一个多维次成分并行提取算法及其收敛性分析
2019-04-12董海迪何兵刘刚郑建飞
董海迪 何兵 刘刚 郑建飞
在信号处理领域,将信号自相关矩阵最小特征值对应的特征向量定义为信号的次成分(Minor component,MC).次成分分析是一种从信号提取次成分的技术.次成分分析已经广泛应用于计算机视觉[1]、波达方向估计[2]、FIR滤波器设计[3]、曲面拟合[4]等领域.目前,基于神经网络的次成分分析算法是国际上的一个研究热点.相比传统的特征值分解算法,神经网络算法具有计算复杂度低、能够在线实施和跟踪非平稳信号等优点[5].
根据提取次成分的维数,次成分分析算法可以分为:单维次成分提取、次子空间跟踪和多维次成分提取等三类[6].目前,学者们已经提出了大量的单维次成分提取算法和次子空间跟踪算法[2−3,6],而多维次成分提取算法还非常稀少.传统的多维次成分提取大多是通过串行提取或空间旋转来实现[6].串行提取法是首先利用单维次成分分析算法提取信号的第一个次成分,然后利用膨胀技术依次提取下一个次成分.串行算法的缺点在于存储器需求量大、提取时间有延迟、误差累计传播等.空间旋转法是首先利用次子空间跟踪算法提取信号的次子空间,然后进行空间旋转得到多维次成分.空间旋转法的缺点在于计算复杂度的增加[7].
相比串行提取法和空间旋转法,并行算法能够直接从信号中提取多维次成分,且不需要中间转换过程,因此可以避免两类算法的缺点.最早的并行提取算法是由芬兰学者Oja提出来的[8],该算法虽然可以并行提取多维次成分,但是其要求信号的最小特征值必须小于1;Mathew等提出的算法[9]虽然没有特征值大小的限制,但是该算法只适用于信号具有多个相同的最小特征值;基于Douglas次子空间跟踪算法,Jankovic等[10]提出了一种新型多维次成分提取算法—MDouglas算法,虽然该算法对特征值大小没有要求,但是需要事先选取参数,而且该参数选取的结果直接影响着算法的收敛性能;采用主/次成分转换机制,Tan等提出了一种并行提取算法[11],该算法的缺点在于需要事先对最小特征值进行估计;Bartelmaos等所提出的MCA-OOJAH算法[12]虽然对信号特征值没有要求,但是需要在每次迭代过程中增加模值归一化措施,以保证算法的收敛性.频繁的模值归一化操作极大地增加了MCA-OOJAH算法的计算复杂度.综上所述可得,现有算法存在以下几个方面的问题:1)对信号的特征值有要求;2)需要事先选取一些参数;3)算法计算过程复杂.本文研究目的就是发展能够避免上述缺点的多维次成分并行提取算法.
本文的主要贡献可以归纳为以下三个方面:1)提出了一种多维次成分并行提取算法,该算法对信号的特征值没有要求,而且不需要模值归一化操作;2)利用递归最小二乘(Recursive least square,RLS)技术对所提算法进行改进,导出了一种具有低计算复杂度的算法;3)利用李雅普诺夫函数法完成了对所提算法的全局收敛性分析,确定了所提算法的全局收敛域.
论文的结构安排如下:第1节是对神经网络模型和次成分进行简介;第2节是在研究OJAm算法的基础上,提出两种多维次成分提取算法;第3节是采用李雅普诺夫函数法对所提算法的全局收敛性进行证明;第4节是通过仿真实验对所提算法的性能进行验证;论文的总结安排在第5节.
1 问题描述
考虑如下一个具有多输入多输出的神经网络模型:
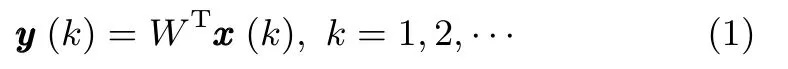
其中,y(k)∈Rr×1是神经网络的输出,W∈Rn×r是神经网络的状态矩阵,输入信号x(k)∈Rn×1是一个零均值的随机过程,这里作为神经网络的输入,n为输入向量的维数,r为所需提取次成分成分的维数.
令R=E[x(k)xT(k)]为输入信号x(k)的自相关矩阵,λi和ui(i=1,2,···,n)分别为自相关矩阵R的特征值和对应的特征向量.根据矩阵理论可得:矩阵R是一个对称非负定矩阵,且其特征值均是非负的.为了后续方便,这里将其矩阵R的特征值按照从大到小方式排列,即
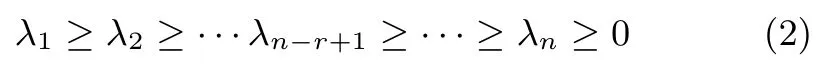
则矩阵R的特征值分解可以表示为
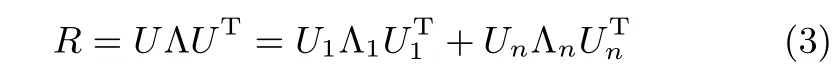
其中,U=[u1, u2,···, un]是由矩阵R的特征向量构成的矩阵,Λ=diag{λ1,λ2,···,λn}是由矩阵R的特征值构成的对角矩阵,U1=[u1,u2,···,un−r]是由前n−r个特征向量构成的矩阵,Λ1=diag{λ1,λ2,···,λn−r}是由前n−r个特征值构成的对角矩阵,Un=[un−r+1,un−r+2,···, un]和Λn=diag{λn−r+1,λn−r+2,···,λn}分别为后r个特征向量和特征值构成的矩阵.
