基于流形正则化域适应随机权神经网络的湿式球磨机负荷参数软测量
2019-04-12贺敏汤健郭旭琦阎高伟
贺敏 汤健 郭旭琦 阎高伟
磨机负荷(Mill load,ML)是指磨机中球、料、水的总和,是选矿行业磨矿过程的重要参数[1].准确检测ML是实现磨矿过程优化控制、节能降耗及提高磨矿效率、磨矿产品质量的关键.但由于球磨机物理条件限制及其多变量、强耦合和非线性等特性使得负荷参数的监测难度大、性能不稳定、精度低,从而制约了这类基础设备自动化水平的提高.
湿式球磨机负荷检测主要针对能够准确表征ML的磨机内部参数(料球比(Material to ball volume ratio,MBVR)、矿浆浓度 (Pulp density,PD)、充填率CVR(Charge volume ratio,CVR))[2].文献[3]对不同研磨工况下的实验球磨机筒体振动信号进行了分析,并建立了基于主元分析(Principal component analysis,PCA)和最小二乘支持向量机的磨机负荷参数软测量模型,但支持向量机训练时需要求解凸二次规划问题,当样本规模较大时,需要较多的训练时间和存储空间.近年来,众多学者将随机学习思想应用于训练不同结构的神经网络,并提出多种类型的随机权神经网络(Random weight neural network,RWNN)模型,如单隐含层前馈神经网络[4]、多隐含层前馈神经网络[5]、随机权递归神经网络[6]等.文献[7]将RWNN用于软测量建模,有效提高算法学习速度及泛化能力.文献[8]提出磨机负荷参数在线集成建模方法,以解决单一模型存在的信息融合不充分或信息冗余导致的泛化性能差、精度低问题.但是,钢球磨损或物料材质改变导致设备特性缓慢漂移问题依然存在.文献[9]针对多工况系统存在的非线性及工况漂移导致的预测精度下降问题,提出基于即时学习的自适应软测量方法,从而使软测量模型能够一定程度适应工况变化.
然而上述软测量建模方法均要求建模与测试样本数据基本满足独立同分布假设.在实际工业过程中,运行任务与设定值变化、原料及环境变化、设备重组等情况,容易导致系统工况发生突变,工况间数据分布不一致、系统具有多模态特性.对这样的多工况系统建模需要解决模态数据差异性问题,并考虑如何使模型具有适应模态变化、数据漂移的能力.因此本文有针对性的引入迁移学习(Transfer learning)[10]策略,通过迁移原有工况下的知识结构和模型解决待测工况仅有少量标记样本,且待测工况与原有工况数据分布不同的问题.
文献[11]对RWNN模型进行改进,并提出域适应随机权神经网络(Domain adaptive random weight neural network,DARWNN),将其用于解决因传感器特性漂移引起的分类器性能恶化问题.但对数据的空间结构变化并未予以关注,且RWNN的权值随机初始化会使数据产生非线性结构,因此在软测量建模的回归问题中结果并不理想.
本文引入DARWNN,针对未建模的新工况,迁移源域所建模型的知识结构,从而完成或改进新工况的建模任务,实现待测工况负荷参数的测量,同时采用可以保持数据几何结构的流形正则化算法[12−13]建立软测量模型.
综上,本文采用基于流形正则化的域适应随机权神经网络(Domain adaptive manifold regularization random weight neural network,DAMRRWNN),解决工况变化引起的模型失准问题.通过玉米样品的近红外光谱数据集和实验室球磨机数据进行实验验证,表明建立的软测量模型具有良好的适应性和较高的测量精度.
1 相关理论与算法
1.1 域适应随机权神经网络(DARWNN)[11]
域适应随机权神经网络是一种基于单隐含层前馈神经网络(Single-hidden layer feed forward network,SLFN)的学习算法[14].常用的单隐层随机权神经网络数学描述如下:
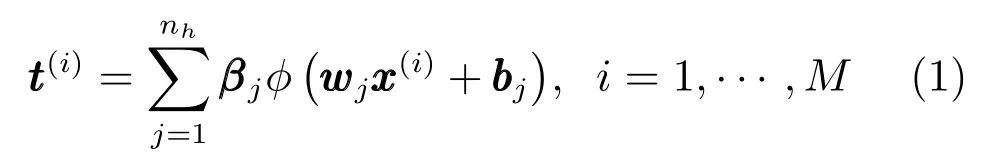
整理矩阵形式为:

式中,β为输出权值矩阵,w为输入权值矩阵,b为偏置.在随机权神经网络中,w和b均随机选取,β通过求解线性方程(3)计算获得,有效解决了基于梯度类学习算法训练速度慢、泛化性能差等问题[15]:
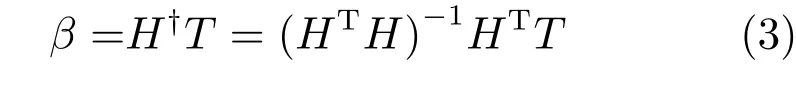
式中,H†表示矩阵H的Moore-Penrose广义逆.文献[16−17]分别在式(3)中添加L1、L2正则项来提高随机权神经网络的泛化性能,改善输出的鲁棒性.
