基于不平衡分类的乳腺肿瘤预后预测方法的研究
2019-04-18杨日东张学良
王 哲, 杨日东, 周 毅, 张学良, 王 凯
(1新疆医科大学公共卫生学院, 乌鲁木齐 830011; 2中山大学中山医学院, 广州 510080;3新疆医科大学医学工程技术学院, 乌鲁木齐 830011)
2010年以来中国癌症的发病率和死亡率不断上升,癌症成为主要的死亡原因,也是我国主要的公共卫生问题之一[1]。乳腺癌(Breast Cancer)是乳腺组织中的细胞不正常分裂和增生的恶性肿瘤,是女性最常见的癌症[2]。近年来,随着乳腺癌的早期诊断和早期治疗,患者的总体疗效明显提高。据估计,通过减少可改变风险因素的暴露可以避免近60%的癌症死亡[3]。因此,对乳腺癌预后状态进行预测,从而寻找有效的抑制途径,是进一步提高乳腺癌患者生存率的关键,具有重大的研究意义。
传统的分类器是基于均匀的数据分布的基础上,而乳腺肿瘤患者的生存数据是不平衡的。虽然乳腺癌是女性癌症死亡的第二大原因,但其存活率较高。早期诊断中,97%的女性存活5年以上[4],所以数据是不平衡的。不平衡数据具有数据稀缺、噪声、决策面偏移、评测指标等传统分类器难以解决的问题[5]。必然会导致多数类精度高而少数类精度不高的问题,然而在乳腺肿瘤的预后预测分析研究中,少数类(死亡患者)的信息对临床医生的研究更有价值,通过少数类发现危险因素可更好地提高生存率。因此,提高少数类的分类精度,对于乳腺肿瘤不平衡数据的研究是十分重要的,本研究结合过采样技术(SMOTE、Borderline-SMOTE和ADASYN)或欠采样技术(One-Sided Select)对乳腺癌患者的生存预后进行预测,现报道如下。
1 资料与方法
1.1资料来源本研究所用数据来源于广州市某三甲医院的乳腺癌患者预后数据,随访了1 845名乳腺癌患者,均为女性。