根据定义可知特征值λn−r+1,λn−r+2,···,λn所对应的特征向量un−r+1, un−r+2,···,un称为信号的前r个次成分,而由特征向量un−r+1,un−r+2,···,un张成的子空间V1=Span{ un−r+1, un−r+2,···, un}称为信号的次子空间.子空间跟踪算法的目的是能够估计出子空间V1的一组基,而多维次成分提取算法则是要找到确定的特征向量un−r+1, un−r+2,···,un.
2 多维次成分并行提取算法
2.1 多维次成分提取算法的提出
在文献[13]中,Feng等提出了OJAm次子空间跟踪算法.当OJAm算法收敛时,该算法的状态矩阵只能收敛到信号次子空间的一组正交基,而非多维次成分.通过对OJAm算法进行加权处理,这里提出如下算法
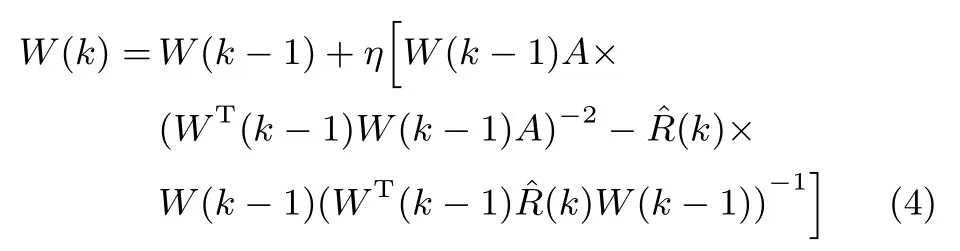
其中,η是神经网络的学习因子,满足关系:0<η≤1;A=diag{a1,a2,···,ar}是一个r×r维对角矩阵,其对角线元素均为正数,且满足关系:ar>ar−1>···>a1>0;(k)为k时刻对自相关矩阵R的估计值,即
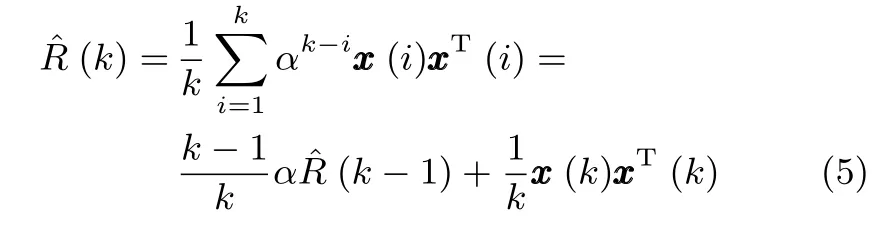
其中,α被称为遗忘因子.如果样本来自于一个平稳的随机过程,则可以令α=1,此时式(5)相当于对x(k)xT(k)取瞬时数学期望.显然当训练样本非常大时,(k)将等价于自相关矩阵R.另一方面,如果x(k)取自一个非平稳的随机过程,则遗忘因子α应该在区间(0,1)内取值,以便对采样样本施加一个宽度为1/(1−α)的遗忘窗.该遗忘窗通过对不同时刻的采样样本赋予不同的权值来降低以往数据对于当前结果的影响.遗忘因子α的取值是由采样信号来决定.通常对于变化缓慢的样本,α的取值要接近1以产生一个较大的遗忘窗;而对于变化快速的样本,遗忘窗口宽度应比较小,此时α则应该在接近0处取值[14].为了方便后续使用,这里将式(4)所描述的算法记为WOJAm(Weighted OJAm)算法.
从式(4)可得:学习因子η控制着算法的学习步长.一般说来,学习因子η越大,算法的学习步长越大,算法的收敛速度也越快,但是学习因子过大有时会引起算法的震荡甚至发散.反之,学习因子越小,算法的学习步长越小,收敛速度也越慢,因此过小的学习因子会降低算法的性能.目前,学习因子的选择主要依靠经验知识,如何选取最优的学习因子仍是一个难以解决的问题.从式(5)可得:遗忘因子主要影响着信号的自相关矩阵.根据文献[15]的研究,遗忘因子对于算法的收敛速度几乎没有影响.
