古籍专名数据库的构建与统计分析
2019-04-19程宁
程 宁
(南京师范大学 文学院,江苏 南京 210097)
1.引言
纵观古今,但凡涉及阅读或研究文献资料,我们不可回避的一个问题就是专名辨识的问题,如果能够通过某种途径对文献中出现的各种专名信息有一个基本了解,这不仅可以加深我们对文献的理解,也可以促进文献研究的进一步深入。早在先秦时期,前人就已经开始了专名信息的整理与研究,并取得罕见的成果,这为我们研究古代专名提供了无比珍贵的资源。随着社会的发展,海量纷杂的电子文本开始活跃在人们视野之中,为了更好地传承我国优秀的传统文化,对古籍数字化的整理与研究已然成为时代迫切的需要。近年来,自然语言处理研究逐步向古籍文献领域深入,这必然给古籍文献的研究带来新的生机与活力。在科学技术高速发展的今天,古籍文献资料的自然语言处理也将成为影响社会经济文化发展进程的重要因素。古籍专名的信息处理是古籍信息处理不可或缺的重要组成部分,本文旨在建立一个包含六种专名(人名、地名、书名、官职、年号、朝代)的古籍专名数据库,该库的构建可以服务于专名自动标引系统,在专名自动标引的基础上,增加词典的匹配查词,可以有效提升专名标引的效果。
2 古籍专名数据库的构建
2.1 基本概况
通过构建大规模古籍专名数据库,将古籍中存在的大部分专名及其释义有机整合在一起,该数据库可服务于古籍专名的自动识别。本数据库通过析取和整合大量的外部词典资源以及期刊文献资源,分别构建了人名表、地名表、书名表、官职表、年号表和朝代表这六种专名词表,并且按照规定的字段组织形式将这六种不同的专名信息进行汇总,得到一个涵盖这六种专名的总的专名词表。对于中国历史上繁多的年号信息及公元纪年对应,也通过人工整理入库。目前已经提取了《中国历史大词典》《中国历史人名大词典》《中国历史地名大词典》《佛经词典》《佛教人名库》《佛教地名库》《历代名僧辞典》《禅宗典籍560种提要》《阅藏知津》等多部xml格式词典中的词条和释义信息。总词条数量已超过90万条,专名词条按出处分布如表1所示。