为便于描述多模态问题,以下分别用下标S和T表示源域和目标域数据(在实际工业过程中分别代表原建模工况及待测工况).假设所有源域数据均有标签,目标域数据少部分有标签.DARWNN旨在通过源域所有标签样本及目标域少量标签样本训练得到模型参数,目标函数如下:
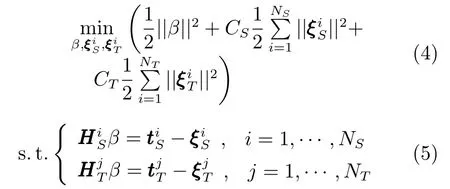
由式(4)和(5)可知,通过目标域的少量标签样本可以使β具有可迁移性.M个目标域的DARWNN架构如图1所示:
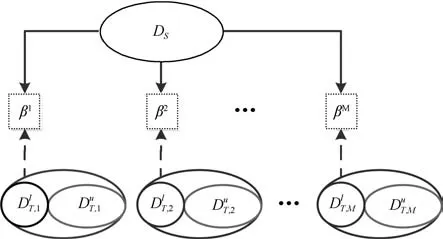
图1 M个目标域DARWNN算法结构Fig.1Mtarget domain DARWNN algorithm structure
图1中实线箭头表示用源域训练数据DS进行学习,虚线表示用目标域有标签数据进行模型训练,是目标域无标签数据.
通过拉格朗日算子对式(4)进行优化,得:
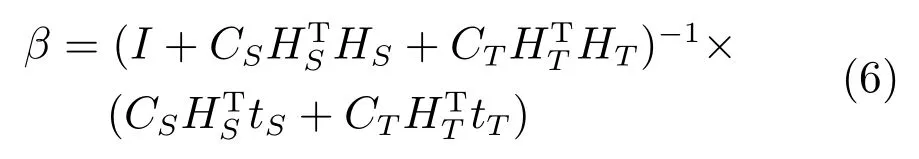
其中,I是维度为L的单位阵.
1.2 流形正则化
软测量建模的回归任务与分类任务所依赖的“聚类假设”有所不同,需要保持源领域和目标领域的数据结构信息,从而使源领域建立的模型能够适用于目标领域数据的预测.流形正则化[18]的本质思想是使数据在新的投影空间(这里指决策空间)中能够保持其在原特征空间(这里指DARWNN特征空间)中的局部几何结构[19−20].该目标函数可以表示如下:
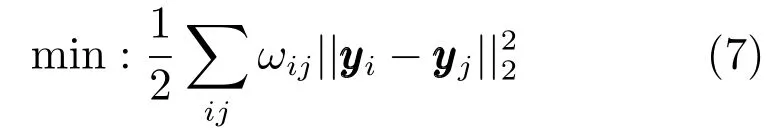
其中,yi和yj分别是样本zi和zj的输出预测向量(在DARWNN结构中,yi是决策层输出向量,zi是隐含层输出向量),ωij表示zi和zj的相似度.通常采用K近邻方法计算两个样本间的相似度,通过高斯核函数计算各点与zzzi的权值,,相应的相似度矩阵W=[ωij]N×N.
最小化式(7)中的目标函数相当于最小化下述函数:
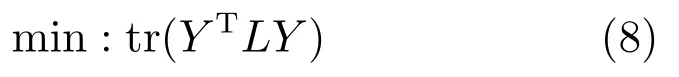
其中,tr(·)表示矩阵的迹,Y是所有训练样本的输出预测向量构成的矩阵,矩阵L表示拉普拉斯矩阵,即L=D−W,D为一个对角阵,其中元素:
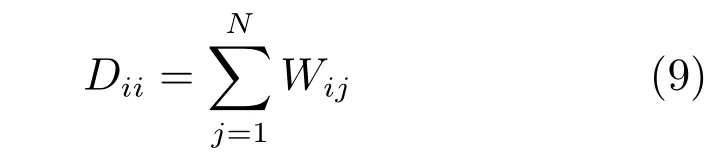
2 软测量策略及实现
综合上述分析可知,为解决建模数据与待测数据不满足独立同分布假设,并且分布差异较大的问题,需要引入域适应算法.同时,在模型建立过程中要求保持数据几何结构相对稳定.因此,本文采用基于流形正则化的域适应随机权神经网络,其在算法上融合了流形结构保持及领域自适应思想,以克服RWNN算法将数据从原始特征空间随机映射到RWNN特征空间时,数据分布差异过大,且可能使数据在RWNN特征空间中呈现出某种难以预测的非线性分布的问题.软测量策略如图2所示.
