基于改进近邻传播算法的Walsh软扩频盲解扩方法
2019-04-23李丞,张玉
李 丞,张 玉
(国防科技大学电子对抗学院,合肥 230037)
0 引言
扩频系统通信是数字通信领域的核心技术之一。该技术最初作为抵抗干扰和截获威胁的手段而用于军事通信系统。随着研究的不断深入,该技术在抑制干扰、增强通信的安全性检测和处理、适应衰落和多径通道、提供多址接入能力等方面的优势越来越引人注目,并逐渐应用于民用、商用领域。目前主流扩频系统是直接序列扩谱系统、跳频扩谱系统[1]。而由于传统扩频技术存在伪随机码率较高、占用频带较宽问题,难以满足新型通信系统,故逐渐使用软扩频技术。
为改善传统单一序列直扩技术频谱效率低的问题,软扩频技术是将直接序列扩频技术和编码技术相结合,发展一种新型的基带扩频技术,在军民用通信上得到应用。相比较传统直扩系统和跳频系统,软扩频技术不但适用于频带受限且数据传输速率高的通信系统,而且在相同射频带宽、相同信息速率、相同扩频增益条件下,该系统性能更佳[2]。但目前关于针对软扩频盲解扩的算法较少。文献[3]中提出了一种高斯白噪声信道下基于K均值据类的软扩频盲解扩方法。但该方法需要较大的数据集合规模以及较高的算法复杂度。文献[4]提出一种基于蚁群聚类的软解扩方法。该方法在低信噪比条件下可以有效进行解扩估计,并具有较低算法复杂度。但在处理大规模数据集合时,盲解扩成功率没有明显提升。文献[5]提出的基于K均值聚类算法的多进制扩频系统伪码序列估计方法。该方法虽可有效降低算法复杂度,但由于编码特性原因,算法容易陷于局部最优。针对以上问题,本文提出一种基于改进近邻传播算法的Walsh软扩频盲解扩方法,并通过仿真结果验证了该方法的有效性。
1 软扩频中的Walsh码
1.1 Walsh码产生