1.2研究方法采样技术是解决类不平衡的方法之一,它通过对数据样本的预处理,从而达到数据平衡的效果。本研究将改进提升树与结合了过采样技术(SMOTE、Borderline-SMOTE和ADASYN)或欠采样技术(One-Sided Select)对乳腺癌患者的生存预后数据进行预处理。经典决策树(classical decision tree)、条件决策树(conditional inference tree)、随机森林(random forest)[6]、支持向量机(support vector machine,SVM)分类算法构造分类器,从而对乳腺肿瘤预后状况进行预测。
1.3分类器性能比较在一个二分类的混淆矩阵中,实际为正类也被预测为正类的样本称为正确正类TP(true positive),实际为正类被预测为反类称为错误反类FN(false negative),实际为反类被预测为正类的称为错误正类FP(false positive),实际为反类被预测为反类的称为正确反类TN(true negative)。表1为二分类分类器中常用的混淆矩阵,将大样本类别称为负类,小样本类为正类。

表1 混淆矩阵
准确率(accuracy)是最常用的选择预测效果的统计量,即分类器能否总能正确划分样本。尽管准确率承载的信息很大,这一个指标仍然不能选出最准确的模型,尤其是针对类不平衡数据,我们还需要其他信息来评估不同分类方法的有效性。敏感度(sensitivity)、特异性(specificity)、正例命中率(positive predictive power)、负例命中率(negative predictive power)也被用来评价分类器的分类效果,具体含义见表2。

表2 预测准确性度量
根据表1中的内容,具体计算方式如下:
(1)
(2)
(3)
(4)
1.4数据处理Python实现采样技术的算法;使用R语言3.5.0,通过rpart包构造经典决策树模型和条件决策树模型,randomForest包可用于生成随机森林,通过e1071包构造支持向量机模型。
2 结果
2.1模型的建立实验使用有监督机器学习领域中的方法对乳腺肿瘤的生存状态进行分类研究。将全部数据分为一个训练集和一个测试集,使用训练集建立预测模型,测试集用于测试模型的准确性。随机分出70%作为训练集,测试集包含样本单元的30%。数据包含年龄、肿瘤大小、婚姻状态、临床分期、病理分级、T-stage、雌激素受体、孕激素受体等15个特征,特征描述见表3、4。
