基于主题一致性和情感支持的评论意见领袖识别方法研究
2019-04-24胡俊阳
安 璐,胡俊阳,李 纲
1 武汉大学 信息资源研究中心,武汉 430072 2 武汉大学 信息管理学院,武汉 430072
引言
近年来,突发事件的爆发往往在社交媒体上引发大量关于该事件的播报和讨论。在这些社交媒体信息中,意见领袖在引导事件的网络舆情走向方面发挥着重要作用。现有对网络意见领袖的研究绝大多数是分析针对某一事件发表微博并在网络中产生一定影响力的博主,很少有研究涉及对博主的博文进行评论的高影响力评论用户。现在有一种普遍现象,即博主博文的评论区有许多网友根据自己的立场和看法进行讨论,在讨论过程中产生观点的分化并形成代表人物。根据两级传播理论[1],意见领袖通常是作为信息与受众者的中间传递人,因此可以将扮演中间传递人角色的评论区代表用户视为评论意见领袖。与普通网络意见领袖直接针对事件发表微博不同,评论意见领袖活跃于微博的评论区,结合事件和博主博文的内容发表评论,并与其他网民产生交互,评论观点可能会影响他人判断、改变他人认知。发现评论区的意见领袖是发现网络意见领袖的一种新思路,本研究通过识别与评论主题一致且情感上支持的回复,构建评论意见领袖识别体系,并探讨评论意见领袖的行为特征,为管理部门寻求在公共事件中如何利用网络意见领袖有效引导网络舆情的策略提供参考。
1相关研究评述
1.1意见领袖识别
意见领袖的概念最早是由LAZARSFELD et al.[1]于20世纪50年代提出,他们认为意见领袖不仅是信息的提供者,还在一定程度上能够对他人产生影响;HOLLANDER[2]于1961年提出一种新的定义意见领袖的方法,即意见领袖最好是以其影响追随者态度和行为的能力来定义;ROGERS[3]总结了意见领袖的特点,并认为意见领袖必须为他人做出示范。相对于普通群众,意见领袖的特点在于拥有更高的社会地位、更好的教育背景、更强的应对挑战的能力[4]。意见领袖不仅将普通群众的注意力集中于特定问题,而且能暗示群众应该以怎样的回应和行动面对该问题[5]。发展至今,对于意见领袖有许多不同的定义,但是所有定义的核心都集中在意见领袖的“中介”作用上。传统上,意见领袖社会地位更高,并与社会事务大量接触,他们比非领袖更频繁地注意新闻媒体的内容[6]。意见领袖可以是社区、群组或社会中有影响力的成员,他人可向其寻求建议、观点和看法[7]。意见领袖能够塑造他人想法,并且对普通群众具有影响力[8]。意见领袖的影响过程类似于一个金字塔,一些极有影响力的人占据了顶层,其影响力作用于下层的群众[9]。
目前,即时通信工具功能不断改进,与天涯论坛等传统网络社区功能相融合,随着Twitter、新浪微博等带有即时性特点的社交应用的兴起,出现了越来越多的网络平台使网络意见领袖充分发挥其自身影响力,豆瓣、新浪微博、网易新闻等网络应用也逐渐成为网络意见领袖聚集的空间[10]。网络意见领袖是指将互联网作为主要的活动场所,通过互联网技术支持的各项服务为普通网民提供意见和信息,能够回答网民在某些领域提出的问题,在网民之中具有一定影响力,并在特定时间、空间条件下能够制造和引领社会舆论的一类人[10]。国外对网络意见领袖的研究早于中国,不仅提出基于在线社区网站的网络意见领袖影响力扩散模型[11],还以商品的推广情况为例分析发现网络意见领袖所具有的明显不同于传统意见领袖的特征[12]。中国对网络意见领袖的代表性研究类型主要有采用数据挖掘等方法筛选网络论坛舆论领袖并从多个维度刻画论坛舆论领袖的特点[13]、构建指标体系以建立舆论领袖影响力传播模型[14]、识别社交网络意见领袖[15]。
