面向中文电子病历的句法分析融合模型
2019-04-12蒋志鹏关毅
蒋志鹏 关毅
电子病历是医务人员在医疗活动过程中使用医疗机构信息系统生成的文字、符号、图表、图形、数据、影像等数字化信息,并能实现存储、管理、传输和重现的医疗记录[1−2].电子病历是一种极其宝贵的知识资源,通过对电子病历进行自动分析,可以为用户健康知识获取提供有力支持.近几年,电子病历的知识获取成为研究的热点问题[3−5],其获取过程一般分为语言分析和信息抽取两个阶段进行,词法分析和句法分析是主要的语言分析手段,能够为信息抽取提供必要的条件.例如,电子病历的句子可能包含多种药物信息及不同的用药说明.传统的规则表示仅在药名抽取上具有较高精度,而用药频率、计量等重要信息的抽取需要结合上下文环境,是规则表示无法处理的.句法分析技术通过对句子进行结构化处理,能够解析复杂的上下文环境,为信息抽取提供丰富的上下文信息,已经成为构建高精度信息抽取系统的重要组成部分.
中文电子病历(Chinese electronic medical records,CEMR)文本不同于一般的限定领域文本.语料构建方面,CEMR的标注工作要求兼顾医学和语言学的相关知识,增加了标注者的学习成本,整个标注过程更加费时费力.文本差异方面,除了词汇层面的差异外,CEMR文本特有的书写方式加剧了与开放领域的文本差异.具体表现为,从文本构造上看,CEMR是结构化数据和自由文本的结合,自然语言处理的对象通常指的是自由文本.根据CEMR词性标注准确率与未登录词率的相关性分析[6],CEMR的自由文本可以分为叙述部分和罗列部分,叙述部分多以长句的形式描述症状、检查等信息,例如诊疗计划、诊断依据、病例特点、主诉等,罗列部分多为医学术语及其修饰语的简单罗列,例如临床初步诊断、临床确定诊断、门诊收治诊断、治疗效果等.其中,罗列部分充斥着开放领域语料鲜有的医学术语,例如“脑梗死”在宾州中文树库(Penn Chinese treebank,PCTB)中从未出现过,使得该部分的句法分析难以利用PCTB中学习的知识.CEMR文本重复度高的特点导致叙述部分呈现强模式化现象,例如“伸舌”、“示齿”这类缩略词构成的动宾短语在病例特点中频繁出现,该类短文本多以标点符号分隔描述病情,在PCTB中同样较少使用.CEMR自由文本的这两部分特点使得直接应用PCTB训练的句法分析模型性能下降更为严重,Berkeley parser[7]与Stanford parser[8]相比,中文开放领域的最好结果下降了30%左右.
本文将CEMR自由文本中重复出现的模式形式化为树片段,树片段主要用于句法树重排序和面向数据句法分析(Data-oriented parsing,DOP).句法树重排序一般分为两步:1)由基本的句法分析器为每个句子产生一组候选句法树,候选句法树的初始概率为最初排序的依据;2)根据句法树的额外的结构特征训练重排序模型,对这组候选句法树重新排序,通常使用树片段作为重排序的额外特征.尽管重排序模型对句法分析精度有较大提升,但是时空复杂度较高的缺点限制了其实际应用.DOP技术首先由Scha在1990年提出,之后由Bod逐步发展,具体表达了如下假设:人类对语言的领悟和创造依赖于以往具体的语言经验,而不是依赖于抽象的语法规则[9].模型首先预设了一个具有带标短语结构树标注的语料库,然后从这个语料库中抽取所有任意大小规模和复杂结构的片段.其次,通过对语料库中片段的组合操作来实现新输入的分析,然后考虑输入的所有派生结果的概率总和的大小来选择最有可能性的分析结果[10].