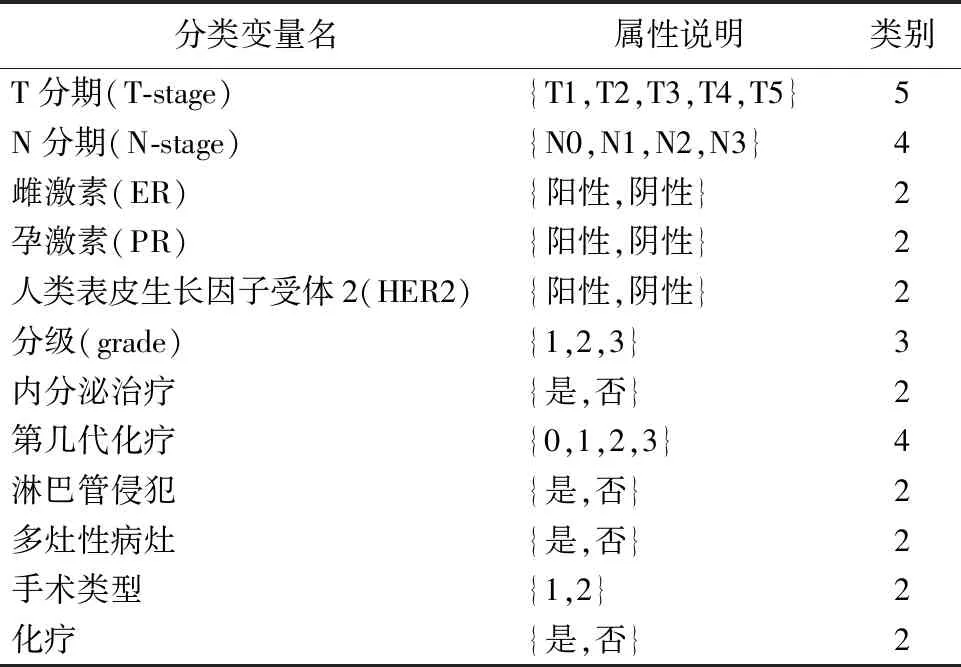
表3 分类型自变量
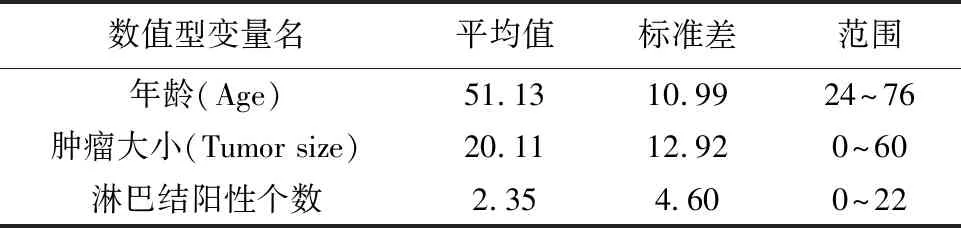
表4 数值型自变量
2.2训练集不平衡数据的分布情况在1 845例数据中,存活患者1 668例,未存活患者176例。用SMOTE、Borderline-SMOTE、ADASYN、One-Sided Select算法对乳腺肿瘤数据集进行预处理,使得预测变量乳腺肿瘤的生存状态成为平衡数据。数据在各种预处理后的多数类、少数类及不平衡比分布情况见表5。
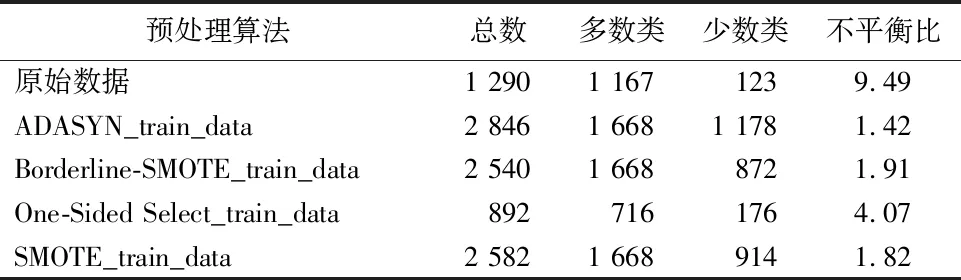
表5 训练集不平衡数据的分布情况
2.3不同采样方法机器学习分类性能的比较在使用经典决策树、条件决策树、随机森林和支持向量机4种机器学习方法进行预测时,未经采样技术处理的原始数据集在预测准确率上均表现良好,其中支持向量机准确率最高,达到了90.42%,条件决策树的准确率为90.05%,经典决策树为89.53%,随机森林为89.51%。在预测准确率最高的支持向量机算法中,针对敏感度的预测仅为0,条件决策树和随机森林仅为2%和4%,经典决策树在未经处理的数据集预测敏感度上表现最好,为11%。结合采样技术对敏感度进行预测发现,条件决策树的预测效果最好,为58%,相较于原始数据集,采用同一种机器学习算法比较后发现,敏感度提升了56%。支持向量机结合SMOTE技术将敏感度由0提高到了43%。经典决策树结合One-Sided Select技术将敏感度提高了36%,随机森林结合One-Sided Select技术将敏感度提高了32%。因此,在使用采样技术针对数据进行预处理之后,预后预测的敏感度均得到提升。比较预测的特异性发现,原始数据集的特异性相较于经过采样技术处理后的特异性,支持向量机的特异性最高,为100%,其次是条件决策树和随机森林,均为99%,经典决策树为98%。