考量每一次公共事件的网络舆情演化过程,几乎都有网络意见领袖参与其中并发挥重要作用[16]。目前国内外对网络意见领袖的研究主要针对其在电子商务活动中的作用,认为意见领袖能够影响消费者的消费倾向[17]。虽然有学者从微博评论出发识别微博转发网络中的意见领袖[18],但是对微博评论的研究仍非常少见。相对于现有对意见领袖的研究,本研究以微博评论为研究对象,在已有研究思路的基础上加入回复与原评论的主题一致性,再结合评论回复的情感支持,识别微博评论中有影响力的意见领袖。
1.2微博文本主题分析
对微博文本的主题发现方法可以大致概括为文本聚类法和主题模型法两大类。相比较而言,由于文本聚类方法是基于统计层面的,很难解决文本中一词多义以及歧义的问题,而主题模型方法对隐含在文本中的主题建模,能够克服文本聚类方法中文档相似度计算方法的缺点,因此主题模型方法在文本主题发现中应用较多[19]。基于潜在狄利克雷分配(latent Dirichlet allocation,LDA)模型的主题发现在微博文本主题发现的研究中较为瞩目。LDA是一种3层贝叶斯概率模型,通过无监督的学习方法发现文本中隐含的主题信息[20]。许多学者对LDA的应用进行拓展。LDA-SVM短文本分类流程是将LDA主题模型和SVM分类器结合起来,使用LDA主题模型对短文本的特征项进行扩展,然后将扩展后的特征向量代入到SVM分类器中进行分类[21];以标签对潜在主题的贡献为出发点,通过Gibbs算法将标签映射到具有特定意义的主题上也是一种行之有效的LDA潜在主题发现方法[22]。由于传统LDA主题模型是根据词语在某一个主题下的概率高低来判断词语与主题的相关性,而实际上LDA模型识别出的主题及其包含的词语可读性欠佳。鉴于基于Relevance公式改进的LDA主题模型[23]中的theta矩阵可确定文档-主题的分布、phi矩阵可确定主题-词语分布矩阵,且引入的权重参数λ可用于调节词语与主题之间的相关性,因此本研究采用可以改善主题可读性的基于Relevance公式改进的LDA主题模型,并通过LDAVis[23]进行可视化分析,判断评论与其回复的主题一致性。
1.3微博文本情感分析
情感分析,又称意见挖掘,由PANG et al.[24]在2002年提出,通过对文本进行语义分析判断文本的情感极性,主要包括正面、负面、中立3种情感态度。基于情感词典的分析方法和机器学习方法是最为常见的两种情感分析方法[25]。基于情感词典的分析方法的核心在于“词典”,很大程度上依赖于词典的质量,目前中国学者在研究微博平台数据时常用的情感词典有台湾大学NTUSD中文情感极性词典、大连理工大学情感词典[26]、HowNet情感词典等。在基于机器学习的情感分析中经常使用朴素贝叶斯[27]、支持向量机[28]、最大熵模型[29]等经典分类模型,其中多数分类模型的性能依赖于标注数据集的质量,而获取高质量的标注数据需要耗费大量的人工成本[30]。综合上述讨论,本研究采用基于情感词典的分析方法。此外,网民经常在微博评论及回复中使用表情符号以辅助自身情感的表达,然而随着网络文化的不断变化,微博表情符号的现实含义早已与微博平台对表情符号的定义大相径庭,如“微笑”表情符号本意是用以表达友好亲切,现在多用于嘲讽、无言的情绪表示。因此,本研究构建与当下网络文化情绪传递相吻合的表情符号词典,作为情感词典的补充。
1.4意见领袖特征指标
