基于集成学习算法构建前列腺癌预测模型
2019-04-27范馨月单立平
杜 超,范馨月,单立平
前列腺癌(Prostate Cancer,PCa)是男性最常见的癌症之一,也是全世界男性癌症死亡的第二大原因,2020年,PCa相关死亡人数估计为385 560[1]。为了使前列腺癌患者能获得更好的预后及进一步提高其生活质量,前列腺癌的筛查和诊断已经成为当前研究的重点。
在临床上,前列腺癌需要经过前列腺穿刺活检才能够确诊,而穿刺前最常用的参考指标为前列腺特异性抗原(Prostate Specific Antigen,PSA)[2]。由于PSA浓度因受到炎症、射精、导尿操作等一系列非前列腺癌因素的影响而出现一过性升高,导致单纯使用PSA无法正确区分前列腺癌和前列腺增生[3]。如果持续采用单一指标诊断模式将造成漏诊或者不必要的活检。
近年来,随着计算机技术的迅猛发展,国内外一些研究开始采用机器学习方法进行前列腺癌的诊断[4-6],但都存在着一定的局限性。预测模型的变量主要为患者的PSA水平或MRI影像参数,没有综合考虑患者病史、化验及检查等指标,同时也没有将得到的模型在临床中进行验证。为克服前列腺癌单一诊断指标的局限性,本文综合当前的研究现状,收集前列腺癌患者的基本信息(年龄、体重)、病史、症状表现、化验结果及MRI检查等指标作为研究变量,通过两种变量筛选方法的比较,确定纳入模型的最佳变量组合,采用多种机器学习方法建立前列腺癌诊断预测模型,并将得到的模型应用于临床,评价模型的准确性,旨在揭示机器学习在前列腺癌诊断中的应用价值,为前列腺癌的早期诊断研究提供新的思路。
1 数据收集与预处理
1.1 数据收集及变量介绍
