PDT手持终端音频子系统的设计与实现
2019-05-05张松轶
李 飞,张松轶,冀 峰,白 清
(河北远东通信系统工程有限公司,河北 石家庄 050200)
0 引言
专业数字集群标准是具有我国自主知识产权的数字集群通信标准,是我国倡导的数字集群技术体制,可满足关键领域用户对高效、专业无线调度指挥业务的迫切需求。该标准采用半双工通信模式、TDMA多址方式和4FSK调制方式,信道间隔为12.5 kHz,数据传输速率为9.6 kb/s[1],具有业务功能丰富、可扩展性好、建设和运维成本低等特点,主要设备包括交换管理中心、基站、调度台和终端[2]。
话音调度是通信系统最基本的功能,是各行各业开展日常工作最重要的通信手段,PDT终端应用环境复杂多变,需要对环境噪声有出色的抑制能力,可以在更广范围内传送准确的语音和数据,保证在非常嘈杂的环境下也能通信自如[3]。音频是衡量终端性能优劣的重要指标,良好的设计以及优良的性能具有重要和现实的意义。
相关参考文献已经对各种终端设备的语音增强与优化技术进行了详尽的研究,但是大多针对的是全双工通信体制和设备,PDT手持终端采用了半双工的通信模式,在实现语音增强和优化方面有所不同,因此本设计对现有通用技术和方法进行了优化和改进。
1 PDT基本架构
PDT手持终端音频子系统(子系统)总体设计如图1所示,包括子系统及其相关的MCU控制单元、音频设备单元和射频及基带单元。
① 子系统采用高性能DSP处理器,主要负责上下行语音信号的处理;
② MCU控制单元采用ARM平台处理器,主要负责子系统和音频设备单元的配置管理;
③ 音频设备单元包括MIC、扬声器和CODEC等器件,主要负责语音信号的输入与输出;
④ 射频及基带单元负责收发空口数据并完成数据的调制解调;
⑤ 语音处理功能集中在音频子系统上,MCU控制单元、音频设备单元和射频及基带单元是子系统外围模块。

图1 子系统总体设计
子系统内部主要包括4部分:
① 运行配置管理模块,负责子系统任务调度、配置管理和模式切换;
② McASP EDMA接口模块,负责同CODEC的交互,完成PCM语音数据收发;
③ 上下行语音数据处理模块,负责上行和下行语音数据的预处理和啸叫识别及抑制处理;
④ 声码器模块,完成话音分析和合成的编、译码工作[4],PDT标准采用了NVOC声码器。
2 核心问题
为了提高设备的音频性能,保证良好的用户体验,子系统设计与实现需解决如下2个核心问题。
2.1 终端音量和音质
PDT手持终端需要在野外嘈杂环境下具有良好的使用效果,终端采用了2 W的大功率扬声器,但是随着音量的增加,噪音和语音失真的问题也更加突出。在提高音量的同时抑制噪音和语音失真,保证声音的清晰洪亮是本设计要解决的第1个核心问题[5]。
2.2 终端啸叫
声反馈是声音能量的一部分通过声传播的方式传到话筒而引起的啸叫现象,声源与扩音设备之间距离越近,传到话筒的音量越大,啸叫现象越明显,啸叫会严重影响用户体验甚至会造成终端损坏[6]。声反馈环境的复杂多样性,增加了啸叫抑制的难度,设计一个实时、高效的啸叫识别和抑制算法是本设计要解决的第2个核心问题。
3 关键技术
解决上述核心问题的思路和关键技术如下。
3.1 语音预处理技术
采用基于滤波器的语音预处理技术,对上下行语音信号进行预处理,在实现增强音量的同时,避免音质的下降。
常用的滤波器算法包括有限脉冲响应(Finite Impulse Response,FIR)滤波器和无限脉冲响应(Infinite Impulse Response,IIR)滤波器[7],本设计采用的FIR滤波器算法能够在保证任意幅频特性的同时具有严格的线性相频特性,其单位抽样响应是有限长的,滤波效果稳定,在通信、图像处理和模式识别等领域都有广泛的应用[8]。
由于人声的频带范围是300~3 400 Hz,同时300 Hz以下的低频信号对语音音质影响很小,因此FIR滤波器需重点过滤3 400 Hz以上的高频非人声信号[9]。采用理论分析和实际测试相结合的办法,综合考虑处理器性能和滤波效果,得到最佳滤波器参数如表1所示。
表1 FIR滤波器参数表