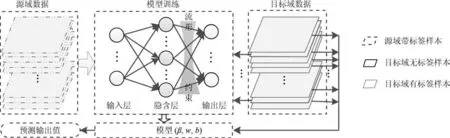
图2 基于流形正则化域适应随机权神经网络的软测量策略Fig.2Soft sensor strategy based on DAMRRWNN
以DARWNN特征空间作为出发点,不同工况下的数据具有不同的内在结构,假设各工况数据分布在该高维特征空间中的一个低维流形上,这种数据的几何结构需要通过上述流形学习的方法加以挖掘,只有保持数据的内在结构才能更好地使迁移学习用于回归任务,所以,这里将式(8)引入到DARWNN目标函数式(4)中,则DAMRRWNN的目标函数如下所示:
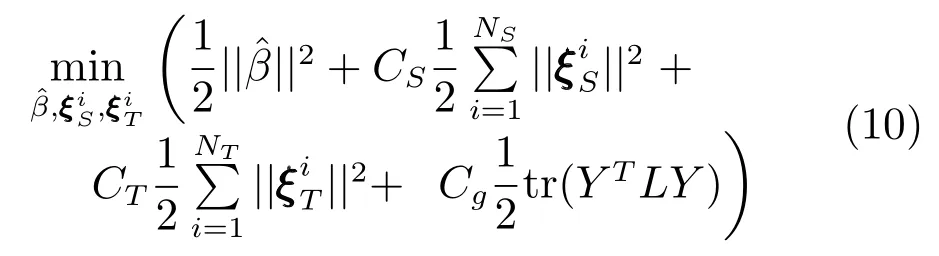
式中,各参数定义与式(4)相同,Cg为流形正则项惩罚系数,拉普拉斯矩阵L是由特征空间中的样本求得,目标函数中第4项的意义是添加流形正则约束项使得在DARWNN的特征空间中相似度较大的数据在决策空间中的距离较小,即在决策空间中保持数据原有的几何性质.目标函数(10)可以表示为:
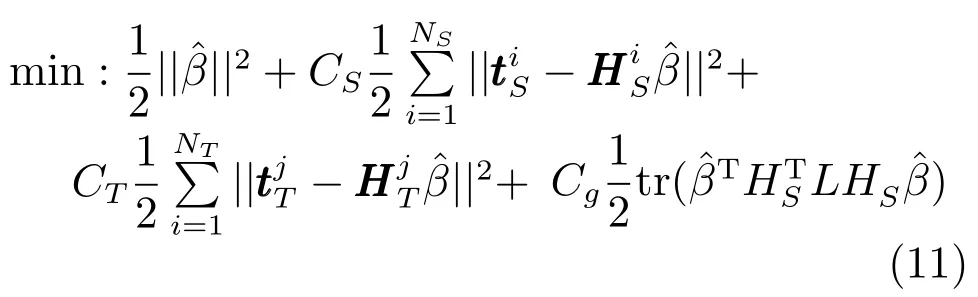
对式(11)求导可得:
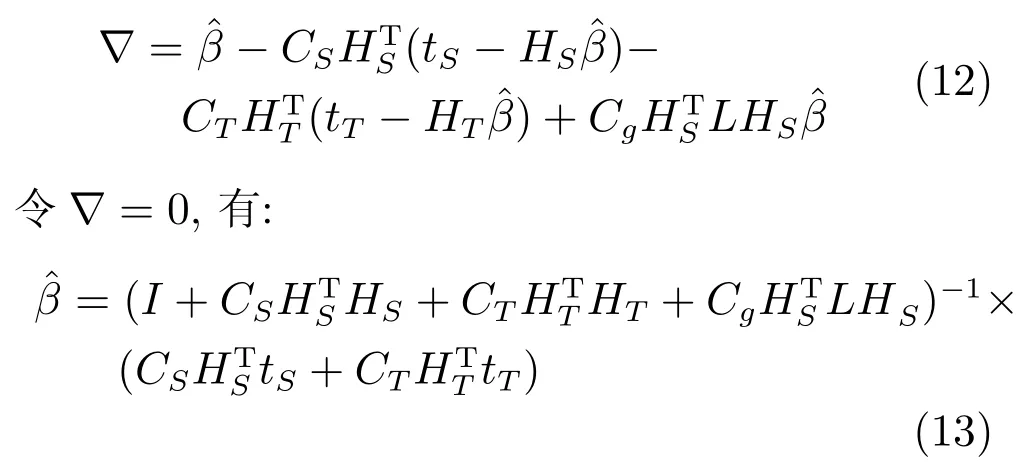
DAMRRWNN算法流程如算法1所示.
算法1.DAMRRWNN算法流程
输入.源域数据,目标域无标签数据少量有标签数据,RWNN的隐含层节点数l,惩罚系数CS,CT,Cg
输出.输出权值,预测标签yj
步骤1.数据预处理.
步骤2.模型参数初始化.
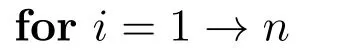
根据RWNN算法训练源域模型,根据式(3)输出权值β0.
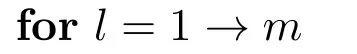
使用目标域标签数据迁移源域模型,根据式(6)计算输出权值β.

