一种成品油模型校正集自动维护方法设计
2019-04-22陈夕松
苏 曼 ,陈夕松 ,段 佳
(1.东南大学自动化学院,江苏南京 210096;2.南京富岛信息工程有限公司,江苏南京 210061)
在成品油分析领域,近红外光谱分析技术相较传统实验化验分析方法具有成熟、快速、无损等优点,近年来应用广泛[1,2]。采用该技术预测成品油性质时,首先要建立与待测样本性质接近的校正集,通过对校正集样品光谱和性质参数进行关联建立模型后,再预测待测样本的性质[3-5]。在工业生产中,待测样品往往会随时间发生变化。例如炼化企业生产的成品油,在更换原油或改变加工工艺后,油品性质会有不同程度的改变。因此在一段时间后,新样本的分布会偏离原模型校正集样本的分布区域。当待测样本周围分布的校正集样本较少,即与待测样本相似的样本数较少时,模型预测效果将变差。这会影响炼化企业生产控制,难以保证产品质量和效益[6]。因此需要不断对模型的校正集进行维护更新,以保证模型的预测精度。
关于近红外光谱模型校正集维护技术的研究目前还相对较少。文献[7]利用RPLS算法预测不同类型土壤样品的速效磷和速效钾含量,在预测过程中对模型的回归系数进行递归更新,从而不断获取待测样品中出现的新的有效信息。但是该方法在样本性质出现较大偏移时作用不明显。文献[8]研究了烟叶4种成分的近红外模型的维护,通过观察不同年份烟叶4种成分的光谱主成分空间分布图判定是否需要更新模型,但是没有提出系统的、可实施的判断方法。
1 方案设计
为解决成品油模型校正集更新问题,本文设计一种自动维护校正集的方法。该方法以新样本在校正集中相似样本数量来判断新样本是否处于稀疏区,并将稀疏区的样本自动添加到校正集。首先对样本进行光谱预处理,然后进行主成分分析。在主成分分布图中以新样本为中心,根据贡献率由高到低选择前n个得分向量,建立n维空间上的固定框。