表1 收录专名词条数最多的前15个出处
该数据库共收录专名词条90万条。由于人名、地名以及书名在历史上是比较多产的,并且有很多外部电子文献资源可以利用,所以它们在词条收录上占了该数据库的绝大部分。由于历史朝代和年号相对于其他专名来说,本来数目就不多,所以它们仅占了数据库的很小一部分,但这一部分对于专名时代标引的词典匹配又是不可或缺的。该数据库六种专名的比例分布如图1所示。

图1 六专名的比例分布图
2.2 古籍专名数据库的构建方法
由于专名词典数据表专名词条数目众多,而且不同专名的数据来源大有不用。为了便于后期维护和完善,采用分表构建的方式。先分别构建人名表、地名表、官职表、书名表等六个专名表,不同的专名表设定不同的字段来汇总专名信息,最后再将六个专名表按照统一规定的字段合并为一个总表。在专名表构建的过程中采用Python作为主要编程语言,用于各种专名的析取和整合。
以人名表为例,人名表汇集了百度百科、中国历史人名大辞典、中国历史大辞典、佛教人名库、佛经词典、历代名僧辞典,以及其他各种期刊文献中的人名信息。不同的文献资源,对人名解释方式是不同的,有的给出了详细释义,有的只是简单介绍。所以人名表的字段设计需要参照外部文献资源的具体释义情况来定。
例如,《中国历史人名大词典》中对“丁汝昌”的解释信息较为丰富:
丁汝昌(1836—1895)清安徽庐江人,字禹廷,一字雨亭。初隶长[江水]师,从刘铭传镇压捻军,官至提督。光绪十四年任海军提督,统率北洋舰队。黃海海战后,奉李鸿章避战保舰之命,困守威海卫军港。日军攻陷威海卫时,拒降服毒而死。
该词条可以分解出较为细致的数据表格形式。如表2所示:
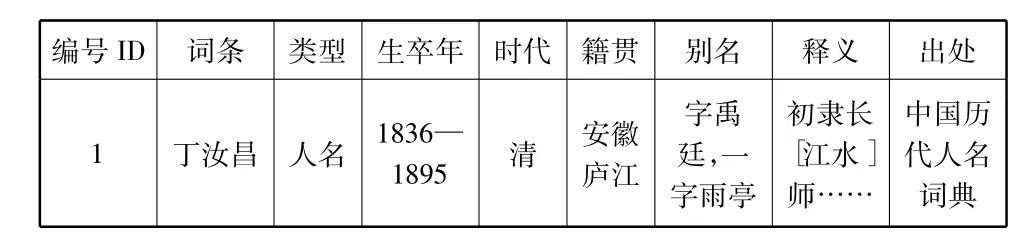
表2 提取特征后的专名词条
