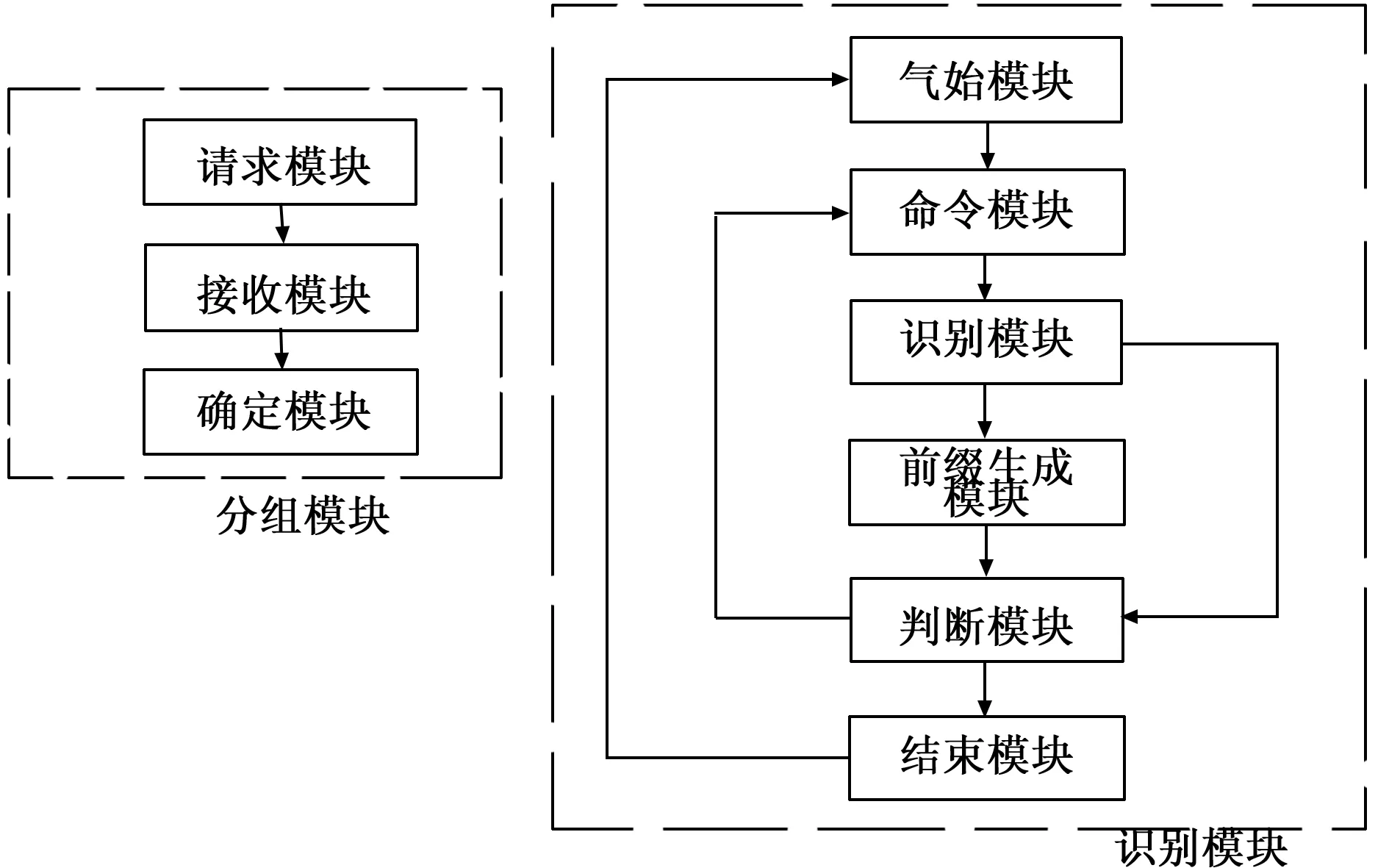
图3 阅读器硬件系统结构图
由图3可知,分组模块主要包含请求模块、接收模块和确定模块。其中,请求模块负责向场内待识别标签发送数值1 的总位数的请求命令;接收模块负责接收标签返回的数值1的统计值的比特串,将其还原回数值1的总位数,并将其储存到阅读器的分组编号栈group中;确定模块负责将分组编号相同的标签编为一组。
识别模块主要包括起始模块、命令模块、识别模块、前缀生成模块、判断模块和结束模块。其中,起始模块负责从分组编号栈group中取出栈顶元素N1;命令模块负责从查询前缀栈prefix中取出栈顶元素M,并向场内待识别标签发送命令(N1,M);识别模块负责接收响应(N1,M)命令的标签的ID,并检测是否发生碰撞;前缀生成模块负责根据首位碰撞位生成两个全新的搜索前缀;判断模块负责查看查询前缀栈prefix中是否有非空元素,若是,则进入命令模块,若否,则进入结束模块;结束模块负责查看分组编号栈group是否有非空元素,若是,则进入起始模块,若否,则标签识别全部结束[10]。
3 改进型算法仿真分析
本章利用Matlab软件对动态帧时隙ALOHA算法、二进制树算法、查询树算法以及本文提出的新算法的通信量和吞吐率进行试验仿真。
仿真实验中,标签的数目的范围取0~1000。为保证仿真试验结果的可靠性,仿真进行了100次取其平均值,结果如图4和图5所示。
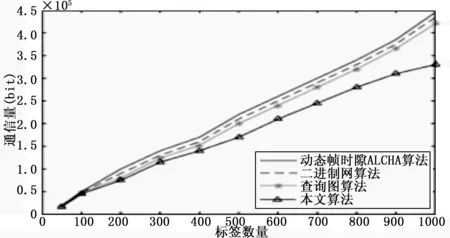
图4 标签个数为不同值时系统通信量对比