3 算法评估及应用
3.1 算法评估标准介绍
为了量化各种方法的预测性能,将均方根误差(Root mean square error,RMSE)、标准均方根误差(Normalized root mean squared error,NRMSE)作为衡量模型预测性能的评价标准,如式(14)和式(15)所示:
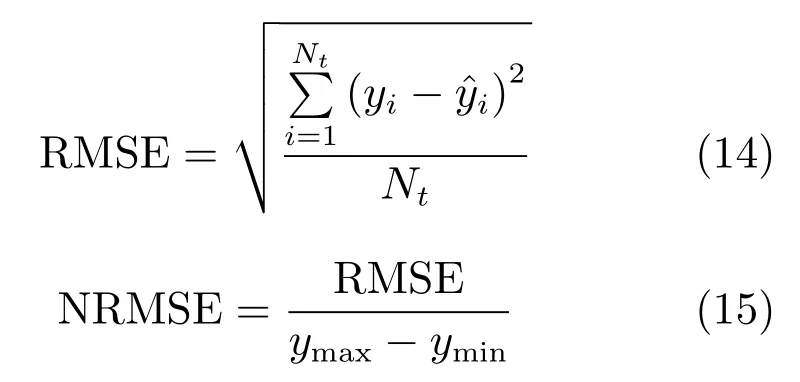
式中,yi和i分别表示第i个样本的实际值和估计值,Nt为测试样本的个数.
3.2 公开数据集
实验采用了玉米样品的近红外光谱数据集验证DAMRRWNN算法的有效性(http://www.eigenvector.com/data/Corn/).光谱数据集包含了3台不同的光谱仪(分别命名为m5、mp5、mp6)上测得的80个玉米样品的近红外光谱,其波长范围是1100∼2498nm.同时包含80个玉米样本的4种组成成分:水分、油、蛋白质和淀粉量的参考值.图3给出了经PCA降维后数据的散点图,表明不同光谱仪测量的数据存在较大的分布差异.
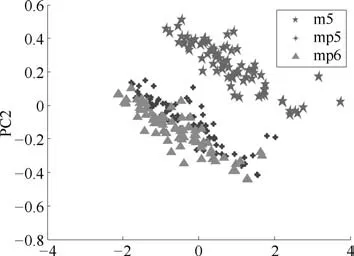
图3 不同设备的数据分布差异图Fig.3 Data distribution diagram for different devices
将设备m5的数据随机分成75%的训练集和25% 的测试集,分别采用随机权神经网络(RWNN)、集成学习方法 (Bagging)、即时学习(Just in time learning,JITL)对油脂含量进行满足数据同分布情况下的预测,结果如表1所示.
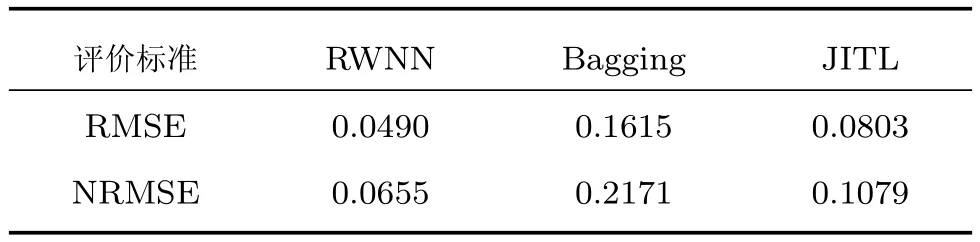
表1 m5油脂含量预测结果Table 1 Prediction result of oil content in m5
迁移学习实验中假设光谱仪m5所产生的数据为源域数据,令光谱仪mp5、mp6产生的数据为目标域数据,分别对数据集中的油脂含量和淀粉含量进行预测.本文引入RWNN、Bagging、JITL以及DARWNN与本文所建立的流形正则化域适应随机权神经网络(DAMRRWNN)预测结果进行对比.DAMRRWNN实验中通过SSA(Sample selection algorithm)方法[11]选取25个目标域有标签数据,nh,CS,CT,Cg分别设置为500,1×10−4,1×103,0.3.结果如图4和表2所示.
