基于OpenFOAM的不同网格数下并行计算性能分析*
2019-04-20王冠石陈宇蒋文涛田晓宝王清晟周志宏
王冠石,陈宇,蒋文涛,田晓宝△,王清晟,周志宏
(1. 四川大学 力学科学与工程系,四川省生物力学工程实验室,成都 610065;2. 北京市顺义区体育运动学校,北京 101300)
1 引 言
随着CFD的不断发展,其趋势总体呈现出计算域更复杂、算法精度更高、网格数量众多等特点,同时人们对快速计算、甚至实时计算的需求日益迫切[1-2],因此,研究高性能计算(high performance computing, HPC)成为人们的当务之急。目前,高性能计算在材料科学、天体物理、核科学、气候气象、结构、生物医学、地震科学等领域得到了广泛地应用,并极大地推动了这些领域的发展[3-5]。准确地说,高性能计算和建模与仿真共同定义了继理论、实验后第三种主要的科学研究手段[6]。
当前,高性能计算机体系结构主要以多核计算集群为主。在实现多核并行计算的诸多开源软件中,OpenFOAM备受瞩目。其自由、开源、高可扩展性、对并行计算友好的特点[7-8],受到使用者的青睐。尤其是可以通过简单修改控制文件的设置,再使用脚本文件设定计算顺序,就可针对不同情况进行大批量自动计算,提高了总体计算效率。
然而,随着问题规模的增大,即网格数量的增加和计算核心数量的增加,多核并行计算平台是否能够保持良好的运算性能?为此,我们有必要研究和分析高性能计算的潜在运算能力,尤其是综合分析在不同计算节点和问题规模下的性能表现[9-10],以便充分发挥其强大的功能。本研究使用OpenFOAM作为测试软件平台,探究了该平台的运算性能,以期得出计算性能和效率随计算节点和网格数量的变化规律,得出最优的解决方案,为大规模并行计算提供一定参考。
2 计算集群软硬件环境
2.1 硬件配置