2.2 基于递归最小二乘的改进型算法
虽然WOJAm算法可以提取信号的多维次成分,但其计算复杂度为n2r+5nr2+11r3/3,高于OJAm算法n2r+2nr2+10r3/3的计算算复杂度.通常,高昂的计算复杂度会在一定程度上限制算法的使用范围.由于RLS技术能够在不改变算法性能的前提下降低算法的计算复杂度[16],因此本节将研究基于RLS技术的多维次成分提取算法.
假设在第i(1≤i≤k)次迭代时,输入数据x(i)在神经网络状态矩阵W(k−1)上的投影可以通过式y(i)≈WT(i−1)x(i)来近似(这一近似已经广泛应用于很多算法的推导过程中,并不会影响算法的最终性能[17]).通过这一近似,就可以在任意时刻i(i=1,2,···,k)获得神经网络的输出y(i)的估计值.将式(5)代入式(4)可得:
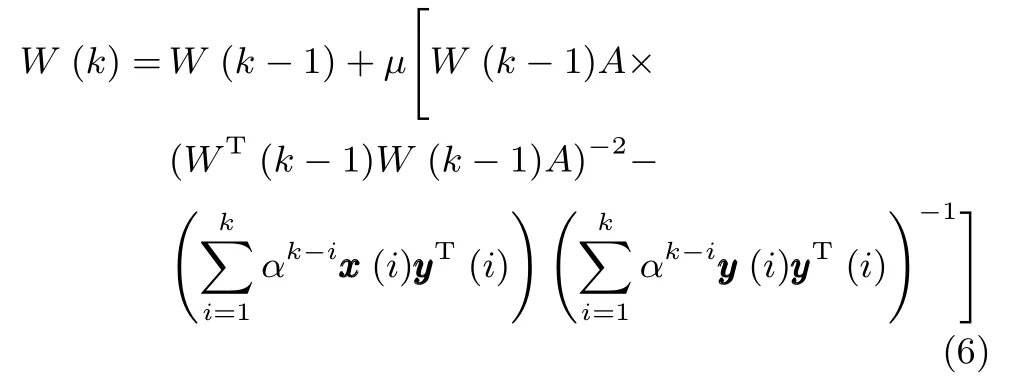
为了方便计算,这里做如下简记:
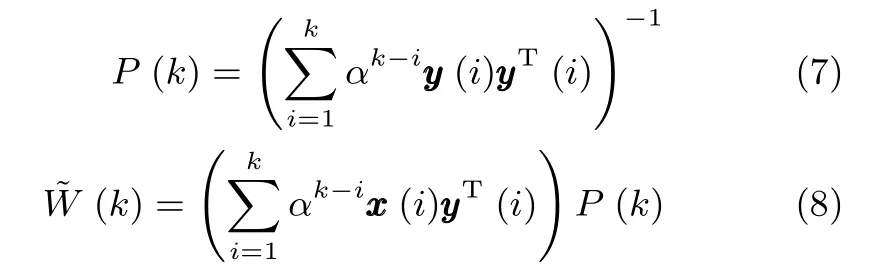
应用矩阵求逆引理[18],则式(7)可以化简为:
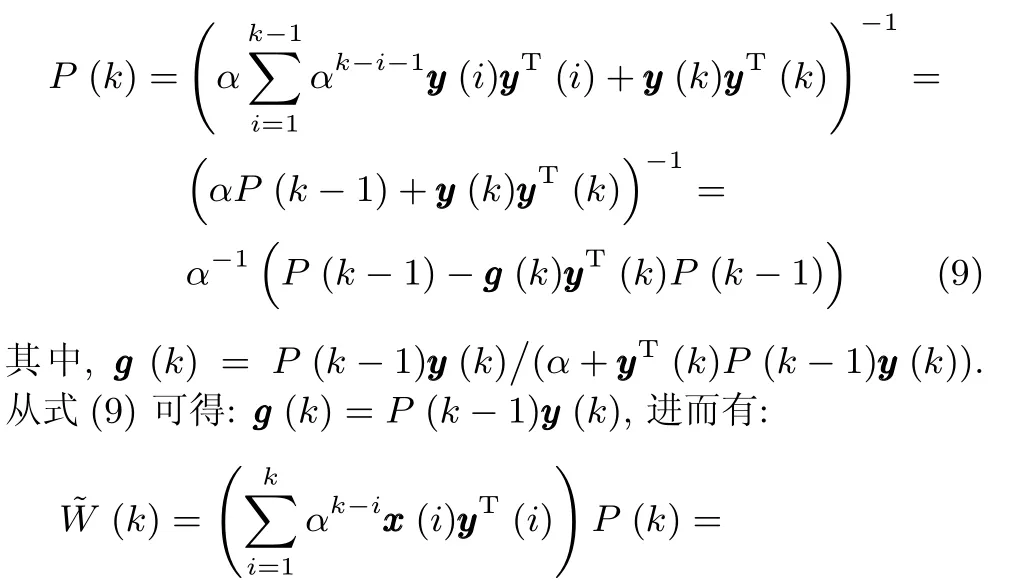
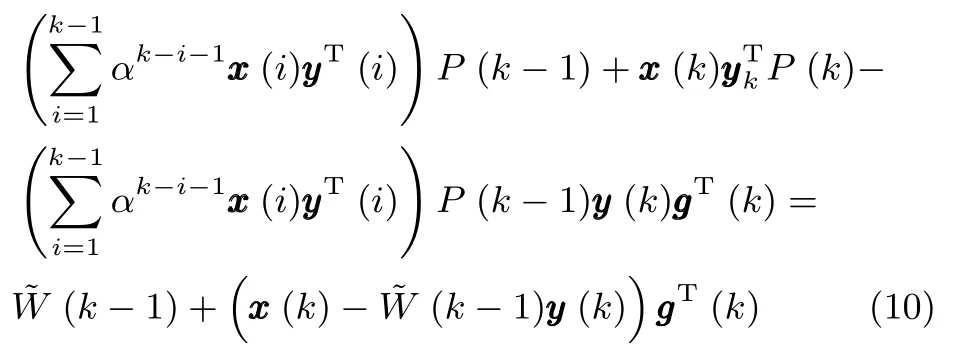
上式推导过程中用到了如下结论:
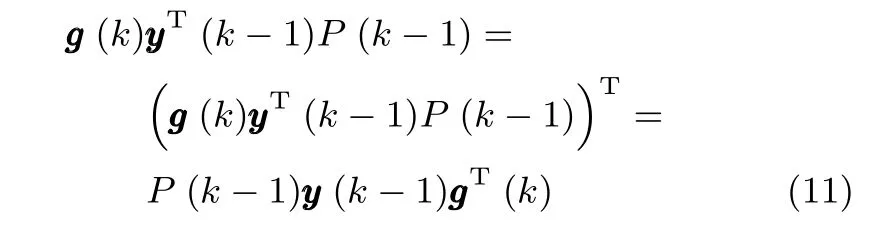
综合式(6)∼(10),就可以利用k时刻的输入向量x(k)和k−1时刻的(k−1)来估计状态矩阵(k),即完成了利用RLS技术对WOJAm算法的改进,因此将该算法记为RLS-WOJAm算法,其计算过程如下.
初始化:令k=0,选择合适的学习因子η和遗忘因子α,其他初始化参数设置为:P(0)=δIr(其中δ是一个非常小的数),(0)=0.
迭代过程:令k=k+1,根据以下方程对神经网络状态矩阵进行更新迭代,
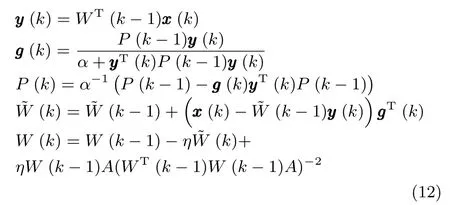
2.3 算法性能评价