统计框内相似样本数量,若大于阈值,则判断新油样处于密集区,不必添加到校正集;若小于阈值,则认为新油样处于稀疏区,继续判断新样本是否为异常样本。若不是异常样本,则自动将新样本添加到校正集。流程(见图1),具体步骤如下:
(1)测定样本的近红外光谱,对新样本和校正集中样本的光谱数据进行常规预处理,包括谱图截取、基线校正和矢量归一化[7]。全谱计算工作量很大,且有些光谱区域样品的光谱信息很弱,因此在建立校正模型之前需要进行谱图截取以选择合适的波段。基线校正主要用来消除基线的漂移,其中两点法基线校正后的吸光度通过式(1)计算:

式中:xi为汽油在近红外光谱区的波数;kxi+b为过两基点的直线方程,其中k为该直线斜率,b为该直线截距;yi表示原谱图在波数xi下的吸光度;表示基线校正后的谱图在波数xi下的吸光度。
归一化用于消除光程变化或样品的稀释等变化对光谱的影响,其中矢量归一化采用式(2)计算:)
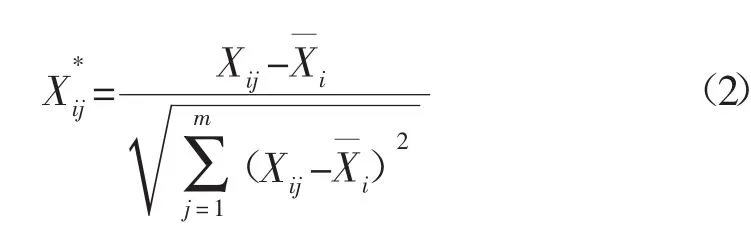
式中:Xij是第i个样本在波数j下的吸光度;指第i个样本的吸光度平均值;m是波数点的个数;表示矢量归一化之后的第i个样本在波数j下的吸光度。
(2)采用主成分分析,对预处理后的光谱数据进行特征提取。主成分分析通过将原始特征空间进行变换,使少数几个新变量是原变量的特征组合,以消除原光谱信息中相互重叠的部分,同时能尽可能多地表达原变量的数据特征,实现数据降维。在主成分分析结果中选取得分矩阵的前n个列向量,绘制n维主成分分布图。n取2或3,在n=2时,选取前两个得分向量绘制二维主成分分布图;当n=3时,选取前三个得分向量绘制三维主成分分布图,通过分布图便于判断样本是否处于稀疏区。