美国数学家J.L.Walsh在1923年提出了Walsh函数。由于每个函数仅有两个可能的取值,即+1和-1,因此,是一种完备的二值正交系。如果把N个Walsh函数组成的集合定义为一个Walsh函数系,表示如式(1):
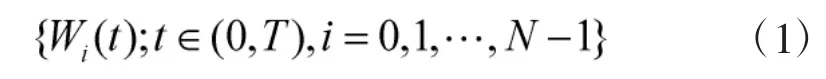
那么该函数系具有以下性质:
1)对于任意一个i,Wi(0)=1;
2)Wi(t)在区间(0,T)内具有i次符号变化;
3)任意两个Walsh函数具有正交性:
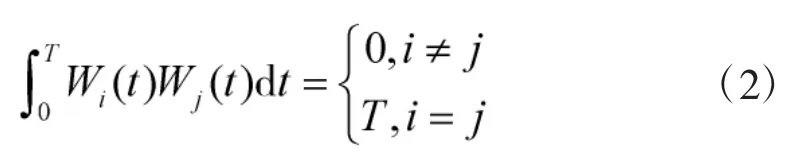
Walsh函数具有良好的正交特性,拉马赫(Rademacher)函数是其主要产生方法之一,即对于,有

式中,tk为1或者0。
Rademacher函数又可以由哈达码(Hadamard)矩阵构成。Hadamard矩阵是一个方阵,矩阵的第1行、第1列始终为+1,而且矩阵的行和列相互正交。二阶Hadamard矩阵可以如下表示:
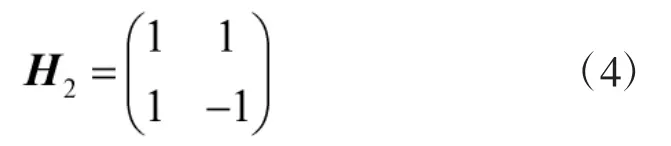
通过递推得到高阶矩阵如下表示:
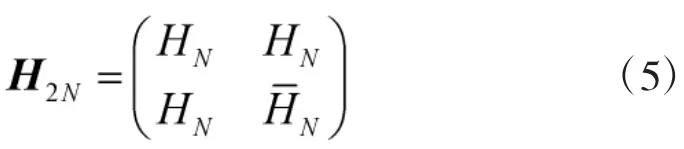
式中,HN为HN的互补矩阵。要生成Walsh序列,通常对Hadamard矩阵做如下变换。Walsh序列的每行都与Hadamard矩阵一一对应。当软扩频系统采用16位Walsh码,其与4位信息码的映射关系如表1所示。
1.2 软扩频技术
软扩频技术是将直扩和信道编码技术结合,以实现频谱扩展。其本质是将k bit信息码元一一映射到长为N的伪随机序列,完成(N,k)编码扩频。扩频增益定义为。相比于直扩而言,其扩频增益值较小。
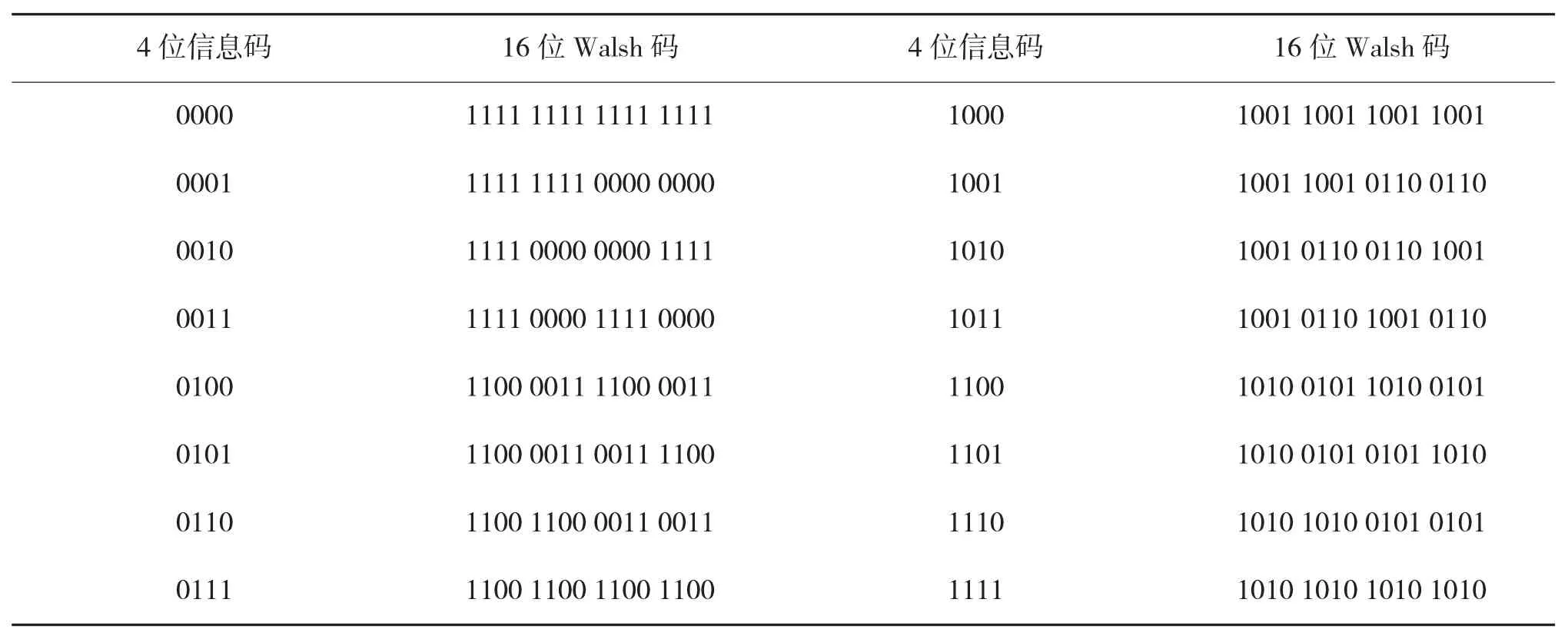
