基于半监督谱聚类的通信网台识别方法*
2019-04-23丁天一方胜良
丁天一,张 旻,方胜良
(国防科技大学电子对抗学院,合肥 230037)
0 引言
在未来信息化战争中,敌方通信网台的识别将是战场态势分析的重要研究内容。随着侦察手段的提高,数据库中积累了大量杂乱无章的通信侦察数据,如何有效地从参数级数据中挖掘出有用知识,得到通信网台间的通联关系,完成通信网台识别,成为了一个亟待解决的问题[1-2]。
文献[3]提出了一种基于粗糙集理论进行侦察数据融合处理的方法,利用中心频率、调制样式和电台位置作为关键属性进行同一电台的通信记录合并,但由于侦察数据存在误差,满足条件的可能是一个通信网内的其他电台。同时,该方法通过某一时刻电台的平台经度、平台纬度和平台高度定义的等价关系来对电台库的记录进行分类,如果电台存在航迹交叉势必会造成误判;文献[4]提出了使用统计距离及DBSCAN算法用于通信电台关联,但该算法仅对电台的位置信息进行聚类,没有考虑其他属性的影响,电台间位置分布相近时很难做出正确判断,存在较大误差;文献[5-7]提出了一种基于灰关联分析和粗糙集的通信电台识别方法,利用粗糙集理论进行等价类划分得到电台航迹后,把电台航迹与雷达航迹进行关联,判断电台与装载平台的关系,但该算法不能判断哪些电台在一个通信网内进行通信。
本文首先介绍了谱聚类算法和成对约束信息的相关概念,然后分析利用谱聚类算法进行通信网台识别的合理有效性,并充分利用知识库中已有的约束条件,提出了一种基于半监督谱聚类的通信网台识别方法。首先,通过密度峰值的方法确定通信网数目;然后通过半监督谱聚类的方法完成通信网台识别。实验结果表明,本文提出的方法可以有效地完成通信网台识别。
1 相关概念
1.1 谱聚类算法
谱聚类算法来源于谱图的划分理论,核心思想是将数据的聚类问题转化为一个无向图的多路划分问题。谱聚类将数据集中的每个样本点看作图中的顶点V,顶点之间用边E连接,其权重为样本点间的相似度W,由此构造出了一个基于样本相似度的无向加权图G(V,E),聚类问题就转化为图G的最优划分问题,划分准则就是使划分成的子图内部相似度最大,子图之间的相似度最小。
谱聚类算法的实现方式有很多,但都可以归纳为以下3个步骤:1)根据相似度函数构造相似度矩阵,并计算得到Laplacian矩阵;2)计算Laplacian矩阵的前k个特征向量,构建特征向量空间;3)采用k-means等聚类算法对特征向量空间进行聚类。