本研究所用的高性能计算集群是四川大学建筑与环境学院的计算平台,其总体计算能力可达6.3 Tflops,由1个管理节点和18个计算节点,共计304个(19×16)计算核心组成,具体节点配置见表1。该集群系统配置一台S5700S骨干以太网交换机,作业网络采用以太网方式,存储系统为12 TB 的分布式系统。考虑到在不同测试条件下保证硬件环境一致,以及避免内存大小对本次试验造成限制,因此本研究使用具有128 G内存的三个计算节点。
2.2 软件平台
该集群系统各个节点的操作系统均为CentOS Linux release 7.2.1511,同时使用 PBS作为进程调度管理软件。测试用的数值模拟软件为OpenFOAM,其版本由OpenFOAM基金会支持,通过从Github开发线上获取源码并进行编译安装,版本号为dev-af88b75e2c3e。

表1 节点的硬件配置
3 测试方案设计
3.1 并行计算的性能评判
在进行并行计算的性能测试前,需要规范统一的衡量标准,该标准需要简单完整地反映在不同节点数下计算性能的相对大小,即加速的倍数。因此,对于多核计算集群,由Gustafson定律[11]可直观地定义加速比为式(1):
(1)
其中TS表示使用单个计算核心串行运行程序的执行时间,Tp表示使用p个核心并行运行程序的执行时间。在本研究中,考虑到PBS的计算资源调度方式和串行计算可能耗费大量时间,因此,选择以8个核心并行运行的执行时间为基础,即TS=T8。
直观来看,加速比的值应该为p,但是现实中总有一些限制使加速比无法达到此值[12-13]。因此,我们需要定义一个标准,能够良好地衡量并行计算的效率,定义计算效率为下式:
(2)
其中Sp表示式(1)中的加速比,p表示p个计算核心。
3.2 测试算例简介
考虑到我们仅研究计算流体力学多核计算时的计算效率,而对大规模网格进行计算时,由于瞬态问题而导致收敛相对复杂,所以我们选择建立层流算例,即在OpenFOAM中使用基于SIMPLE算法的simpleFoam求解器进行稳态求解。建立一个简单的二维管道模型,直径为0.1 m,长度为0.2 m。