从图4可以看出,随着待识别标签数目的增加,动态帧时隙ALOHA算法、二进制树算法和查询树算法这三种算法的系统通信量呈线性增长,而本文提出的新算法的系统通信量则呈对数增长。其主要原因有两个,一是本算法中新的搜索前缀由碰撞位产生,直接减少了阅读器与标签的通信次数;二是标签ID编号与搜索前缀匹配成功后,只回传匹配成功之后的数据位,直接减少了系统通信量。
由此可见,本文提出的新算法的两点改进,有效减少了通信时间的同时,减少了系统通信量,这也是该算法能够减少标签识别总时长,实现多标签快速识别的关键因素。
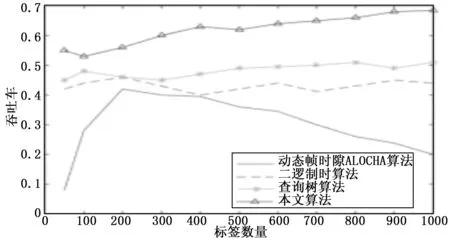
图5 标签个数为不同值时系统的吞吐率对比
由图5可以看出,本文提出的新算法的系统吞吐率明显高于其他三种算法,且当待识别标签数目增多时,其他几种算法吞吐率波动较大,而本文提出的算法性能稳定,保持在65%左右。这主要是因为本文提出的新算法有效减少了系统识别总时长,从而显著提高了系统识别吞吐率。
由仿真试验的结果图可见,本文提出的算法能有效提高系统的识别效率,节约系统的通信量,相比与现存的其他几种算法,更适合用于短时间内大量标签的识别。
4 总结
本文提出了一种新算法来实现工业现场短时间内大量标签的快速识别。该算法延续了查询树算法的优点的同时,改进了查询树算法中易出现空搜索的缺点,使新的查询前缀根据碰撞位直接生成,生成的碰撞树为满二叉树,有效避免了电子标签与阅读器之间的无效通信。此外,匹配成功的标签响应命令时,只回传自身ID中与搜索前缀相匹配之后的数据,这就减少了标签与阅读器间的数据通信量,进一步优化了算法的性能。
该算法通过以上两点改进,有效减少了RFID系统识别总时长。此外,通过对待识别标签的分组从识别初始便减少了发生标签碰撞的可能性。仿真结果表明,本文提出的新算法吞吐率高达65%,且当场内存有大量待识别标签时,通信量仅呈对数增长。可见该算法可有效运用于工程机械智能制造生产线中,实现短时间大量标签的识别。