(3)在主成分分布图中以新样本为中心,建立n维的固定框,框内样本为校正集中与新样本相似的样本。主成分分析结果中第一主成分代表吸光度矩阵变异最大的方向,第二主成分次之,以此类推。因此按照各主成分包含的信息量大小,设置固定框不同维度上的比例,包含信息量较大的主成分所占比例较大。如当n=3时,设计三维立体框图的长宽高比为3:2:1。然后统计n维框内相似样本数量,与阈值比较,判断样本是否处于密集区。若相似样本数量大于阈值则新样本处于密集区,不添加到校正集,避免校正集样本冗余,返回步骤(1);否则继续判断该样本是否为异常样本,转步骤(4)。
(4)判断新样本是否为异常样本,如是异常样本,则不添加到校正集,返回步骤(1),否则转步骤(5)。本方法中以杠杆值h为指标判断新样本是否为异常样本,并将杠杆值大于3 k/m的样品视作杠杆值偏高,放入预备库做进一步观察;杠杆值小于3 k/m的样品为正常样品。h的计算方法如式(3):
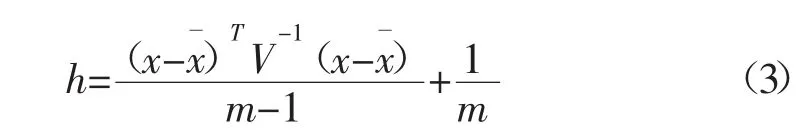
式中:x为新样本光谱主成分得分向量;V为校正集光谱主成分得分矩阵的协方差矩阵;m为校正集样本数量;k为变量数。
因为工业中生产的成品油性质是逐渐变化的,若某一油品与最近一段时间生产的油品都有较大差异,则该油品为异常样本。此类样本参与建模,其光谱会对用于建模的一个或多个光谱变量有显著贡献,进而对回归结果产生强烈影响,降低模型的稳健性。因此当新油样杠杆值偏大时,先将其放入预备库,观察邻近时间的油样。若邻近时间内只有个别油样杠杆值偏大,则新油样为异常样本,将其剔除。若邻近时间内采样油样杠杆值都偏大,说明近期油样产生较大变化,新油样虽然杠杆值偏大,但不应判断为异常样本。
(5)自动将新样本添加到模型校正集,结束本次模型维护。
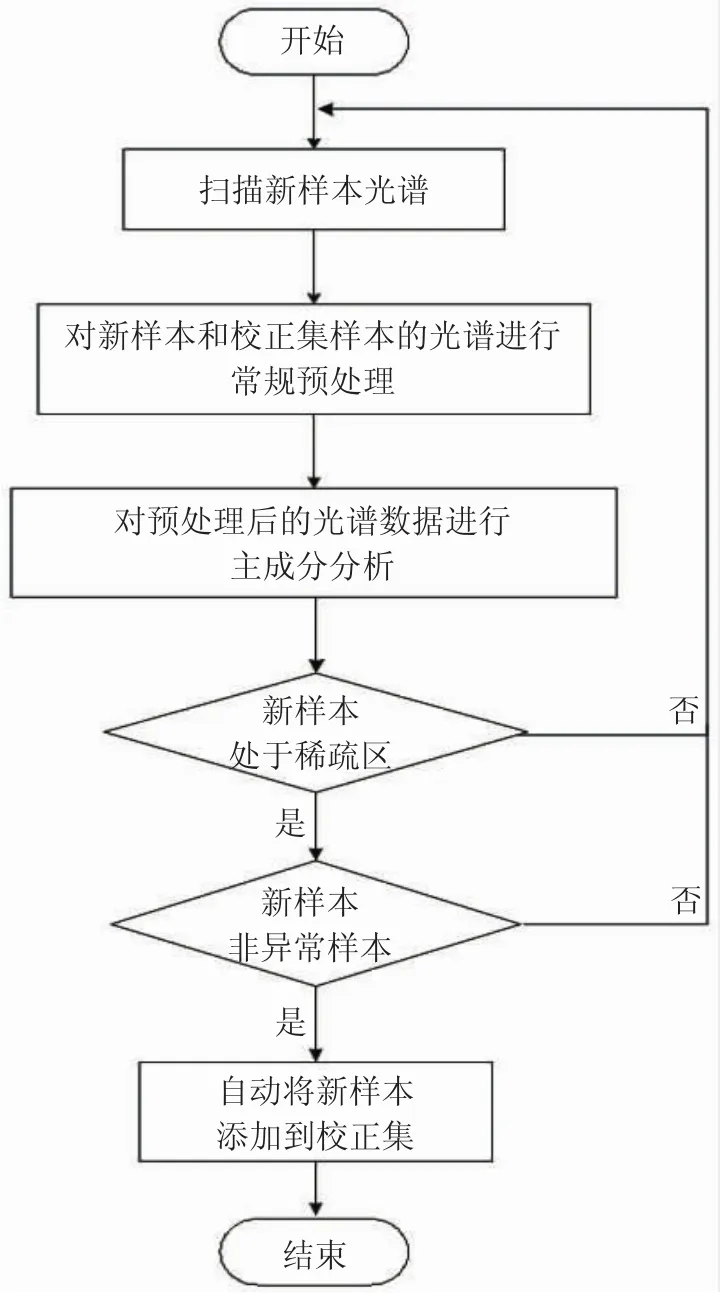
图1 自动添加校正集样本方法的实施流程