左侧入口inlet定义为patch边界,右侧出口outlet定义为patch边界,上、下两侧fixedWalls定义为固定壁面,前、后两侧frontAndBack定义为empty边界,这是因为OpenFOAM 只在三个维度上求解算例,若求解二维模型,需要指定第三维边界条件为empty。然后,定义物理参数和边界条件,运动粘度0.01 m2/s,左边速度入口inlet为1 m/s,右边运动压力出口outlet为4 m2/s2,内部场初始化为初始压力为4 m2/s2、初始速度为1 m/s。
对于简单规则的结构,可以使用OpenFOAM自带的blockMesh划分网格。对于本研究中的二维管道模型,我们分别采取1000×1000、2000×2000、3000×3000、4000×4000、5000×5000五种方式进行网格划分。为了避免分布在每个核心上的网格数量差别过大,使负载尽可能均衡[14],统一采用scotch分区方法,分别对所有网格划分方案构建8、16、24、32、40、48,共计六种分区结构。设置迭代次数为2 000次,并提交计算。
4 测试结果和分析
由于计算节点资源有限,本研究针对每种情况只进行了一次计算。虽然如此,我们仍然能够获得良好反映并行计算时间随计算核心数和网格数量的变化趋势。同时,我们更多关心并行计算的时钟时间,因此对网格二次划分的时间不做讨论。最后,计算时钟时间的结果见表2,图1反映其变换趋势。
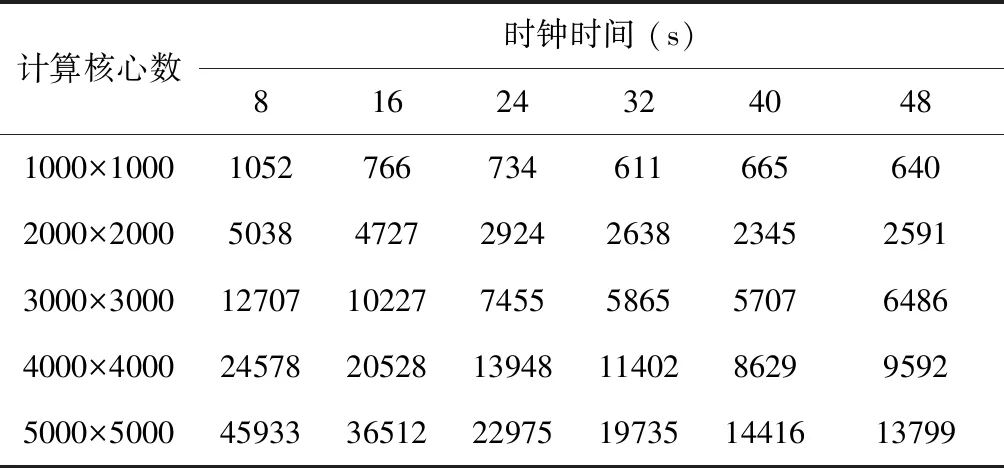
表2 不同情况下并行计算的时间
4.1 加速比
根据表2中的结果和式(1)中定义的加速比公式,我们计算出不同网格数下的加速比,见表3,相应的变化曲线见图2。可知,对于400万、900万、1600万网格这三种情况,其加速比都存在先增加后减小的趋势。注意到和其他两种情况相比,对于1600万网格,增大到40核时有更好的加速趋势,但是在到达48核时,加速比和40核相比又减小了。对于100万网格,在使用16核计算时,其加速比优于其他情况,但是随后加速比增长缓慢,在增加到32核之后便趋于稳定,总体加速效果并不明显。而对于2500万网格,加速比在24核之后增长趋势强劲,甚至到了48核时,仍然保持良好的加速趋势。
