基于CEEMD-MPE和ELM的齿轮箱故障诊断研究*
2019-05-07崔宝珍
王 斌,崔宝珍
(中北大学 机械工程学院,太原 030051)
0 引言
由于齿轮箱结构紧凑,传动效率高等优点,使其成为运用最为广泛的传动部件,但是受到长时间恶劣环境的影响,其故障发生频率也相对较高,所以对其进行故障诊断尤为重要。传统的故障诊断方法为采集齿轮箱的振动加速度信号,提取特征值并进行诊断,但是齿轮箱的振动响应是各个频率特征信息的叠加[1],为了更好地实现故障诊断,就必须对振动信号进行分解。为此人们将经验模态分解(EMD)算法引入到齿轮箱故障诊断领域,但是EMD存在明显的模态混叠现象,为了弥补这一缺陷,又提出了总体经验模态分解(EEMD),这种算法通过在原始信号中加入白噪声,有效地避免了模态混叠问题,但是却增大了计算量,损害了原始信号的纯洁性[2]。基于此,本文提出了在经验模态分解的基础上不断完善的互补集合经验模态分解(CEEMD),此方法既继承了EMD良好的自适应性,和EEMD有效抑制模态混叠的优点,也改进了添加白噪声的形式,避免了白噪声残余的问题,使计算次数减少,提高了运算效率。
由于振动信号的复杂程度是跟随齿轮不同故障类型而发生改变,为了准确从振动信号中提取出特征,克服时间序列在多尺度的复杂性变化,提出了抗干扰能力较强的多尺度排列熵(MPE),目前以MPE作为特征已经广泛应用到机械故障诊断及生理信号识别等领域:文献[3]把MPE引入到滚动轴承故障诊断领域,并与单一尺度的排列熵进行对比;文献[4]将MPE引入到液压泵的故障诊断领域,并证明了该方法的有效性和优越性。目前,MPE应用在齿轮箱的故障诊断方面还有待研究,由此,本文将MPE应用在齿轮箱的故障诊断特征提取方面,进行研究改进。
1 基本原理介绍
1.1 CEEMD原理
EMD产生的模态混叠问题,EEMD通过引入白噪声协助分析的方式得以解决,但是这却导致处理过程复杂、计算耗时,对原始信号有一定的破坏,不能完全中和引入的白噪声等一系列问题,而CEEMD引入的是一正一负互补的噪声对,且这些噪声是独立同分布的,既有效克服了EMD的模态混叠问题,又避免了EEMD的白噪声污染,另外由于白噪声残余较少,可一定程度上提高运算效率。
CEEMD具体处理步骤如下:
(1)在待处理的信号中加入,正、负成对的白噪声。使原来要处理的一个信号变为两个;
(2)将上一步得出的两个信号依照EMD的步骤分别分解成相应的本征模态函数IMF;
(3)最后对多组IMF进行组合平均,得出结果:
(1)
式中,Cj表示分解后的第j个分量,Cij表示第i个信号的第j个分量。
为了表明CEEMD分解的优越性,构造如下仿真信号进行验证:
(2)
式中,x(t)为仿真信号,n(t)为随机噪声信号,采样频率设置为1000Hz,采样时间为1s;
针对上述仿真信号,分别进行EMD、EEMD和CEEMD处理,在同样的运算环境下记录运算时间,最终得到CEEMD和EMD的分解结果如图1所示。三种分解算法的运算时间如表1所示。

图1 CEEMD和EMD分解结果对比图

分解算法EMDCEEMDEEMD运算时间2.212s4.790s6.445s
从图1和表1中可以明显观察到,CEEMD既有效避免了EMD分解过程中出现的模态混叠问题,同时相对于EEMD分解,CEEMD处理过程较简洁,运算时间较短,提高了运算效率,综上所述,CEEMD能够有效结合EMD和EEMD的优点,更适于实际应用。
1.2 多尺度排列熵原理
排列熵可以表征时间序列的复杂性,提取排列熵作为故障特征可以分析不同工况信号的复杂性和随机性以反映信号的故障特征,并且由于计算过程简洁,使得其在设备故障诊断领域应用广泛。传统的排列熵算法仅能从单一尺度上表征故障信息,但是在对复杂机构进行故障诊断时,其振动信号往往在多重尺度上包含故障信息,传统的单一尺度排列熵,已经不能满足要求,为此文献[6]提出了多尺度排列熵算法,通俗来说,可以把多尺度排列熵看做是多重尺度下的排列熵。
多尺度排列熵的计算方式为:将长度为N的时间序列X={x1,x2,x3,···,xN}经过粗粒化后,求其排列熵。具体计算步骤如下:
(1)粗粒化处理时间序列X={x1,x2,x3,···,xN},得到:
(3)
[N/τ]为N/τ取整,τ=1,2,···为尺度因子,当尺度因子等于1时,粗粒化的时间序列仍为原始序列。
(2)对经过粗粒化处理的时间序列进行重构得到:
(4)
其中,m为嵌入维数,λ为延迟时间,l为重构分量l=1,2,···,N-(m-1)λ。
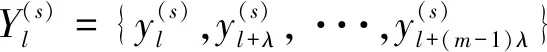
(4)计算每一种符号序列出现的概率:
(5)
将Shannon熵的形式定义不同符号序列的排列熵:
(6)