在前期工作中,我们对CEMR语料进行了词法统计分析[6],其中逐点互信息的结果说明CEMR相比中文开放语料和英文EMR模式化程度更强,这是由于CEMR的编写具有更强的目的性,力求表述清晰、简洁,导致重复使用相似的句法结构,形成模式化的表述.同时,CEMR中包含不同的部分,每个部分意图不同,重复使用的短语结构也不尽相同,这种模式化表述一般与陈述性语句混合使用.以首次病程记录为例,包括主诉、既往史、主观症状、客观检查、评估和诊断、诊疗计划六个部分,其中频繁出现的重复结构如表1所示,而传统的PCFG文法将句法树层数限制为2,难以直接表示这些模式,例如“伴心率失常室早”、“伴心率失常房颤”、“伴心动过速”会形成两类重复模式,即“伴心率失常+疾病名”和“伴+疾病组”,这两类模式均不属于PCFG文法.DOP希望抽取所有可能的树片段(不限制层数),能够更加直观、形象地表现CEMR中的模式.我们以树片段替换的方式对初始的句法分析结果进行纠错,类似于引入了句法树重排序中的结构特征,但相比句法树重排序按模板抽取结构特征,DOP的优势在于不限制树片段的形式,能够保证其多样性,并且在增加新语料时不需要重新训练模型.尽管DOP的文法归纳过程不需要训练模型,但是树片段的数量随树库规模呈指数级增长,抽取树库中所有可能的树片段难以实现.
层次句法分析是一种快速的完全句法分析方法,在前期工作中,我们改进了层次句法分析模型[11],并标注了小规模CEMR句法树库[12−13],本文希望充分利用CEMR模式化强的特点,进一步提升层次句法分析模型的精度.本文的工作属于后处理融合,基于改进的树片段的抽取算法,将DOP中树片段的选择和替换操作融入层次句法分析过程中,最终在CEMR上句法分析的F1值超过了目前最优的Berkeley parser和Stanford parser.模型整体架构如图1所示.

表1 重复模式样例Table 1 Pattern samples repeated
图2为面向数据句法分析与层次句法分析的融合示例,输入为经过词性标注的CEMR句子“对光反射存在,双眼运动自如,无面舌瘫”.该句子依次经过词汇词性混合匹配、初选、筛选和组合过程,获得了一个最优的树片段集合,最终通过树片段替换的方式改进了层次句法分析结果.图中虚线框部分为该实例中两个有效的替换.
1 相关工作
树核方法一般用于量化两棵句法树的相似程度,并不能明确给出这两棵句法树的共有结构,Sangati等[14]在2010年首次将树核应用到树片段抽取中,Sangati将树片段分为标准片段和局部片段,抽取时对树库中所有树结点进行两两比较,并提出基于树核的局部片段抽取算法,该算法不只计算公共结点数量,还保留了重复出现的最大公共树片段.尽管Sangati能够从树库中抽取有效的树片段,但是使用二次树核(Quadratic tree kernel,QTK)在树片段抽取时效率不高.与Sangati相类似,Moschitti[15]同样对树片段进行了划分,并提出了基于快速树核(Fast tree kernel,FTK)的树结点匹配算法,该算法的效率要高于Sangati,但是仅保留了树库的公共结点集而不是树片段.van Cranenburgh[16]将Moschitti的快速树核算法改进为矩阵形式抽取树片段,算法时间复杂度降为线性平均时间,但整个抽取过程只适用于二叉树,并且只抽取树库中的局部片段.本文的树片段抽取以Sangati的工作为基础,借鉴动态规划思想改进了标准树片段抽取算法,并使用Moschitti的快速树核算法替换Sangati的二次树核算法,提高了整个算法的执行效率.
中文方面DOP相关研究较少,早期张 杰等[10]提出基于DOP框架的中文句法分析方法.整个分析过程中,句子需要依次经过词汇层与词性层的初选,再从树片段库中获得与句子相匹配的片段组合形式,利用Kullback-Leibler距离函数评估句子与初选结果的相似度,分析结果为相似度大于阈值或相似度最高的片段组合.本文的树片段处理过程相当于在张 杰工作的基础上,提出了一套适用于CEMR的树片段选择和替换方法.由于我们的目的是通过树片段替换融合层次句法分析模型,所以没有保留张 杰的组合分析过程.
层次句法分析是一种高效的完全句法分析方法,但是逐层组块分析导致错误累积问题严重,在前期工作中,我们提出了一种简单可行的错误预判及协同纠错算法[11],每层组块分析时跟踪预判错误标注结果进入下一层,利用两层预测分数相结合的方式协同纠错.实验结果表明,加入纠错方法后,层次句法分析在保证解析速度的同时,获得了与主流中文句法分析器相当的解析精度.近几年,由于单一模型的解析结果仍然存在局限性,模型融合成为提高现有句法分析水平的主要途径.模型融合一般指将不同句法分析器的结果融合成一个最终结果,常见的融合方式包括将不同结果杂合成为一个结果[17−18],或按照某些标准从多个结果中选择一个最优的结果[19].