本文收集2017年1月-2018年12月于中国医科大学附属盛京医院泌尿外科行超声引导下前列腺穿刺活检术的患者信息,包括患者年龄、血清总PSA(total Prostate Specific Antigen,tPSA)、游离PSA(free Prostate Specific Antigen,fPSA)、游离PSA百分比((fPSA/tPSA,f/tPSA)、PSA密度、前列腺体积、碱性磷酸酶(Alkaline Phosphatase,ALP)、血糖、血脂、血压、体重、饮酒、吸烟、核磁共振检查(Magnetic Resonance Imaging,MRI)、尿急尿痛、排尿困难、夜尿频次、血尿共18个相关变量用于变量的筛选及建模。部分变量的计算方法及介绍如下:
游离PSA百分比(f/tPSA):单纯的tPSA升高对前列腺癌的诊断特异性不高。当tPSA介于4-10ng/ml之间时,因患者的tPSA仅轻度升高而加大了诊断的难度;当f/tPSA<0.16时,则患者前列腺癌风险增加[2]。
(1)
PSA密度(Prostate Specific Antigen Density,PSAD)表示单位体积内前列腺的PSA含量。
(2)
前列腺体积(Prostate Volume,PV)表示前列腺增生的情况。本文前列腺的左右、前后、上下径由MRI测得。
PV=0.52×左右径(cm)×上下径(cm)×前后径(cm)
(3)
碱性磷酸酶(Alkaline Phosphatase,ALP)是广泛分布于人体肝脏、骨骼、肠、肾和胎盘等组织经肝脏向胆外排出的一种酶,临床上测定ALP主要用于骨骼疾病的诊断和鉴别诊断,ALP水平的升高与恶性肿瘤的骨转移相关[7]。
MRI:前列腺核磁共振检查已成为诊断前列腺癌的常规手段,不仅能够发现直肠指诊难以发现的占位性病变,而且具有一定的特异性。由于前列腺癌以前列腺外周带多发[8],因此当磁共振检测出外周带结节时,应警惕前列腺癌的发生。
本文共纳入样本255例,其中穿刺结果为前列腺癌患者85例,前列腺增生患者170例。
1.2 数据预处理
1.2.1 缺失值处理