(7)
显然,0≤HP≤1,HP值越小时间序列越有序,值越大越接近随机。HP值的变化直观反映与放大时间序列的微小变化[5]。
2 齿轮箱故障方案设置
选取JZQ250减速齿轮箱作为实验对象,为了模拟齿轮箱在现实环境中的工作状态,将Y280-M4三相交流变频电机作为动力源对齿轮箱进行驱动,在齿轮箱的输出端联接磁粉离合制动器,以提供实验过程中的负载,将故障设置在中间轴,分别设置最普遍的4种工况分别是:①点蚀故障、②磨损故障、③断齿故障、④正常工况。齿轮箱故障设置如图2所示。

(a) 点蚀 (b) 磨损 (c) 断齿 图2 齿轮箱实验故障设置
在齿轮箱轴承上对应的箱盖位置对称安装6个CA-YD系列振动加速度传感器,设置采样频率为5120Hz,通过DASP数据采集系统进行数据收集,对每种工况采集20组信号储存备用,实验平台如图3所示。

图3 齿轮故障诊断实验装置
3 特征提取
针对齿轮箱振动信号存在非平稳和非线性等特点,本文将CEEMD和MPE相结合以提取齿轮箱故障特征。其具体步骤如下:
(1)将齿轮箱信号首先进行CEEMD分解;
(2)计算各分量与原始信号的相关系数,筛选出相关系数大于0.1的分量;
(3)对于筛选出的模态分量,计算其多尺度排列熵;
(4)对每个模态分量的多尺度排列熵取平均值作为特征值。
首先,以采集到的齿轮箱断齿信号为例,对其进行CEEMD分解,得到各模态分量,取前8个模态分量如图4所示。
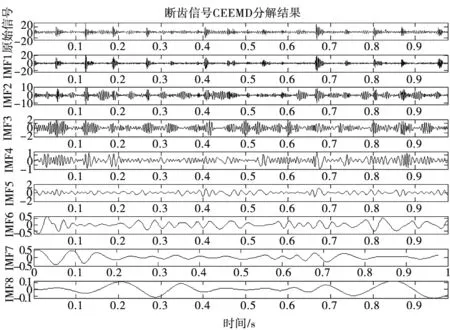
图4 齿轮箱断齿信号CEEMD分解结果
求得各模态分量与原始信号的相关系数如表2所示。

表2 各模态分量与原始信号相关系数
本文选取与原始信号相关系数大于0.1的模态分量作为参考,可以从表1中看到前4个模态分量符合要求,因此对前4个模态分量分别计算其多尺度排列熵,并取平均值,得到特征矩阵。本文共设置4种工况,每种工况采集20组样本数据,每组数据提取4个特征值,共组成80×4维特征矩阵,由于矩阵维度过大,现取部分特征值如表3所示。

表3 齿轮箱信号部分特征值
4 基于ELM的齿轮箱故障诊断
4.1 极限学习机
极限学习机器(ELM),是一种泛化的单隐层神经网络算法[7],传统的单隐层前馈神经网络(SLFN)训练效率较低,而极限学习机对输入权值和隐层阈值进行随机赋值,输出层权值则通过最小二乘法直接计算,整个学习过程一次完成,无需迭代,因而在保证学习精度的前提下,比传统的神经网络算法速度更快[8]。
ELM的网络训练模型采用前向单隐层结构。设m,M,n分别为网络输入层、隐含层和输出层的节点数,g(x)是隐层神经元的激活函数,bi为阈值[9]。设有N个不同样本(xi,ti),1≤i≤N,其中:

(8)
则ELM的网络训练模型如图5所示。

图5 ELM的网络训练模型
ELM的网络模型可用数学表达式表示如下:
(9)

