基于不平衡分类的原发性肝癌患者无病生存期预测研究*
2019-04-20杨日东李琳陈秋源华赟鹏周毅
杨日东,李琳,陈秋源,华赟鹏,周毅△
(1.中山大学 中山医学院,广州 510080;2.新疆医科大学 公共卫生学院,乌鲁木齐 830011; 3.中山大学附属第一医院 肝胆外科,广州 510080)
1 引 言
肝癌是死亡率最高的恶性肿瘤之一,中国每年约有38.3万人死于肝癌,占全球肝癌死亡人数的51%。近年来,随着原发性肝癌(hepatocellular carcinoma,HCC)的早期诊断和早期治疗,患者的总体疗效明显提高。但据有关研究表明,即使对肝癌进行根治性切除,5年内仍高达60%~70%的患者出现转移复发[1]。因此,对肝癌转移复发进行预测,从而寻找有效的抑制途径,是进一步提高肝癌患者生存率的关键,具有重大的研究意义。
在HCC预后预测研究方面,Hua[2]等人通过多因素分析,表明肿瘤数量,数门脉癌栓、肿瘤大小和中性粒细胞/淋巴细胞比值(NLR)是无病生存(DFS)和总生存(OS)的独立预测因素,并表明伴有肝硬化的肝癌患者,较大的NLR往往术后DFS和OS较差。Ji[3]等人通过单因素分析和多因素分析,发现NLR和谷草转氨酶/血小板比值指数(APRI)可作为HCC患者预后的独立预测因子,并且当两者结合起来预测时,可以得到更高的准确率。赵利锋[4]等人通过多因素Logistic回归模型,显示原发性肝癌患者术前血液中RBC数量低于标准是影响其累积生存时间的危险性因素之一。目前,基于机器学习的原发性肝癌患者无病生存期预测研究较少,结合多种影响因素构建HCC的预后预测模型,是当前一大研究热点。
然而,大部分HCC患者的无病生存期小于5年,研究数据往往是类不平衡的。传统机器学习算法以最小化分类器的错误率为目的,导致多数类样本的识别率远高于少数类样本的识别率。鉴于此,本研究提出一种针对类不平衡改进的提升树算法。为了提高分类器对难分类的少数类样本的预测性能,我们修改提升算法的样本权重更新方式,在每次迭代过程中,仅提高误分类的少数类样本权重,对于分类正确的少数类样本和所有多数类样本,保持其权重不变。并且,为了更好地评价基分类器,我们修改提升算法的权重更新方式,将F值纳入到基分类器权重的计算中。
简单起见,本研究将多数类称为负类,将少数类称为正类。
2 实验2.1 实验数据
本实验数据来自广东省某三甲医院于2006至2009年收治的321例进行肝切除术的肝癌患者,包括77例无病生存超过5年的患者和244例无病生存小于5年的患者。具体属性说明见表1。
2.2 实验方法
2.2.1代价提升树 传统的提升算法在每次迭代中增加当前基分类器误分类样本的权重,并减少正确分类样本的权重。考虑到这种权重更新策略并不能强调正类样本的重要性,我们提出了一种改进的提升树算法——代价提升树(cost boosting tree,CBT)。在代价提升算法的每次迭代中,只增加误分类的正类样本权重。对于负类样本和正确分类的正类样本,则保持其权重不变。因此,代价提升树的基分类器更关注难学习的正类样本,最终提高整个集成分类器对正类样本的预测性能。

表1 HCC临床数据集属性说明
另外,传统提升算法在更新分类器权重时考虑的是整体错误率:
然而,错误率并不能很好地衡量不平衡学习任务。鉴于此,我们将F值(F-measure)作为衡量基分类器性能的指标。
