机器学习在智能辅助避碰系统中的应用
2019-04-22杨凌波
杨凌波
(北京海兰信数据科技股份有限公司,北京100095)
0 前 言
船舶碰撞问题的研究一直是航海界专家、学者的重要研究方向,而船舶智能避碰系统的实现是船舶驾驶全面智能化的关键。 20 世纪80 年代以来,日本、英国率先使用人工智能的方法对船舶避碰问题展开研究。 专家系统作为人工智能领域中的一个重要分支,在船舶智能辅助避碰领域得到了广泛应用。
本智能辅助避碰系统是基于专家系统的船舶智能化应用,通过对避碰信息的分析和处理判断碰撞危险等级。根据《国际海上避碰规则》(Convention on the International Regulations for Preventing Collisions at Sea 1972,COLREG)、船长和驾驶员丰富航海经验及优良船艺,做出避碰决策建议。 针对现有专家辅助避碰系统在实际应用中的不足,对危险区域划分和避碰危险度计算提出相应的机器学习方法,充分利用现有实船数据,将复杂的实际海况简化,提高了现有系统的实用性。
1 避碰决策过程
根据海上实际的航行环境,智能避碰决策基本过程如下:
第一,避让对象的识别与提取,包括水上航行船舶与水下碍航物信息的自动获取与预处理。 水上航行船舶的动态信息可以借助如船舶自动识别系统(Automatic Identification System,AIS)、无线电探测和测距(Radio Detection and Ranging,RADAR)/自动雷达标绘仪(Automatic Radar Plotting Aid,ARPA)或者两者融合后的船舶信息作为其信息源。
第二,避碰信息的处理,包括各类避让对象的位置、速度、距离、相对方位等避碰基本数据。 这类信息是避碰决策支持的输入信息。 获取基本数据后,进行计算,得出避碰算法中需要的参数。
第三,危险判断与最佳决策的自动生成。 如何判别航线上所有船舶和静态碍航物的危险等级,采用安全的避让措施是智能避碰决策过程的核心环节,是船舶智能避碰决策的关键点。 在遵守COLREG、通常操船方法及优良船艺进行船舶间避让的前提下, 确定安全经济的避让方案是船舶智能避碰技术投入实船使用的基本要求。 船舶避碰决策基本过程如图1 所示。
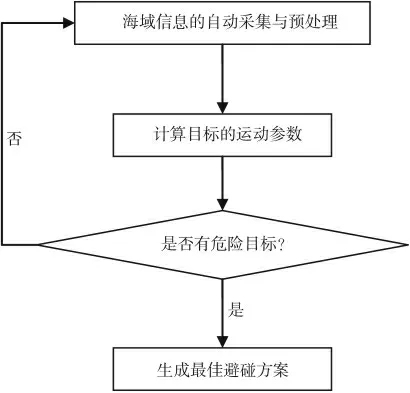
图1 船舶避碰决策基本过程
海域信息的自动采集和预处理决定着避碰决策的合理性和有效性。 在这个步骤中,需要得到必要的数据信息,同时又需要尽可能地简化数据。 良好的信息采集与预处理能够极大地提升避碰算法的功能。
在处理避碰信息时,现有辅助避碰技术在繁忙水域中无法很好地生成避碰策略,其主要原因是目标数量超出算法的极限。系统在计算避碰策略之前,引入危险区域划分概念,通过机器学习方法降低避碰目标数量,充分利用现有的避碰策略生成算法。
在生成最佳避碰方案过程中,现有避碰危险度计算方法在多船相遇时不能客观地反映各船的危险程度,主要原因是影响因素考虑不全面,并且在衡量危险程度方面没有准确的量化标准。利用实船数据训练的神经网络模型能够输入所有影响因素,在数据集足够大的前提下,能够生成接近客观的经验模型。