2 应用研究
仪器:ABB MB-3600型傅里叶变换近红外光谱仪,光程长度为0.5 mm的常压样品池,光谱采集范围为3 700 cm-1~14 750 cm-1。本文的实验过程软件均通过Matlab编程实现。
样品:本案例以95#汽油的终馏点为例,依据汽油的近红外光谱建立预测模型。原模型校正集A由某炼化企业在2015年1月至2017年11月期间生产的296个95#汽油样本组成。依据本文设计的模型校正集维护方法,向校正集A中添加2017年12月至2018年5月的部分汽油采样,建立新的校正集B。选取2017年7月至2018年5月的112个样本进行终馏点预测,说明自动添加校正集样本对模型预测精度的影响。
2.1 建模过程
采用近红外光谱仪扫描汽油样本,获得样本的近红外光谱数据。全谱段建模计算量较大,本案例仅截取近红外光谱信息量较大的4 000 cm-1~4 800 cm-1波数段的吸光度数据进行建模。因为样品的近红外光谱常常受到仪器高频噪声、基线漂移等因素的影响,因此首先进行光谱预处理。本案例中对截取的光谱数据做两点法基线校正和矢量归一化,在一定程度上可以去除原始近红外光谱中包含的噪声和干扰信号。
对预处理后的样本光谱数据进行主成分分析,将原始的数据做降维处理,提取原光谱的特征变量并消除原光谱变量间的多重共线性。案例中截取的4 000 cm-1~4 800 cm-1波数段的原始光谱为208维吸光度数据,经主成分分析后的得分矩阵中,前2个得分向量的累计贡献率达到85%以上,已经涵盖原光谱的大部分信息。因此选取主成分分析结果中得分矩阵的前二维列向量,绘制二维主成分分布图,观察油样分布情况。
以2016至2017年间油样的二维主成分分布为例(见图2),2016年全年采样的79个95#油样以“*”表示,2017年全年采样的158个95#油样以“·”表示。图2中可以明显区分出2016年和2017年的油样分布区域,证明工业生产的成品油样随时间发生较大变化。