再如,《历代名僧词典》中对某一人名的解释如下(xml格式):
</script></head><bodybgcolor="#D2B48C">【佛驮什(宋建康龙光寺)﹝梁.慧皎《高僧传》卷三﹞】<hr><BR>佛驮什。此云觉寿。罽宾人。少受业于弥沙塞部僧。专精律品兼达禅要。以宋景平元年七月届于扬州。先沙门法显。于师子国得弥沙塞律梵本……什后不知所终。 <BR><BR><hr>FROM:【历代名僧辞典】</script>
通过对xml格式的文本进行解析,解析结果如表3所示。
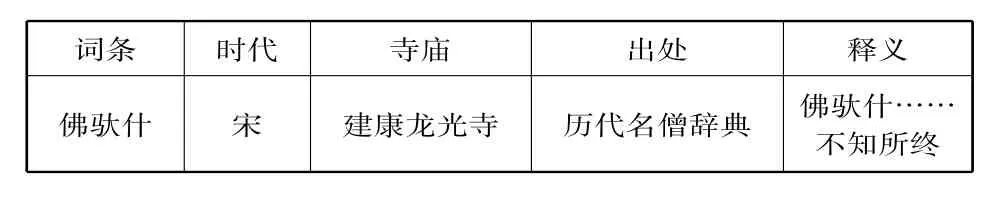
表3 XML文档解析后的专名词条
用于抽取人名的外部词典数量众多,通过对多部词典进行整合,词表数据项不断扩充,从而得到一个总的人名表。其他专名表依照这种方法类推,形成六张数据项详尽、词条规模可观的专名词表。
在各专名数据表的基础上,进行古籍专名总表的构建。由于各专名数据项的设定不尽相同,比如,人名表有生卒年的设定,地名表有地理坐标的设定,书名表有编纂者的设定等,为了避免总表的数据项过于冗杂,我们提前设计了总表的基本数据项。如表4所示。

表4 古籍专名数据表总表的数据项设计
确定好总表字段以后,需要对六张专名表进行合并归类,六张专名表除了涵盖了总表字段之外的其他字段内容视情况归并到“sense”字段中去。这样就形成了一个简化的总的专名数据表,第一条专名到最后一条专名用一个总的id号来标明。专名总表的样例如表5所示(根据专名类型各举一例)。

表5 古籍专名总表样例
2.3 对重复专名信息的归并
专名词条的数据来源广泛,导致汇总的专名数据表中有不少专名词条重合。比如,人名词条“一行”可能会在多种外部词典资源中出现,这种情况不仅会造成数据库内容的臃肿繁杂,而且不利于古籍文本专名的自动标引。具体样本实例如表6所示。
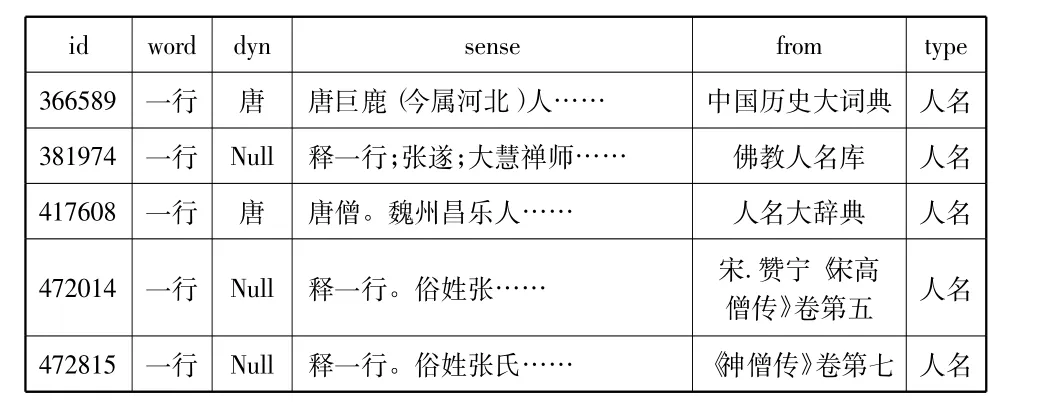