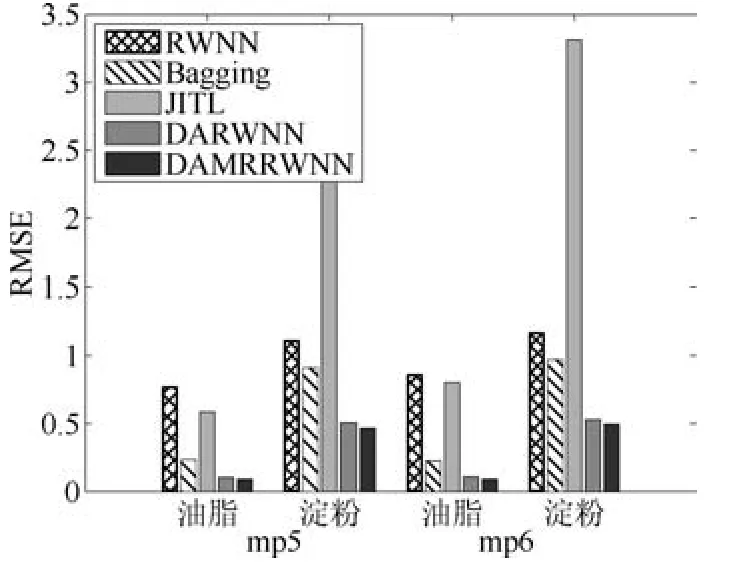
图4 光谱数据集实验结果对比Fig.4 Comparison of experimental results for spectral data sets
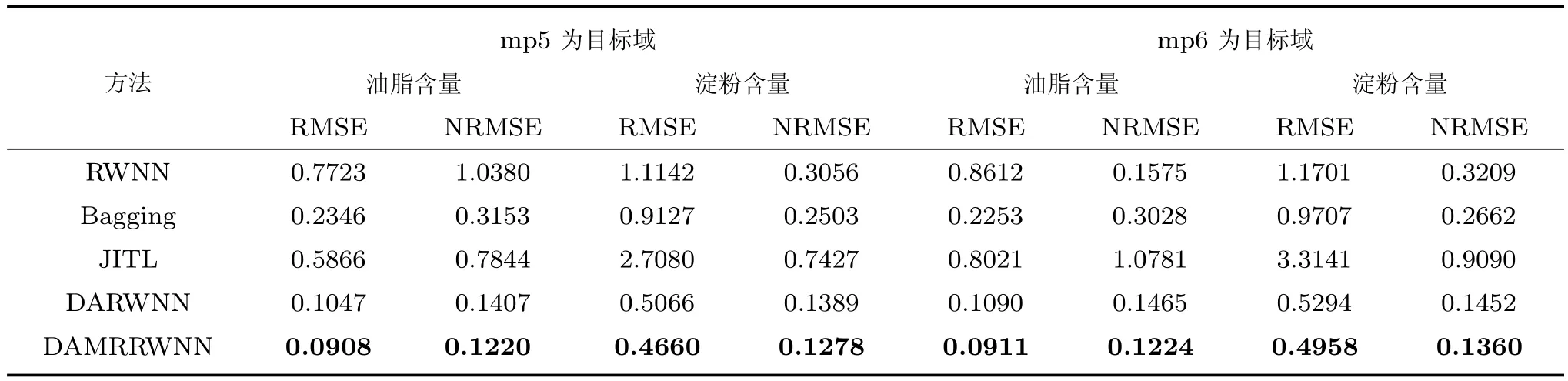
表2 m5为源域的不同算法实验结果对比Table 2 Comparison of experimental results of different algorithms for m5 as source domain
根据同分布情况下近红外光谱数据集上的实验结果(表1)可知,数据在满足独立同分布的前提下,传统的机器学习算法可以满足测量精度要求,获得较为理想的预测精度.结合表1和表2的实验结果可以看出,当数据独立同分布前提不满足时,建立在传统机器学习算法上的软测量方法存在较大的误差.
从表2和图4中可以看出DARWNN比传统随机权神经网络及其他算法的预测精度显著提高,说明迁移学习策略在数据分布不同时有效.同时可以看出引入流形正则框架后形成的DAMRRWNN在玉米样品近红外光谱数据集上拥有更理想的预测结果,可以有效提高数据分布不同情况下模型的预测精度,降低数据分布不同对软测量结果的影响.
3.3 湿式球磨机实验
3.3.1 数据预处理
实际工业过程中介质充填率(Medium filling rate,MFR)在0.3∼0.5之间变化,为了模拟实际工业过程中的工况变化,对实验室小型湿式球磨机进行负荷参数软测量实验研究,实验采取了分别固定介质充填率的5组实验方案数据,即每组实验都固定相应的磨机滚筒内钢球和水的质量,通过改变物料的质量以获得不同的负荷参数.对不同工况分别同步采集球磨机筒体振动信号,各工况实验次数如表3所示.
在此基础上将每次实验采集的振动信号平均分为28个样本(每个样本覆盖球磨机旋转1周以上的数据),对每个样本以w=1024的窗口进行不重叠滑动,每个窗口进行快速傅立叶变化(Fast Fourier transformation,FFT),最后将每个窗口的变化结果取均值,完成特征值提取过程[21].具体处理流程如图5所示.
3.3.2 实验结果与分析
为了验证基于流形正则化的域适应随机权神经网络(DAMRRWNN)的有效性,同样将随机权神经网络(RWNN)、集成学习(Bagging)、即时学习(JITL)以及域适应随机权神经网络(DARWNN)作为对比方法,分别对料球比MBVR、矿浆浓度PD、充填率CVR三种磨机负荷参数进行预测实验.在磨机负荷参数的软测量建模中,均以工况1作为源域,以其他4种工况分别作为目标域,测试结果分别用1-2、1-3、1-4、1-5表示.