相比于传统的聚类算法,谱聚类算法能够识别非凸分布聚类,收敛于全局最优解,适用于许多实际问题[8]。
1.2 成对约束信息
聚类是一种典型的无监督学习方法,然而在现实的聚类任务中往往能获得少部分数据的先验知识。因此,可以通过半监督聚类的方法利用这些具有先验知识的数据来辅助聚类,获得更好的聚类效果。对于用户来说,要确定样本类属会比较困难,而获得一些关于样本点是否可以或不能位于同一类的约束信息将会比较容易[9]。
若两个数据点为must-link,则这两个数据点必须在同一聚类中;若两个数据点为cannot-link,则这两个数据点必须分配在不同类中。must-link和cannot-link这两类成对约束作为样本的先验信息在实际聚类中是非常容易得到的,但是一般数量有限,因此,需要对这些成对约束进行扩展。Klein等人提出must-link和cannot-link在样本上具备一组二值传递关系:
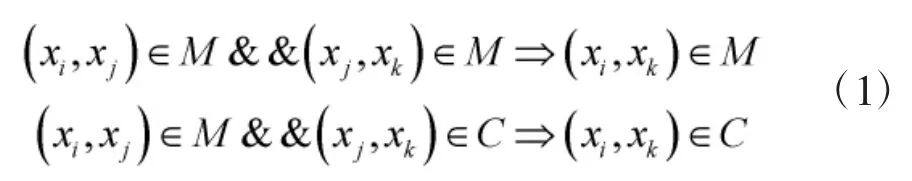
式中,M和C分别表示must-link和cannot-link的约束集[10]。
利用上述传递关系,通过数据集中的成对约束信息,可以得到数据集的闭包关系。属于同类闭包的数据点互为must-link,属于异类闭包的数据点互为cannot-link。通过现有的成对约束求同类闭包和异类闭包,可以扩展must-link和cannot-link这两类成对约束的数量,从而最大化地利用成对约束信息。
2 通信网台识别
通信侦察的主要目的是通过对敌方通信信号的搜索、截获、记录、测向定位、技术参数测量,解调和监听通信信息等作业,获取敌方通信信号内涵信息及技术参数,查明敌方通信电台分布、活动规律及隶属关系,提供战略与战术决策情报。通信侦察数据信息表如下页表1所示[3]。
2.1 基于聚类分析的通信网台识别
通信网台识别面临的主要问题有:数据的迅速更新使得数据库中积累了大量杂乱无章的侦察数据难于分析;知识库中不具备足够的完整数据用于一般有监督学习算法的学习过程。
聚类算法能够通过无标记的样本来揭示数据的内在性质及规律,将聚类算法用于通信网台的识别和分析,能够在已有知识匮乏的情况下,发现隐藏在其中的内在联系,有效判断通信网台间的通联关系。