表6 专名词条“一行”的收录情况
因此,要对上述情况进行归并,只保留一个专名词条,其他字段信息合并处理,用“;”进行界定,表示不同的义项信息。合并之后的专名信息不会发生错乱,可以根据各数据项中的“;”还原成合并之前的形式。通过数据表进行处理,保证数据库中每一种专名类型下每一个专名都是独一无二的。合并结果如表7所示。

表7 专名词条“一行”合并后的表格形式
通过这种方法对专名词典所有词条进行去重处理,这样关于某一专名的所有解释都集中在了专名数据库中的一条记录上,分号隔开的不同义项信息分别来自于不同的外部词典,不会发生错乱。这样在古文专名标引过程中,如果识别到“一行”这样的词条,将其链接到数据库中,这个专名的所有数据项内容就可以有条理地呈现出来。
3.古籍专名数据库的统计分析
3.1 数据库专名置信程度的统计分析
该数据库所收录的专名来源广泛,有相当一部分抽取自不同的期刊文献,不能保证所有的词条信息都准确无误,而且在真实语料的词性标注过程中有很多词条既可以充当专有名词,又可以充当非专有名词。比如,“吉祥”一词在古代汉语中有时候既可以充当名词作宾语又可以充当形容词作定语。示例如下:
①恢恢/a六合/n,/w成/v吉祥/a之/u宅/n。 /w(《高僧传卷第四》)
②菩萨/nr谓/v吉祥/nr曰/v:/w“/w欲/v得/v草/n坐/v,/w地/n则/d大/a动/v。(《经律异相卷第四·现迹成道》)
上述两例所用到的语料均来自于中古时期古籍文本。可以发现,“吉祥”一词在①中是形容词词性,在②中是名词词性,而且它表示一个人名。《佛教人名库》对该词的解释如下:
吉祥:鸡足山直隶僧。明天启年间,与鸡山各直隶僧儒能、排寂、周辉、悟宽等连名具诉,奉批允赏立直隶勒碑,蠲免一应夫马杂差。鼎革之后,内里排将僧等,妄扳置日夫马杂差,诸僧人再次连名上诉。康熙二十一年(1682),经大理府批示,各僧遵照嗣后输纳钱粮,止许本山、本剎田地,其他杂差悉行豁免,以永名山香火。