表1 Walsh码字映射表
假设发送的信息为:
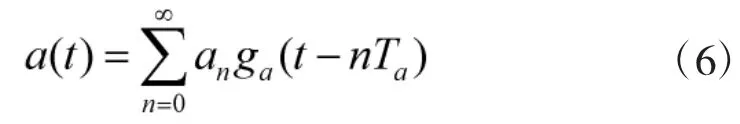
式中,an表示信息码元;ga(t)表示门函数,当时,为信息码元宽度。
将a(t)以k为长度对信息码进行分组,可得:
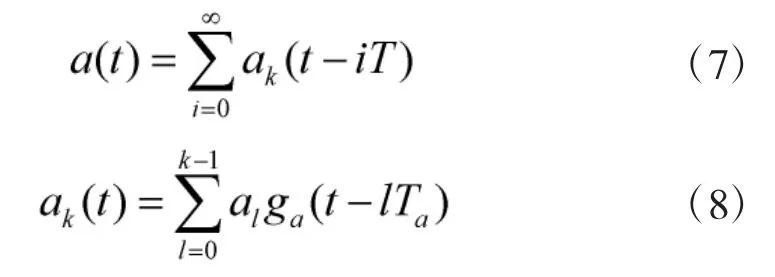

式中,m表示k位信息码2k个状态对应的伪随机码的标号。用cj(t)来表示伪随机码,则可以写为:
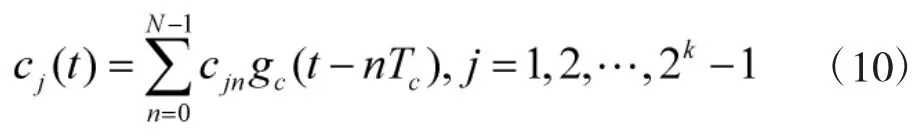
式中,cjn表示伪随机码的码元。因此,得到的扩频序列表示如下:
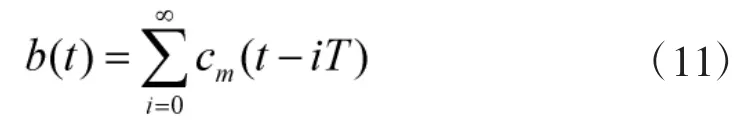
式中,cm(t)下标选择由式(4)确定。
那么接收得到受高斯白噪声影响的软扩频信号可表示为:
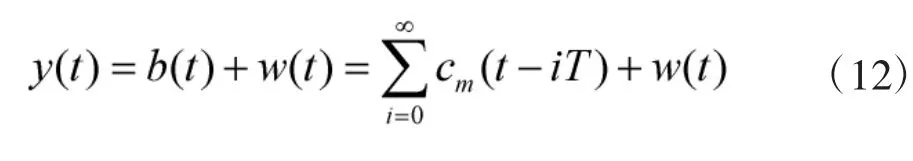
2 近邻传播聚类算法及改进
2.1 信号模型建立
假设在软扩频系统中,伪码速率Tc和扩频因子N已经通过参数估计法进行估计,即已知的离散信号序列可表示为:
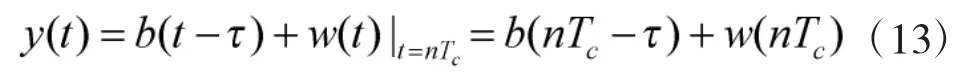
再把离散的信号序列分成互不重叠的若干段,每段含有N个采样值,即
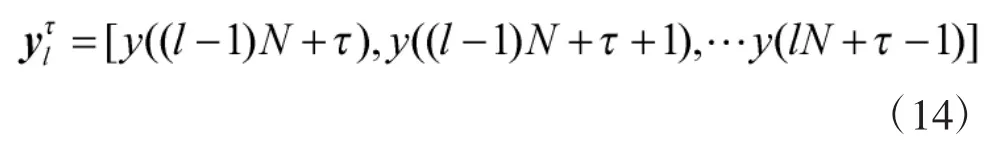
式(10)表示向量在聚类算法中称为一个对象,L个这样的对象可以构成输入数据集合[5]。且由上式发现,对于对象集合的软扩频信号伪码序列进行盲估计,需要对信号延时与伪码规模进行有效估计。
2.2 信号时延估计
由于软扩频序列之间信号具备非周期互相关的非正交性,故传统的自相关矩阵最大Frobenius范数准则并不能进行信号时延估计。