绝大部分患者的临床信息能够完整收集,但仍有少部分患者的信息是缺失的。我们在纳入数据时,将缺失值大于10%的患者排除,在纳入的255例患者的缺失数据均小于10%,使用SPSS 22.0中均值填充(序列均值)缺失值的方法,补全所有患者信息。
1.2.2 预测变量筛选
在纳入的18个变量中,首先对各个变量的分布情况进行分析,然后采用传统的变量筛选方法即单变量方差分析,筛选出有统计学意义的变量,再对变量进行Logistic多元回归分析。进行单变量t检验/卡方检验,采用Weka 软件将所有数值型变量转为标称型变量,并计算各个变量信息增益率,将单变量分析与信息增益率相结合进行变量筛选。
本文采用上述两种方法进行变量筛选,选用最优变量建立前列腺癌诊断预测模型。
1.3 结局变量
纳入的所有患者均行12针系统穿刺活检术,以术后病理结果作为患者诊断的“金标准”,若病理结果显示为前列腺癌(恶性)则为阳性样本,穿刺结果为前列腺增生(良性)则为阴性样本。本文共纳入255例样本,其中阳性样本85例,阴性样本170例,用于建立模型。
2 构建前列腺癌诊断预测模型
2.1 构造样本集
2.1.1 训练集和测试集
考虑到样本量的限制,本文不再按比例单独划分训练集和测试集,而是采用十折交叉验证方法(10-fold cross-validation)[9]建立模型。所谓十折交叉验证就是每次将数据随机分成10份,其中9份作为训练集,将余下的1份作为测试集。该过程重复进行10次,可以有效提高模型的稳定性和泛化能力,防止“过拟合”现象的出现。
2.1.2 验证集
为了更好地评价模型性能,本文引入验证集对模型进行验证。验证集共包含75例样本,为2019年1-6月在中国医科大学附属盛京医院泌尿外科行超声引导下前列腺穿刺活检术的患者(变量纳入和排除标准同上),其中阳性样本26例,阴性样本49例。
2.2 模型构建方法
2.2.1 集成学习