许多学者从不同角度构建意见领袖特征体系对潜在意见领袖进行评估。传统上,主贴数、回帖数、总跟帖数是常见的意见领袖特征指标,在此基础上,根据研究对象和研究角度的不同,特征指标的选取也出现一些差异。响应值测量用户对意见领袖的响应类型和响应强度[31];活跃度、认同度、关注度分别用于揭示意见领袖的发帖频率、受其他用户认同情况和观点的影响扩散程度[14];支持力则是其他用户对意见领袖支持程度的体现[32];平均回复长度、平均被回复长度等量化指标也从侧面反映意见领袖与其他用户的交互[33];还有学者采用威望度测量意见领袖自身影响力的效应[34]。已有研究对意见领袖特征指标的选择通常会考虑用户本身影响力等因素,并且尽可能涵盖意见领袖所有方面的特征,以期识别结果准确度更高。本研究并非从用户自身影响力出发,而是从用户评论内容出发,探讨评论内容造成的实际影响力。本研究选取的意见领袖特征指标包括获点赞数和获回复数2个1级指标,以及获回复数下的直接获回复数、间接获回复数、直接回复数3个2级指标,以此评估评论意见领袖的影响力。
2研究框架和方法
2.1研究框架
通常,用户发布的微博可能收到若干评论,而每条评论又可能得到若干回复。微博的评论和回复结构见图1。主题分析有助于了解用户的观点,情感分析有助于识别用户的情感极性。本研究基于主题一致性和情感支持构建研究框架,包括数据收集和预处理、评论主题获取、主题校正、情感计算、意见领袖值计算5个步骤,见图2。
数据收集和预处理阶段的主要工作是利用网络爬虫获取新浪微博评论及其评论回复数据,经过预处理后的语料集留作下一步使用;评论主题获取阶段主要使用基于Relevance公式改进的LDA主题模型获取微博评论的主题;主题校正阶段是将每条评论与其回复结合,再次使用基于Relevance公式改进的LDA主题模型进行主题分类,并通过LDAVis进行可视化分析,利用多维尺度分析法剔除与评论主题不相关的回复;情感计算阶段基于情感词典和扩展词典,计算每条评论和回复的情感值,以此确定回复用户对评论用户的情感支持态度;意见领袖值计算阶段构建意见领袖特征值指标体系,采用标准离差法确定各指标的权重,根据评论用户意见领袖值的高低确定意见领袖。
2.2基于Relevance公式改进的LDA主题分析
LDA是BLEI et al.[35]在2003年提出的一个主题模型。为了改善主题的可读性,使用基于Relevance公式改进的LDA主题模型对微博评论进行潜在主题提取和主题校正。给定一个权重参数,Relevance计算公式为
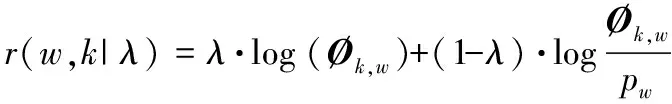
(1)
其中,w为词语,w∈{1,…,V};k为主题,k∈{1,…,K};λ为权重参数,0≤λ≤1;r(w,k|λ)为在指定的λ下,词语w与主题k的相关程度;Øk,w为主题k下词语w出现的概率分布矩阵;pw为词语w在主题-词语矩阵Ø中的边际概率。通常使用变分贝叶斯方法或吉布斯抽样以及pw计算Ø。可以用λ调节词语与主题之间的相关性,如果λ接近于1,主题词语的选择是基于在主题下出现越频繁的词语与主题更相关这一思想,即为传统的LDA主题关键词选择方法[36];如果λ越接近于0,在该主题下更特殊、更独有的词语与主题更相关,即在该主题下出现的次数较多但在其他主题中很少出现的词语跟主题更相关。
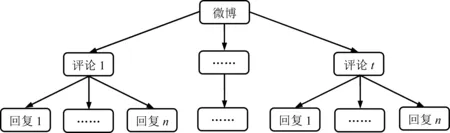
图1微博评论和回复结构Figure 1Structure of Microblog Comments and Responses
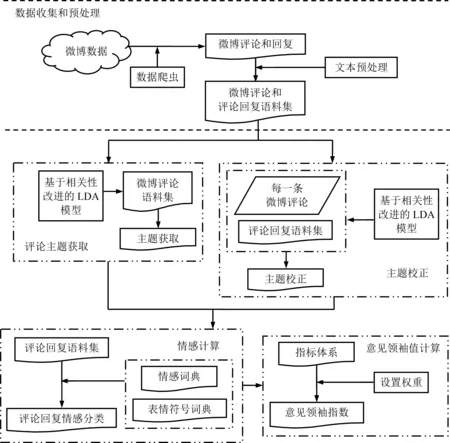
图2基于主题一致性和情感支持的意见领袖识别总体框架Figure 2Opinion Leader Identification Framework Based on Topic Consistency and Emotional Support
2.3基础情感词典及扩充
