基于累积logit模型的医学生数据素养分析
2019-05-02付文玉曹海霞
杨 丽,付文玉,曹海霞
(潍坊医学院公共课教学部,山东 潍坊 261053)
随着“互联网+”时代的到来,大数据充斥着人们的日常生活;数据是信息的表现形式和载体[1],可以是数字,也可以是语音、文字、符号、视频等。那么数据素养就成为衡量人们数据处理能力高低的素质[2],包含的方面涉及到数据收集分析能力、数据利用共享、数据评估管理等。作为新时代的医学生这种数据素养也尤为重要,本文通过选取医学院校医学生为样本,利用logistics模型,对医学生的数据素养进行综合分析。
一、研究对象
调查对象来自于山东省某医学院校,在校园内随机发放调查问卷500份,回收调查问卷478份,有效问卷444份,有效率92.89%。由专门数据统计人员准确无误地录入数据,进行相关数据分析。
二、研究方法
“数据素养现状调查问卷”第一部分包括:人口学信息性别、年龄、专业、年级、数据处理能力自我评价、数据操作的相关活动;第二部分是“数据素养测量量表”,共26个题目。在进行正式调查前,进行预调查,结果显示问卷信度效度良好,统计软件SPSS 20.0。选择累积Logit模型进行分析,选择Logit作为联接函数。
三、结果与分析
1.基本情况。
本次调查大学生总数是444例,其中男生150人(33.8%),女生294人(66.2%);专业涉及到临床、公共卫生与管理、口腔、药学、影像等10个专业,其中大一157人(35.4%),大二100人(22.5%),大三119人(26.8%),大四68人(15.32%)。
2.医学生数据素养的得分现状。
性别方面,男生得分(86.87±20.288),女生(85.83±20.247);统计学分析P值为0.609,差异没有统计学意义。不同年龄段、年级的数据素养得分如下(见表1、表2),差异均无统计学意义。数据的中位数88,说明得分集中在稍较高的分数,即大多数大学生的数据处理能力处于中等偏上水平。数据素养得分中最大值为130,最小值为26,其极值为104;该数据的四分位数为25。该数据跨度较大,最小值与最大值较分散,数据的变异程度大。说明大学生的数据处理能力差距较大,有的学生具有较强的数据处理能力,有些同学的数据处理能力较差。