因为在工业生产中每过一段时间,可能会更换原油或改变加工工艺,这些均会导致生产的成品油样性质组成发生较大变化。新样本的分布偏离原模型校正集样本的分布区域,使原校正集中很少存在分布在新的待测样本周围的相似样本,不利于建模。尤其是采用相似样本建模的方法,模型预测精度会受到很大影响。因此在建立模型时需要对校正集进行定期维护,识别出处于稀疏区的新样本,并自动添加到校正集中,以及时适应油样变化,提高模型稳健性。
本案例中以主成分分析结果的前3个得分向量判断相似样本,通过建立三维空间上的立体框判断新样本是否处于稀疏区。前三维得分向量的累计贡献率已经超过90%,基本可以表征样本的光谱信息。其中第一主成分包含光谱信息量最大,第二主成分次之,第三主成分最小。因此依据各向量贡献率大小,设置立体框的长为0.3,宽为0.2,高为0.1。结合本模型校正集样本数量和样本分布情况,设置相似样本阈值为50。
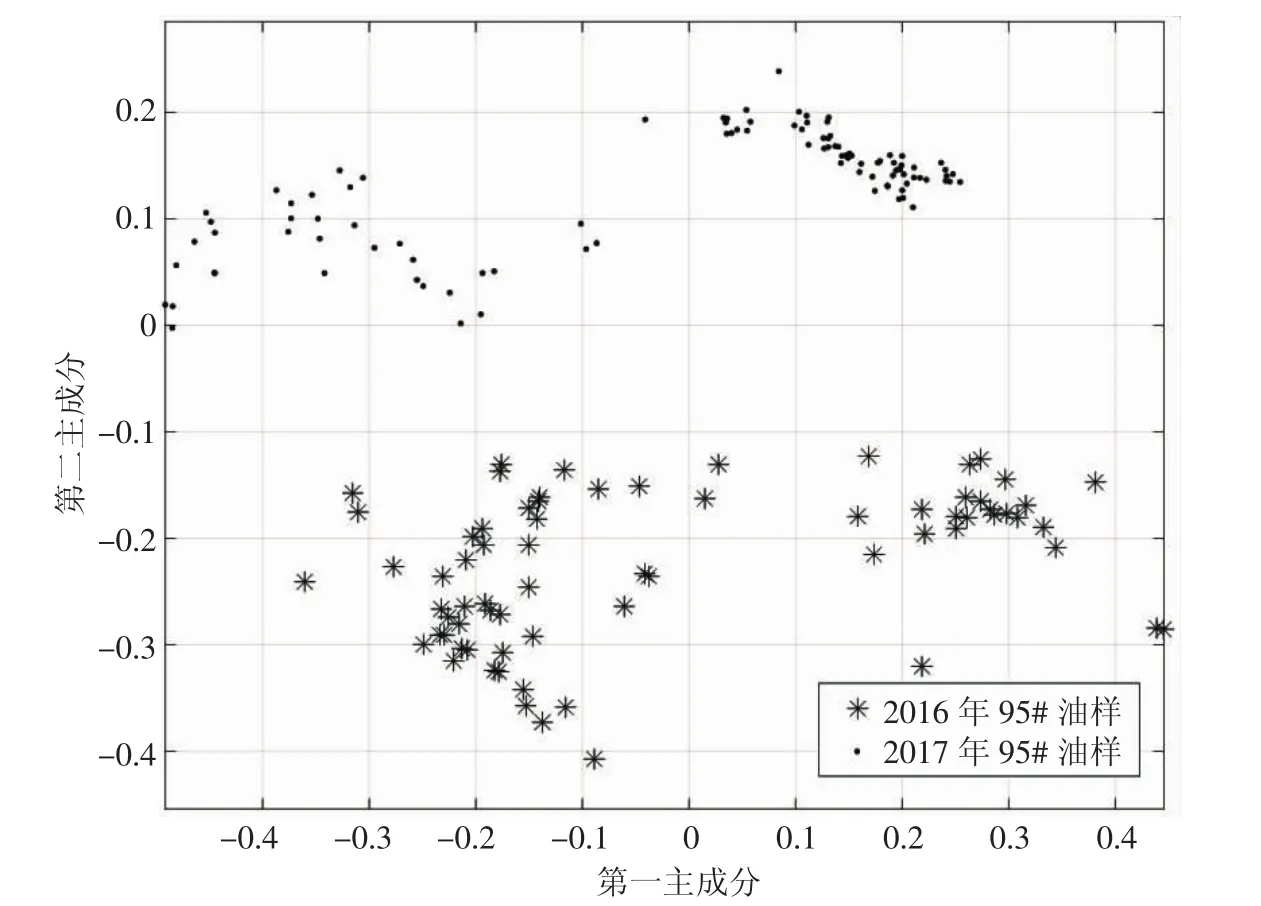
图2 2016-2017年间95#汽油样本主成分分布图
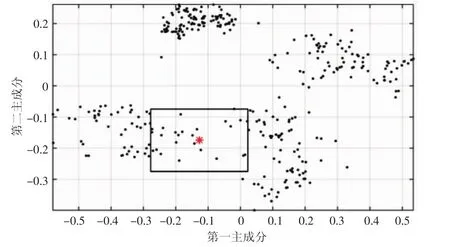
图3 (a) 稀疏区样本分布示例图
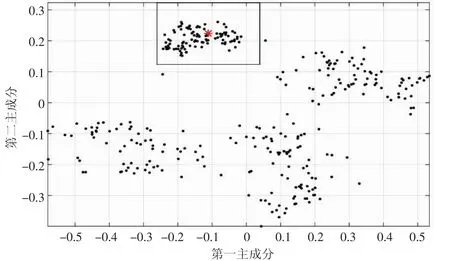
图3 (b) 密集区样本分布示例图
对2016年12月至2017年5月采样的61个95#汽油样本分别进行判断,观察每个样本在原校正集中的分布区域。
如果以新样本为中心建立的立体框中相似样本数量少于50,则判定样本处于稀疏区。说明近期油样发生较大变化,使新样本的分布偏离原模型校正集样本的分布区域,或该样本测量有问题属于异常样本。接下来将该样本放入预备库,继续判断是否为异常样本。为便于观察,以二维分布图示意(见图3(a))。