集成学习(Ensemble Learning)[10]并不是一种单独的机器学习算法,而是将多个单一的分类器组合在一起,使它们共同完成学习任务,可以有效提高基分类器的泛化能力并解决过拟合问题。常见的集成学习方法有Bagging,Boosting和Stacking,本文主要采用Bagging方法。
Bagging(Bootstrap aggregating)[11]采用自助采样法(Bootstrap)进行多轮有放回抽样,每轮从原始样本集中抽取n个训练样本,共进行k轮抽取,得到k个训练集;每次使用1个训练集进行建模,共得到k个模型,每个模型的重要性是相同的。对于分类问题,将k个模型结果采用投票的方式获得最终分类结果;对于回归问题,则计算上述k个模型的均值作为最后的结果。
2.2.2 朴素贝叶斯
朴素贝叶斯法(Naive Bayes)[12]是基于贝叶斯定理与特征条件独立假设的分类方法。对于一个已知分类的待分类集合(训练样本集)x={a1,a2,…,am}和有类别集合C={y1,y2,…,yn},统计各类别下各个特征属性的条件概率估计公式为:
P=a1…m| y1…n
(4)
因各个特征属性是相互独立的,故得到最终的朴素贝叶斯公式为:

(5)
朴素贝叶斯对小规模的数据表现良好,对缺失数据不太敏感,算法比较简单,用于本文的数据较为合适。
3 结果与分析
3.1 变量筛选结果及分析
对训练集和验证集的255例样本进行单因素分析,可知有10个变量有显著性意义。变量分布情况及显著性见表1。其中前列腺癌组与前列腺增生组的年龄、体重、tPSA、fPSA 、f/tPSA、PSAD、PV、ALP、夜尿频次及MRI检查均存在统计学差异。
3.1.1 多因素Logistic分析
将上述10个指标进行多因素Logistic回归分析,经筛选后,年龄、tPSA、游离PSA百分比、前列腺体积、体重5个指标被纳入(表2)。其中年龄、tPSA和体重都是危险因素,tPSA每提高一个单位水平,患前列腺癌的风险提高1.067倍。各个指标的ROC曲线如图1所示。其中tPSA在所有指标中最有诊断意义,游离PSA百分比次之。