观察正例命中率发现,总体的正例命中率偏低,针对不同的机器学习算法,采用不同的算法获得的效果不同。其中,采用One-Sided Select结合支持向量机算法的正例命中率最高,为40%。各预测方法结合各采样技术的负例命中率整体较高,采用One-Sided Select结合条件决策树的负例命中率最高,为95%,具体见表6。
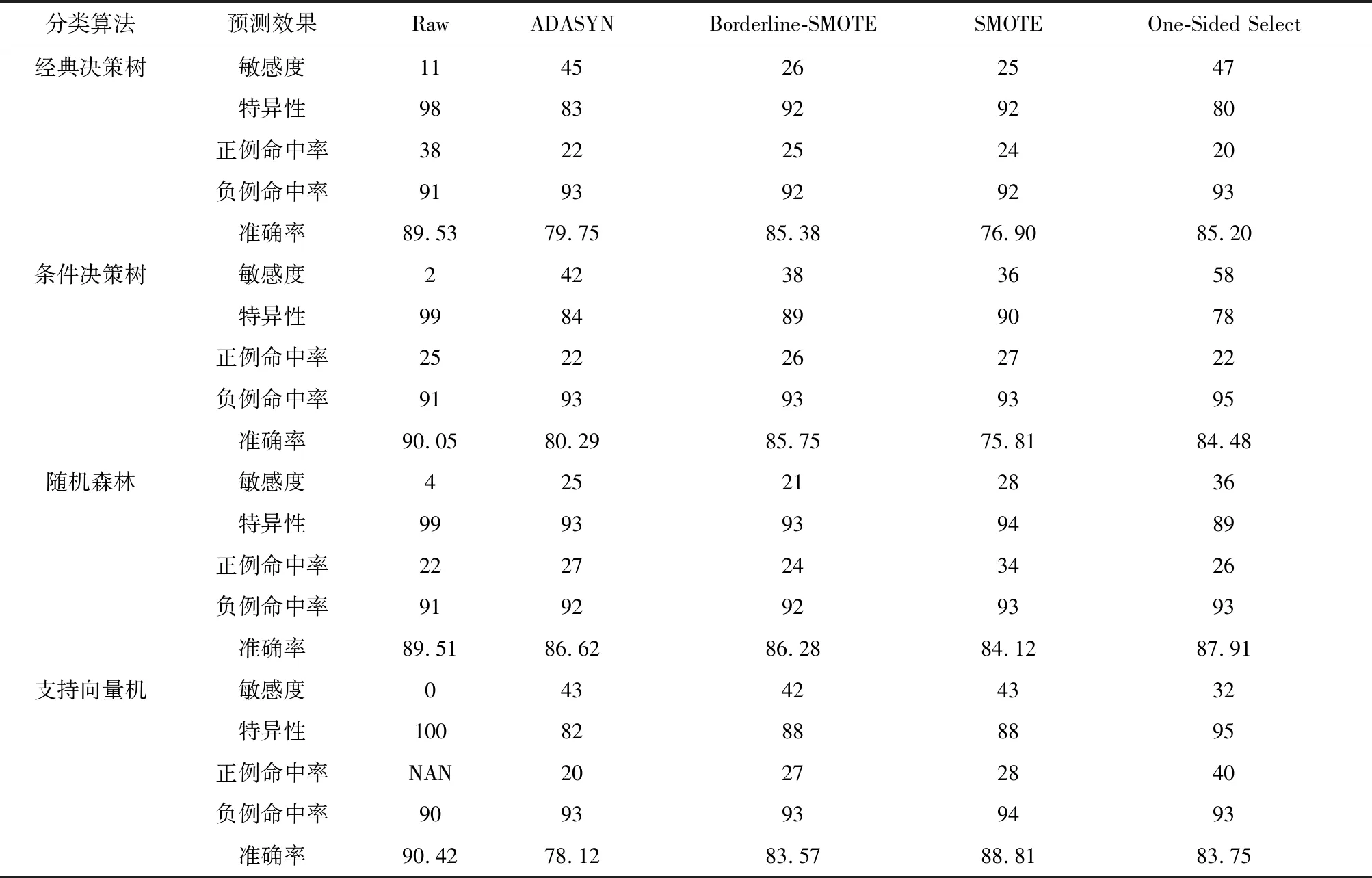
表6 不同采样方法机器学习分类性能比较/%
3 讨论
传统的乳腺癌预后研究是基于统计学的方法寻找影响因素,而利用机器学习算法,根据影响因素构建分类器的研究较少。传统机器学习算法也没有考虑数据集的类不平衡问题,鉴于此,本文选用SMOTE、Borderline-SMOTE、ADASYN、One-Sided Select共4种方法处理类不平衡数据,并通过经典决策树、条件决策树、随机森林、支持向量机共4种机器学习模型进行分类结果预测。结果显示,支持向量机预测准确率最高,达90.42%。使用欠采样方法One-Sided Select技术,结合条件决策树预测,在不平衡的乳腺肿瘤数据集中预后预测效果最好,将敏感度由2%提高到58%,提高了56%。支持向量机在预测未经处理的数据集时特异性最高,为100%。采用One-Sided Select结合支持向量机算法的正例命中率最高,为40%。采用One-Sided Select结合条件决策树的负例命中率最高,为95%。因此,可根据不同临床需求,选择最适合的采样技术结合预测方法来预测结果。同时也说明目前收集数据样本数量虽大但代表性差,因此可以对数据集进一步做特征分析,从而选出同临床理论相符合的具有高代表性的特征变量。临床医师更加关注的是造成患者死亡的危险因素,针对类不平衡数据的过采样和欠采样方法在分类性能上有一定的提高,尤其能大大提高灵敏度,但准确率下降,因此在后续针对不平衡数据的处理问题研究中,我们将考虑通过欠采样与过采样结合,进一步研究能否提高模型性能。