FIR参数设计值采样率/Hz8 000阶数63通带频率/Hz3 300阻带频率/Hz3 400通带权重0.1阻带权重40
3.2 啸叫识别与抑制技术
3.2.1 啸叫的产生原理及其抑制算法
PDT手持终端采用半双工通信模式[10],单部终端不存在声反馈问题。2部终端通话时,如果主叫的MIC和被叫扬声器距离过近,某些频率的信号会通过声反馈路径传回主叫的MIC被拾取,并与输入信号叠加,在某频点形成正反馈,形成啸叫[11-12],如图2所示。

图2 PDT手持终端啸叫原理
业内广泛采用的啸叫抑制算法包括移频法、随机相位法、陷波法及自适应滤波法等。移频法简单易实现,但容易导致语音严重失真;随机相位法虽然不会导致语音严重失真,但随机加入的相位有可能产生新的啸叫频点;陷波法需要人工寻找啸叫频点/频带,如果啸叫频点/频带判断不准,会导致语音失真;自适应滤波法自动调节语音的冲激响应特性,适应信号变化达到最优滤波,但是要频繁调整滤波器参数,计算量大,系统设计复杂[13]。
结合陷波法和自适应滤波法的优点,通过自动寻找啸叫频点,并对该频点周边频段进行陷波处理的方法,可以有效减低设计复杂度,保证啸叫抑制效果。
3.2.2 啸叫识别原理分析
啸叫从无到有的过程中,伴随着音频信号能量向啸叫频点不断聚集,逐渐破坏了正常语音的能量分布规律,因此从能量分布的角度出发,分析啸叫语音同正常语音之间的差异,即可实现啸叫的识别[14]。
语音信号既有时域特征又有频域特征,啸叫识别的目的是识别出啸叫频点,借助于傅里叶变换,将时域语音信号转换为频域,得到语音信号频谱,通过对比正常语音信号频谱和不同啸叫语音频谱,可归纳总结出啸叫语音区别于正常语音的频谱特征[15]。
为了获取啸叫频谱特征,采集一系列语音样本,样本包含以下五类:正常语音、轻度啸叫语音、高频(2 000 Hz以上)剧烈啸叫语音、中频(1 000~2 000 Hz)啸叫语音和低频(1 000 Hz以下)啸叫语音。典型频谱如图3~图7所示,为了更直观地表示语音频率成分变化,图中纵坐标直接采用PCM量化幅值,没有转化为对应分贝值。