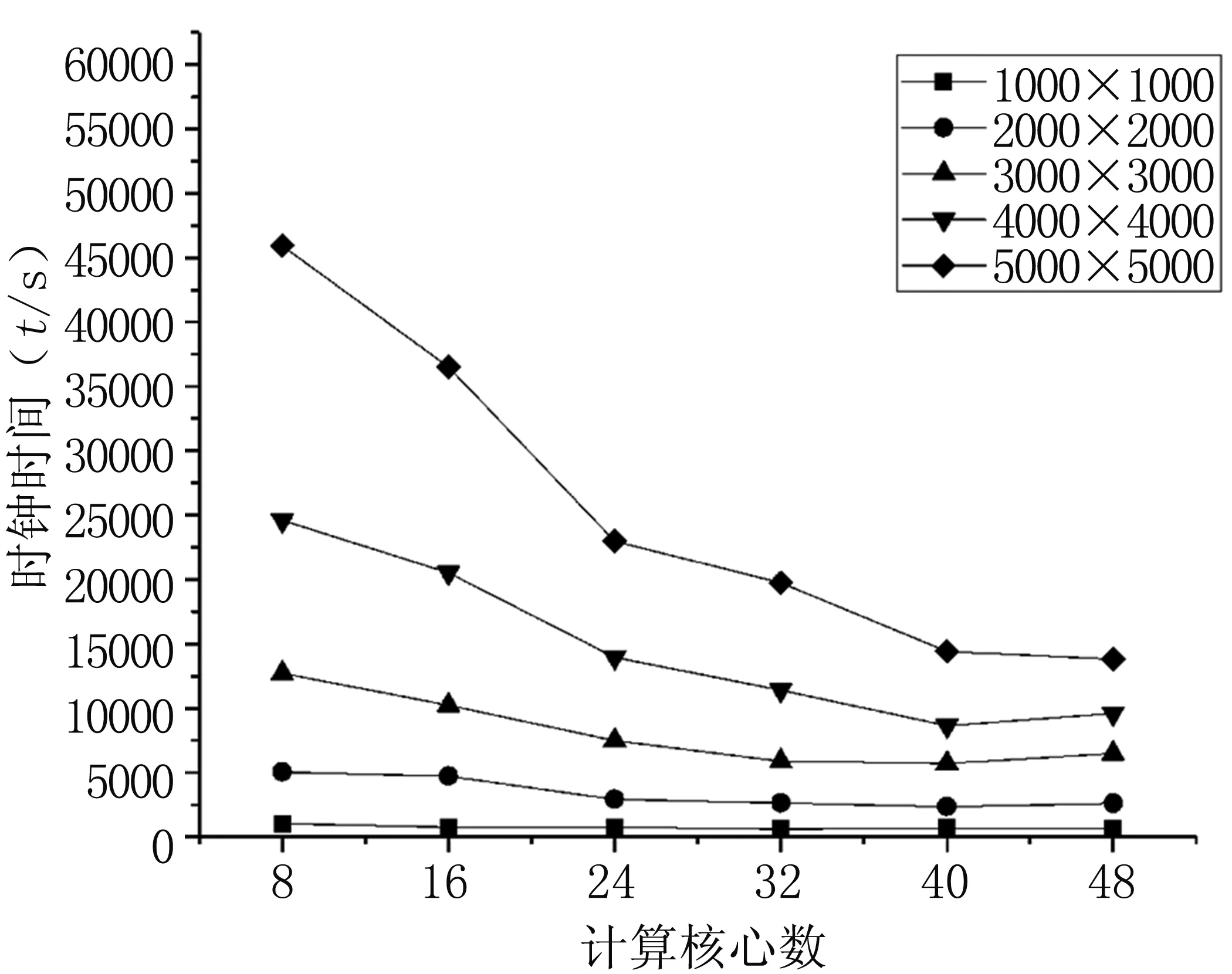
图1 不同情况下并行计算的时间的变化趋势
Fig1Timeofparallelcomputingunderdifferentconditions
另一方面,五种情况的网格数量比为1:4:9:16:25,然而在某一核数对应的不同网格数下,最大加速比和最小加速比的比值差距很小,甚至最大比值也未超过2.02(在48核时,2500万网格加速比与100万加速比的比值)。需要注意的是,在16核时100万网格的加速比最高,但随着核数的增加,最高加速比均为2500万网格,直至48核时和其他网格数的加速比差距最大。

表3 不同情况下并行计算的加速比
4.2 效率
根据式(2),和表3中的加速比结果,我们可以获得计算效率,见表4和图3。从计算效率上看,随着网格数量的增加,计算效率的下降反而变慢。对于100万网格,在16核时,计算效率和其他情况相比最高,随后效率下降比其他情况都快。在400万网格和900万网格时,计算效率都在32核时开始下降。分析1600万网格的情况,计算效率在16核时下降到了59.9%,随后总体保持在55%~60%之间,但是在48核时剧烈下降到了42.7%。而对于2500万网格,计算效率在16核时下降到62.9%后,效率一直在60%左右波动,总体利用效率在高位稳定。
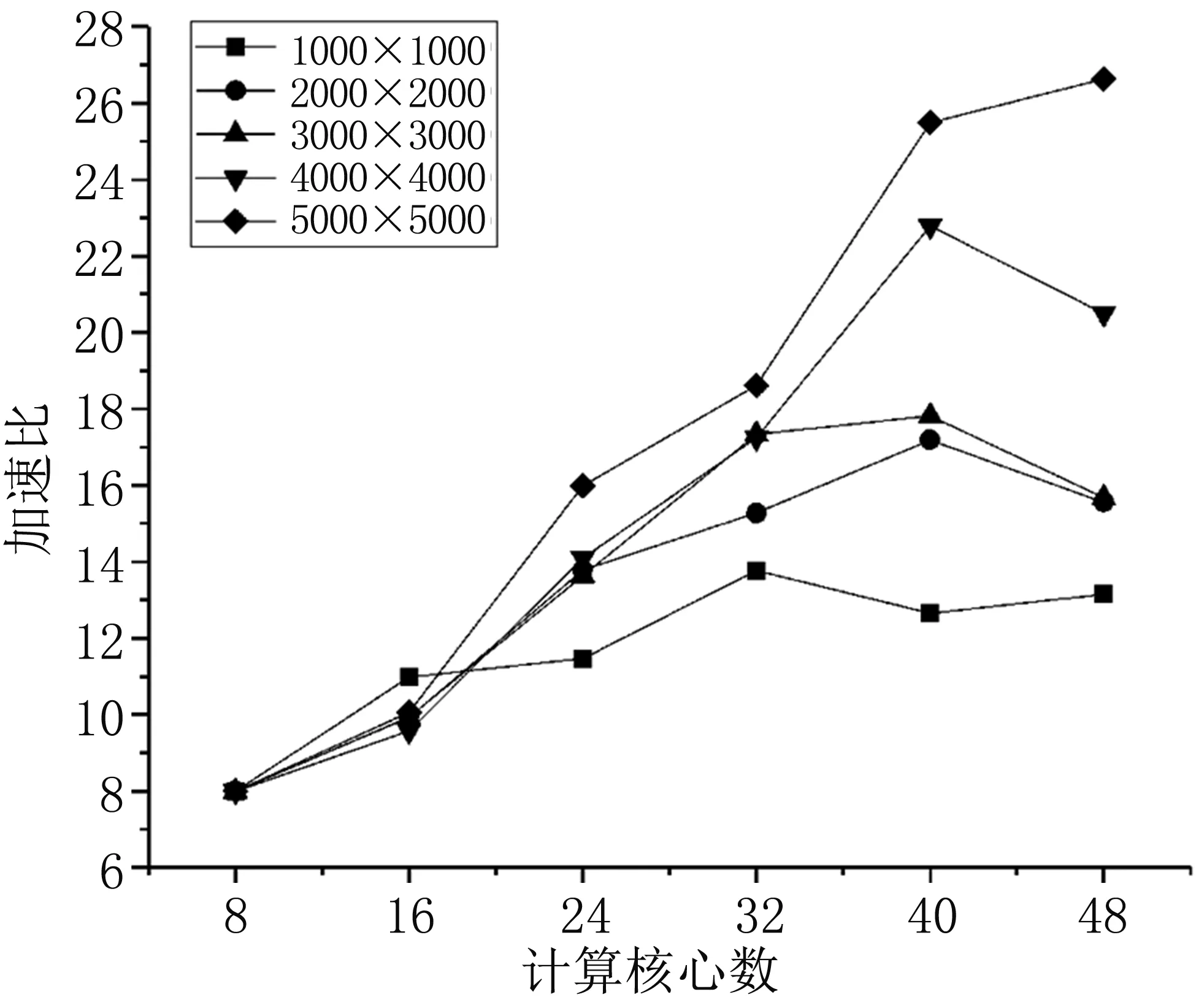
图2 不同情况下并行计算的加速比
Fig2Speedupratioofparallelcomputingunderdifferentconditions

表4 不同情况下并行计算的效率
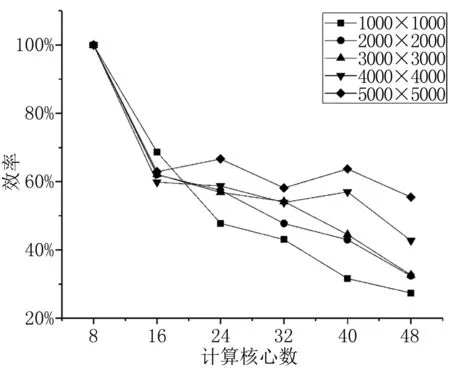
图3 不同情况下并行计算的效率
Fig3Efficiencyofparallelcomputingunderdifferentconditions
4.3 结果分析