本节对所提算法进行分析,并将所提算法与一些现有算法进行比较:
1)将WOJAm算法与OJAm算法进行对比可以发现,两者相差的只是加权矩阵A.OJAm算法只是在对状态矩阵的模值进行了约束,而WOJAm算法则是通过该加权矩阵对状态矩阵不断地实施Gram-Schmidt正交化操作,从而使得状态矩阵能够收敛到所需的次成分.显然,这里加权矩阵的作用是与文献[16]相类似的.
2)从文献[13]可得,OJAm 算法是一个次子空间跟踪算法,算法只能收敛到信号次子空间V1=Span{ un−r+1,un−r+2,···, un}的一组基,不一定是次成分un−r+1, un−r+2,···,un,而所提算法收敛结果则是确定的次成分.根据矩阵理论[18]可得:子空间V1有很多种不同的基,而次成分只是其中一个特殊的基.即所提算法不仅适用于多维次成分提取,而且还可以用于子空间跟踪.因此相比OJAm算法,所提算法具有更为广泛的应用范围.
3)这里将所提算法与近期提出的AMMD算法[11]和MCA-OOJAH算法[12]进行对比.在应用AMMD算法前,必须要对信号自相关矩阵的最大特征值进行估计,由于信号是多种多样,有些情况下是难以估计的,因此这一约束限制了AMMD算法的实际应用.而所提算法在使用前并没有这一要求,因此拓宽了使用范围.MCA-OOJAH算法虽然没有限制条件,但是其需要在每一次迭代过程中增加状态矩阵模值归一化操作,以确保算法的稳定性,由于大量的归一化操作,增加了MCA-OOJAH算法的计算量,而所提算法则没有这些要求,降低了算法的硬件开销.
4)虽然WOJAm算法的计算复杂度为n2r+5nr2+O(n),但是由其导出的RLS-WOJAm算法的计算复杂度将至2nr2+2nr+O(n).这一计算复杂度不仅要低于原来的OJAm次子空间跟踪算法(n2r+2nr2+10r3/3),而且还要比AMMD算法[11]n3+2n2r+O(n)的计算复杂度和MDouglas算法[10]n2r+5nr2+O(n)的计算复杂度要低很多.此外,RLS-WOJAm算法只涉及到矩阵的加、乘和简单求逆操作,因此实施较为容易.