图3 正常语音信号特征频谱
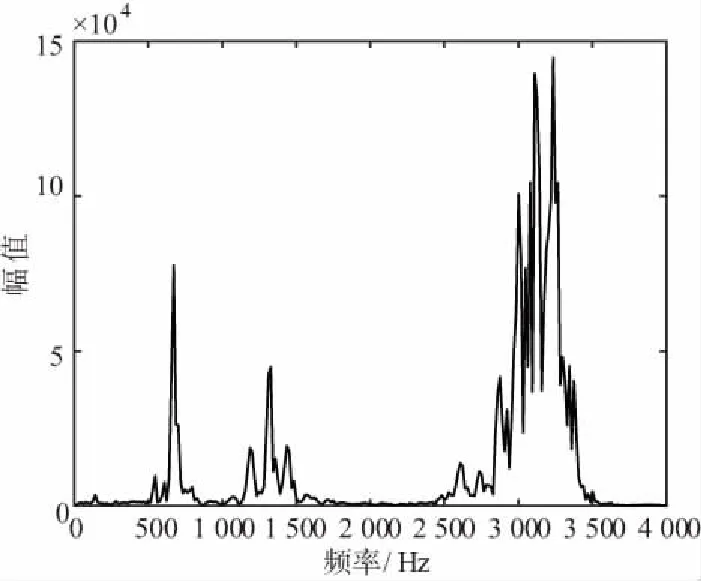
图4 轻微啸叫语音信号特征频谱

图5 剧烈高频啸叫语音信号特征频谱

图6 剧烈中频啸叫语音信号特征频谱
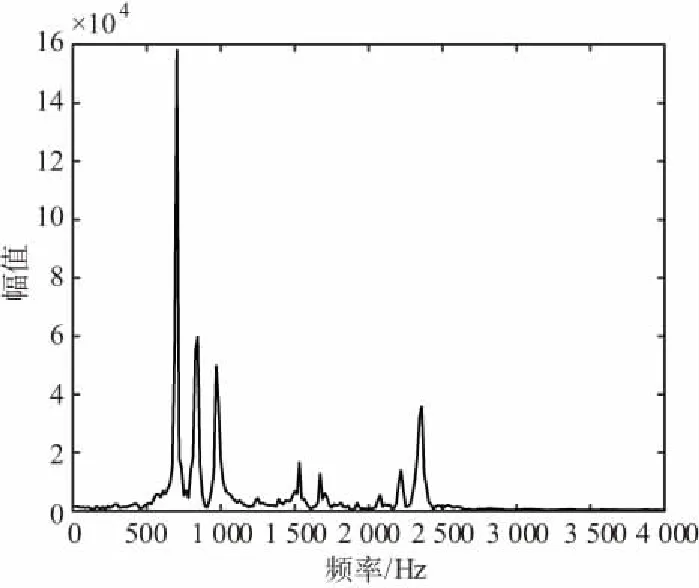
图7 剧烈低频啸叫语音信号特征频谱
通过大量样本的分析,总结出如下6个规律:
① 啸叫频点在频带上随机出现,并且会在一定范围内漂移抖动;
② 轻微啸叫通常表现为在频谱上同时出现多个能量集中的频点;
③ 剧烈啸叫通常表现为在频谱上出现单一能量集中的频点;
④ 正常语音的信号最大幅值频点在低频段,在0~500 Hz范围内能量谱密度(能量谱密度是当信号的频带宽度趋近于零时,每单位带宽的均方根值[16])最大;
⑤ 低频啸叫最大幅值频点在低频段500~1 000 Hz,在0~500 Hz范围内能量谱密度几乎为0;
⑥ 中频啸叫的最大幅值频点在中频段,高频啸叫的最大幅值频点在高频段,高频啸叫的带宽大于中频啸叫。
3.2.3 啸叫识别和抑制算法设计
综合吸收陷波法和自适应滤波法的优点,采用了一种基于频域分析的啸叫抑制算法,主要流程如图8所示。