2.2 半监督谱聚类
传统的聚类算法,如 k-means、k-medoids、模糊c均值等算法的聚类结果依赖于数据的分布,对于趋于球形分布的数据集能够取得一个较好的聚类结果,但是对于不规则形状数据集,聚类结果较差[11-12]。由于电台目标分布的复杂性,传统聚类算法的这一特点可能会带来结果上的较大偏差。例如,电台目标在地理位置上的分布会依据任务部署呈现出不规则分布,尤其在目标的转移过程中可能会形成弯曲的带状分布。此时,传统的聚类算法不再适用。因此,本文选取具有识别非凸分布聚类能力的谱聚类算法,聚类结果能够收敛于全局最优解。
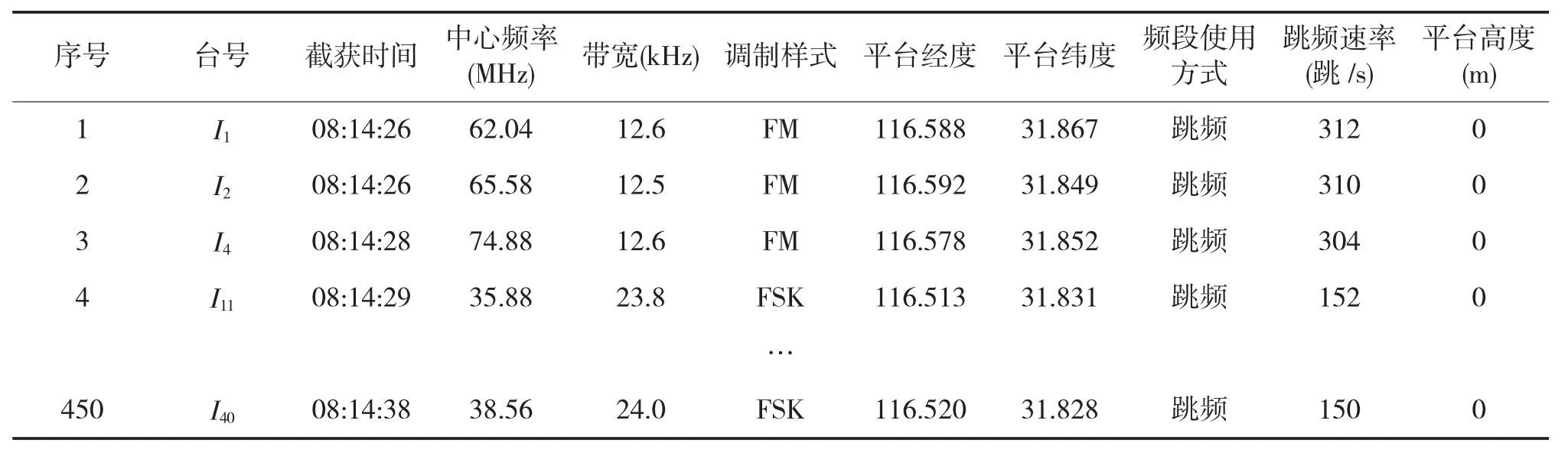
表1 通信侦察数据信息表
谱聚类是一种基于配对的聚类算法,使得在算法中利用成对约束信息变得非常容易。通过侦察方已有的少量先验知识,可以得到部分通信电台间的通联关系,以此作为must-link和cannot-link约束。将通信侦察数据投影到二维平面,并添加成对约束信息,如图1所示。
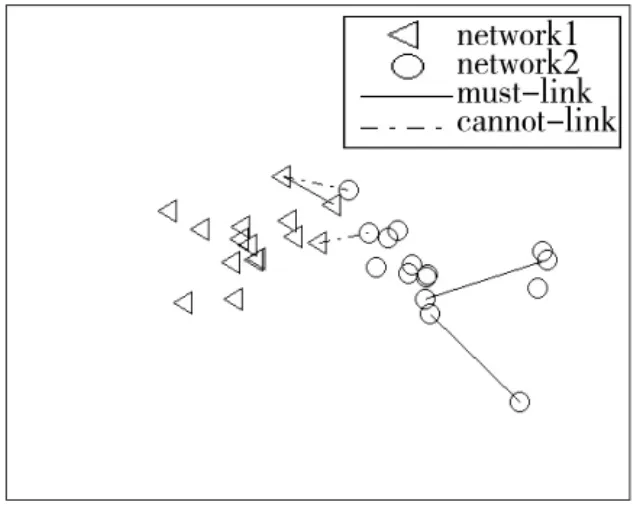
图1 添加成对约束信息
由图1可以看出,通信网1和通信网2的部分通信侦察数据样本相似度很高,难以区分;通信网2中的部分通信侦察数据样本与同类别中的其他样本相似度较小。在这种情况下,如果仅凭借无监督的聚类分析方法进行通信网台识别,结果经常会造成误判。如果能够根据侦察方已有的先验知识,添加少量的成对约束信息辅助聚类,以半监督聚类的方法来判别通信侦察数据样本的类属,就能够有效地将不同通信网的通信电台区分开,从而提高通信网台识别准确率。
3 基于半监督谱聚类的通信网台识别方法
3.1 基于密度峰值的通信网数目确定
在通信网台识别之前,首先需要判断通信网的数目。密度峰值的方法可以自动发现数据集样本的类簇中心,从而得到类别数目,其基本原理是理想的类簇中心应具备两个基本特征:1)其局部密度大于围绕它邻居的局部密度;2)不同类簇中心之间的距离相对较远[13]。
定义1(局部密度ρi)局部密度ρi采用高斯核的方法进行计算,计算结果满足与xi的距离小于dc的数据点越多,ρi的值越大,如式(2)所示:
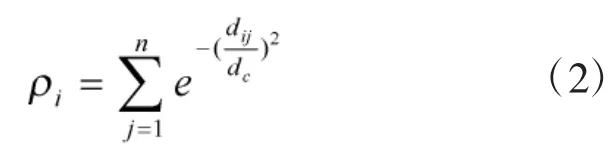
其中,dij为样本xi与xj间的欧氏距离,dc为截断距离。
定义2(相邻密度点距离δi)在所有局部密度大于xi的数据点中,找到与xi距离最小的数据点,其与xi之间的距离即为相邻密度点距离δi,如式(3)所示:
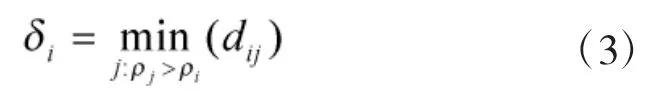
对于局部密度ρi最大的样本xi,其。
由样本xi的相邻密度点距离δi的定义可见,若样本xi的密度是最大局部密度或最大全局密度,则样本xi的距离δi远大于其最近邻样本的相邻密度点距离。因此,类簇中心往往是δ异常大的样本点,这些样本点的局部密度ρ也相对较高。通过构造获胜神经元相邻密度点距离δ相对于局部密度ρ的决策图,选择ρ、δ都较大的点作为类簇中心,类簇中心的数目就是样本的类别数。具体步骤如下:
Step 1:计算所有样本间的距离dij。
Step 2:确定截断距离dc。将上一步计算的n个样本的距离dij进行升序排列,假设得到的升序序列为,则截断距离dc为:

其中,t是每个样本点的邻居样本点的平均个数占数据集样本点总数的百分比,round(nt)表示对nt四舍五入后得到的整数。
Step 3:根据式(2)计算每一个样本的局部密度ρi,将样本按照局部密度由高到低进行排序。
Step 5:根据ρi和δi构成的关系决策图,中点的分布位置,以“最上最右”的点为起点,按照“向下向左”的原则,找到与剩余点差异最大的一组点,这组点的ρ和δ都较大,并且明显偏离剩余点所构成的密集分布区域,这组点的数目即为类别数k。
文献[13]中给出dc的选择策略是使每个样本点的邻居样本点的平均个数是数据集样本点总数的 1%到 2%,即 t∈[0.01,0.02],本文将参数 t设置为0.02。
3.2 谱聚类相似度矩阵构造
为了能够更好地适应样本数据可能出现的不均匀分布,本文采用了文献[12]提出的相似度矩阵构造方法:
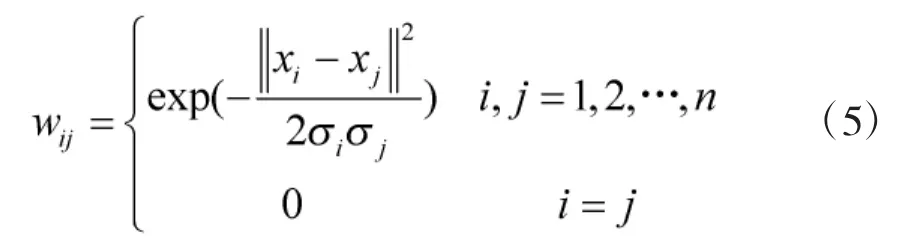
3.3 基于成对约束的半监督谱聚类
在某些特殊情况下,侦察方对通信侦察数据的情报分析过程中,可能具备一定量的先验知识,这些先验知识可能来自于对个别侦察目标的细致分析、对敌方通信装备的掌控、长久以来侦察方知识库积累的知识,以及情报分析人员对战场环境和侦察数据的分析判断等诸多方面。先验知识作为判别通信电台间通联关系的重要约束条件,可以用来指导通信侦察数据的情报分析过程。