3 算法的全局收敛性分析
文献[13]只是对OJAm算法进行了收敛性分析,并未给出算法的收敛域;本节将通过李雅普诺夫函数法对所提算法的收敛性进行分析,确定出算法的收敛域.借鉴现有文献[19]分析结论可得:所提WOJAm算法和RLS-WOJAm在本质上是相同的,因此两个算法具有相同的全局收敛域.假定输入信号x(k)是一个零均值的平稳随机过程,当学习因子η非常小时,根据随机近似理论[20],则式(4)所描述的离散时间方程可以转化为相对应的一阶常微分方程
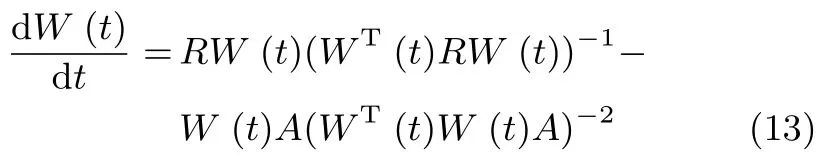
其中,t=µk.通过对式(13)的收敛性分析就可以间接获得所提算法的全局收敛性.事实上,算法的全局收敛性主要是回答以下两个问题[21]:
1)式(13)所描述的动态系统能否全局收敛到自相关矩阵的多维次成分?
2)算法对于次成分的吸引域是多少?或者说确保算法全局收敛的初始条件是什么?
为了回答上述问题,这里构造如下函数:
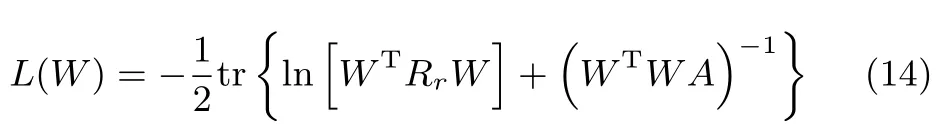
其中,Rr=UnΛnUTn.所提算法的收敛性可以通过定理1来完成.
定理1.L(W)是常微分方程(13)所对应的李雅普诺夫函数,通过该函数可以获得神经网络状态矩阵W在平稳点处的吸引域为
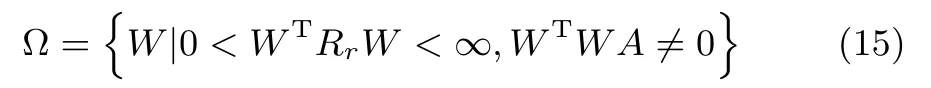
证明.由于L(W)是一个连续函数,则其是连续可微的:
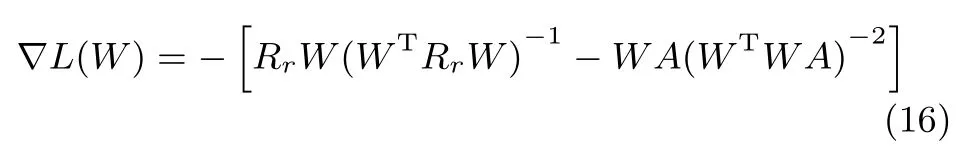
通过链式法则,可以获得L(W)对于时间t的导数
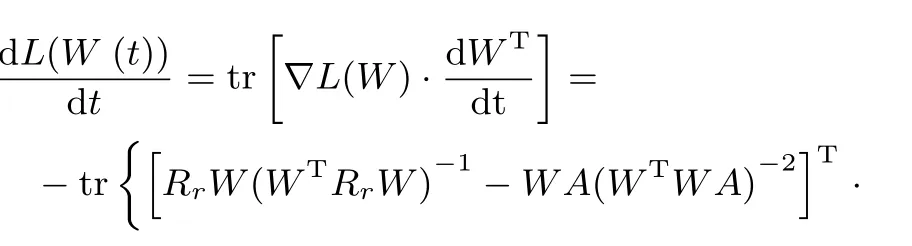
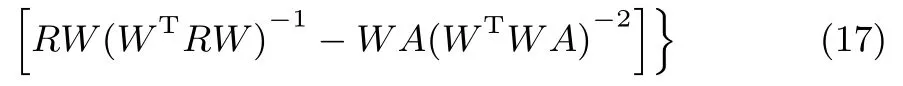
为了方便起见,上式中省略了时间变量t.根据李雅普诺夫第二定律,需要证明如下结论:在域,而在域内(dL(W)/dt)=0.为了完成上述证明,这里将R=代入式(17),并进行适当化简可得:
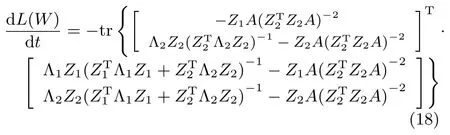
其中,Z1=UT1W和Z2=UTnW.由于WTRrW0,则矩阵Z2是可逆的.因此,必定存在一矩阵B∈R(n−r)×r使得Z1=BZ2成立.将式(18)中的Z1用Z2来表示,则有:
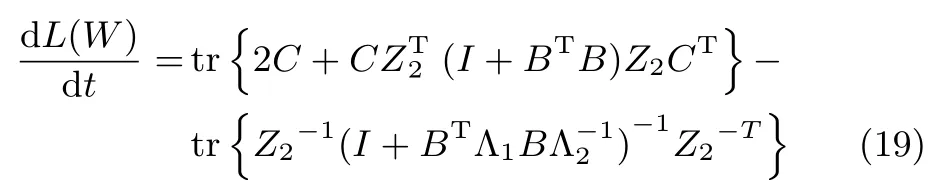