本研究通过选取基础情感极性词汇、表情符号、否定词和双重否定词等特征,对微博评论和回复信息进行情感分类。基础情感极性词汇采用台湾大学中文情感极性词典(NTUSD)中被标记为positive和negative的词表,以及安璐等[37]在情感分析相关研究中构建的中文微博情感词典;表情符号特征通过构建微博表情符号词典进行匹配;否定词和双重否定词则参考王勇等[38]构建的否定词典和双重否定词典。
微博平台上的表情符号比语言更直观,它是微博用户经常用来辅助情感表达的一种工具。本研究分析新浪微博自带的表情符号的极性,在已构建好的表情符号词典[39]的基础上,结合新的网络环境下表情符号的增加和表情符号的情感转变,构建微博表情符号词典。部分新增的表情符号和情感极性发生变化的表情符号见表1。
在汉语表述中经常用到否定词及其多种组合。当使用否定性词语修饰某一词语时,该词的情感极性将发生改变,因此通常使用否定词来表达不同的情感态度;双重否定词语主要表现形式是连用两个否定性词语,与否定性词语不同的是,双重否定有表达肯定、强化语气等功能。构建否定词典时结合实际语料补充21个否定词,新增否定词包括不到、不该、不行、不会、不借、不去、不算、不提、不想、不知、从来不、否、很少、极少、没能、没人、没想到、没用、千万别、勿、只不过。

表1部分新增表情符号和特殊表情符号Table 1Some Newly Added Emoji and Special Emoji
2.4微博评论及其回复情感计算
目前许多研究的情感分析涉及到多种情绪分类,如喜、怒、哀、乐等,本研究主要从情感是否支持的角度识别意见领袖,因此对情感倾向性的分析简化为正面情感极性和负面情感极性。本研究认为表情符号表达的情感与情感词表达的情感同样重要,并将表1中的正面情感表情符号与正面情感词汇融合,标注其情感极性值为1;将负面情感表情符号与负面情感词汇融合,标注其情感极性值为-1。使用(2)式修正若干个否定词修饰的情感词的情感极性,即
s′(wi)=(-1)φs(wi)
(2)
其中,wi为第i个情感词,s′(wi)为经否定词修饰后新的情感词极性值,φ为否定词的个数,s(wi)为wi的初始情感极性值。
微博评论及其回复的总体情感值计算公式为
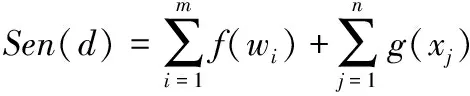
(3)
其中,Sen(d)为评论及其回复的总体情感值,等于该条微博评论或评论回复的情感词语总情感值与表情符号总情感值之和;m为情感词的个数,i=1,…,m;f(wi)为wi经否定词修饰后得到的情感修正值;n为表情符号的个数,j=1,…,n;xj为第j个表情符号;g(xj)为xj的情感值。
2.5意见领袖识别方法
HOLLANDER[2]认为,意见领袖能够影响追随者的态度和行为,ROGERS[3]认为意见领袖须为他人做出示范,WEIMANN[5]认为意见领袖能够将普通群众的注意力集中于特定问题,且暗示群众应如何回应该问题。因此,本研究借鉴以上学者的研究,将主题一致性和情感支持纳入评论意见领袖识别,即要求评论意见领袖既能持续获得同一主题回复又受到他人的情感支持。由于本研究以评论为切入点,识别的是评论区的意见领袖,考虑到用户在评论区与他人的交互,引入直接获回复数、间接获回复数和直接回复数3个指标。
