胶囊网络下基于三元损失的图像相似性学习
2019-04-26潘执政魏鹏飞
潘执政,杨 旻,魏鹏飞
(烟台大学数学与信息科学学院,山东 烟台 264005)
图像的检索、识别、分类一直是科研和应用领域中的重要问题,近年来,基于深度学习的方法[1-3]得到了充足的发展.在这些方法中,图像相似性的测度选择是影响算法性能的关键因素之一.近年来,利用三元组度量图像的相似性[4-7]在类内细粒度图像甄别上取得了很好的效果.CHECHILK等[8]提出了一种在线三元稀疏被动攻击的图像相似性学习算法,解决了由于CPU和存储等限制,图像语义相似性算法不能扩展到大规模数据集等问题.BALNTAS等[9]利用三元组图像训练得到了局部图像探测器,用于寻找与特定图像相匹配的图像.
而另一方面,网络的层次与结构,尤其是特征提取部分的网络,对算法性能起着重要的影响.最近,SABOUR等[10]建立了一种源于生物视觉研究的特征提取网络—胶囊网络(capsule),其中胶囊是一组神经元,表示图像中存在的特定实体的各种属性,其可以是不同类型的实例化参数,如位置、方向、形变、速度、反射率、色调、纹理等等,胶囊用实例化参数向量的模表示实例存在概率.通过引入动态路由协议,避免了重要特征的损失.在实际应用中,应用胶囊网络都获得了非常好的表现.XI等[11]探索了MNIST手写字体集和其他图像集在胶囊网络应用的差异.ZHAO等[12]针对胶囊网络在文本分类任务上的应用做了深入研究,对于传统的分类问题,胶囊网络取得了较好性能,在多标签迁移的任务上,胶囊网络的性能超过了卷积神经网络(CNN)和时间递归神经网络(LSTM).
根据目前研究现状,将胶囊网络应用于图像相似性学习的工作还未有相关文献研究.为此,本文提出了胶囊网络下基于三元损失的图像相似性学习方法,构建了基于胶囊网络的三元损失网络结构.在此网络中,每组三元样本并行通过胶囊网络,分别完成特征提取,其结果汇总后,由三元损失函数得到该样本组的损失,通过大量样本的不断训练,得到最优模型.新方法不仅优化了图像提取质量,提升了特征的准确性,同时具备了对细粒度图像的高识别性.本文最后的实验表明,相比于文献[7]中基于排序损失函数的深度学习网络,其准确率有极大的提高.
本文结构如下:第1节给出三元组及损失函数的定义,胶囊网络的结构及符号说明;第2节,将三元损失与胶囊网络有机结合在一起,建立了新型的网络结构;第3节,在人脸数据集Labeled Faces in the Wild(LFW)上,进行了实验分析,并与文献[7]的方法进行了结果对比.
1 三元组及胶囊网络
1.1 “三元组” 损失学习
定义了2张图像p与q的相似度:
D(f(p),f(q))=‖f(p)-f(q)‖22,
(1)
其中f(·)是在欧几里得空间上将图像映射到d维的映射函数.D(·)衡量2张图像相似程度,2张图像越相似,D(·)越小.受文献[4]和[7]启发,采用“三元组损失”来进行模型的度量学习.一个三元组包含标准样本(xa)、正样本(xp)、负样本(xn),目的是保证通过三元组损失的学习使得xa和xp之间的距离最小,而和xn之间距离最大.其中xa为训练数据集中随机选取的一个样本,xp为和xa属于同一类的样本,而xp则为和xa不同类的样本.故此有:
D(f(xa),f(xp))+α<
D(f(xa),f(xn)),∀(xa,xp,xn)∈Ω,
(2)
其中α是人为给定的2张图像相似与不相似的界定标准,若取较大的参数值,则2张图像不相似程度越大,会导致较大的损失;Ω是训练集中所有可能的三元组集合,大小为N.
最小化的损失函数为L:
L=∑Ni=1[‖f(xai)-f(xpi)‖22-
‖f(xai)-f(xni)‖22+α]+.
(3)
其中[]+表示[]内的值大于零的时候,取该值为三元组样本i的损失,小于零的时候,该三元组样本i的损失为零.