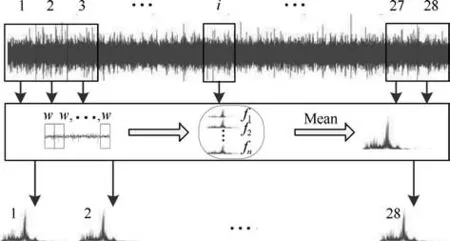
图5 数据预处理流程Fig.5 Data preprocessing process

表3 不同工况振动信号采集次数Table 3 Acquisition times of vibration signals under different working conditions
表4为不同预测模型软测量结果的均方根误差RMSE值,表中1-1表示训练集测试集数据均来源于工况1,可以看出RWNN、Bagging以及JITL在数据满足独立同分布时,均能获得理想的预测精度,相较于其他预测模型,DAMRRWNN在工况发生改变的情况下对三种磨机负荷参数的预测误差均能达到最低.图6表示目标域为工况2情况下分别采用RWNN及DAMRRWNN建模时各磨机负荷参数的预测结果.根据预测结果可知,引入迁移学习可有效解决工况变化带来的数据分布失配情况下的软测量建模问题.图7表示三种对比算法,集成学习、即时学习以及域适应随机权神经网络分别在目标域为工况2时对浓度的预测结果.
结合图6中浓度预测结果可知,DAMRRWNN算法在三种负荷参数软测量实验中均可获得最佳预测结果,DARWNN预测结果与DAMRRWNN的预测结果对比可以看出,引入流形约束后,预测结果更加稳定且误差降低,图8表示以工况1为源域进行域适应学习的三种磨机负荷参数的预测结果.