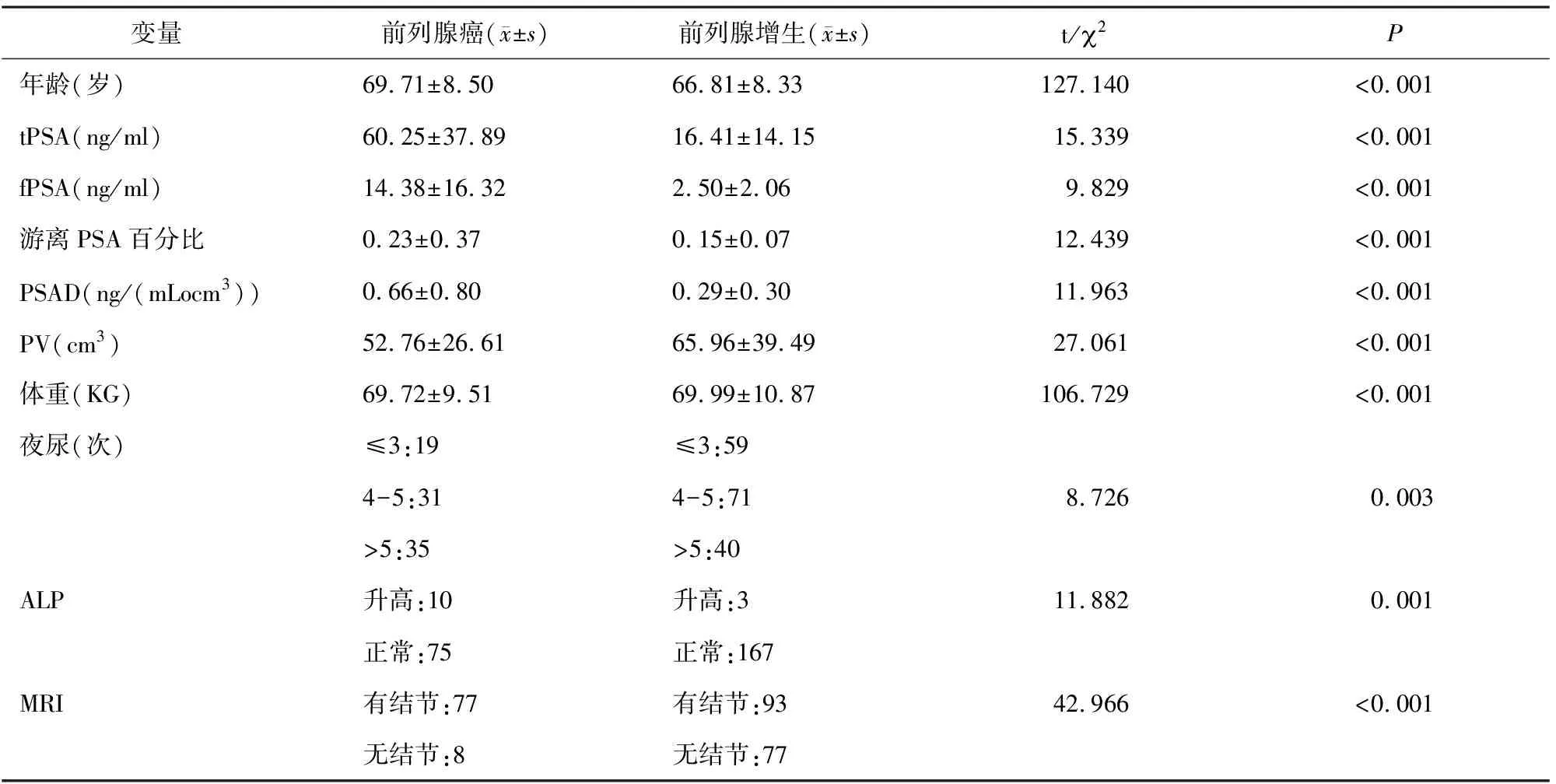
表1 前列腺癌与前列腺增生变量分布及差异性比较
注:t/2为t检验和卡方检验对应的t值或2值
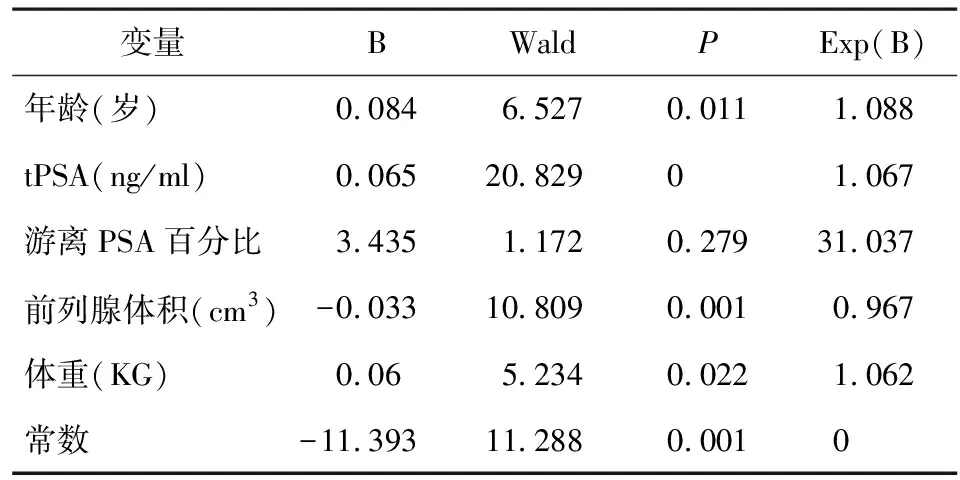
表2 多因素Logistic分析结果
注:B表示系数;Wald为检验统计量,检验自变量对因变量是否有影响;Exp(B)代表OR值

图1 Logistic回归各指标ROC曲线
3.1.2 信息增益率分析
使用Weka中变量选择模块计算各个变量信息增益率,属性评估器(Attribute Evaluator)选择InfoGainAttributeEval,查找算法(Search Method)选择Ranker。各变量信息增益率如表3所示。其中数值型变量无需变量划分。综合显著性分析和变量重要性分析,将P<0.05且信息增益率>0.02作为纳入标准,年龄、tPSA、fPSA、游离PSA百分比、PSAD、前列腺体积、体重、夜尿频次、ALP及MRI10个变量被纳入,而吸烟、饮酒、排尿困难、血尿、血脂、血糖、血压、尿急尿痛等8个变量被排除。
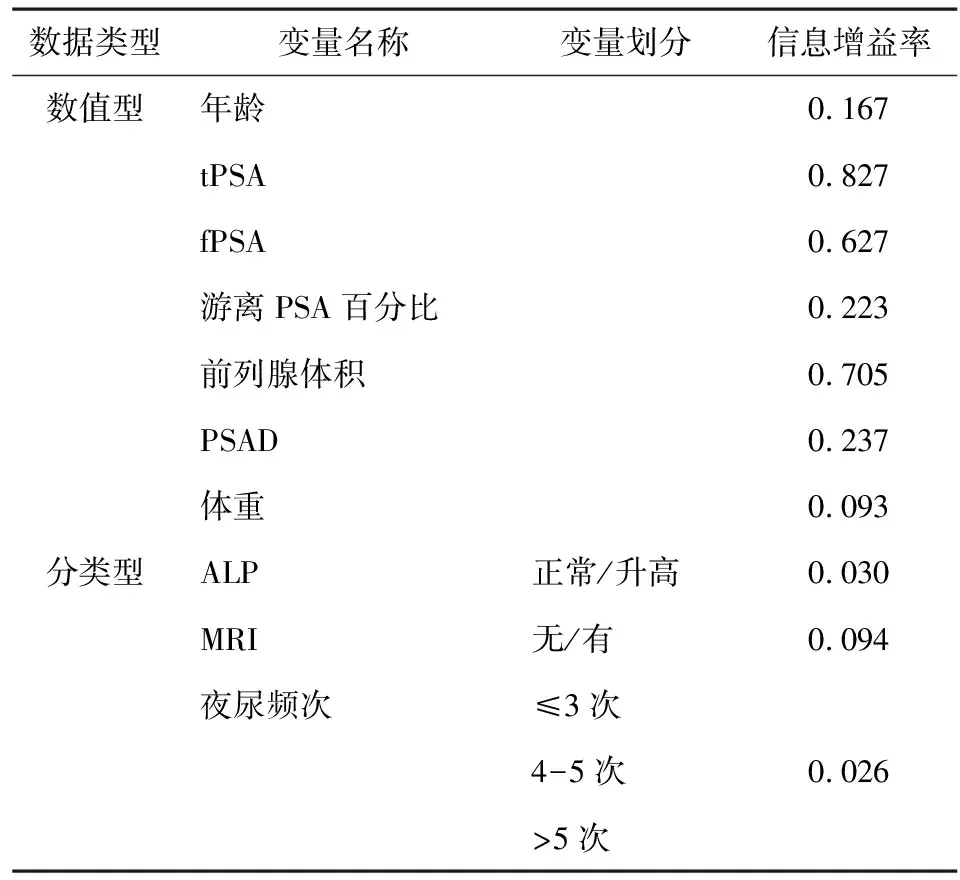
表3 变量类型、划分及重要性排序
3.2 模型结果分析
为进一步提高模型性能,采用十折交叉验证划分训练集和测试集,运用集成学习的方法选取随机森林、Bagging 集成朴素贝叶斯、支持向量机(Support Vector Machine,SVM)及Logistic等基分类器,构建前列腺癌诊断模型。
为验证不同算法及不同变量构建的模型性能,采用Precision、Recall、F值及AUC共[13]4个指标对诊断预测模型进行评价与比较的结果,如表4所示。