首先,使用基于Relevance公式改进的LDA主题模型对微博评论进行潜在主题提取,确定各评论所属主题。然后,分别将每条微博评论与其接收到的回复结合,在LDA主题建模之后利用LDAVis包生成一个可视化的主题模型,揭示主题下词语的显著性和词语-主题相关性,利用多维尺度分析法提取出主成分的维度,将主题分布到这些维度上,主题相互之间的位置远近表达了主题之间的接近性[40]。通过评论所属主题节点与其回复所属主题节点之间的距离,删除主题相关度较低的评论,实现主题校正。之后再基于情感词典和扩展词典,计算每条评论及其回复的情感值,以此确定回复用户对评论用户的情感支持态度。在意见领袖值计算前构建意见领袖特征指标,包括获点赞数和获回复数2个1级指标,以及获回复数下的直接获回复数、间接获回复数和直接回复数3个2级指标。意见领袖判定标准和特征指标具体结构见表2,获点赞数指1条评论获得的点赞数,获回复数指1条评论获得的总回复数。

表2意见领袖特征指标设置和判定标准Table 2Characteristic Indices Setting and Criterion for Opinion Leaders
评论与回复之间的局部结构见图3,①为B回复A,即A的直接获回复;②为C回复B,即A的间接获回复;③为A回复B,即A的直接回复;④为B回复C,即A的间接获回复;⑤为C回复A,即A的直接获回复;⑥为A回复C,即A的直接回复。
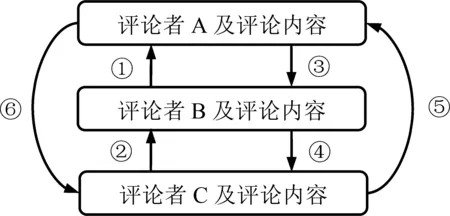
图3评论与回复的结构示意图Figure 3Structure for Comments and Responses
根据图3,本研究给出3个2级指标的含义。直接获回复数指其他用户对该评论回复的数量,直接获回复数=①+⑤+类似回复类型;间接获回复数指发生在该评论下但交流双方不包括评论作者的回复的数量,间接获回复数=②+④+类似回复类型;直接回复数指该评论作者对他人的回复又进行回复的数量,直接回复数=③+⑥+类似回复类型;获回复数=直接获回复数+间接获回复数+直接回复数。
标准差能反映一个数据集的离散程度[41],通常某个指标的标准差大小反映了其提供的信息量的大小,从而决定该指标在综合评价中所起的作用和权重分配。本研究采用标准离差法确定各指标的权重,首先,以极值法对由指标组构成的数据矩阵的每列(即每个指标)数据进行无量纲化处理;其次,依据标准差计算方法确定获点赞数和获回复数2个指标的标准差;最后,根据1个指标的标准差占所有指标标准差之和的比重计算该指标的权重。
由于1条评论的获回复数等于该评论的直接获回复数、间接获回复数和直接回复数之和,因此本研究保留获点赞数和获回复数2个1级指标赋予权重计算意见领袖值,根据评论用户意见领袖值的高低确定意见领袖。意见领袖值的计算公式为
Val=W1·L1+W2·L2
(4)
其中,Val为意见领袖值,W1和W2为指标对应的权重,L1和L2为经无量纲化处理后的获点赞数或获回复数的值。直接获回复数、间接获回复数和直接回复数用于分析意见领袖值排名靠前的用户的特征。
2.6意见领袖行为特征分析
本研究从用户主页基本信息和用户评论内容属性两个角度,探讨评论意见领袖的行为特征。在用户主页基本信息方面,关注用户的微博账户创建时间、当前等级、是否取得微博认证、关注数、粉丝数、发表微博数等,以此判断该用户的活跃度和基础影响力;在用户评论内容属性方面,除统计评论获点赞数、获回复数(包括直接获回复数、间接获回复数和直接回复数)的数值之外,还充分讨论直接获回复数、间接获回复数和直接回复数3个2级指标之间的相关性。综合上述两方面的研究,以实验和数据支撑探讨评论意见领袖的行为特征。
3实验设计和分析
3.1实验数据和预处理
本研究以山东辱母杀人事件为例,将“山东辱母”作为关键词,利用网络爬虫获取在新浪微博平台上2017年3月1日至2017年12月1日期间所有热门微博的评论及该评论对应的回复信息,得到2 014条评论的53 564条回复数据。通常意义上,只有接收到他人的回复的评论用户才可能成为意见领袖,因此需要剔除评论接收到的回复数为0的用户,经初步清洗后,最终有1 547条评论的26 676条回复数据,平均长度约51个字符。