其中,C=(Z2TZ2)−1A−1(Z2TZ2)−1.当W接近平稳点处时,矩阵C可以近似为一个对角矩阵,即C≈C′=diag{c1,c2,···,cr}.此时,式(19)就可以化简为:
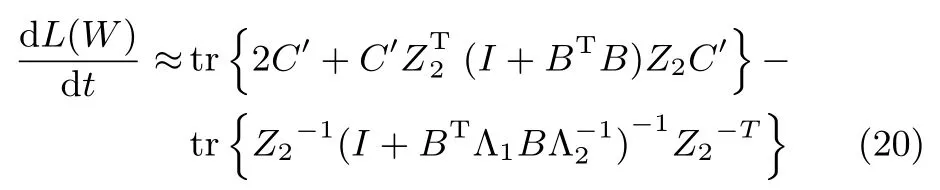
接下来,考虑矩阵Z10的情况.根据矩阵理论有:
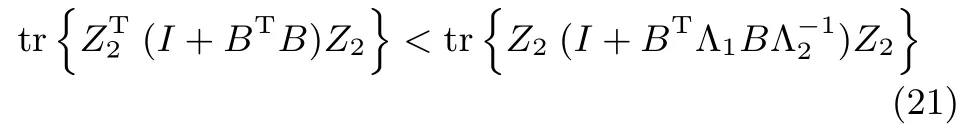
令D=ZT2(I+BTB)Z2,则其特征值分解可以表示为:
其中,Ψ=diag{µ1,µ2,···,µr}是一对角矩阵,µi(i=1,2,···,r)是矩阵D的特征值,Φ是由特征向量组成的矩阵.将式(22)代入式(21)可得:
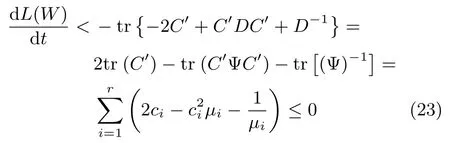
接下来考虑Z1=0的情况,此时式(19)可简化为:
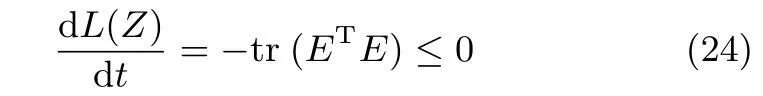
其中,E= Λ2Z2(ZT2Λ2Z2)−1−Z2A(ZT2Z2A)−2.
从式(24)可得:当且仅当E=0时,有dL(Z)/dt=0成立.此时,即.从式(23)和式(24)可得:对于任意的W∈Ω∗均有d(L(Z))/dt<0成立.因此,在域Ω内平稳点是渐近稳定的,即只要初始化状态矩阵W在域Ω以内,则算法(13)全局渐近收敛到自相关矩阵矩阵R的前r个次成分.
4 仿真实验
本节将通过两个数值仿真实验来验证所提算法的性能.第一个实验是考察所提算法提取多维次成分的能力,第二个实验将所提算法与一些现有算法进行对比.在仿真实验过程中,为了衡量算法的性能,这里采取两个评价函数,第一个是方向余弦(Direction cosine,DC):
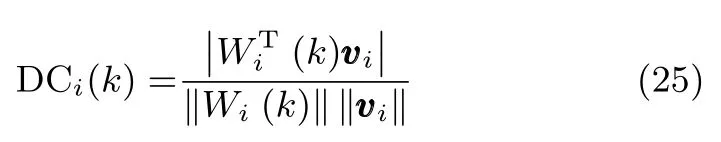
其中,Wi(k)表示在k时刻神经网络状态矩阵的第i列,而vi则是代表着自相关矩阵R的第i个次成分.显然,如果Wi(k)能够收敛到次成分vi的方向,则方向余弦的值应该收敛到1.
方向余弦只能评价状态矩阵的收敛方向,而状态矩阵模值也是一个非常重要的评价函数:
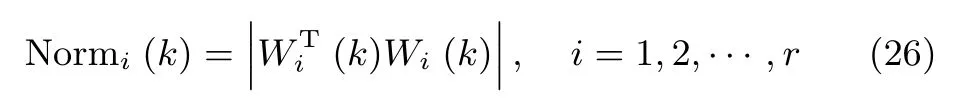
当神经网络状态矩阵收敛到次成分的方向(此时方向余弦等于1)时,如果状态矩阵模值能够收敛到一个常值,则算法是收敛的.