由表4可知,4种算法构建的模型性能因变量筛选方式不同略有差异。在使用信息增益率筛选方式建立的模型中,Naive Bayes模型AUC最高,为0.826;RF的Precision值最大,达到0.839;在应用Logistic筛选变量建模中,RF的AUC和Precision均为最高,分别是0.743和0.823;4种算法在应用信息增益率筛选变量建立的模型性能均优于应用Logistic筛选变量的模型性能。
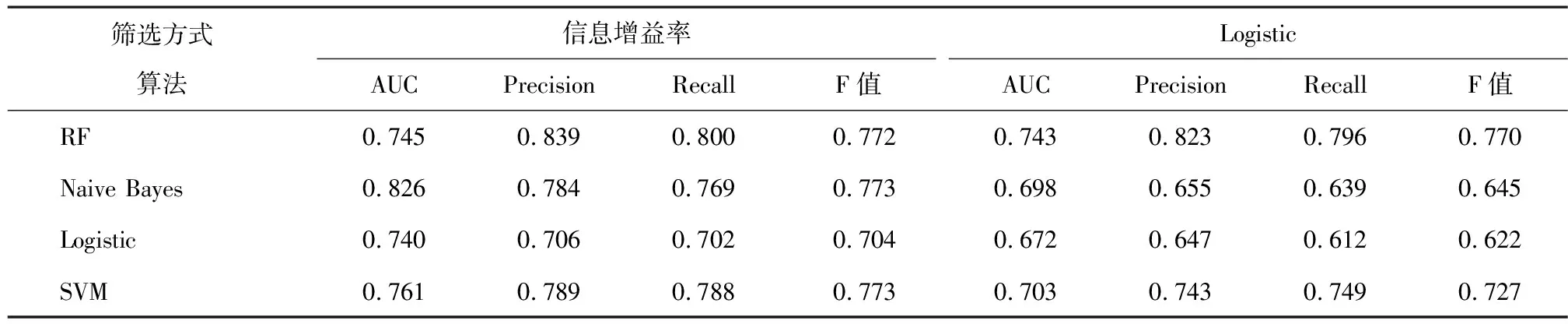
表4 2种变量筛选方式、4种集成学习模型结果比较
3.3 模型验证
应用信息增益率筛选的变量构建的模型性能更佳。为进一步验证模型性能,将模型应用于临床研究,采用相同的纳入和排除标准收集75例患者(阳性26例,阴性49例)作为验证集,采用4种算法应用相同的参数进行模型性能评估,结果见表5。其中Naive Bayes算法的AUC值最大(AUC=0.797,Precision=0.764),RF的Precision最高,而AUC值最低(Precision=0.791,AUC=0.610)。两种算法的ROC曲线及混淆矩阵分别如图2和表6所示,图2分别表示Naive Bayes算法ROC曲线和RF算法ROC曲线。由表6可知,RF算法对于阴性的预测更准确,49例阴性样本全部预测正确,可避免不必要的穿刺活检;而Naive Bayes算法对于阳性样本的预测效果较好,26例中有21例预测正确,准确率达80.7%。故在将模型应用于临床时,应该综合考虑多个模型的结果,以达到最好的术前诊断效果。
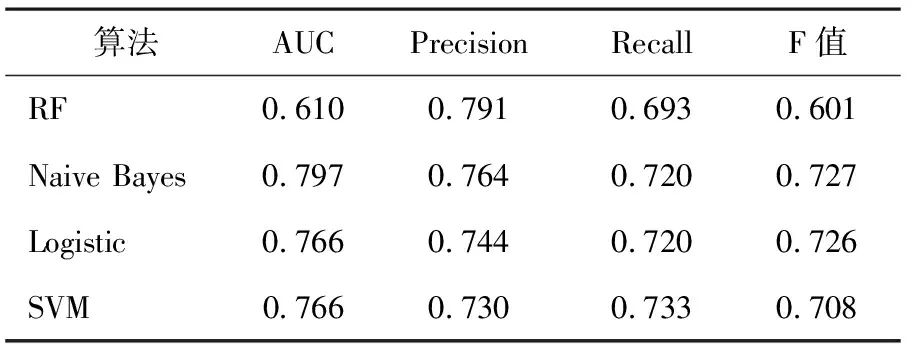
表5 4种算法验证集模型性能
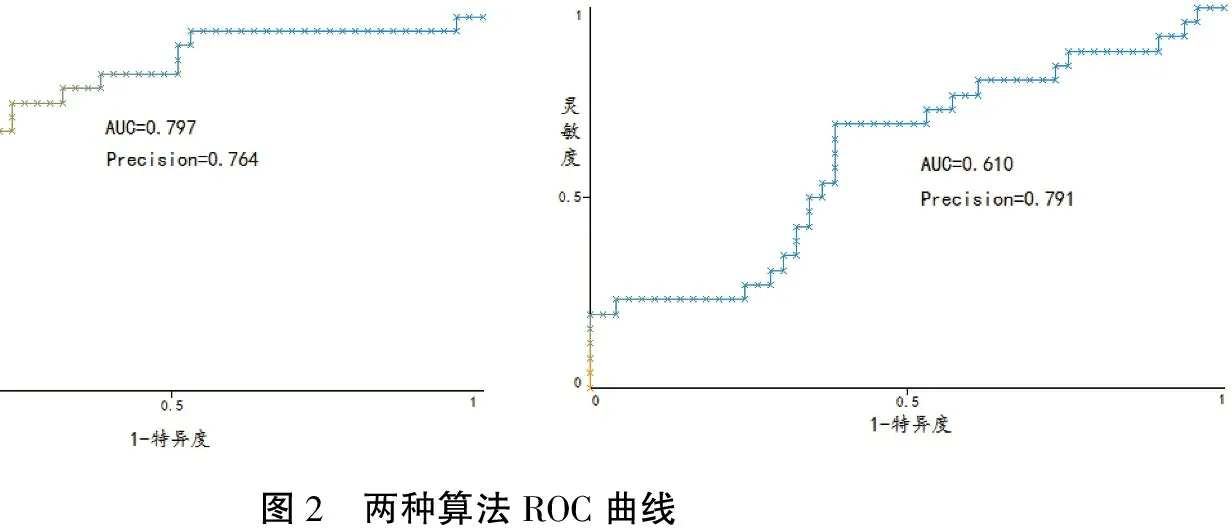
图2 两种算法ROC曲线
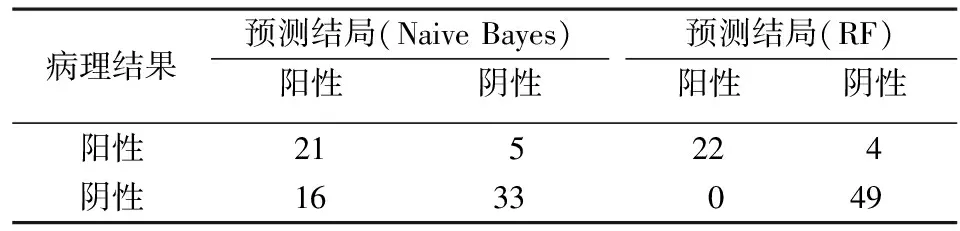
表6 两种算法混淆矩阵
4 讨论