如果以新样本为中心建立的立体框中相似样本数量大于50,则判定样本处于密集区,说明近期油样并未发生明显变化,因此不将该样本添加到校正集,避免校正集样品出现冗余,降低模型计算速度。返回步骤(1),继续测量其他样本(见图3(b))。
对2017年12月至2018年5月采样的61个汽油样本判断结果为:其中有15个新样本变化不大,仍处于原校正集样品密集区域,没有添加到校正集中,另外46个样本处于原校正集样品稀疏区域,继续判断是否为异常样本。
然后以杠杆值h为指标判断样本是否为异常样本,并设置阈值9/m,其中m为此时校正集中样本数量。若新样本杠杆值低于阈值,则认为该样本属于正常样本,直接添加到校正集;若新样本杠杆值高于阈值,则该样本可能为异常样本,先将其放入预备库。对每一个放入预备库的样品,观察其后7天采样样本的杠杆值。若邻近7天内采样油样杠杆值都偏大,说明近期油样产生较大变化,并非该油样出现异常,因此仍将其添加到校正集。若邻近7天内只有个别油样杠杆值大于阈值,则该油样为异常样本,剔出预备库,且不加入到模型校正集中,避免对模型精度和稳健性造成影响。
经过主成分分析判断位于原校正集样品稀疏区域的46个样本中,有2个样本为异常样本,将其剔除,并提示报警,其余44个样本被添加到校正集中。
2.2 应用效果
通过比较添加校正集样本前后模型预测精度的变化,说明本文设计的校正集自动维护方法的有效性。
校正集A由某炼化企业在2015年1月至2017年11月期间生产的296个某成品油样本组成。逐步更新校正集A,将2017年12月至2018年5月的成品油采样中处于稀疏区的44个非异常样本自动添加进校正集A,最终形成校正集B。
