LT码的一种非阶梯化高斯消元译码算法
2019-04-24贺亮,雷菁,黄英
贺 亮,雷 菁,黄 英
(国防科技大学 电子科学学院,湖南 长沙 410073)
0 引言
为了避免多播系统中,多个终端向发端反馈重传信息时的反馈风暴,相关学者提出了喷泉码的编码方案[1-3],通过喷泉编码,可以生成理论上无穷多个编码符号,因此喷泉码也被称为无码率码。Luby提出的LT码[4]是首个可以具体实现的喷泉码,其编码符号是信息符号的线性组合。Shokrollahi提出Raptor码[5],通过在LT码前加上固定码率的信道编码,使其能够在噪声信道下发挥更出色的性能。目前喷泉码在数字视频广播标准[6]以及3GPP中都有应用。
LT码最初建立在二元删除信道(BEC)上,其译码属于硬判决译码,主流的2种算法是置信传播(BP)算法和高斯消元(GE)算法。原始的高斯消元并没有实现实时译码,在文献[7-9]中相关学者进一步提出了可渐进实现的高斯消元算法。针对BP算法译码开销大的问题,有学者提出BP算法与高斯消元结合的方法[10-12],国内有人提出了增强型BP算法[13],以及一种BP与最大似然译码结合的BPMLE算法[14]。
高斯消元算法是LT码的一种最大似然译码方法,能够最小化译码开销,但其复杂度也较高。提出一种可以降低复杂度的高斯消元算法,在LT译码的过程中,使用该方法进行矩阵化简,不需要实现阶梯化,同时结合BP算法,使其能够实时渐进的译码。
1 LT码的硬译码
1.1 编码原理
LT编码器将固定数量的信息符号生成理论上无穷数目的编码符号。编码符号的度分布是设计LT码的关键,符号的度,即该符号拥有的连接的数目。度分布可以用多项式表示为
(1)
G·sT=yT。
(2)
1.2译码原理
通常假定接收端已知编码的生成矩阵,那么译码就是在接收到编码符号的情况下,恢复出信息符号的过程。两大主要方法为BP译码和高斯消元(GE)译码。
1.2.1 BP译码
在接收的编码符号中,找到一个度数为1的符号yi,将其值赋给唯一相邻的信息符号sj,即sj=yi,则该信息符号得到恢复,并将对应的这条连接删除。此后,所有与sj相连的编码符号与sj异或,并随后将连接删除。在这之后,继续在编码符号中寻找度数为1的,重复上述步骤,若不存在度为1的编码符号,则接收端需要更多的编码符号,将接收到的符号与已经恢复的信息符号异或更新后删除连接,再按上述步骤进行度数1符号搜索,使BP译码能够继续进行,直至所有信息符号恢复。
1.2.2 GE译码
高斯消元译码首先对生成矩阵和接收符号构成的增广矩阵进行三角化,若成功,则回代方程组可求解出信息符号。三角化是将增广矩阵转化为上三角形式,若该过程失败,说明需要更多的编码符号,然后三角化需要重新进行。原始的GE失败后,并不保留处理后的矩阵,实际上,文献[7]中增量的高斯消元算法(incGE)才是实用的高斯消元译码。设信息符号的数目为k,增量高斯消元在刚接收到k个编码符号后,仅执行一次三角化,将原始的生成矩阵G简化为G′,若三角化不完全,译码失败,但保留G′。在G′中,“优行”指那些最左方“1”在对角线上的行,“劣行”则是不符合该情况的行。首次三角化中以及之后在接收更多编码符号时,增量高斯消元通过行变换,尽可能地将劣行转换为优行。当接收到足够多的符号时,三角化将完全实现,此时再对方程回代,即可恢复出所有的信息符号。
定义译码开销
ε=1-n/k,
(3)
式中,n为译码成功时接收的编码符号数目。实验验证已经表明,对于任意的k,incGE算法的译码开销均明显大于BP算法,且其开销随着k的增大收敛于0的速度更快。在译码复杂度方面,BP算法的较低,为O(klb(k)),incGE的复杂度则相当于一次高斯消元,为O(k2)。
1.3 非阶梯化高斯消元
本文提出的高斯消元是一种非行阶梯化的消除方法,非阶梯化高斯消元(NEGE)在BP算法遇到停止集时,将所有未消除连接符号对应的矩阵,进行矩阵简化,简化符号之间的连接,使得简化后的矩阵有再次进行BP译码的可能。
(2)高校教师数据知识。根据调查结果显示:数据基础知识掌握方面,利用统计数据进行相关知识的教学占比76.6%,经常、偶尔通过书籍等渠道了解或者专门学习数据如何分析占比分别为63.3%与20%;对于数据工具使用情况,60%的高校教师使用数据分析工具超过三个,而Excel、SPSSS 使用率高达63%以上,相反地,SAS、R、Python、Stata 等软件使用极低,其中最高占比16.7%。从这两方面来看,内蒙古高校教师使用统计软件的能力较弱,使用工具较单一。但数据基础知识方面情况良好,单这一方面可看出,内蒙古高校教师数据知识在逐步积累。
该算法在矩阵层面的实现是:译码开始时首先应用BP算法,找到权重为1的行,对应的编码符号的值将被赋予给其唯一的邻接信息符号,此后这些行上的1置0,表示连接删除;而这些新恢复的信息符号,将要与它们的邻接编码符号异或,进一步删除这些连接,即将1置0;然后,将在寻找权重为1的行重复上述步骤。当找不到权重为1的行时,再利用高斯消元,完毕后寻找权重为1的行,进行BP译码。若经过上述所有步骤,信息未完全恢复,则接收更多的编码符号,将接收的符号与已经恢复的编码符号之间可能存在的连接消除,并更新编码符号,依上面步骤进行BP和高斯消元的联合译码。非阶梯化高斯消元算法如下:


其中,M(i,j)表示M的第i行第j列元素,用“:”表示对矩阵或向量整行、整列的引用。函数isemtpy(·)判断变量是否为空,为空则返回1,“~”表示逻辑非,’row’代表按行求和,函数size(·)为返回矩阵的行列数,sum(·)为求和函数。
所提的NEGE相比原始的方法在复杂度上有明显的降低。首先,选取某一行对其他行作消除时,采用了选取权重最小行的策略。在高斯消元过程中,对行的处理是从顶行到底行进行,对列则是从最左至最右。传统的高斯消元,在选取基准行对其他行做消除时,选取是均匀随机的。而所提的NEGE则选取权重最低的作为基准,这样可以降低其他行在消除后的权重,进而减少行操作的次数。其次,由于高斯消元后会应用BP译码,因此行阶梯的特点可以舍弃。原始的高斯消元使得每行最左方的1依次呈阶梯状,这样就需要对基准行进行行交换。NEGE在选取基准行后,保持其位置不变,可以避免行交换操作。
NEGE译码示例如图1所示。

图1 NEGE译码示例
以Tanner图表示符号之间的连接关系,圆形为信息符号,方形为编码符号。在图1(a)中,Y1,Y2,Y6是新接收到的符号,S6,S7是已经恢复的信息符号。新符号首先与S6,S7异或更新连接,然后进行BP译码直到图1(b)遇到停止集BP无法继续。提取剩余连接,进行NEGE如图1(c)所示。在图1(d)中,可以观察到符号之间的连接已经简化,BP译码可以再次展开。
2 仿真结果
不失一般性,令1个符号代表1 bit。仿真信道为二元删除信道,同样假设信道删除率为0。本节给出BP算法、incGE算法以及NEGE算法的仿真结果。度分布采用文献[4]中的鲁棒孤子分布(RSD),RSD的δ参数设置为0.05,所有结果都在1 000次蒙特卡洛仿真下平均得到。
图2给出了3种算法的开销ε与信息符号长度k的关系,且RSD的c参数有3个不同值0.01,0.1,0.5。可以看出,NEGE的译码开销与incGE相同,因为二者都最大限度地利用了生成矩阵。此外,NEGE和incGE随着k的增大开销趋于0的收敛速度显著快于BP算法。在c=0.01及c=0.1的情况下,BP算法2条曲线的差距显著大于NEGE之间的,且BP算法最上方的曲线在k较小时还出现了波动。因此NEGE算法的性能对度分布的选择敏感性远远小于BP算法的,若选择NEGE算法,度分布的精细设计可以在较大程度上忽略。
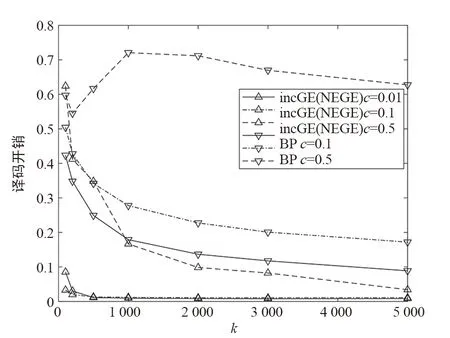
图2 RSD下不同参数c的开销
图3给出了3种算法的复杂度,以异或操作、行交换的总数作为指标,RSD的参数选为δ=0.05,c=0.1。3种算法均在刚接收到符号时就开始译码。可以看出,BP算法的复杂度是最低的,与k成线性增长。而incGE的复杂度最高,相比之下,NEGE的复杂度明显降低。若对于接收方来说,计算能力能够支持高斯消元的负担,同时最大限度地降低译码开销,那么提出的NEGE是一个不错的选择。

图3 BP,incGE,NEGE的复杂度
3 结束语
提出了非阶梯化的高斯消元算法,在选择某一行作为基准行对其他行进行消除时,采取了选择权重最小行的策略,该策略减小了后续行操作的数量,相比原始的高斯消元,复杂度大大减小。当BP算法遇到停止集无法继续进行时,提取出未处理的符号,进行非阶梯化高斯消元,简化后的连接关系使得再次BP译码成为可能。从而对LT码译码,能够显著降低译码开销,使得度分布的设计在该算法下居于次要。在接收端计算能力能够保证的前提下,NEGE算法是一种较好的选择。