从加速比的结果来看,有三组曲线表示了随着核心数的增加,求解速度反而下降。这是因为随着分区数目的增多,各区域之间的通讯边界越来越多,通讯带来的并行开销加大。在达到40核时,并行开销的增加大于理想并行计算时间的递减,计算加速能力的提升接近饱和,随后加速能力反而下降。对于100万网格,由于计算网格量较小,在开始增加核数时,加速能力提高反而很快。但由于通讯时间相对占比较高,随即计算能力达到饱和,在32核后基本趋于稳定波动。而考虑2500万网格的情况,由于计算量较大,和其他网格数相比,通讯时间占比较低,对集群计算资源的利用较高。随着计算核数的增加,计算加速比不断提高,甚至到了48核时,虽然增长比前一阶段要慢,但是计算能力始终没有达到饱和。
同样分析效率,对于100万网格,计算通讯的成本远大于并行计算节省的时间,因此效率剧烈下降。而随着网格数量的增加,通讯相对占比越来越低,因此影响也越来越小。对于2500万网格,我们仍然可以观察到,效率始终保持在60%左右。另外,考虑到其他用户在控制节点上的操作、不同节点通讯是否稳定、计算机底层各种意想不到的情况等,这些都会不同程度影响最后的求解结果。
5 结论
从五组网格数对应的加速比和并行效率来看,一方面,并行计算加快了求解的时间,但是很难达到理想的加速性能,甚至当计算能力达到饱和时,加速性能反而下降。同时,随着网格数量的逐渐增加,即计算规模的增大,相应的计算效率越来越高,反映了更加充分地利用了计算资源。因此,我们需要在相应的网格数量下,选择相对合理的并行计算核心数,才能获得最优的求解方案。对于本研究的计算平台,使用PBS作为进程调度管理软件,其调度的单位是节点,每个节点有16个计算核心。因此,综合考虑加速比、计算效率以及计算平台总体的任务分布,本文提出如下建议:对于100万规模的网格,使用1个节点16核较好;对于400万和900万网格,使用2个节点32核更好;对于1600万网格,需要使用3个节点,但是反而让8个计算核心闲置,才能获得最优的计算效果;最后,对于2500万网格,使用3个节点48核最好。