可见,该词的确能够充当人名。但是这种词型较丰富的词要不要最终收录进古籍专名数据库中,需要具体情况具体分析。
还有另外一种情况需要考虑,比如某一词条,即使在某些专名词典中已收录。但是在大规模古文语料中,该词的成词概率较低。从古籍信息处理的角度来看,这种词形并不能很好地服务于专名的自动识别。
比如,“何求”作为一个词时可以在古代汉语中充当专有名词(人名),《中国历史人名大辞典》解释如下:
何求:南朝齐庐江潜人,字子有。宋文帝元嘉末,历官丹阳、吴郡丞,太子中舍人。宋明帝泰始中,妻亡,还吴,累迁不拜。齐武帝永明间,征太中大夫,又不就。隐居虎丘。初求父有风疾,无故害死求母,坐法死,求兄弟以此无宦情。
“何求”作为一个字串时可以切分成两个词,即“何”和“求”。
下面是两个关于“何求”的语料实例(词性标记规范参考LDC发布的《左传》语料库①):
①何求/nr字/v子有/n,/w庐江/n灊/n人/n也/u。 /w (《南齐书·高逸传·何求》)
②不/d知/v我/r者/r,/w谓/v我/r何/r求/v。 /w(《诗经》)
不难发现,①中“何求”是一个人名,而在②中则是两个独立运用的词。
综合以上所述,语法功能较活跃的一些词(既可以充当专名,又可以充当其他词类)以及成词概率较低的一些专名要不要最终收录进专名数据库,需要对这些词进行专名置信程度的统计计算。如果一个词在古代汉语中成词概率较高,而且该词经常作为专名出现,那么这个词作为专名置信程度一般;如果一个词成词概率较低,或者不经常作为专名出现,那么这个词作为专名的置信程度较低;如果一个词只能作为专名出现,且结合紧密,那么这个词作为专名的置信程度极高。
该研究以完成分词与词性标注任务的先秦22本古籍语料、史记语料以及中古语料为基础(语料总词次为261万),将专名数据库中的所有专名与该语料中的词或者字串进行匹配计算,统计出每个专名的置信程度,用0、1、-1来表示置信程度的高低。具体统计方法如下:
(1)将专名词条与标注好词性的先秦和中古语料进行匹配。在原专名数据库中新增三列数据项:
A专名作为纯字符串在语料中出现的次数
B专名作为一个词且标注为专名词性的词例在语料中出现的次数
C专名作为一个独立运用的词且词性不属于专名的词例在语料中出现的次数
(2)根据新得出的三列词频信息计算词语置信程度并将统计结果新增至数据库“grade”字段中:
当A、B、C三列字段统计结果均为0时,grade属性为0。 当三列字段统计结果有不为0的情况,则继续进行如下计算:
若专名词长等于1且B/A=1,则grade属性为1,否则为-1;若词长大于1:如果B/A=1,且C/B<1,则grade属性为1;如果B/A<0.1或C/B>1,则grade属性为-1;如果0.1<B/A<1且C/B<1,则grade属性为0。部分统计结果如表8所示。
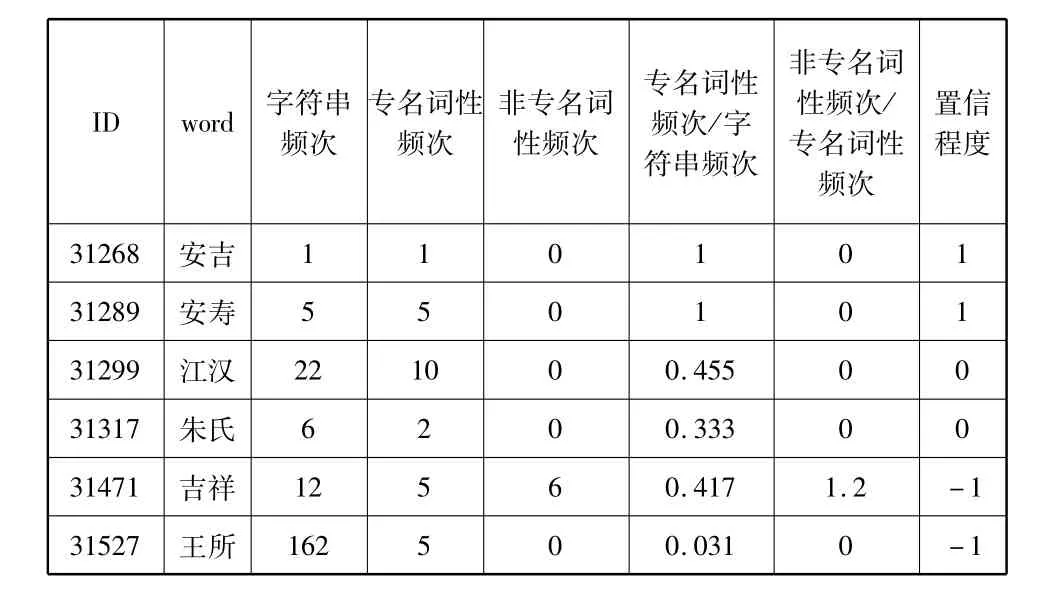
表8 专名置信程度的部分统计
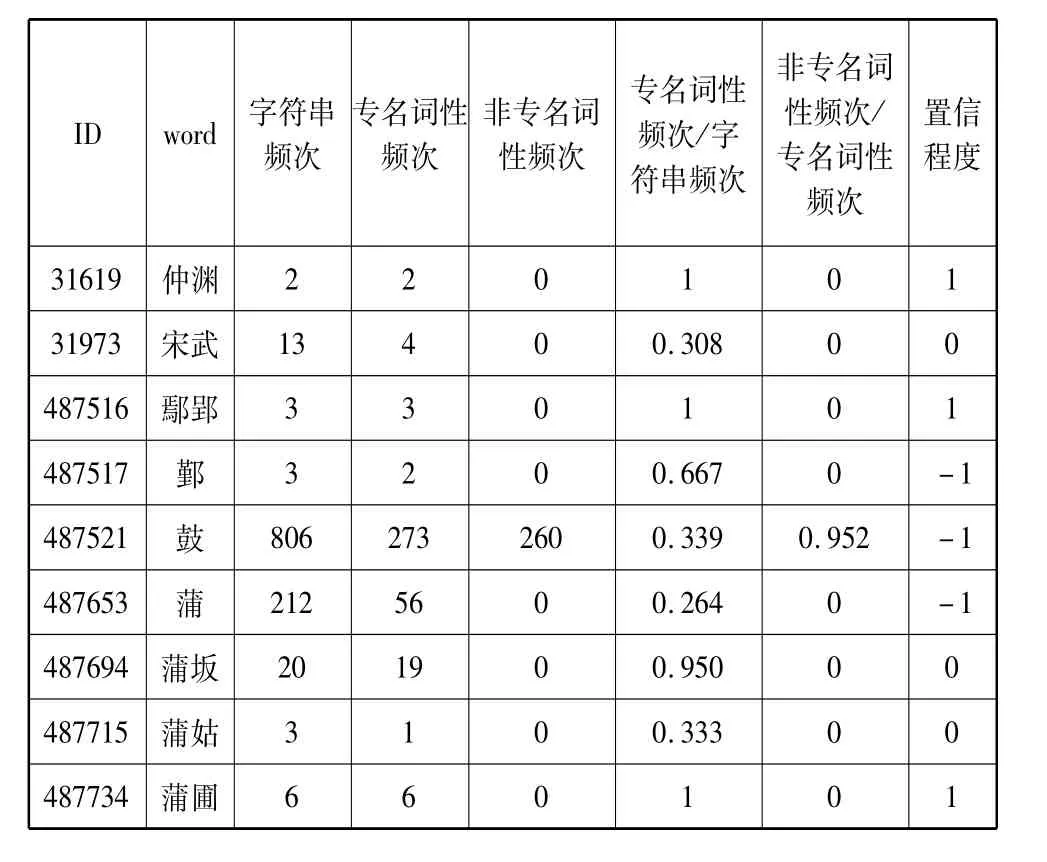
ID word 字符串频次专名词性频次非专名词性频次专名词性频次/字符串频次非专名词性频次/专名词性频次置信程度31619 仲渊2 2 0 1 0 1 31973 宋武13 4 0 0.308 0 0 487516 鄢郢3 3 0 1 0 1 487517 鄞3 2 0 0.667 0 -1 487521 鼓806 273 260 0.339 0.952 -1 487653 蒲212 56 0 0.264 0 -1 487694 蒲坂20 19 0 0.950 0 0 487715 蒲姑3 1 0 0.333 0 0 487734 蒲圃6 6 0 1 0 1