采用R语言结巴分词[42]对清洗后的数据进行分词。由于原用户词典的不完善,没有收录“山东辱母”事件相关词汇、网络流行用语和法律词汇等,因此本研究首先选用搜狗词库中的搜狗日常用语大词库、搜狗网络流行新词、搜狗法律词汇大全,再结合图悦生成的辱母事件高频150词,将上述步骤得到的51 319个词汇一同纳入用户词典并导入分词系统,分词效果得到极大提升。实验使用哈尔滨工业大学停用词表、四川大学机器智能实验室停用词库和百度停用词等结合的1 893个停用词构成的停用词典删除停用词。
3.2主题识别与校正
在对所有评论进行分词操作后,利用基于Relevance公式改进的LDA主题模型确定各主题下的特征词。主题的个数由困惑度确定,对于不同主题训练出来的模型,计算其困惑度,最小困惑度对应的主题个数就是最优的主题数。经试验最优主题数为20,分别为:司法判决与道德舆论的平衡(V1);微博平台在本案中起到的作用(V2);别有用心的人煽动群众情绪(V3);致敬于欢的忠孝,舆论应保护他(V4);法律应保护儿子护母的孝顺行为(V5);法律丢失了道德底线(V6);中小企业融资困难向高利贷借款(V7);人民的血性被剥夺(V8);案件背后存在“警匪一家”等问题(V9);案件暴露的问题上升到更高层面(V10);出警民警及案件审判人员信息(V11);出警民警的处理结果存在争议(V12);不满以法官为代表的法院的判决(V13);警察对民事纠纷敷衍了事、渎职(V14);法院冤判,能否相信法律与正义(V15);于欢案量刑过重应轻判(V16);鼓励遭受不公的人反抗(V17);为不公正事件发声,敢于奋起反击(V18);聊城市全面调查案件背后公务人员的问题(V19);严厉打击山东省内涉黑行为等(V20)。
经反复试验,λ=0.6时各主题之间距离最大,主题词语的选取效果最好。这20个主题可以分为5个大类:V1和V2期望以法律形式保护于欢权益;V3、V4、V8和V11对此次事件涉及到的政府公务人员的行为展开讨论;V13和V19关注舆论如何推动此次事件的发展;V16鼓励群众为不公正事件发声;V5、V6、V7、V9、V10、V12、V14、V15、V17、V18和V20探索本案背后更深层次的问题,如法律完善、贷款制度、司法公正等,围绕全面调查并严厉打击山东省内公务人员涉黑、渎职、贪腐等问题发表意见。
按照上文描述的主题校正方法,对每条评论收到的所有回复进行主题一致性筛选。首先,将经预处理后留下的1 547条评论分别与其对应的回复结合,形成1 547份评论-回复结合的数据文件;其次,利用基于Relevance公式改进的LDA主题模型和LDAVis,将这些数据文件一一做可视化展示;最后,在可视化结果的基础上判断每个数据文件中评论与回复的主题一致性,识别不相关的回复并将其删除。删除不相关回复的规则如下:①若获回复数不超过100,则删除与评论主题距离最远的一个主题的特征词所构成的最相关回复;②若获回复数多于100但不超过1 000,则删除与评论主题距离最远的两个主题的特征词所构成的最相关回复;③若获回复数多于1 000,则删除与评论主题距离最远的3个主题的特征词所构成的最相关回复。对所有回复内容进行主题一致性筛选后,与对应评论主题保持一致的回复的数量为25 535条。
同时,将没有进行主题校正的数据保留,以在后续处理中进行对比实验。
3.3情感计算
基于情感词典及其扩展,本研究采用上文的情感计算方法,将各主题下每条评论对应的回复信息进行情感分析,各主题下获得支持和反对态度的评论数量分布见图4。