4.1 多维次成分提取实验
本实验考察所提算法提取多维次成分的能力.实验中,输入信号由式x(k)=T z(k)产生,其中,T=randn(10,10)/10是一个随机产生的10×10维矩阵,而z(k)∈R10×1是一个均值为零方差为σ2=1的高斯白噪声序列.这里分别采用WOJAm算法和RLS-WOJAm算法对信号的前3个次成分进行提取(即r=3).两种算法的初始化参数设置如下:根据加权矩阵ar>ar−1>···>a1>0的要求,这里取加权矩阵A=diag{3,2,1};根据0<η≤1要求,同时也要保证算法的收敛性能,这里取学习因子η=0.1;由于输入信号是一个近似平稳的随机过程,所以这里取遗忘因子α=0.998;此外RLS-WOJAm算法中初始化逆矩阵P(0)=0.001×I3,其中I3是一个3×3的单位矩阵.两个算法的采取相同的初始化状态矩阵,且该矩阵是随机产生的.仿真结果如图1∼图4所示,该结果是100次独立实验的平均值.
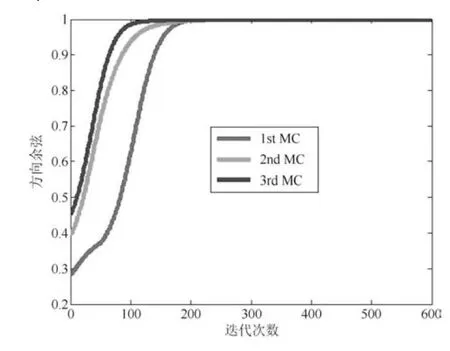
图1 WOJAm算法的DC曲线Fig.1DC curves of WOJAm algorithm
图1和图3分别是两种算法状态矩阵列向量与所求次成分之间的方向余弦曲线;图2和图4分别是状态矩阵各列向量的模值,黑线则是整个状态矩阵的F-范数.从图1和图3中可以看出,经历若干次迭代后,WOJAm算法和RLS-WOJAm算法的方向余弦均收敛到1,即两种算法均最终收敛到了信号次成分的方向.从图2和图3中可得:两种算法在方向余弦收敛到1的同时,状态矩阵模值也已经收到一个常值.综合两图可以得出结论:本文所提两种算法均能够自适应地提取信号的多维次成分,而且具有很好的收敛特性.
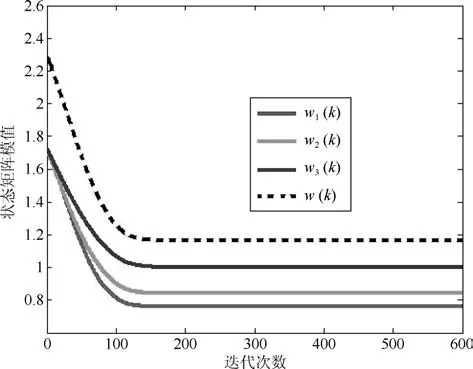
图2 WOJAm算法的Norm曲线Fig.2 Norm curves of WOJAm algorithm
此外对比上述4图可以得出结论:对于方向余弦曲线和状态矩阵模值曲线,WOJAm算法和RLS-WOJAm算法的收敛情况近似相同,只是WOJAm算法的收敛速度略快于RLS-WOJAm算法.由于RLS-WOJAm算法是由WOJAm算法推导而来,两者本质上是相同的,所以上述现象很容易解释.从第2.3节可得,RLS-WOJAm算法的计算复杂度远小于WOJAm算法,因此RLS-WOJAm算法更符合实际使用需要.在后续实验中,将重点对RLS-WOJAm算法的性能进行考核.
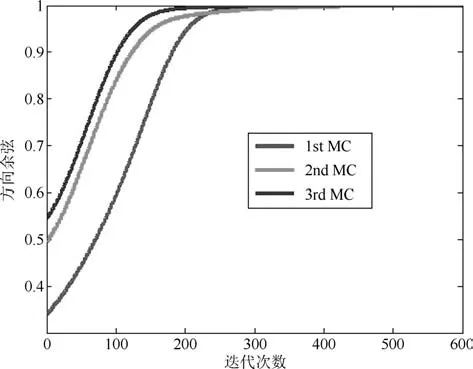
图3 RLS-WOJAm算法的DC曲线Fig.3 DC curves of RLS-WOJAm algorithm
4.2 算法性能对比实验
为了突出所提算法的性能,本实验将所提RLS-WOJAm算法与MCA-OOJAH算法[12]和AMMD算法[11]进行比较.实验中输入信号采用如下一阶滑动回归模型来产生:
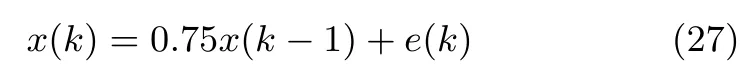
该模型由一个均值为零方差为1的高斯白噪声e(k)作为模型驱动输入.取该模型的10个不连续的输出构成神经网络的输入向量.然后利用上述三种算法对该输入信号的前3个次成分进行提取,即r=3.试验中三个算法采用相同的初始化状态矩阵,学习因子也都设置为0.1,仿真结果如图5∼图8所示.