基于校正集A和逐步更新得到的校正集B分别建立模型,对2017年7月至2018年5月的112个样本的终馏点性质进行预测。
首先获取待测样本和校正集样本的近红外光谱,截取近红外光谱信息量较大的4 000 cm-1~4 800 cm-1波数段的吸光度数据进行建模。再对截取后的光谱数据做两点法基线校正和矢量归一化,消除基线漂移和光程变化或样品的稀释等变化对光谱的影响。然后进行主成分分析,对原始的数据降维处理提取特征变量,并消除原光谱变量间的多重共线性。在主成分分布图中,以新样本为中心,建立三维立体框,框内样本即为待测样本的相似样本。最后基于相似样本采用局部偏最小二乘法建立成品油性质预测模型,对112个待测成品油样本的终馏点进行预测。
基于校正集A建立成品油性质预测模型,预测结果(见表1)。
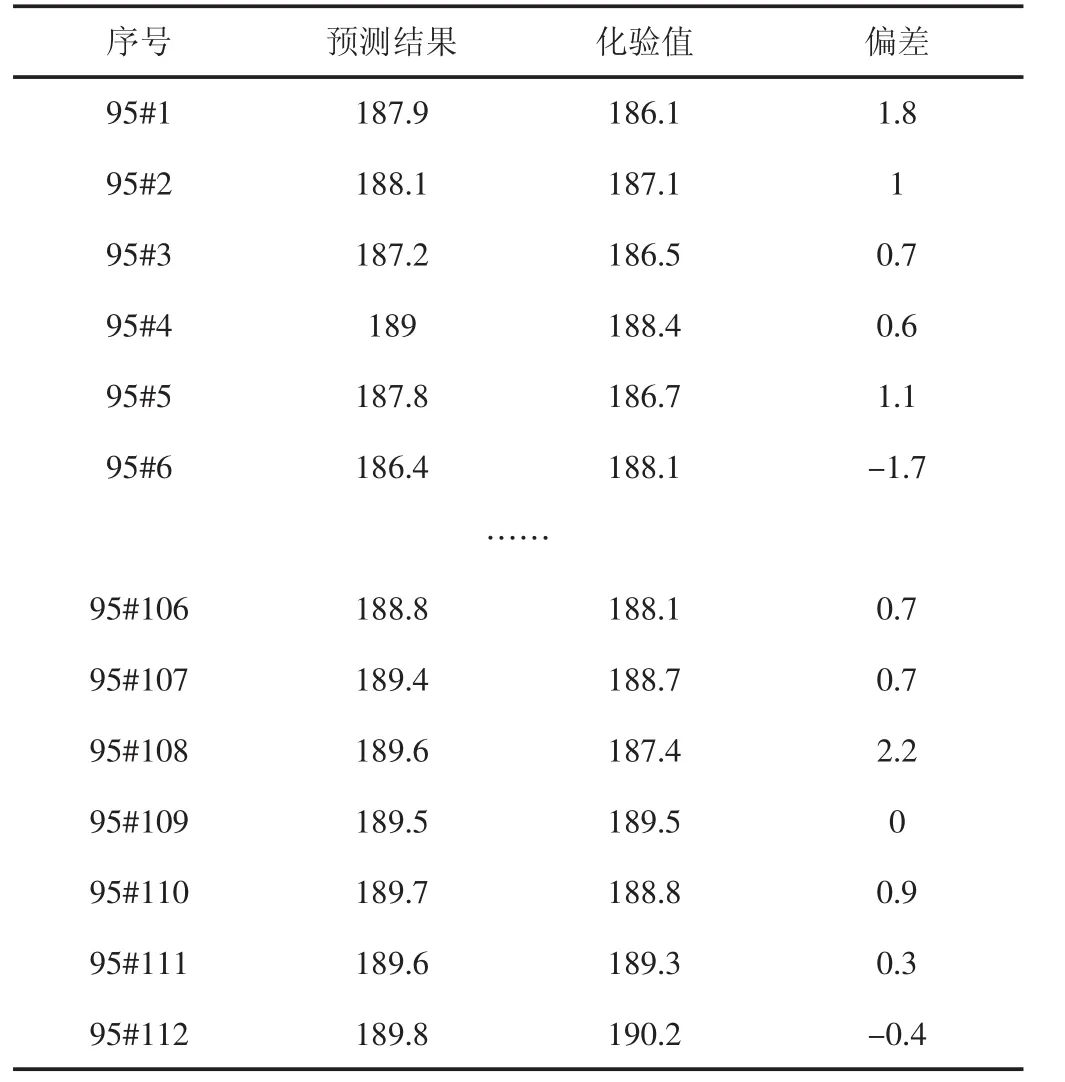
表1 原模型预测结果
基于维护后的校正集B建立成品油性质预测模型,预测结果(见表2)。
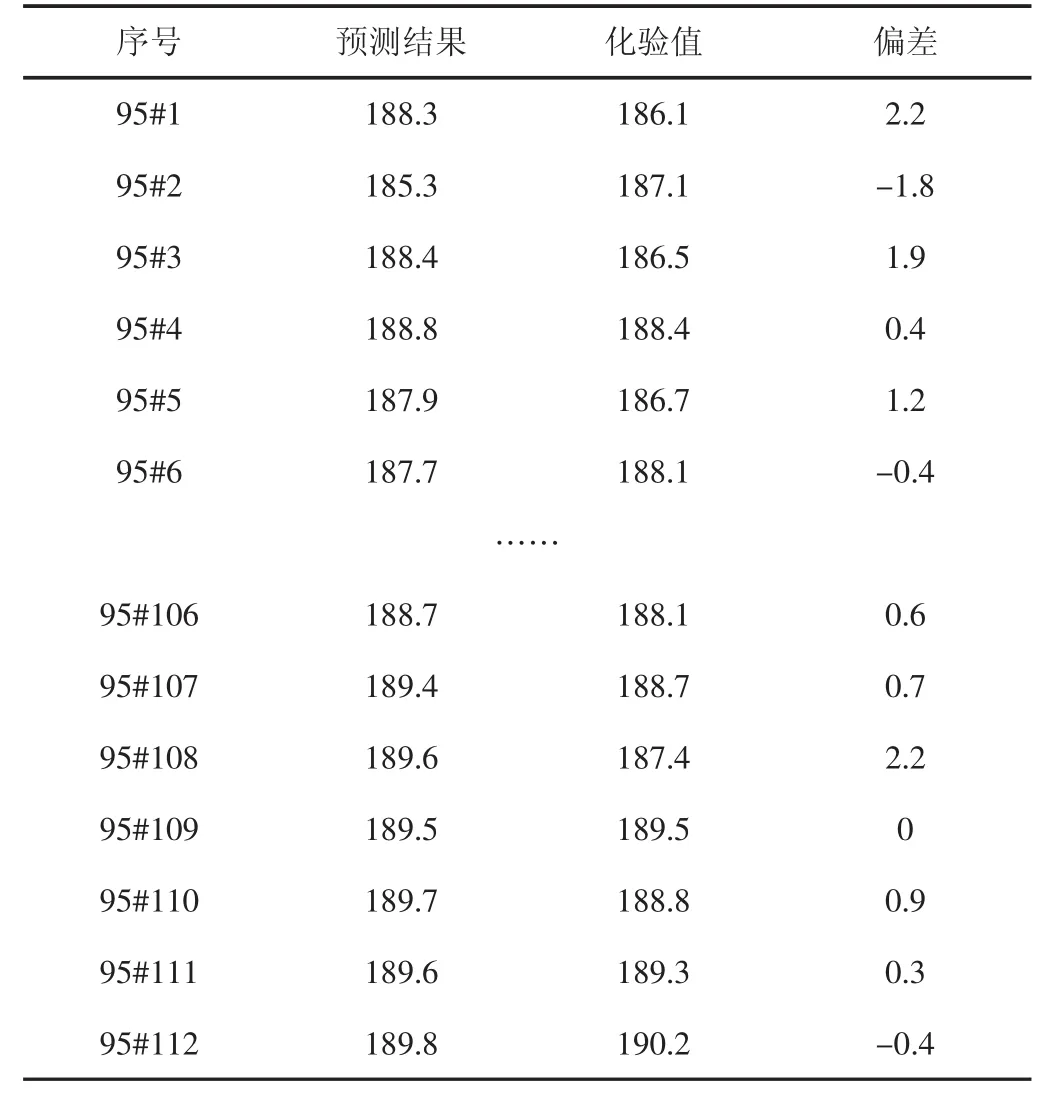
表2 新模型预测结果
针对95#汽油的终馏点,国家标准规定测量的重复性误差为3℃,再现性误差为5℃。此处将基于该汽油近红外光谱建立模型预测结果和化验值的偏差与国家测量标准中该汽油终馏点性质的重复性误差和再现性误差进行比较,以体现模型预测精度。
对表1和表2中的数据进行统计,校正集维护前后建立模型的预测精度比较(见表3)。
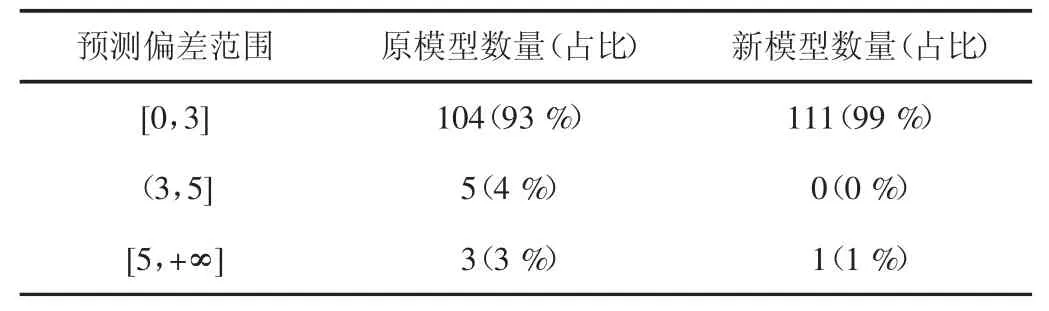
表3 原模型和新模型比较
由表3中数据可知,在添加校正集样本,建立新模型后,112个预测样本中预测偏差低于重复性误差,处于[0,3]范围内的样本数量增加7个,占比提高至99%。同时预测偏差高于再现性误差,处于[5,+∞]范围内的样本数量减少2个,占比降低至1%。样本总体预测偏差降低,预测精度显著提高。