战场区域内,同一个通信网内的所有通信电台在进行通信的过程中一定会满足以下基本条件:通信电台的工作频率属于同一个频段;通信信号的调制样式和通信体制等技术参数相同;通信电台在通信时间上存在交叉。如果在某一相同工作时间段内,某些通信电台不在同一频段工作、调制样式不同或通信体制不同,那么这些通信电台一定不在一个通信网内。
同时,通过知识库中已有的先验知识以及通信辐射源个体识别等方法,可以得到部分电台间的通联关系,以此作为must-link和cannot-link约束。
在获得样本间的成对约束后,通过修改相似度矩阵的方法来施加成对约束信息,按照式(6)的方法更新约束点间的相似度:

得到更新后的相似度矩阵之后,继续执行谱聚类的算法步骤,完成对通信侦察数据样本的聚类。
3.4 算法步骤
输出:通信侦察数据X的聚类结果。
Step 1:符号型属性数值化,并采用式(7)的最小-最大规范化的方式进行数据预处理。
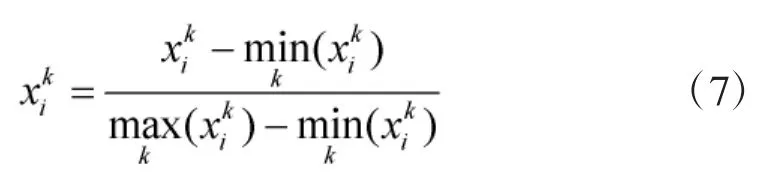
Step 2:通过密度峰值方法构造决策图,找到明显偏离剩余点所构成的密集分布区域的一组点,点的数目即为通信网数目k。
Step 3:根据式(1)的传递关系,通过初始成对约束集合M,C扩展成对约束关系。
Step 4:根据式(5)建立相似度矩阵W。
Step 5:按照式(6)的方法根据成对约束信息更新约束点间的相似度。
Step 6:计算规范化Laplacian矩阵L:

其中,D为W的度矩阵,对角线上的元素为W每行元素的和,表达式为。
Step 7:求解规范化Laplacian矩阵L的前k个最大特征值所对应的k个特征向量,建立矩阵,其中vi为列向量。
Step 8:对V的行向量规范化处理,得到单位长度向量组成的新矩阵Y,其中,。
Step 9:将Y的每一行看成是Rk空间内的一点,使用k-means算法把n行数据划分为k类。
Step 10:当矩阵Y的第i行在类Aj中时,划分原样本空间中的样本到Bj类中。
4 实验结果与分析