通过进一步分析,发现古代汉语中某些单字词只作为专名使用。这种只能作为专名的单字词在数据库中有72条,其中人名8条,地名32条,书名32条。部分统计结果如表9所示,其中ns表示地名,nr表示人名,nx表示其他专名。
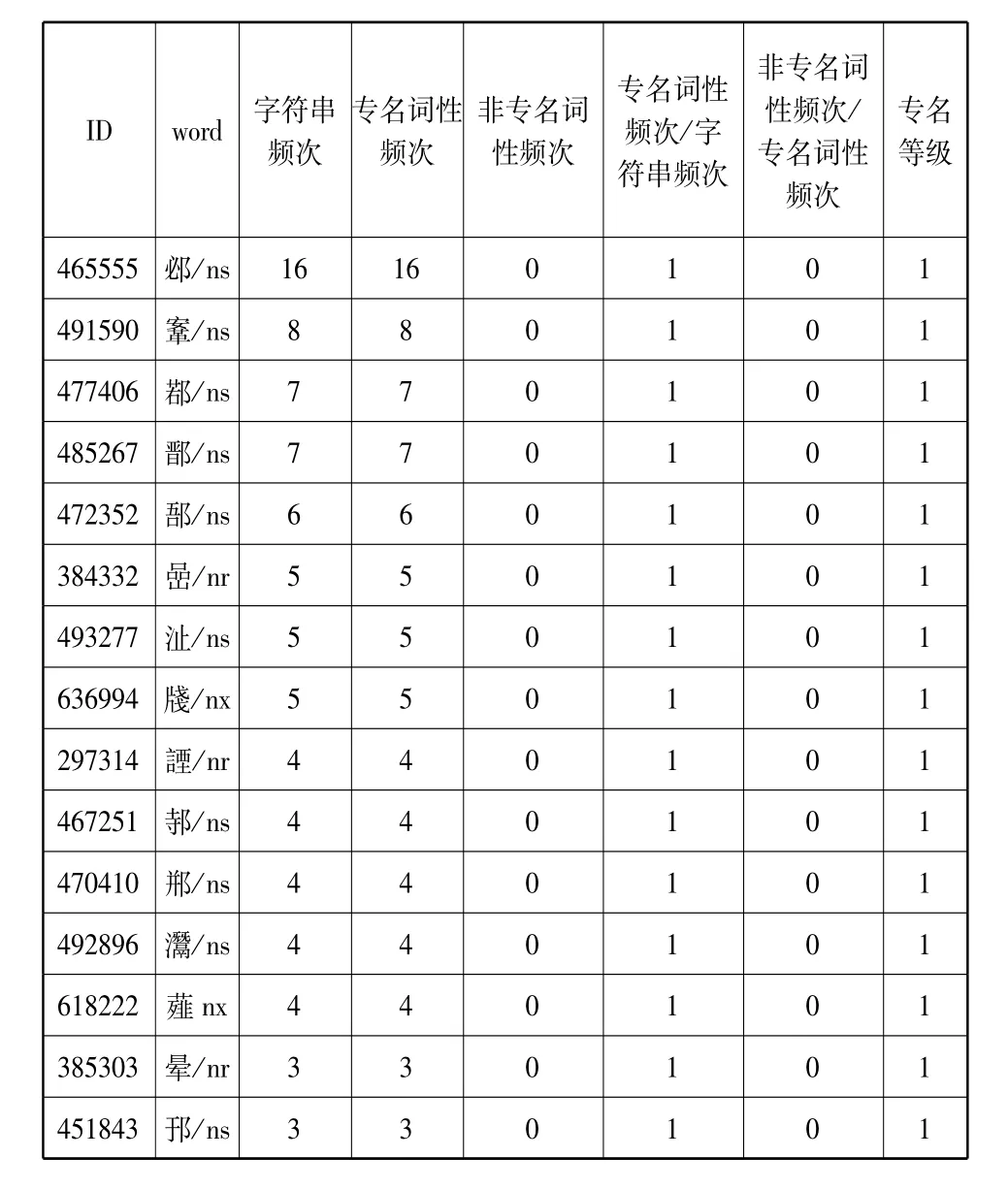
表9 频次最高的前15个只能用作专名的单字词
3.2 专名数据库中重要专名统计
古籍专名数据库中所收录的专名历史跨度大,词条数目众多。有的专名大家耳熟能详,有的专名并不常见。一个专名有可能被多部古籍辞典以及多种期刊文献所记载,根据专名的各个出处,对所收录的专名进行量化统计,可以清楚地看到有哪些专名在历史上打下的烙印比较深。本文对古籍专名数据库中专名出处较广的人名、地名、书名进行了统计分析,得到了每个专名出处的频次信息,并进行降序排列。如表10所示。
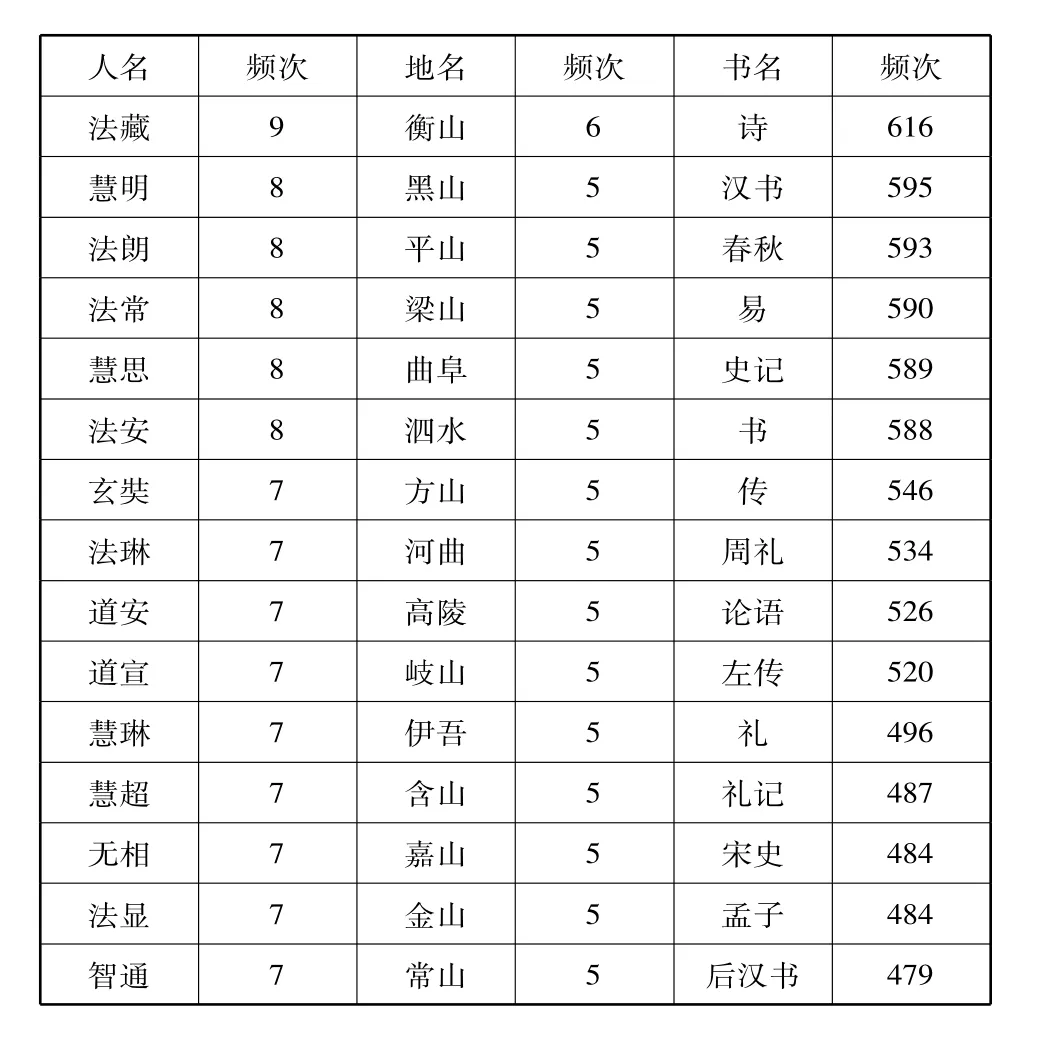
表10 出处最多的前15个专名词条(人名、地名、书名)
不难发现,排名靠前的人名多为佛教僧人,经过分析发现,该数据库收录的佛经文献资源来源广泛,包括《佛教人名库》《佛经词典》《历代名僧词典》《阅藏知津》等,并且一些有名的僧人不仅在佛经词典资源中有所收录,在普通的历史词典中也有收录,比如“法藏”在《中国历史大辞典》就有所记载。大家耳熟能详的一些人名,比如“王安石”“杜甫”“朱熹”等排名也很靠前,他们都有四个不同的出处。在地名两列中不难发现,排名靠前的多是山名、水名,而国名、城邑名排名相对靠后。在书名两列中,可以发现排名前15的书名大家都很熟悉,四书五经基本都涵盖在内。
3.3 古代专名中的高频字
通过对数据库中各专名本身的构词材料进行统计,比如,统计出某类专名中哪些字用的比较频繁,可以窥探出古代专名的一些命名规律。统计结果如表11所示。
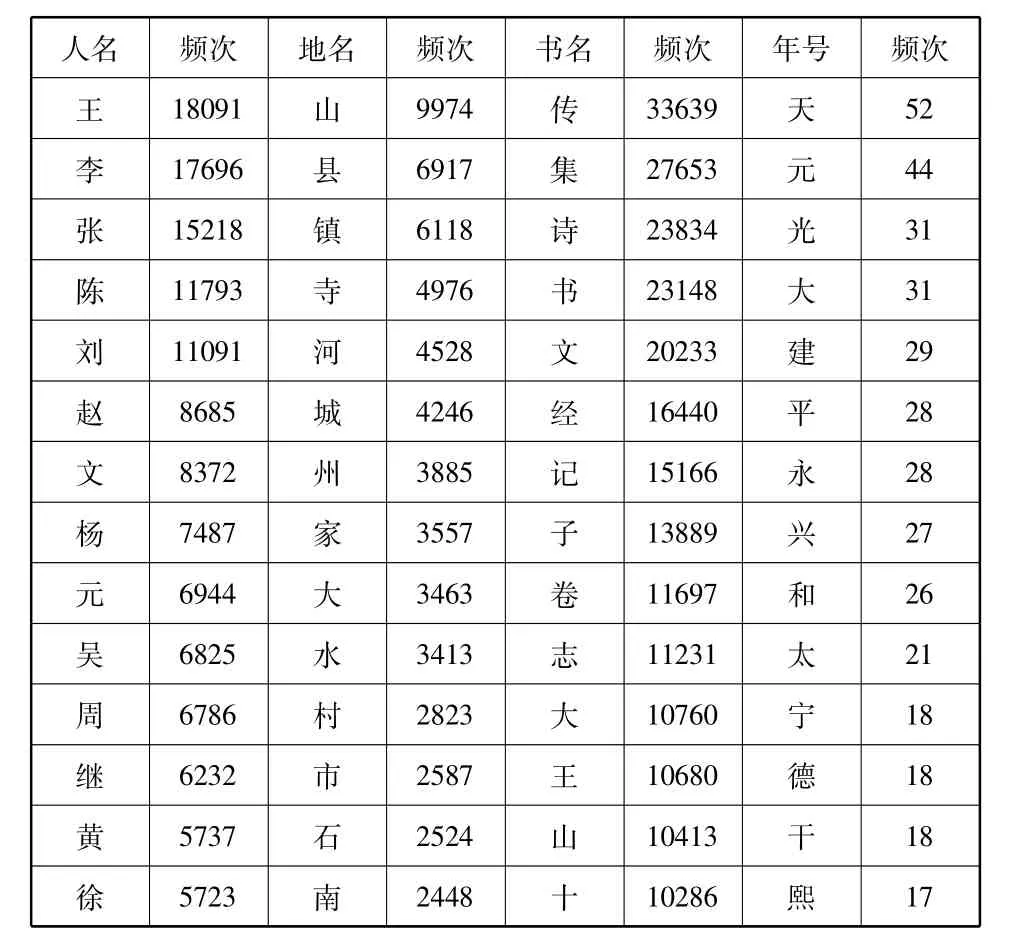
表11 古籍专名中前20个高频字统计