基分类器的权重更新如下:
在最终决策时,它将作为基分类器的权重系数。这里Max(F-measurem,0.5)是为了保证基分类器的F值大于0.5,若F值小于0.5,则am=0,表示舍弃该基分类器。具体的算法步骤如下:
输入:训练数据集:
T={(x1,y1),(x2,y2),…(xn,yn)},基分类器CART

(2)对于m=1,2,…M。
(3)使用带权重分布的样本Dm训练数据集学习,得到基分类器:
Gm(x):→{-1,+1}
(4)计算Gm(x)在训练数据集上的F值:
其中:
这里的I是指示函数,当条件成立时等于1,当条件不成立时等于0。
(5)计算Gm(x)的权重系数:
(6)更新训练集的权重分布:
Dm+1=(wm+1,1,…,wm+1,i,…,wm+1,N)
这里的Zm是归一化因子,它使得样本的权重分布成为概率分布:
(7)构建基分类器的线性组合,最终得到分类器:
2.2.2采样技术 采样技术是解决类不平衡的方法之一,它通过对数据样本的预处理,从而达到数据平衡的效果[5]。为了验证改进提升树的有效性,本研究将改进提升树与结合了过采样技术(SMOTE、BorderlineSMOTE和ADASYN)或欠采样技术(One-Sided Selection)的决策树进行对比。
1、合成少数抽样技术
Chawla[6]等人提出了一种经典的过采样技术,称为合成少数抽样技术(synthetic minority over-sampling technique,SMOTE)。基本思想是正类样本与其在正类样本集中的K近邻的连线之间随机产生一个样本。
2、自适应合成抽样方法
He[7]等人提出了一种自适应合成抽样方法(adaptive synthetic sampling,ADASYN)。ADASYN根据正类样本的K近邻中正类样本数判断学习的难易程度,自适应地调整合成样本的数量。具体地,对于K近邻中属于正类的样本越少,认为越难被正确预测,在其附近生成更多的正类样本,反之更少。
3、边界合成少数类过采样技术(BorderlineSMOTE)
考虑到类边界附近的样本对分类器的影响较大,Han[8]等人提出了一种BorderlineSMOTE过采样算法。他们根据正类样本的K近邻中的正类样本数将其分为“安全样本”,“噪声样本”和“危险样本”(即在类边界的样本),并仅对“危险样本”合成新样本。
4、单边选择欠采样技术(One-Sided Selection)
Kubar[9]等人提出一种欠采样算法,称为One-Sided Selection算法。One-Sided Selection将负样本分为“安全样本”,“冗余样本”,“边界样本”和“噪声样本”。他们使用CNN算法去除“冗余样本”,然后通过去除Tomek-link样本的方式去除“边界样本”和“噪声样本”。这样,数据集仅保留安全的负类样本和所有正类样本。
2.3 评价指标
二分类算法的分类性能可用混淆矩阵表示[6],见表2。

表2 混淆矩阵
对于类不平衡问题,准确率通常无法衡量分类算法的好坏[6]。例如,不平衡数据集的负类样本数为990,正类样本数为10,分类器将所有样本预测为负类,其准确率将达到99%,然而这是毫无意义的分类器。此时,应考虑的评价指标为:召回率、精度、F值(F-measure)、G均值(G-mean)、AUC(Area Under roc Curve)。具体计算方式如下:
G-mean=(ACC-×ACC+)1/2
其中,参数β用于调整召回率和精度之间的权重,一般令其为1。
在类不平衡问题中,F值用于权衡召回率与精度的重要性。G均值则与召回率和特异性相关,一般召回率高的分类器,即使精度偏低,也可达到较好的G均值。因此,G均值可用于衡量重视召回率的类不平衡学习任务。
2.4 实验结果
为了提高分类性能,可对条件属性进行单变量统计检验,以P值为参考标准,仅保留P<0.01的属性构建模型,见表3。
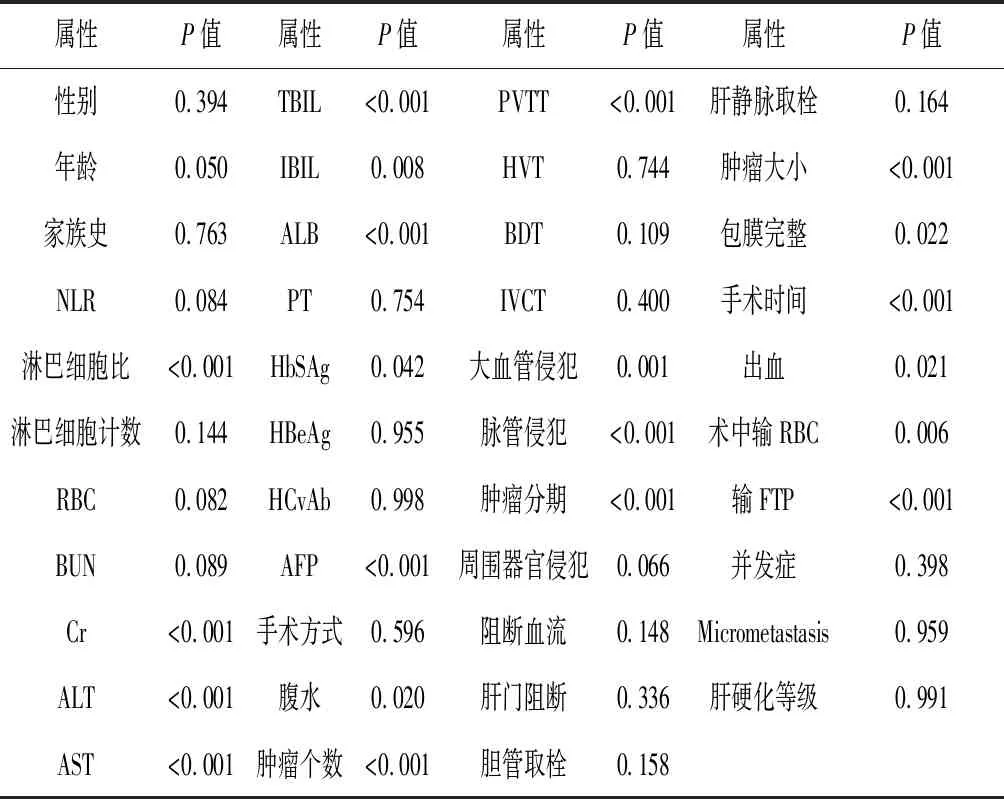
表3 各变量的统计检验结果
考虑到文献[2-3]提出的NLR对HCC患者无病生存的影响较大,本次实验也将其保留。
为了对比算法本身的改进,我们用BT表示传统提升树,用CBT(错误率)表示仅修改样本权重更新方式的提升树,用CBT(F值)表示修改样本权重更新方式和基分类器权重计算方式的提升树,进行对比。本次实验用到的决策树是调用python中的sklearn工具包[10],在保证准确率的情况下,参数的设置以最大化AUC值为原则。采用20次10折交叉验证的平均值作为最终结果,实验结果见表4。
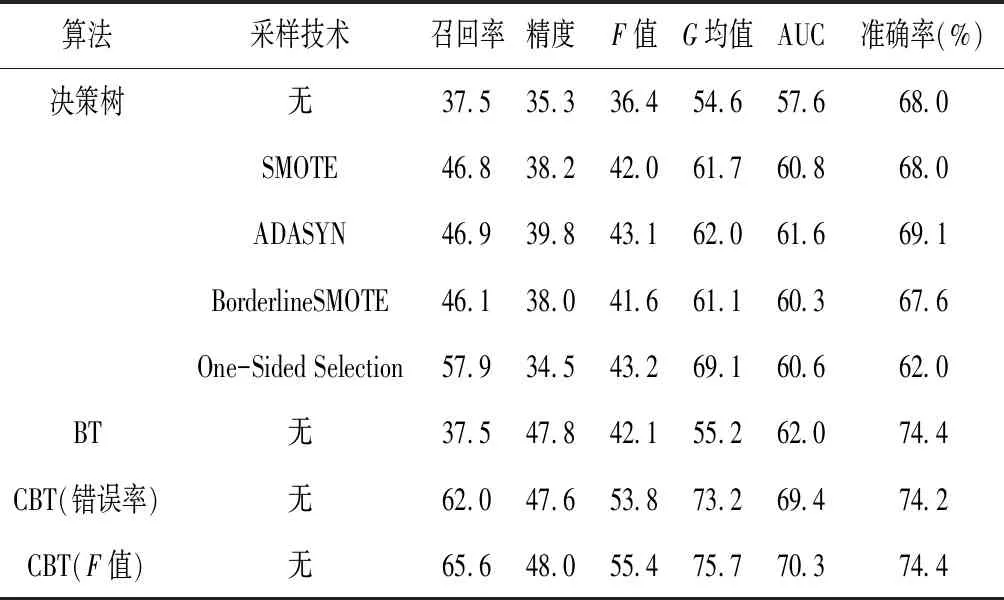
表4 各算法在HCC临床数据集上的性能对比
从表4可以看出,由于传统的提升树BT以整体错误率为优化目标,导致其在不平衡数据集上的F值、G均值和AUC指标较差。经修改,样本权重更新方式的CBT(错误率)相比BT在各性能指标上有很大提升。可得出结论:在样本权重更新过程中,只提高误分类的正类样本权重,有利于训练出更关注正类的基分类器,从而提升对正类样本的预测性能。与CBT(错误率)相比,CBT(F值)以F值计算基分类器权重,而CBT(错误率)采用错误率。CBT(F值)相比CBT(错误率)有所提升,这说明以F值为指标计算基分类器权重更有利于评价不平衡分类,从而提升整体集成决策的预测性能。同时,CBT在数据集上的F值、G均值和AUC优于结合采样技术的决策树算法,说明CBT在不平衡分类任务中是有效且可行的。
3 总结
传统的HCC预后研究是基于统计学的方法找出影响因素,而利用机器学习算法,根据影响因素构建分类器的研究较少。传统机器学习算法在类不平衡数据集上的性能不佳,主要体现在正类的识别率远低于负类,导致AUC指标低。鉴于此,本研究针对传统提升算法迭代过程中,样本权重的更新方式无法体现出正类样本的重要性和错误率,无法准确衡量不平衡分类任务的问题,提出了一种改进的提升树算法——代价提升树。在每次迭代中,CBT提高误分类的正类样本权重。并且,CBT将F值纳入基分类器权重的计算。通过在HCC患者的临床数据集上进行实验,我们发现CBT算法的F值、G均值和AUC比传统提升树有很大提升,并且优于结合采样技术的决策树算法。
本次实验还发现,在CBT每次迭代过程中,由于提升了误分类的正类样本权重,因此,每次抽样后正类样本的比例呈递增趋势。我们意识到,若正类样本的比例越大,其训练得到的基分类器对正类样本的分类效果会越好。因此,在后续研究,我们将考虑以正类样本的比例构造基分类器的权重系数,得到新的加权集成方式。