图8 啸叫识别和抑制算法流程
上下行的啸叫识别和抑制算法流程基本相同,本文以上行处理为例进行介绍,流程分为5个阶段:
① 语音输入及预处理阶段:MIC端以8 000 Hz速率采样语音数据,通过0~3 400 Hz的FIR低通滤波器,滤掉高频干扰信号。
② 频谱分析阶段:将信号进行快速傅里叶变换,得到语音信号频谱;获取语音频谱的最大幅值频点,重点分析该频点是否具备啸叫特征。
③ 啸叫识别逻辑阶段:根据语音样本分析总结的规律,针对低、中、高频啸叫形态不同、频域特征不同的特点,采用不同的方法进一步识别。如果最大幅值频点落在低频带,则计算500 Hz以下能量谱密度,如果小于临界值,则判断为低频啸叫,反之则为正常语音信号。如果最大幅值频点落在中频和高频带,则判定一定产生了啸叫。
④ 啸叫抑制阶段:判定产生啸叫后,采用陷波器(带阻滤波器)技术对该频点及附近的信号强度进行衰减,不同子频带内啸叫的带宽不同,因此不同子频带内需采用不同带宽的陷波器[17]。
⑤ 语音输出阶段:将经过啸叫识别和抑制后的频域数据和正常语音数据,直接进行反向快速傅里叶变换,恢复为时域数据输出。
该方法不需要建立整个声反馈环境模型,只在上下行链路对语音信号进行频域分析,进行啸叫识别并进行陷波抑制,就可达到抑制啸叫,同时不损失语音信号[18]的目的。
4 测试结果分析
该设计已经通过测试验证并在实际产品上部署和应用,测试验证情况如下。
4.1 语音带宽及音量测试
通过FIR低通滤波器后的语音信号带宽限制在了3 400 Hz以内,高频信号被有效滤除。如图9所示,语音信号经过低通滤波后,频带被限制在3 400 Hz以内,音量有明显提升,满足了嘈杂环境中正常使用的要求。
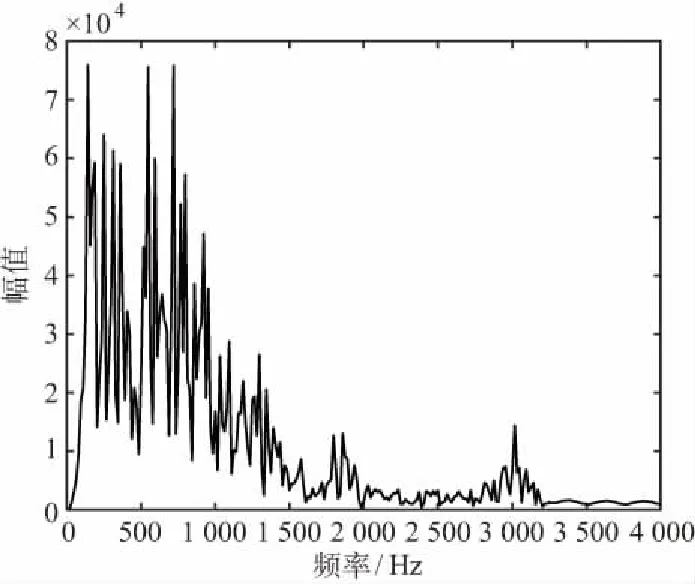
图9 FIR低通滤波后语音频谱
4.2 啸叫测试
信号通过基于频域分析的啸叫抑制算法处理后,2台终端在较近距离(20~50 cm)呼叫时,不会产生剧烈啸叫,在较远距离(50 cm以上)呼叫时,不会产生啸叫,语音频谱如图10所示。
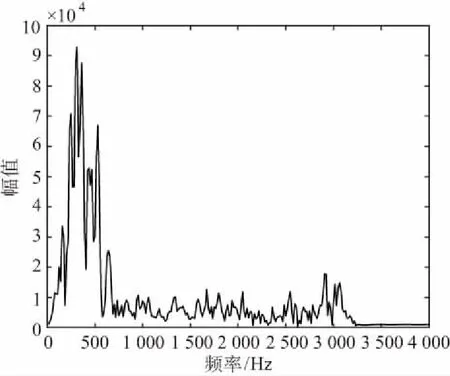
图10 啸叫抑制处理后语音频谱
5 结束语
针对音频子系统进行了总体设计,对影响音量、音质等音频性能的2个核心问题的关键技术进行了分析及论证,详细阐述了语音的增强处理和基于频域分析算法的啸叫识别与抑制处理,测试证明,通过上述方法,终端的音频性能和用户体验得到明显改善,终端对于环境的适应能力也得到有效提升。