图5∼图7分别是所提次成分的方向余弦曲线,图8是在迭代过程中三种算法的状态矩阵模值曲线.从图8中可以看出,由于MCA-OOJAH算法在迭代过程中存在模值归一化操作,所以其模值始终为一常值,而RLS-WOJAm算法和AMMD算法虽然没有归一化操作,但状态矩阵模值仍能收敛到一个固定值.从图5∼图7中可以发现:在所有次成分的提取过程中,RLS-WOJAm算法的收敛速度均快于其他两种算法.
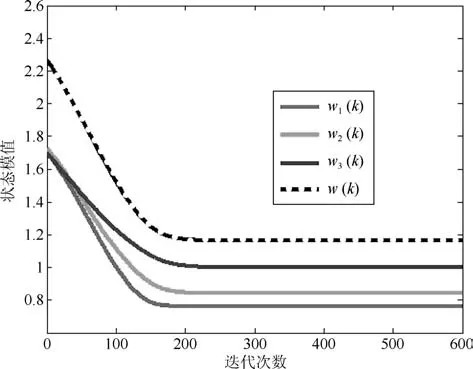
图4 RLS-WOJAm算法的Norm曲线Fig.4 Norm curves of RLS-WOJAm algorithm
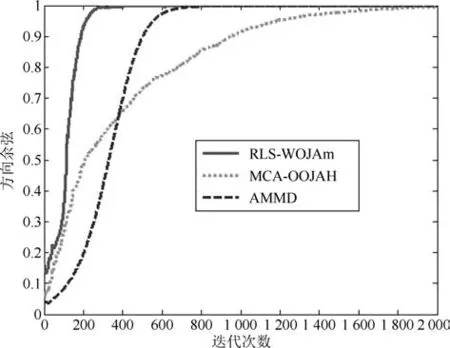
图5 第一个次成分的DC曲线Fig.5 DC curves of the 1st MC
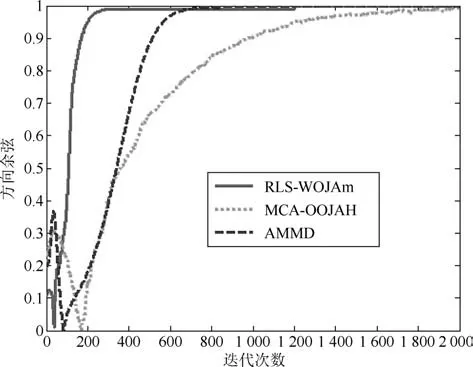
图6 第二个次成分的DC曲线Fig.6 DC curves of the 2nd MC
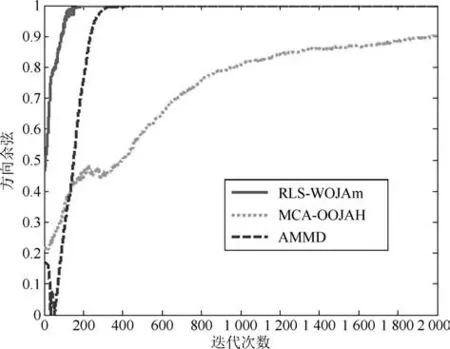
图7 第三个次成分的DC曲线Fig.7 DC curves of the 3rd MC
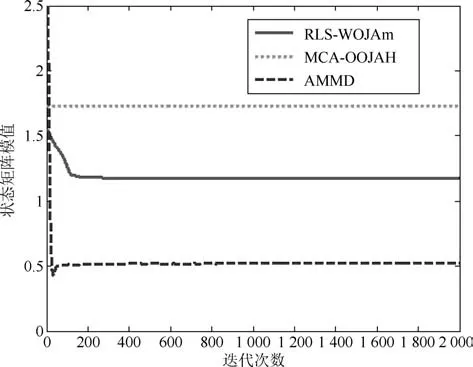
图8 三种算法的Norm曲线Fig.8 Norm curves of the three algorithms
5 结论
本文对多维次成分并行提取算法进行了研究.首先,通过对OJAm次子空间跟踪算法进行加权改造,提出了一种多维次成分并行提取算法;然后,为了降低该的计算复杂度的,采用递归最小二乘技术导出了一种新型算法—RLS-WOJAm算法;相比现有算法,所提算法对信号自相关矩阵的特征值大小没有要求,也没有模值归一化措施;最后,通过李雅普诺夫函数法确定了所提算法的全局收敛域.仿真实验表明:相比现有一些同类型算法,所提算法具有较快的收敛速度.