3 结语
针对炼化企业生产中随时间推移,成品油性质会发生不同程度变化的情况,设计一种自动维护模型校正集的方法。该方法可有效避免基于近红外光谱的成品油性质预测模型中,建模一段时间后因新样本偏离原校正集样本分布区域,导致模型预测精度降低的问题。该方法能够提高成品油近红外光谱建模的预测精度,保证模型稳健性,控制生产、确保油品质量具有重要应用价值。本文提出的方法对其他基于近红外光谱的性质分析模型维护也具有较好的借鉴意义。
我国学者研发出可捕集二氧化碳的新型吸附剂
记者19日从南京工业大学了解到,该校刘晓勤、孙林兵教授课题组研发出一种智能吸附剂,实现了对二氧化碳的低能耗、可控式捕集,有望大幅降低工业过程中气体分离的能耗。相关成果近日发表在化学领域国际知名期刊《德国应用化学》上。
据论文第一作者、南工大博士生江耀介绍,在工业上的吸附分离操作中,传统吸附剂通常需要在变温或变压条件下实现其循环使用过程。“也就是在常温下吸附、升温时脱附;或者加压下吸附,减压后脱附,缺点是这两种办法往往能耗较高。”江耀说。
“我们尝试选用光能这种绿色清洁能源作为替代。”孙林兵教授告诉记者,自然界存在一些具有“光响应性”的特殊物质,能够在不同波段光的照射下产生结构变化,发挥吸附作用,偶氮苯分子就是其中之一。
“我们希望将这种光响应性能与活性物合理配比,协同实现对二氧化碳的可控性捕集。”孙林兵说,基于这个想法,课题组先是构建了一种具备光响应性的“金属-有机”框架,再引入可吸附二氧化碳的活性位点,在不同光照条件下对活性位点进行调试,最终实现了对二氧化碳的可控性捕集。
“这种协同机制相较于传统的变温、变压吸附大大降低了能耗。”江耀说,新型吸附剂将来可应用于充满二氧化碳的工业烟道,助力节能减排。
(摘自宁夏日报第21823期)