文献[4]提出一个软扩频信号延迟时间估计方法,步骤如下:
2)对自相关矩阵R(k)右上角(不包括对角线元素)从大到小进行排序;
根据已知的Walsh码特性,非同步状态下的Walsh码互相具有较差的正交性。因此,在上步骤中的循环搜索,存在输入数据集合Y()中任意两个对象不相等,使得s1减小,同时也不正交,使得s2变大。即当统计量处在峰值时,估计值k可作为估计延迟时间。
2.3 改进近邻传播聚类算法的伪码规模估计
近邻传播聚类算法是一种基于近邻信息传播的聚类算法,该算法的目的是找到最优的类代表点集合,使得所有数据点到最近的类代表点的相似度之和最大。但与K中心算法不同,近邻传播聚类根据数据点的相似度信息进行传播,得到最优类带标点进行优化,并在初始类代表点的选取进行优化[5]。本文算法为聚类数目未知类优化法。
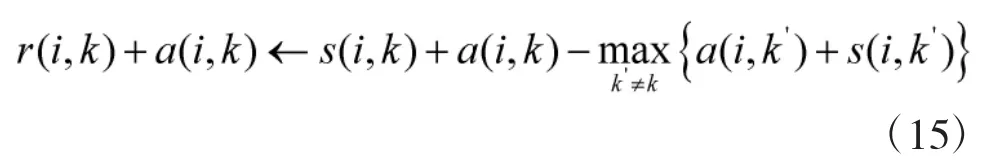
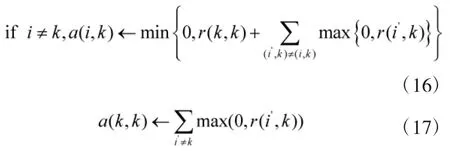
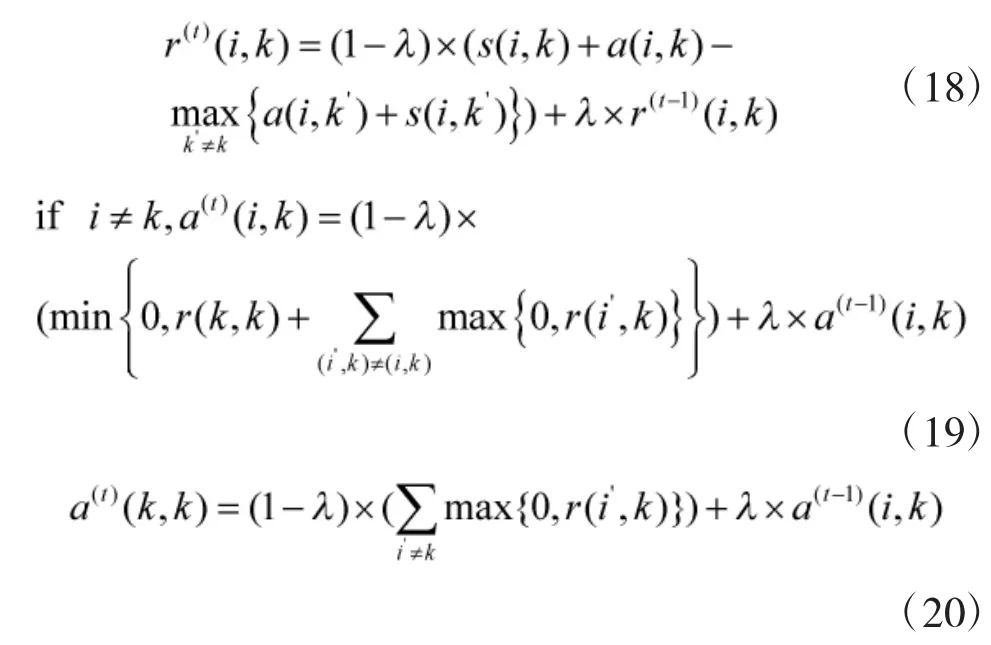
在本文估计过程中,为了抑制噪声对估计结果的影响,在计算各聚类代表点吸引度与归属度值时,把算法中的阻尼因子调整至0.8。同时,在聚类过程中,将xk改为xk+δ(δ为相邻两点欧式距离均值)。引入此两点改进后,可加快算法聚类归并速度,减少运算量,同时可以有效降低噪声的敏感度,减少噪声干扰。
考虑到已经估计出信号时延,经调整采样时间点,可取得同步数据结构为。若同步数据集合Y表示为尚未聚类数据,伪码集合规模及伪码序列的估计过程如下:
1)将初始L个样本各自分类,共L类,设定p为计数值,初始值为1;计算任意相邻两点欧式距离均值,并初始化,并初始化;