仿真实验以现有的外军战术电台的技术参数为依据,按照表1通信侦察数据信息表的构成方式,模拟生成通信侦察数据进行实验。通信侦察系统一般是由分布在侦察区域内的多个地面、升空等侦察设备组成,因此,在某一侦察时间段内,对于每一个通信电台可能有多条通信侦察数据的记录。在对通信侦察数据的聚类分析过程中,由于通信信号参数的复杂性,可能会造成一个通信电台的多条侦察数据被划分到不同的类别中。为此,在通信侦察数据的聚类分析实验中,本文采取择多法的判别方式来确定通信电台的类属,即如果某通信电台的大多数通信侦察数据被划分到某一类中,那么就将此通信电台的类属确定为该类。
仿真的场景为在一个短时间段内,侦察区域内有4个通信网内的共50个超短波电台正在进行通信,通信电台的地理位置相对固定,通信电台的类型为美军的SINCGARS电台。仿真截获了400条通信侦察数据,侦察记录内容如表2所示。
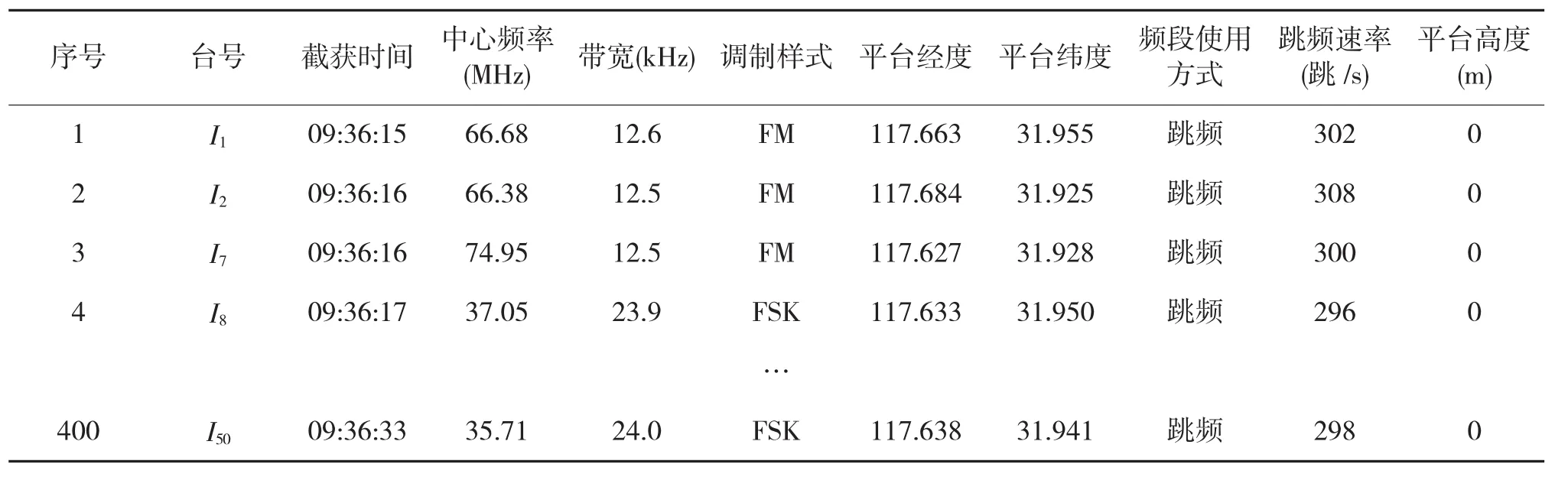
表2 通信侦察数据信息表
依据通信侦察数据的经度与纬度参数可以得到通信电台的地理位置分布,如图2所示。
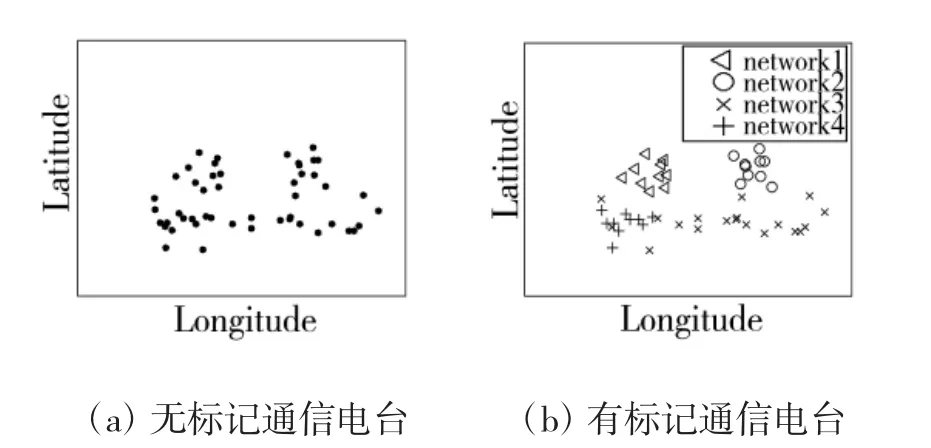
图2 通信电台地理位置分布
从图2(a)可以看出,通信电台的地理位置分布较为复杂,仅凭借地理位置分布很难区分属于不同通信网的通信电台。从图2(b)可以看出,不同通信网的通信电台在地理位置上分布相近,通信网3和通信网4的部分通信电台在地理位置上存在交叉,同时通信网3的通信电台形成了非凸的带状分布。
为了验证基于半监督谱聚类的通信网台识别方法的有效性,本节设计了两个实验。实验1在不具备约束条件的情况下分别采用k-means算法和谱聚类算法对通信侦察数据进行聚类分析,通过比较无约束条件下两种算法的聚类结果,验证选取谱聚类算法作为半监督聚类中使用的聚类算法的合理性。实验2在具备一定量约束条件的情况下,采用半监督谱聚类算法对通信侦察数据进行聚类分析,实验中增加不同数量的成对约束,通过比较不同数量成对约束下聚类结果的正确率验证本文方法的有效性。
实验1:无约束条件的聚类分析
实验1在侦察方不具备先验知识的情况下对通信侦察数据进行聚类分析。首先,采用k-means算法对通信侦察数据进行聚类实验,得到的3次聚类结果如下页图3所示。