2 危险区域划分
机器学习中的聚类分析算法(k-means)能够通过分类划分的方法将避碰目标数减少,将一些具有相似特征的目标聚合在一起,形成避碰区域,从而简化目标海域信息。 目前已应用的船舶辅助避碰算法可以较好地实现3~5 艘危险目标船的避碰分析,但无法较好地处理5 个以上的目标船。 系统将机器学习中的聚类分析算法融入到宽水域辅助避碰系统,缩小可航行区域,减少避碰算法的计算量,使之能够应用到繁忙水域中。
目前聚类分析算法主要用于实现以下功能:
1)确定聚类的数量。每个繁忙水域的情况不尽相同,聚类的数量决定着避碰算法输出结果的合理性。
2)确定聚类分析算法的标准测度函数。在考虑船舶自身安全性参数的前提下,确定聚类计算参数,通过计算分析形成合理的危险区域。 危险区域划分的流程如图2 所示。
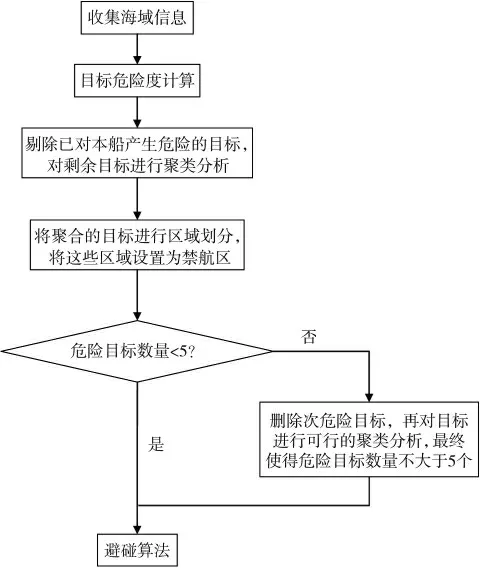
图2 危险区域划分流程图
具体步骤:
1) 收集附近海域信息,得到所有船舶的方位、距离、航向、航速等信息;
2)计算目标的危险度;
3) 剔除已对本船产生危险的目标,对剩余目标进行聚类分析;
4) 将聚合的目标进行区域划分,将这些区域设置为禁航区;
5) 判断危险目标数量,如果不大于5 个,则进入步骤7),否则进入步骤6);
6) 删除次危险级的目标,再对目标进行可行的聚类分析,最终使得危险目标数量不大于5 个;
7) 将危险目标和经过上面步骤处理后的可航行区域输入到避碰算法中。
其中步骤3)的聚类分析为该技术的重点,详细的聚类分析流程如图3 所示。
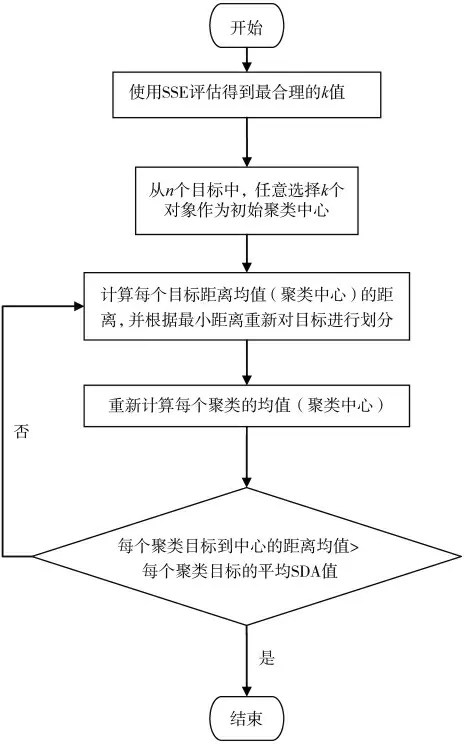
图3 聚类分析流程图
具体步骤:
1)通过SSE(簇内误方差)分析得出最合理的k值(聚类中心个数);
2)从n 个目标中任意选取k 个目标作为初始聚类中心;
3) 计算每个目标距离均值(聚类中心)的距离,并根据最小距离重新对目标进行划分;
4)计算每个(有变化)聚类的均值(中心对象);
5) 如果每个聚类目标到中心的距离均值大于每个聚类目标的平均SDA(安全会遇距离)值,则结束算法,否则回到步骤3)。
使用聚类算法后,有效地提高了现有多目标避碰算法的使用范围,在具有大量相似运动特征的船舶航行水域,能够有效降低避碰问题计算的复杂度,提升避碰策略的合理性和适用性。
3 碰撞危险度
3.1 碰撞危险度评价体系
根据COLREG, 船员在实际操作中, 以DCPA(最近会遇距离)和TCPA(最近会遇时间)判断碰撞危险是最常见的方法。 如果目标船在SDA 外通过,即DCPA>SDA,则两船没有碰撞危险;如果DCPA<SDA 且TCPA>0, 则两船存在碰撞危险。 最小SDA是以本船为中心,不考虑船舶操纵余量,两船保向保速不致发生碰撞的安全会遇距离最小值,又称碰撞区域半径。 文献[1]以SDA 和最小SDA 作为重要判断参数,形成碰撞危险度评估方法如下:
1) 一般危险:本船改向30°或10°(本船为追越船),目标船与本船能在SDA 外安全通过;
2) 紧迫局面:本船改向90°或Cm(特殊交会特征DCPA 变化最大且小于90°的最大改向角),目标船与本船能在最小SDA 以外安全通过;