2 标点符号分割与纠错算法
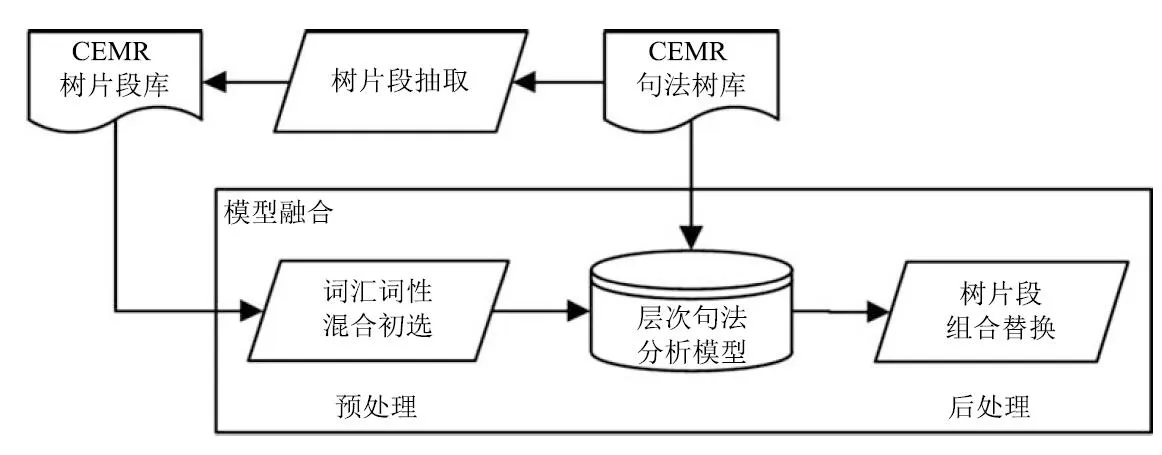
图1 融合模型框架Fig.1 The framework of integrated model
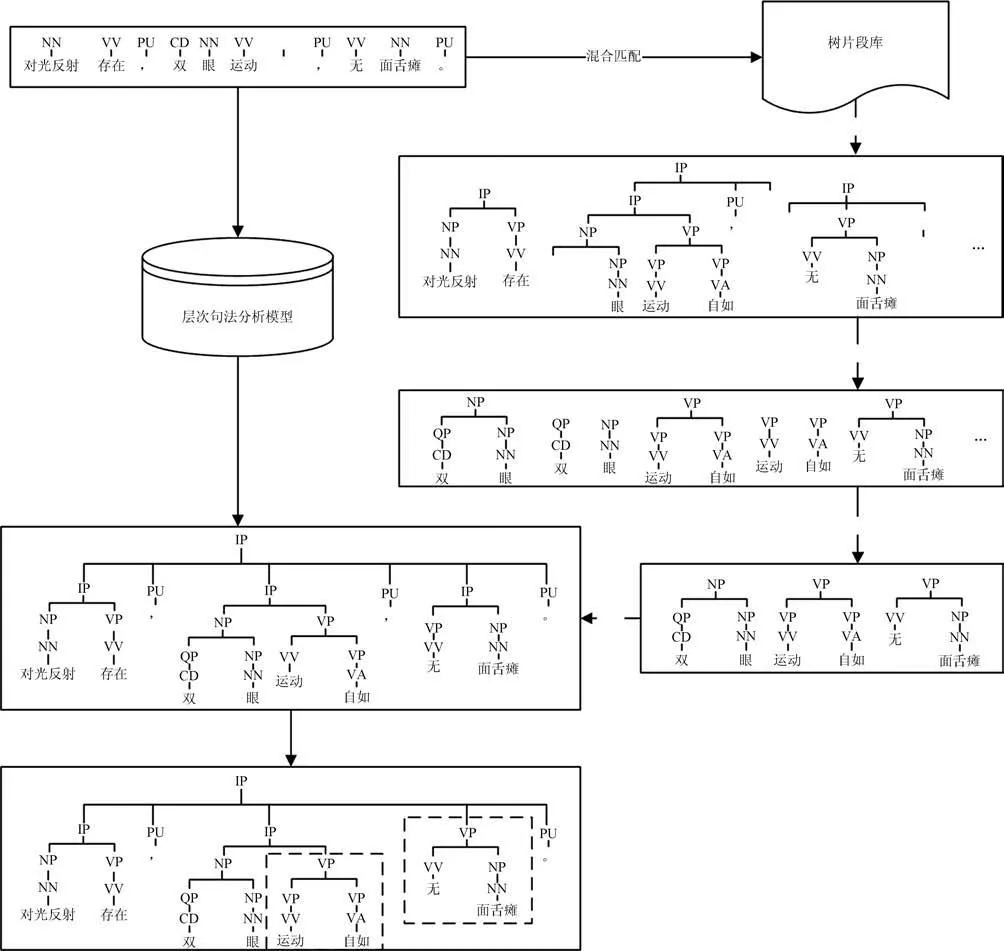
图2 面向数据句法分析与层次句法分析融合示例Fig.2 The sample integrating DOP and hierarchical parsing
通过对CEMR标注语料进行统计分析[6],我们发现标点符号在CEMR中所占比例高达21.69%,仅次于名词位居第二位,并且高于开放领域文本6.4%之多.由于层次句法分析框架是自底向上逐层序列化标注,CEMR标点符号的频繁使用使得下列问题更为突出:1)句法树中高层标点符号成分较难确定;2)并列结构中标点符号成分难确定;3)逐层标注的错误累积导致标点对的内容无法成为单棵句法树.CEMR中最常见的标点对为双引号和圆括号,其内容经常被CRF模型分割成多棵句法树,后续部分提及的标点对也默认为双引号和圆括号.
CEMR中标点符号的使用同样有较强规律性,例如,经常出现在高层句法树中的标点符号多用于连接并列句法结构.为缓解上述问题,一方面,本文围绕标点符号设计了辨识度更高的特征,形成上下文词典,以词典纠错的方式改进标点符号的标注效果.另一方面,使用标点对分割句子,优先解析标点对的内部成分,采用分割组合的方式进行句法分析.
结合层次句法分析模型[13]在调试语料上的错误分析结果,我们设计了上下文词典对标点符号进行纠错,关键词为标点符号,词典项如表2所示.其中,第1行为通用项⟨father,lfather,rfather⟩,father表示父结点,lfather表示父结点的左兄弟结点,rfather为父结点的右兄弟结点.