结合实际数据可以看出,由于对出警民警的处理结果存在很大争议,因此有关主题V12的评论也引起广泛讨论,一部分网民认为出警警察玩忽职守,而另一部分网民认为警察处理并无不妥,双方争执不下导致在这一主题下很难有一个统一的意见。以警察的行为为切入点,许多网民分享了自己遇到的报警无果事件,牵扯出的与主题V9相关的“警匪一家”问题也引起了极大的争论。基于此,有网民呼吁严厉打击山东省内涉黑行为(主题V20),同时聊城市也发出公告,将全面调查于欢杀人护母案件背后公务人员的问题(主题V19),但是多数网民对此并不抱有期待。除此之外,一些网民质疑于欢母亲向高利贷借款的非法行为,但更多的网民认为是银行贷款制度的苛刻和缺乏人性化的设置导致于欢母亲求助于高利贷的做法,而这一现象背后透露出中国中小企业融资困难及难以生存的现状(主题V7)。民众的信任缺失极易引发社会矛盾,需要意见领袖理智发声,引导网民以正确且积极的心态看待问题,因此识别网络评论意见领袖具有至关重要的意义。通过情感分析,本研究筛选出824个候选意见领袖。
3.4意见领袖值计算
意见领袖特征指标包括获点赞数和获回复数2个1级指标,以及获回复数下的直接获回复数、间接获回复数和直接回复数3个2级指标。指标体系构成的数据矩阵在经过无量纲化处理和标准差计算后,确定了获点赞数和获回复数的权重,分别为0.469和0.531。按照意见领袖值从高到低排序,前10名意见领袖见表3,No.1103评论用户和No.958评论用户的意见领袖值远高于其他评论用户。
结合实际数据可知,排名第1的No.1103评论用户获点赞数为58 000,获回复数为1 680,其中直接获回复数为912,间接获回复数为675,直接回复数为93。No.1103评论用户获点赞数在所有评论者中是最高的,获回复数在所有评论者中排名第2,综合这两个指标分析,该用户无疑是一个具有影响力的意见领袖。No.1103评论用户的直接获回复数和直接回复数在所有评论者中是最大的,说明该用户与回复用户之间互动较多;其间接获回复数在所有评论者中排名第4,高于平均水平,即其他用户与回复用户之间也有较多交流。核对No.1103评论用户的评论内容可知,该评论用户的观点在于于欢护母的忠孝,认为无论是社会还是法律都应保护于欢,并鼓励人们敢于发声,许多回复用户用点赞和回复的方式表示支持。No.1103评论用户与回复用户之间的讨论基本上达成了共识,这也说明大多数网民对于欢抱以同情的心理,理解于欢的行为。鉴于上述讨论,识别No.1103评论用户为一名意见领袖是无争议的。
No.958评论用户获点赞数为33 112,获回复数为2 282,其中直接获回复数为678,间接获回复数为1 604,直接回复数为0。No.958评论用户的获回复数在所有评论者中是最高的,获点赞数在所有评论者中排名第3,该用户在这两个指标上的表现均处于较高水平。No.958评论用户的直接回复数在所有评论者中是最小的,表明该用户很少与回复用户进行交流。此外,该评论用户的直接获回复数在所有评论者中排名第3,间接获回复数在所有评论者中排名第1,这也说明该评论用户的评论易引起不同观点之间的相互讨论。核对No.958评论用户的评论内容可知,该评论用户重点讨论出警民警及案件审判人员信息,关注聊城市对此案件的调查,对案件处理尤为重视,并且几乎不与回复用户进一步交流。回复用户针对案件的处理情况发表了不同的看法,相互之间因观点不同而产生许多争论。从回复用户的回复内容可以看出,许多网民关注公检法系统在此次案件中的行为,期待正义的声音不会被淹没。因此,No.958评论用户是一个能够引导其他用户思考的意见领袖。