图9表示目标域为工况2条件下各建模方法对三种磨机负荷参数的预测误差对比,图10表示对磨机负荷参数进行预测时,各建模方法预测误差对比(图例与图9相同).实验证明,湿式球磨机工况发生变化时,历史数据建立的软测量模型性能急速下降.为解决工况改变引起的软测量模型失准,引入域适应随机权神经网络对源域数据构建的模型进行知识结构迁移,从而提高模型适应能力.由图9、图10对比结果可以看出,进一步引入流形正则化后,DAMRRWNN模型的泛化性能及预测精度较DARWNN模型均有所提高,从而可以验证该方法的有效性.
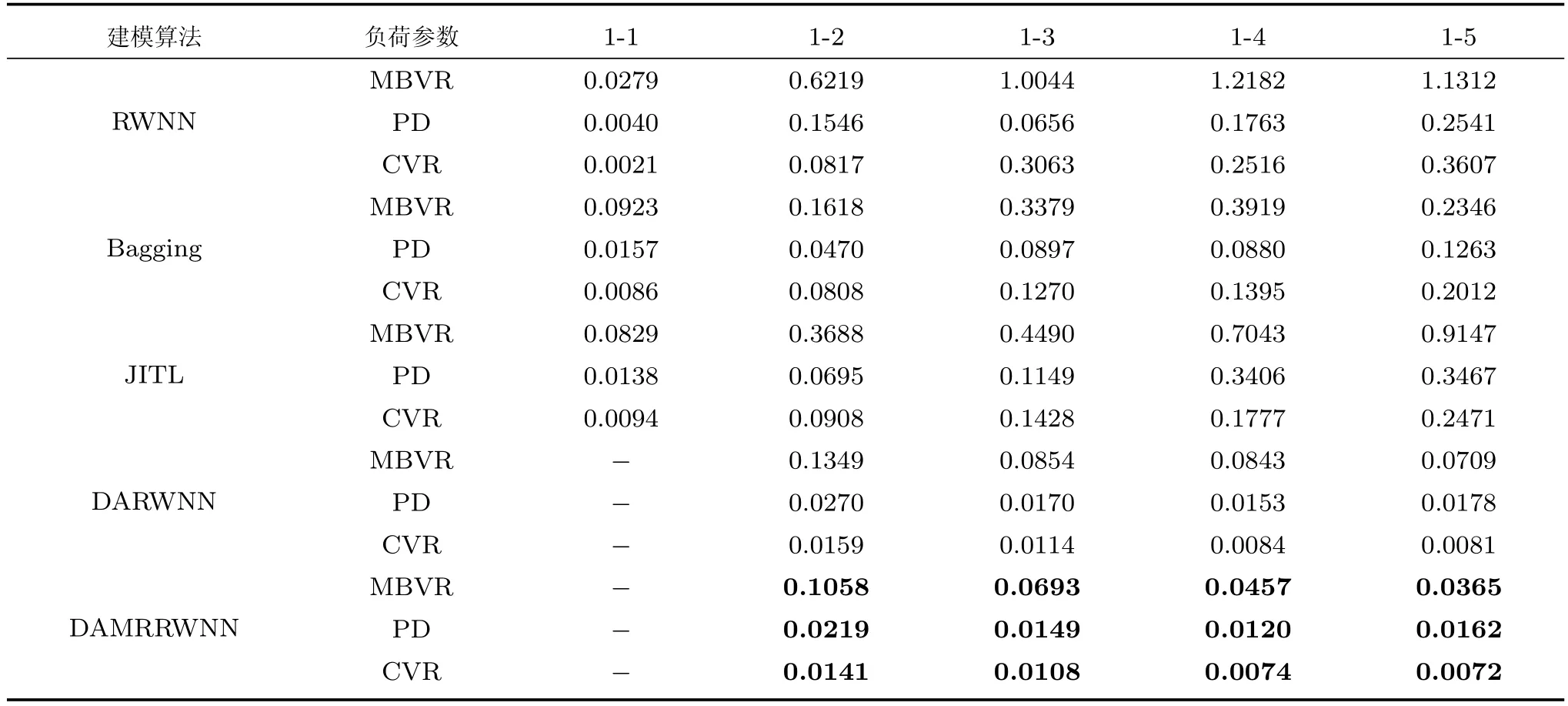
表4 磨机负荷参数预测结果对比(RMSE)Table 4 Comparison of prediction results of mill load parameters(RMSE)
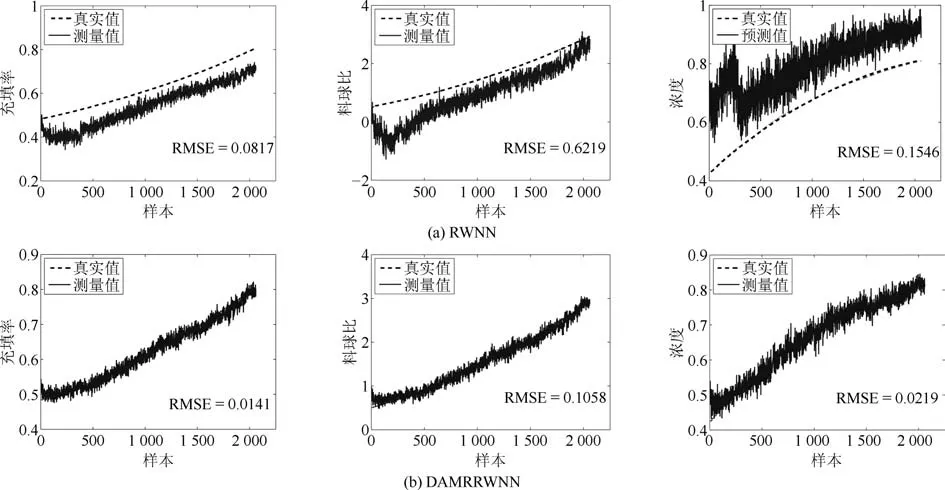
图6 目标域为工况2时RWNN和DAMRRWNN的负荷参数预测结果Fig.6 Prediction results of RWNN and DAMRRWNN on load parameter,when the condition 2 is the target domain
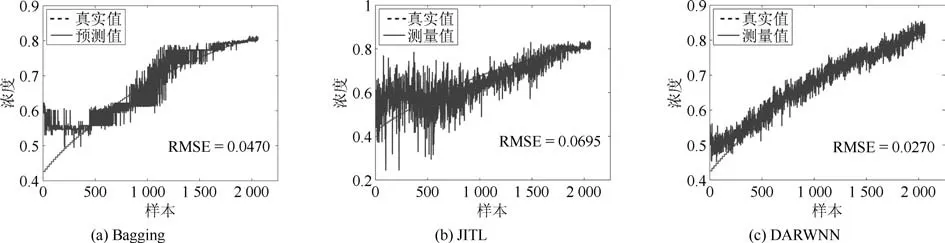
图7 目标域为工况2时三种对比算法对负荷参数浓度的预测结果Fig.7 Prediction results of three algorithms on load parameter PD,when the condition 2 is the target domain