近年来,我国的前列腺癌发病率逐年升高。在综合考虑患者的基本信息、症状、体征、化验及检查结果后,对穿刺结局进行准确预测能够有效减轻患者身体及经济上的负担。面对庞大的临床信息量,变量筛选方式的选择是研究面临的主要问题之一。本文发现信息增益率筛选出的变量较Logistics更为科学合理。Logistics分析显示,年龄、tPSA是前列腺的相关危险因素,而前列腺体积则为前列腺癌的保护因素,此结论与近些年的研究结果一致[14]。但Logistic分析舍弃了许多有价值的变量,PSA密度[15]、MRI检查等重要的参考指标并没有被纳入,容易造成临床医生对患者重要信息的忽视。
信息增益率筛选方式,不仅能够对不同变量的重要程度进行排序,而且能够根据实际情况设计阈值,使实验结果更加贴近临床。PSA相关指标是重要性最高的几种变量,应在诊断时优先考虑;前列腺体积、体重、MRI检查在重要性方面次之。虽然夜尿频次、ALP水平仅对诊断的参考价值较小,但仍然不容忽视。其中,夜尿频次增加是前列腺癌患者的早期临床表现之一,ALP升高为存在骨转移的重要指标,因此可以间接反应患者是否存在前列腺癌的风险。虽然高血压、高血脂以及糖尿病等代谢综合征的存在会增加前列腺癌风险,但本文中未见统计学差异,有待进一步进行更大样本量的研究。
本文对Losgistic多因素分析与机器学习算法的横向对比,证明机器学习算法具有较准确的预测效果。不同机器学习算法间的纵向对比发现,虽然不同算法之间均具有良好的效果,但以ROC曲线下面积为标准。朴素贝叶斯的预测效果最好,而以基于精准率与召回率的F值为标准,则随机森林效果最佳。除了进行更加全面的对比之外,还对建立的模型进行了临床验证,以较为准确的朴素贝叶斯算法及随机森林算法为例,结果证明两种模型均具有良好的临床应用潜能但随机森林的预测结果更加准确。但是,本文仍存在以下不足:患者临床信息的缺失,未考虑存在患者穿刺结果为假阴性可能、样本量较小等。综上所述,机器学习算法在前列腺癌的诊断中具备较高的准确率,但其临床应用尚待进一步研究。