结合实际情况考量,识别出的其他评论用户在本次事件中基本上均发挥了意见领袖应有的作用。此外,通过对比实验,对没有校正主题的回复进行情感计算和意见领袖值计算,发现对比实验识别出的、但原实验未识别出的一些意见领袖,其回复者出现偏离评论主题转而讨论其他事情的现象,回复者与评论者讨论的不是一个主题,这种情况下的评论用户不应视为意见领袖。因此,只考虑情感支持不考虑主题一致性的对比实验存在缺陷,不能有效识别真正的意见领袖,而本研究提出的基于情感支持和主题一致性的方法弥补了这一缺陷。
3.5评论意见领袖行为特征探讨
通过对1级指标与用户基本信息(包括微博账户等级、是否取得认证、关注数、粉丝数、发表微博数等)之间的相关性检验,发现在置信水平为0.010时,获点赞数与微博账户等级、是否取得认证、关注数、粉丝数、发表微博数等均不存在显著相关性,获回复数与这些用户基本信息也均不存在显著相关性。因此,评论用户的自身影响力不一定对评论的实际影响力产生作用。
本研究还对意见领袖特征指标之间的相关性进行分析,从而揭示了意见领袖的行为特征。在置信水平为0.010时,直接回复数与直接获回复数之间存在显著的弱相关性,直接获回复数与间接获回复数之间存在显著的强相关性,直接回复数与间接获回复数之间存在显著的弱相关性。结合实际情况可初步得出以下推论:评论者的直接回复在一定程度上引起更多的回复者再次回复,从而增加一定数量的直接获回复数;回复者的间接回复是在直接获回复的基础上产生,即直接获回复是间接回复的存在条件,直接回复数与间接获回复数两者之间存在强相关性不难理解;直接回复需经过直接获回复作用于间接获回复,直接回复数与间接获回复数之间的相关程度较低。
综上所述,本研究提出的基于主题一致性和情感支持的网络评论意见领袖识别方法并不局限于只考虑用户自身影响力,而是着重关注评论内容以及用户之间的交互,是一种新的识别网络评论意见领袖的方法。此外,构建的意见领袖特征体系中的3个2级指标能够反映评论意见领袖的行为特征。
4结论
本研究提出一种基于主题一致性和情感支持的网络评论意见领袖识别方法,以山东辱母杀人事件为例,使用基于Relevance公式改进的LDA模型和情感词典,筛选与评论主题一致且情感上支持评论者的回复,并根据意见领袖指标体系最终确定具有正面和负面高影响力的微博评论意见领袖,同时从用户主页基本信息和用户评论内容属性两个角度,探讨评论意见领袖的行为特征。
研究结果表明,本研究提出的方法能够识别评论区的意见领袖,评论内容的效应与用户概况之间没有显著的相关性,提出的网络评论意见领袖识别方法并不局限于只考虑评论者自身的影响力,而是着重关注评论内容本身以及用户之间的交互。评论者的获点赞数和获回复数等指标可以作为评论者成为评论区意见领袖的基础,而根据直接获回复数、间接获回复数和直接回复数之间的相互作用可勾勒出用户在交互中的行为特征。
本研究结果能够为突发事件管理部门提供网民对事件的关注焦点和情感态度,有助于其及时掌握网络舆情,通过识别、引导正面评论意见领袖积极发声减少消极情绪,通过引导负面评论意见领袖合理回应存在的问题避免情绪的极端化乃至事件恶化,为后续的应对管理提供理论和方法支持。
本研究也有一定的局限性,即识别的评论意见领袖没有考虑时间因素,缺乏事件发生期间高影响力评论用户的观点演变分析,后续将尝试增加时间这一因素,探索不同时间段内意见领袖的观点构成,进而识别是否存在具有影响力但观点不同于之前意见领袖的“意见扭转者”;以山东辱母案为例,本研究结果的分析是针对该事件的微博数据展开,该结论在其他突发事件中是否成立还有待验证,因此还需结合多类型事件探讨结论的普适性;情感词汇的情感判断方面,可能会出现情感词汇在词汇表中的情感极性与实际表达中不同的问题,未来将在研究中引入反讽计算等方法。