3)在所有点信息量更新后,求出相应点的求和信息量xk
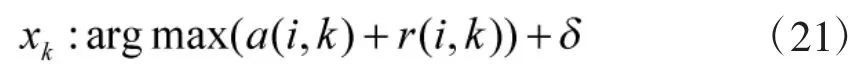
并计算各路径上的信息量。设t为聚类半径,tik是Wi类到Wk类聚类距离,可有

4)若tik=1,则Wi归并于Wk邻域,类别数减1。归并后得到新类,J为新类中对象的总数。设置k为聚类S的聚类中心,p加1;
5)提取出所有类,返回步骤3)重新计算,并判断有无归并,是否有迭代过程不稳定,迭代数目是否超过阈值。若无上述问题,则完成聚类。
在算法聚类结束后,得到的迭代计数器p即为伪码集合规模,归并得到的类S中包含的点即为聚类中聚类中心,也就是伪码集合。二者估计得到后,通过Walsh码与信息码之间的映射关系可得到信息序列,即完成Walsh码系统中软扩频的盲解扩。
3 算法性能比较
3.1 改进算法复杂度分析
3.2 改进算法仿真实验与分析
3.2.1 改进近邻传播聚类算法的仿真实验
下面举例对算法进行仿真实验。假设周围噪声为零均值高斯白噪声且信噪比为-2 dB,通过已有的估计时延,调整采样时间,以长度为128的数据窗样本采样,得到同步采样数据集合Y,样本数目为100。
下页图1和图2分别为估计出的伪码序列和原始的伪码序列。从图中可以看出在零均值高斯白噪声条件下,采用本文算法能准确地估计出Walsh软扩频信号的伪码序列和伪码集合规模。在估计得到伪码后,通过阈值分析法得出相应的原始伪码序列。
3.2.2 改进近邻传播聚类算法的性能分析
聚类算法对伪码进行估计时,主要受到信噪比以及对数据提取时其规模的大小,因此,需要分别对两个因素进行考虑。本文性能分析将以算法的误码率作为衡量标准。
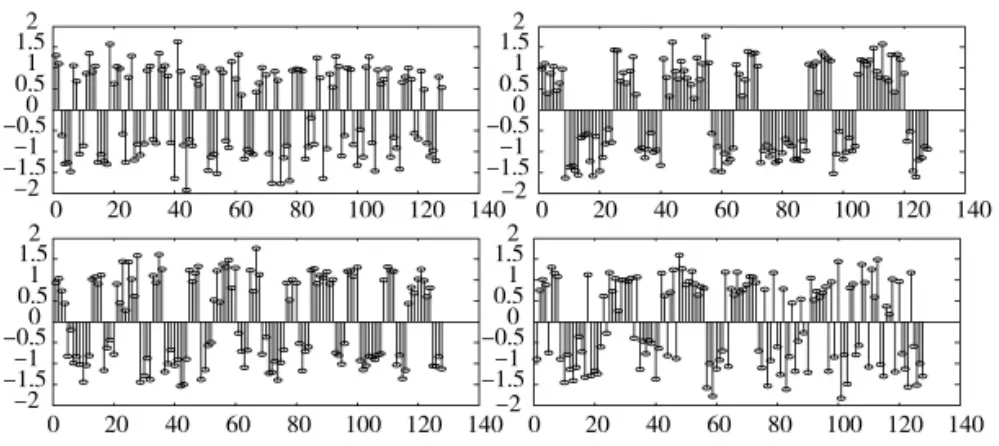
图1 估计出的伪码序列