由图3可以看出,由于k-means算法初始聚类中心的不确定性,即便在指定聚类数目的情况下,也会造成重复实验过程中聚类结果的多样性,不同聚类结果差别较大,使得通信网台识别率较低。
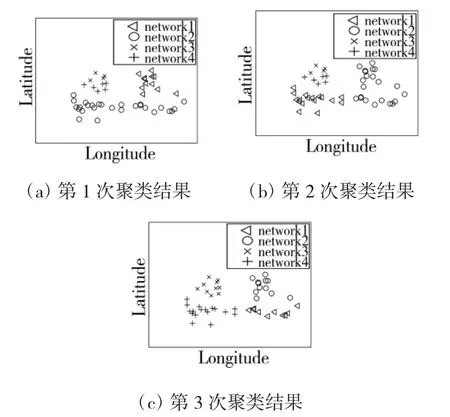
图3 k-means算法聚类结果
下一步,采用本文方法对通信侦察数据进行聚类实验。在对通信侦察数据进行数据预处理后,通过密度峰值方法得到的决策图如图4所示。
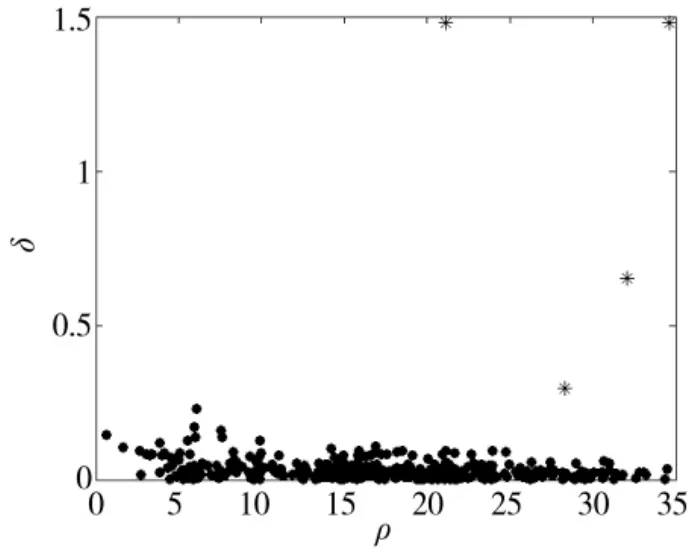
图4 决策图
密度峰值方法得到的决策图中有4个点明显偏离于剩余点所构成的密集分布区域,因此,指定通信网的数目k=4。在不添加任何成对约束信息的情况下,采用谱聚类算法对通信侦察数据进行聚类实验,得到的聚类结果如图5所示。
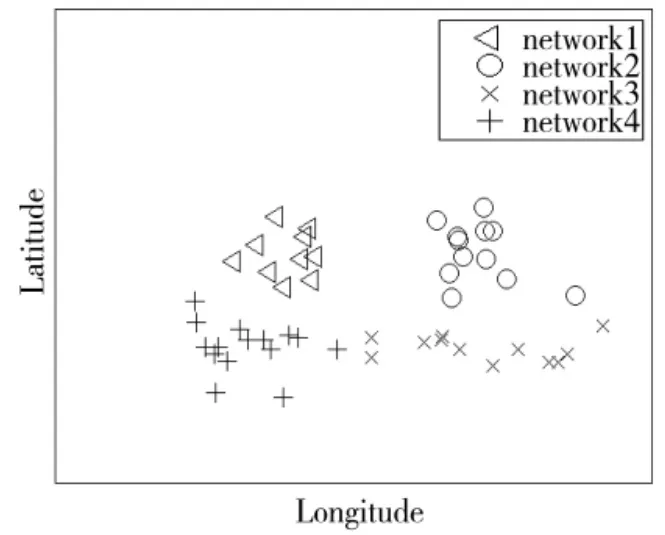
图5 谱聚类算法聚类结果
由图5可以看出,谱聚类算法对通信侦察数据进行聚类后,得到的聚类结果的正确率要高于k-means算法的3次聚类结果,50个通信电台中有43个通信电台得到了正确的聚类结果,聚类正确率为86%。
实验2:有约束条件的聚类分析
实验2在具备一定量先验知识的情况下对通信侦察数据进行聚类分析。假设根据侦察方所具备的先验知识,可以得到通信电台间成对约束的数目分别为25、50和75时对通信侦察数据进行聚类分析。由于所选的通信电台以及通信电台间约束的不同对聚类算法的性能有很大影响,所以对于每一个给定的成对约束数目产生50组不同的成对约束,以此重复进行50次实验,输出聚类结果的平均正确率,实验结果如图6所示。
由图6可以看出,在增加了成对约束之后,通信侦察数据聚类结果的正确率有了提高,并且随着约束对数目的增加,聚类结果的正确率呈上升趋势。实验结果表明,本文算法可以充分利用先验知识,有效提高通信侦察数据聚类分析的正确率。
5 结论
通信侦察积累了大量的通信侦察数据,如何从海量侦察数据中挖掘出有用价值的信息,从而判别电台间的通联关系,是战场态势分析的重点。本文提出了一种基于半监督谱聚类的通信网台识别方法,通过密度峰值的方法判别通信网的数目,然后借助于已有的先验知识,通过半监督谱聚类方法对通信侦察数据进行聚类,得到最终的聚类结果。实验结果表明,本文算法可以充分利用具备的先验知识,有效地完成通信网台识别。