1.2 胶囊网络
胶囊网络是为解决卷积神经网络(CNN)在特征提取中存在的不变性(invariance)问题而提出的.胶囊网络和CNN都能够得到样本图像的背景特征图、轮廓特征图以及纹理特征图等等.尽管在CNN中,池化能够带来特征不变性(invariance)的效果,也就是当样本内容发生很小的变化或有一些平移和旋转,CNN也能够有效地识别内容,但并不能学习到样本中不同特征间的关联性,且部分信息的丢失会对检索、识别等结果产生很大的影响.在生物视觉系统的研究中,发现大脑皮层中存在大量的柱状结构(皮层微柱),其内部含有上百个神经元,并存在内部分层.这就意味着人脑中的一层与神经网络(NN)的一层并不一样,而是有着复杂的内部结构,由此,文献[10]提出了对应的结构-胶囊(capsule).
与CNN不同,胶囊是一组神经元,表示图像中存在的特定实体的各种属性,其输入和输出都是向量,胶囊的输出向量长度表示胶囊所代表的实体在当前的输入中存在的概率,所以,即使实体在图片中的位置或方向发生了改变,但实体存在的概率没有发生变化.使用一个非线性的挤压函数(squashing)来确保将短的向量长度压缩到接近于0,将长的向量长度压缩到略低于1,且方向始终不变,
vj=‖sj‖21+‖sj‖2·sj‖sj‖,
(4)
其中vj是胶囊j的向量输出,sj是其总输入.
除了胶囊体的第一层外的其他层,一个胶囊的总输入sj是来自于低一层的胶囊所有“预测向量”uj|i的加权总合,而uj|i是通过用一个权重向量wij乘以一个低一层的胶囊的输出ui得出的.
sj=∑icijuj|i,uj|i=wijui,
(5)
其中cij是由迭代动态路由过程决定的耦合系数.胶囊i和高一层的所有胶囊j的耦合系数总和为1,即∑icij=1,并且是由路由softmax决定,该路由softmax初始逻辑bij是对数先验概率,即胶囊i与胶囊j的耦合为:
cij=exp(bij)∑kexp(bik) .
(6)
如图1所示,整个层级间的传播和分配分为2个部分,第1部分是ui和uj|i的线性组合,第2部分是uj|i和sj的路由过程.底层胶囊u1和u2的输入是向量,这两个胶囊分别与不同的权重wij相乘得到预测向量uj|i,即低维特征到高维特征的概率;然后该预测向量和对应的耦合系数cij相乘,传入特定的后一层胶囊sj,不同胶囊的输入sj是所有可能传入的预测向量uj|i和耦合系数sj的乘积和;最后输入向量sj通过挤压函数(squashing)得到后一层胶囊的输出向量vj.如果该预测向量uj|i与对应的输出vj之间存在着一个较大的标量积,则会通过自顶而下的反馈机制来增加该可能的vj的耦合系数cij,从而降低其它的耦合系数.这样做的好处是:增加了当前胶囊对vj的“贡献”,也提高了当前胶囊的预测向量与vj的输出向量之间的标量积,这种路由协议比最大池化法高效得多,最大池化机制只是激活每一个映射中的一个神经元,其余的神经元进行抑制.

图1 胶囊层级结构和动态路由过程
2 基于胶囊的三元网络结构
本文提出的网络结构如图2所示,网络开始以三元组图片为输入,一个三元组包含标准样本、正样本、负样本3张图片,此3张图片同时分别输入相同结构的胶囊网络进行提取特征,最后将提取的特征输入到损失层.

图2 基于胶囊的三元网络结构
在本网络中,原始图像经过处理,由原来的256×256缩放到28×28,以便于减少网络的计算量.在胶囊网络中主要包括3个层,分别为卷积层、初始胶囊层、胶囊层.卷积层是常规卷积,首先是将28×28像素的图片通过一个9×9的卷积核,其通道为256,步长为1,通过常规的CNN进行卷积,得到特征图大小为20, 通过一层卷积后得到20×20×256的特征图,这一层将像素强度转化为局部特征;第2层同样采用9×9的卷积核,通道为32, 步长为2的8次不同卷积,每次都得到一个6×6×8×32的输出,再把这些输出在6×6×1×32的第3维上堆叠(concatenate),故得到6×6×8×32的特征图,特征图大小为6,其6×6的特征图上每个点都是一个8维的向量;在传递到第3层之前,先把6×6×8×32的特征图重塑成1152×8的矩阵.在第3层需要经过迭代路由操作,最后通过挤压函数(squashing)得到10×16的矩阵;最后在10个维度为16的胶囊中,选取模长最大的向量作为最后的输出.3张图像经过胶囊得到的特征传送到损失层.三元损失函数的目的就是使损失在不断的训练迭代中越来越小,也就是通过不断学习,使得标准样本与正样本越来越近,标准样本与负样本越来越远.