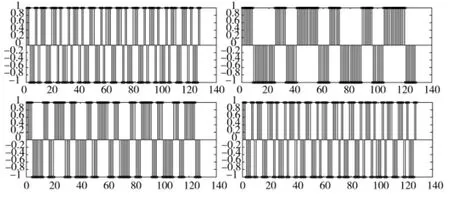
图2 原始的伪码序列
图3为不同采样数据规模条件下算法聚类估计性能随信噪比变化曲线。通过曲线可以发现,随着信噪比的升高,伪码估计性能明显增强,误码率明显下降,并最终下降至8%。这说明算法可以有效对伪码进行估计。而在信噪比一定时,随着数据集合规模之间增高,估计的误码率也明显下降。当规模足够大时,即使信噪比很低,仍可保证对伪码进行有效估计。
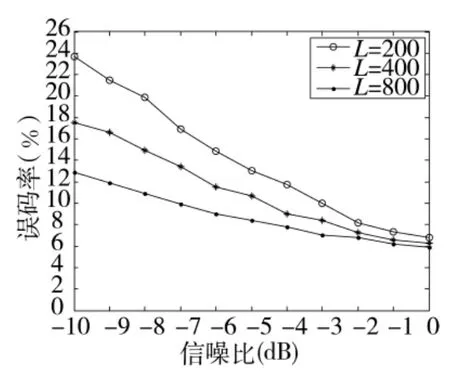
图3 不同规模条件下性能随信噪比变化曲线图
图4为相同数据规模条件下不同算法性能曲线。通过曲线可清晰发现,在信噪比较高时,本文算法的误码率可以降低至5%以下,完全可适用于实际应用。而同类比较时,本文算法估计信号的误码率始终小于另两种算法,并且具有明显提升,说明本文算法的估计性能较好。此外,尽管在信噪比较高时,本文算法估计性能和改进的蚁群算法没有明显区别,但是随着信噪比降低,本文算法性能优势逐渐体现出来,相较另两种算法性能提升明显,并且可以证明其自身的算法稳定性。
4 结论

图4 相同规模条件下不同算法性能曲线图
本文应用改进近邻传播算法对Walsh软扩频成功完成盲解扩。文中先利用Walsh码自身良好的正交性及其统计量估计出软扩频信号的延迟时间。随后借鉴近邻传播聚类分析的思想,提出了一种改进方法对伪码数据规模进行估计。最后应用阈值分析解码完成对Walsh编码系统软扩频的盲解扩。最后,通过仿真证明本文算法的有效性。仿真证明,该方法即使在低信噪比条件下仍能较为准确估计出伪码数据集合规模。而在相同数据集合规模与信噪比条件下,较之KCDS与改进蚁群聚类算法,不但降低了算法复杂度,而且性能有一定提升,更能适应噪声复杂环境。