4.2 故障识别
将提取出的多尺度排列熵作为齿轮箱的故障特征值组成80×4维特征矩阵,将其分成两组:随机选取其中1/2作为训练集,剩余1/2作为测试集,将训练集样本输入到极限学习机中进行训练,当训练完成之后,输入测试集样本进行齿轮箱故障诊断,并计算准确率、记录运算时间。同时为了突出极限学习机的优点,采用RBF神经网络进行齿轮箱的故障诊断[11],对比两种分类器的故障诊断准确率和运算效率。
最终,在同样的硬件平台上两种分类器的分类结果和运算效率如图6、图7和表4所示。
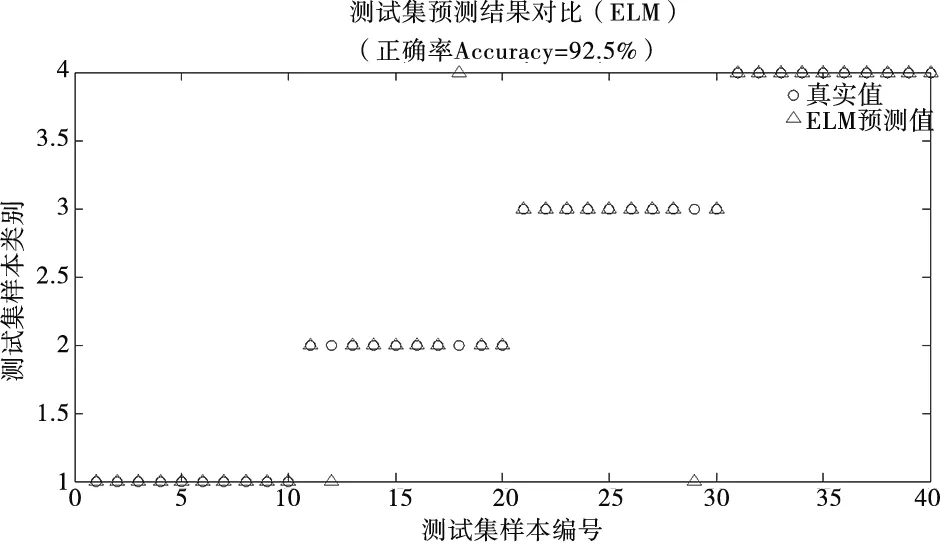
图6 ELM分类结果
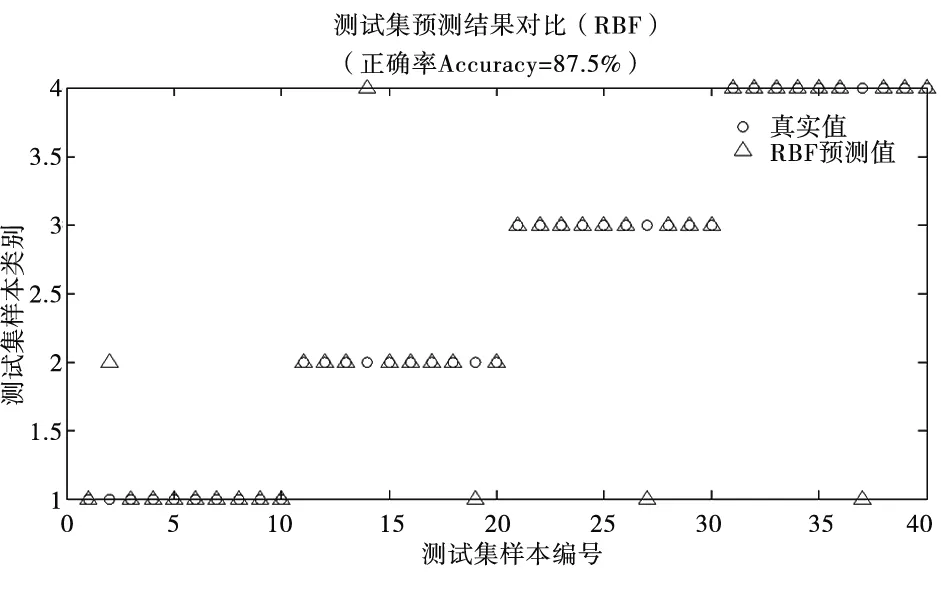
图7 RBF神经网络分类结果

网络种类训练样本数测试样本数分类准确率反应时间RBF网络40×440×487.5%8.352sELM40×440×492.5%6.012s
图6可以看出ELM的分类结果仅有3个与真实情况相匹配,而图7中却出现了5个与真实值不相符的结果,表4的清楚总结到极限学习机比RBF神经网络故障分类能力更显著,运算效率更高。
5 结论
齿轮箱信号的非线性和非平稳性,以及齿轮箱内部各部件振动信号的耦合,增大了齿轮箱故障诊断的难度,本文提出的基于CEEMD-MPE和ELM的齿轮箱故障诊断方法,对齿轮箱信号进行CEEMD分解,既避免了模态混叠现象的发生,又提高了运算速度,并对分解后的信号提取多尺度排列熵,来表征齿轮箱信号多重尺度上的故障信息,最终将故障特征输入到极限学习机中进行故障识别,实验结果表明分类准确率达到90%以上,而且运算效率较高,证明该方法对齿轮箱故障诊断有一定的可行性和实用性。