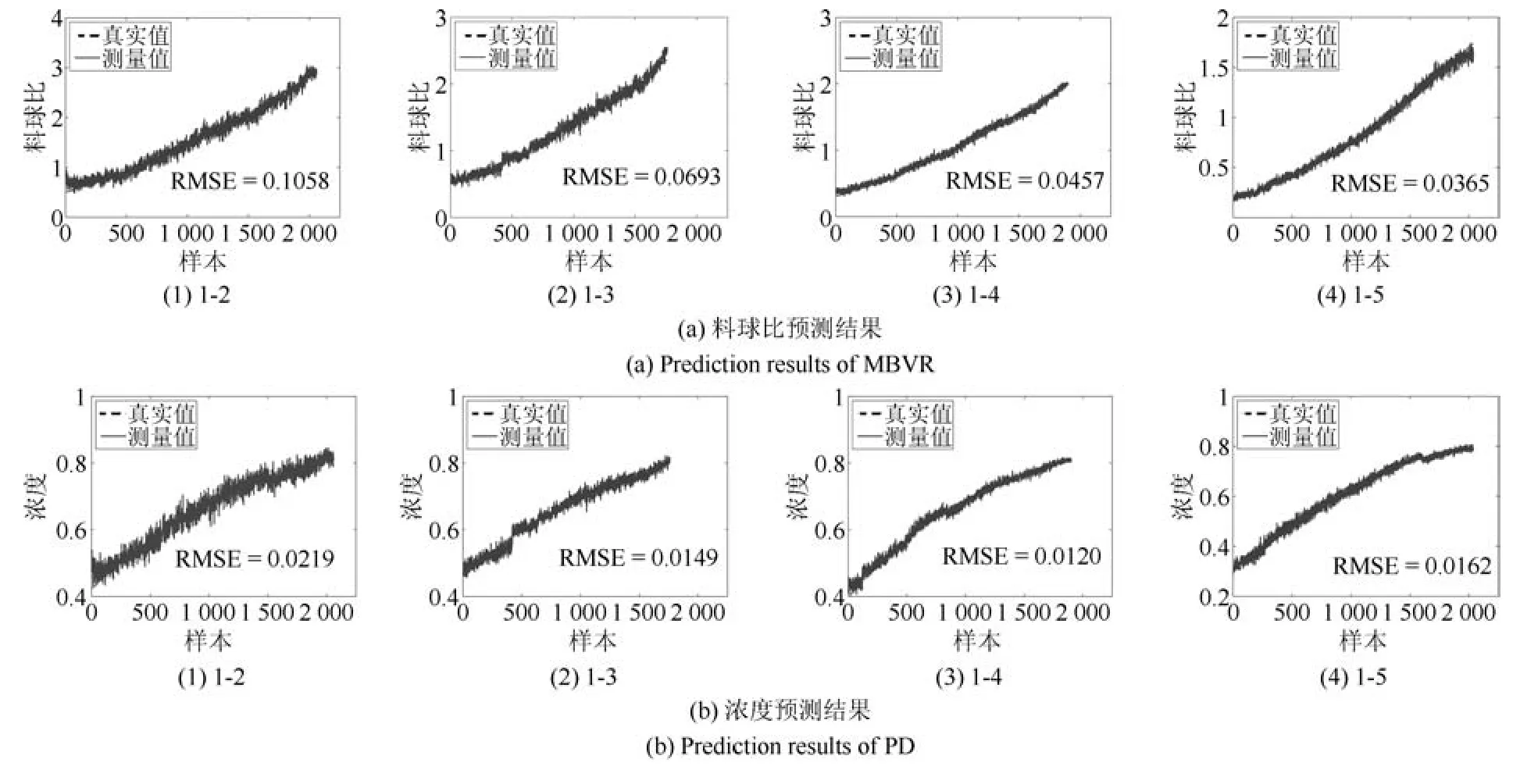
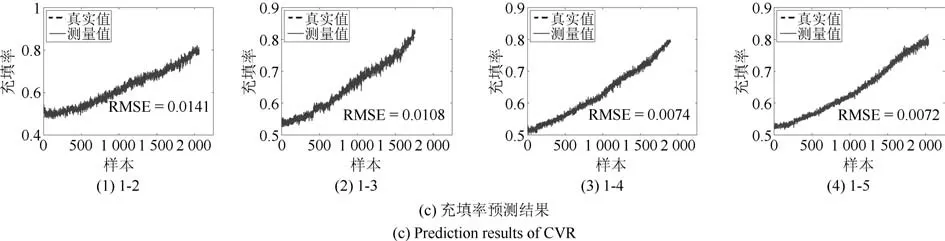
图8 DAMRRWNN负荷参数预测结果Fig.8 DAMRRWNN load parameter prediction results

图9 目标域为工况2时建模方法对比Fig.9 The target domain is the working condition 2 and the prediction results are compared
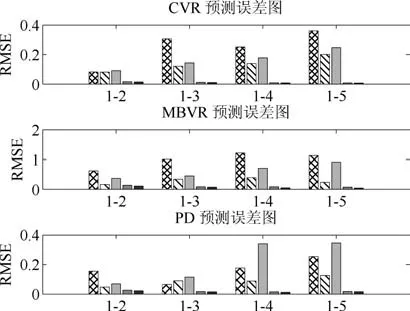
图10 三种负荷参数预测误差对比Fig.10 Comparison of prediction errors of three load parameters
4 结论
为解决湿式球磨机工作过程中,由于工况突然变化造成的实时数据与历史数据不再满足传统建模方法要求的概率同分布问题,本文引入迁移学习策略,建立了一种基于流形正则化域适应随机权神经网络(DAMRRWNN)的湿式球磨机负荷参数软测量模型.对预处理后的特征数据,首先通过域适应随机权神经网络进行迁移学习,然后添加流形正则约束项保持数据结构,实现变工况情况下湿式球磨机负荷参数回归预测.实验结果表明,磨机工况发生改变时,引入迁移学习策略,能够充分利用原有数据,降低数据收集成本,有效提高模型的泛化能力,并且该方法引入的流形正则化约束能够一定程度上降低结构风险,提高预测结果的准确性和可信性.