3 实验及结果分析
本文模型的运行环境:Linux系统 ubuntu16.04版本,Python3.6,CPU-i5-7500,GPU-gtx1070,pytorch-0.3.1.使用的数据集是Labeled Faces in the Wild(LFW),LFW是无约束自然场景人脸识别数据集,该数据集由13 000多张全世界知名人士互联网自然场景不同朝向、表情和光照环境人脸图片组成,共有5 000多人.
对LFW进行三元采样,首先从数据集中随机选取一张图像作为标准样本,再从数据集里面另外选取一张同一人的图像作为正样本,而负样本是随机选取一张不是同一人的图像,以此类推,共选取6 484组三元组作为训练集和1 000组作为测试集.
将本文提出的方法与基于排序损失的深度学习方法[7]进行了实验比对.epoch是所有训练图像全部通过网络训练的次数;batch是对三元组进行批处理的数量;acc是在每次epoch后在测试集上的精确度;loss是每次epoch后在测试集上损失,α为最小间隔阈值.2种方法的训练集和设置相同:学习率为0.001,α为0.000 8,训练batch为32,测试batch为32,epoch为100.
实验结果由图3和图4给出,其中cap-曲线表示本文提出的方法所对应结果,tri-曲线表示由基于排序损失函数的深度学习方法[7]得出的结果.由图3可知,在初始阶段tri-acc虽然高于cap-acc,但随着模型的不断训练,后者逐渐高于前者,最终本文精确度达到99.8%.而在图4中,cap-loss始终低于tri-loss,本文最终损失为0.015 4. 经过实验对比可知,基于胶囊网络的三元损失新模型优于基于排序损失的深度网络模型.
由于α是人为设定的,α的大小对模型有一定的影响.当α设置偏小时,会使得精确率出现很大偏差,损失偏大;当α设置偏大时,会使得精确率不稳定,出现震荡现象,同时损失收敛过快.因此,设置一个合理的α值很关键,这是衡量相似度的重要指标.实验表明,当α为0.000 8时,效果最佳.根据数据集和网络模型的不同,α也要随之调整.
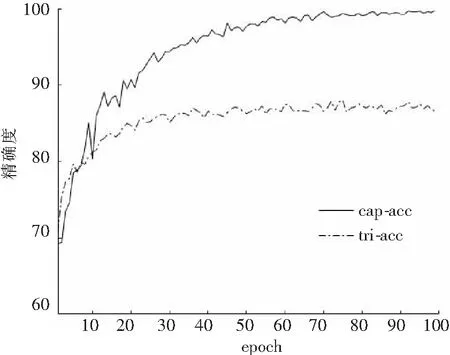
图3 准确率vs epoch
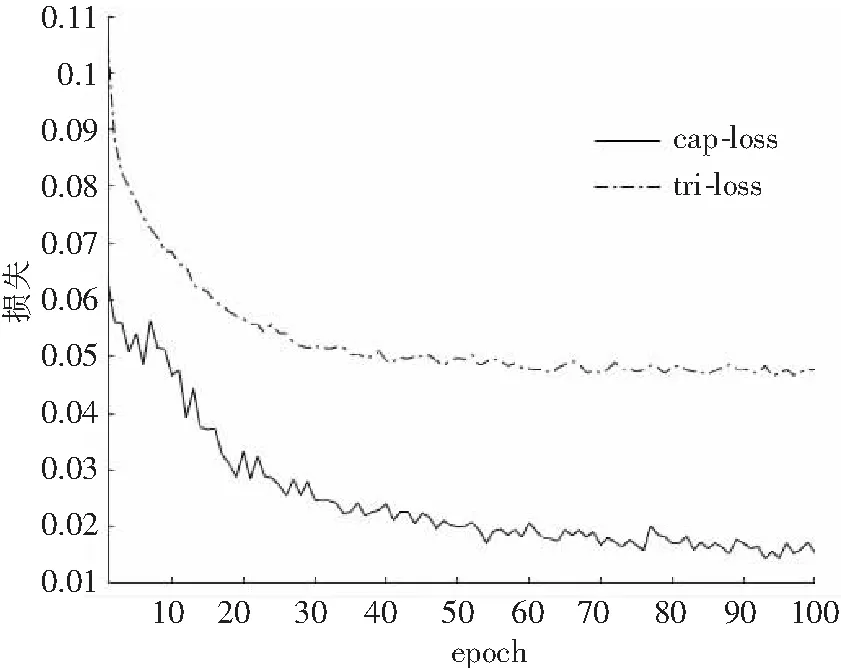
图4 损失 vs epoch