表1 不同年龄段数据素养的得分

表2 不同年级数据素养的得分
3.医学生数据素养影响因素的有序多分类logistic回归分析。
将性别、年龄、是否参与数据处理、是否参与数据操作等因素作为自变量纳入有序多分类logistic回归分析。经模型拟合检验得χ2=53.406,P=0.000,模型成立有统计学意义;平行线检验结果显示χ2=30.763,P=0.078;经拟合优度检验,Pearson和Deviance两个准则的P值是0.1和1.0,均大于0.05.说明模型拟合较好(见表3)。
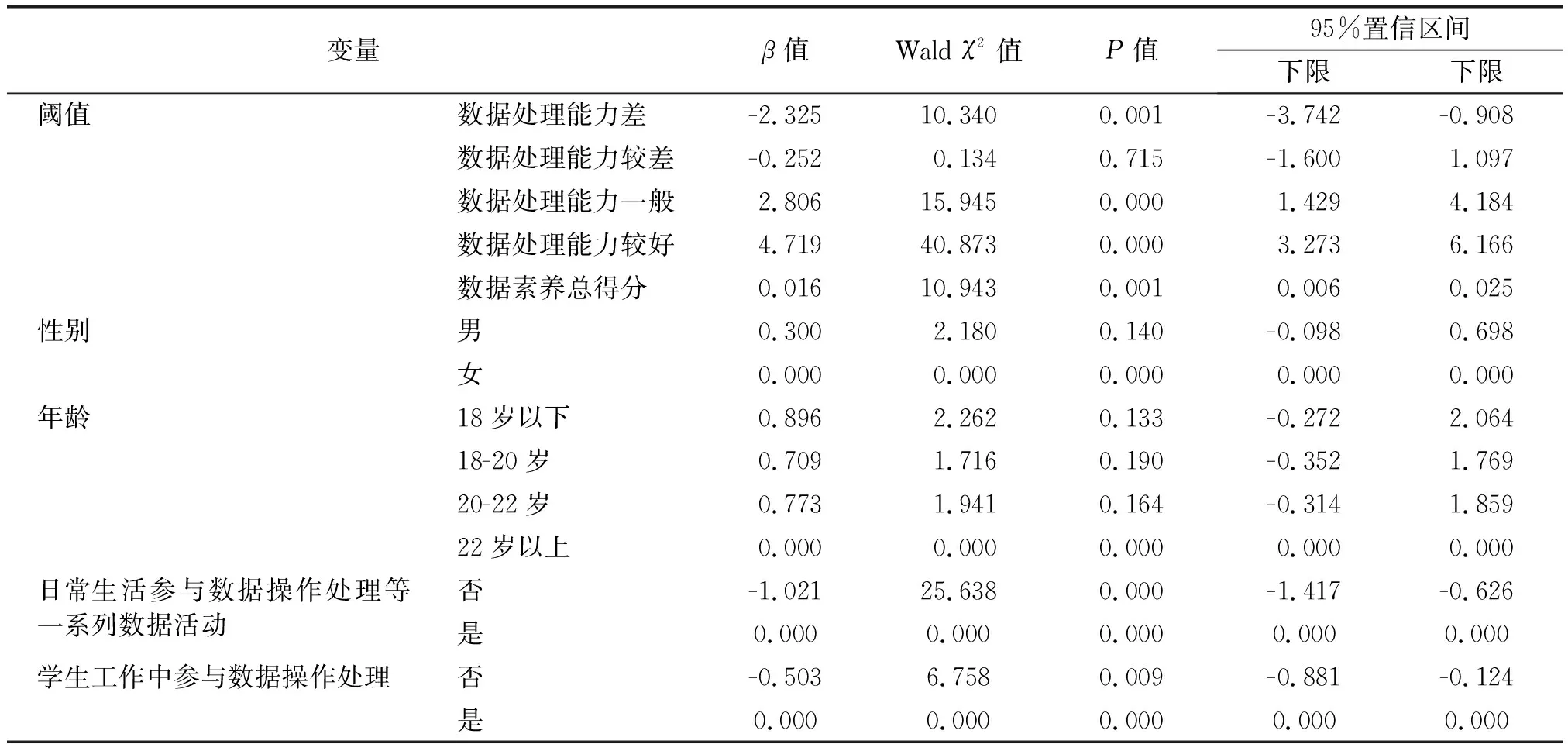
表3 医学生数据处理能力的有序多分类logistic回归分析
性别和年龄对数据处理能力的影响没有统计学意义,但是日常生活中参与数据处理、学生工作中参与数据处理、以及数据素养总得分越高,数据处理能力就会越强。
三、讨 论
通过自行设计问卷调查大学生的数据素养,结果有一定局限性。从调查结果发现,该医学院校的大学生数据素养得分情况属于中等偏上,但是差距较大;大学生提高数据素养的途径首先是通过相关的理论课程[3-4],比如:统计学,软件课程,其次还可通过论文、大学生社团、大学生科技创新项目、数学建模比赛等活动。高校教师通过相关数据分析课程[5],将数据管理的基本理论和技术方法,系统地传授给学生,所以高校可以将更多的数据分析的课程纳入教育教学体系中来;另外,近几年各高校开展的各类竞赛活动[6],也可以在很大程度上提高大学生的数据素养,在校大学生应该积极参与到各类竞赛活动中来,利用学校图书馆[7-8],查找相关的实体文献信息资源和虚拟文献信息资源,利用信息技术提高自身的数据素养。