3) 紧迫危险:本船改向90°或Cm,目标船与本船在最小SDA 以外不能安全通过,此时需要本船变速或者需要目标船协同避让。
3.2 神经网络模型
基于文献[2]的研究,采取神经网络方法计算碰撞危险度。 系统选用以下10 个因素作为神经网络的输入参数:
1)dCPA——两船最近会遇距离
2)tCPA——两船最近会遇时间
3)D——两船间的距离
4)B——目标船的相对方位
5)Vo——本船速度
6)Vt——目标船速度
7)Co——本船航向
8)Ct——目标船航向
9)Lo——本船船长
10)Lt——目标船船长
在上述10 个因素中, 各因素对碰撞危险度的影响程度不同。 为了能够更贴合实际情况,在不同的会遇态势中,碰撞危险度的神经网络模型也不一样。
结合实际情况和文献[3]的研究,会遇态势可划分为A、B、C、D 和E 类,如图4 所示:
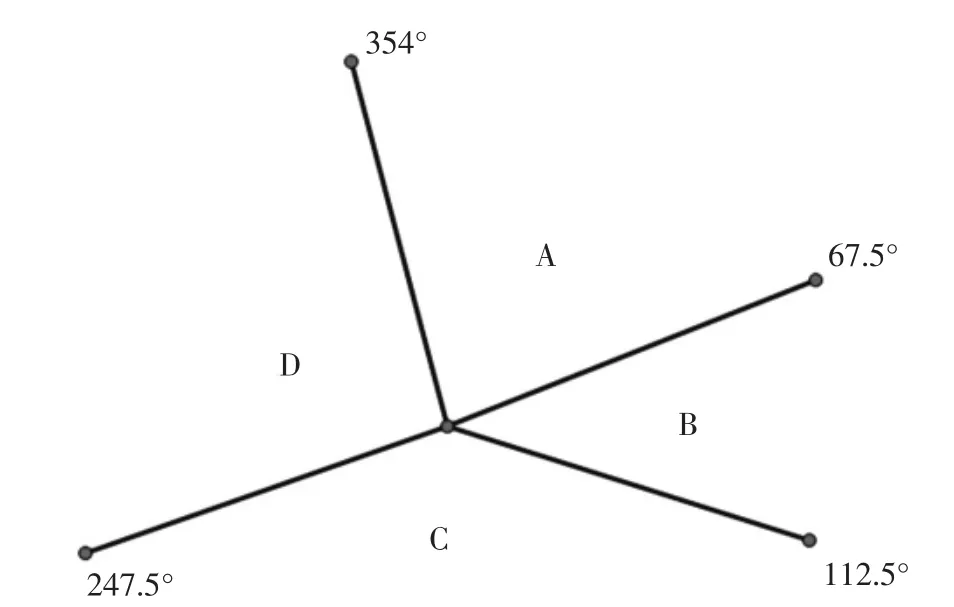
图4 目标船会遇属性划分图
1) A:包含来船与本船右舷交叉的情形和来船与本船对遇的情形,相对方位范围为{354°,360°}和{0°,67.5°};
2)B:包含来船与本船右舷大角度交叉的情形,相对方位范围为{67.5°,112.5°};
3)C:包含来船追越本船的情形,相对方位范围为{112.5°,247.5°};
4)D:包含来船与本船构成左舷交叉的情形,相对方位范围为{247.5°,354°};
5)E:包含来船为被追越船的情形。
其中A 类和E 类在避让方法上没有区别, 将它们划归为同一类。 所以最后组成4 个神经网络模型,模型结构如图5所示。 这是一个反向传播(Back Propagation,BP)神经网络模型,其中包含输入层、输出层和2 个隐藏层。BP 神经网络的传播过程主要分为2 个阶段:第一阶段是信号的前向传播,从输入层经过隐藏层,最后到达输出层;第二阶段是误差的反向传播,从输出层到隐藏层,最后到输入层。 依次调节输入层、 各隐藏层和输出层的权重 (w) 和偏置(b)。 训练数据集使用经过筛选后的100 万条实船数据集,其中包含现有避碰算法的计算结果。

图5 BP 神经网络结构图
使用大量数据对BP 神经网络模型进行训练后,得到4 个模型预测准确率分别为:
1)A 类和E 类情形:96.4%;
2)B 类情形:94.0%;
3)C 类情形:96.6%;
4)D 类情形:92.0%。
预测结果表明,使用神经网络算法能够得到准确度较高的碰撞危险度,再继续增加训练数据集的大小后,能够继续提升准确度。
4 结 语
在智能船舶辅助避碰系统中,使用机器学习方法计算或者优化相关参数,与现有的避碰算法有机结合,得出更加准确合理的避让方案。 在危险区域划分中,使用聚类算法,在确保安全的前提下,减少避让目标数量,扩大了现有多目标避碰算法的使用范围。 基于文献[2]的研究思想,利用现有的历史实船数据对BP 神经网络进行训练, 得到较准确的碰撞危险度预测模型,为避碰决策的生成提供了准确有效的阈值范围。 神经网络的应用和大数据集的使用为未来的避碰研究方向提供了思路。