人名 频次 地名 频次 书名 频次年号 频次宗5641安2364论9887宝17孙5547口2255公9362始16林5473江2123三9299嘉16郑5376溪2089中8802正16大5356塘1998图8714延15 15朱5206西1990篇8614泰
从上表人名两列信息可发现,古籍中有很多以“氏”结尾的专有名词,除了人名中基本的姓氏以外,“继”“文”“子”“宗”“德”等字占了很高的比例。从地名两列可以窥探到古代地名的基本分类,即国名、城邑名、山名、水名、部族名以及部分建筑名,而且不少地名包含表示方位的词素,如上表中的“南”、“西”。从年号两列信息中可以发现,“天”排在了首位,这也映照了我国历史上封建王朝的体制特点与封建思想。总览全表,可以发现一个有趣的现象,各专名都包含一个相同的高频词素,即“大”。说明此字在古代较为活跃,构词能力极强。《汉语大词典》关于“大”的释义义项极多,可以作为姓,又可以作为一种尊称,还可以表示程度深的含义等,而且古通“太”和“泰”。所以古代各专名采用“大”作为它们的构词材料也就不足为奇了。
4.结语
本文总结了古籍专名数据库的构建方法以及构建过程,介绍了该数据库中的专名构成,简单统计分析了该数据库中各专名的置信程度,以及古籍专名的诸多特点。该库的构建可以服务于古籍文本的专名自动识别,也可以服务于古代汉语理论方面的研究。
当然,该数据库仍然存在一些缺点和不足,例如专名的同名异指问题还没有在数据库中得到有效的区分:某一专名出处众多,不同出处给出不同的解释,有的出处对该专名的解释内容大体一致,有的出处对该专名的解释完全不一致。可以认定这是两个形式相同而内容不同的专名,这种词条需要在数据库中加以标明。古籍专名数据库的构建不是一蹴而就的,需要对数据库进行不断地优化和完善,这也是今后我们工作要努力的方向。
注释:
①LDC左传语料库https://catalog.ldc.upenn.edu/LDC2017T14