第2行aword为相邻词,相邻词的选取与Collins的头词类似,目的是对子树边界位置的标点符号进行消歧,如果父结点是NP,则aword为左相邻词,否则aword为右相邻词,当 aword为空时⟨lgfather,rgfather,lbword,rbword⟩生效,lgfather和rgfather分别为祖先结点的左兄弟和右兄弟结点,lbword为lfather的最右子结点,rbword为rfather的最左子结点.第3行和第4行的词典项与句法树高度相关,即句子边界有助于高层标点符号纠错,固定搭配有助于低层标点符号纠错.当标点符号所在层数大于3时,⟨lbbegin,rbend⟩判断当前位置是否为句首或句尾,若不是则直接比对aword项.

表2 上下文词典项概括Table 2 Summary of elements of context dictionary
标点符号的上下文词典纠错算法能够与多层协同纠错算法[11]很好地配合使用.当歧义项为标点符号时,优先检索上下文词典,选择匹配成功的候选结果作为最优解,否则进入多层协同纠错算法消歧.在检索上下文词典时,为了减少词典中人工错误带来的干扰,我们规定只有当前条件对应的元组完全匹配时,才算匹配成功.
由于闭合的标点对必然会成为一个句法树,所以省去了训练模型识别独立语块的过程,在进行句法分析时,如果存在标点对,则优先解析标点对的内容,再将标点对的句法树与其余部分重组成新的输入,进行新一轮解析.引入标点符号分割和纠错算法的层次句法分析流程如图3所示,其中“CRF序列化标注”和“多层协同纠错”是前期构建的基础模型CLP[11].
3 树片段抽取
由于树片段不限制层数和结构,导致其数量随语料规模呈指数级增长,抽取时间远长于统计机器学习模型的训练时间,当需要从更大规模语料中抽取树片段时,抽取时间将成为其实际应用的瓶颈问题,所以在树片段抽取上的改进工作主要围绕抽取效率展开.
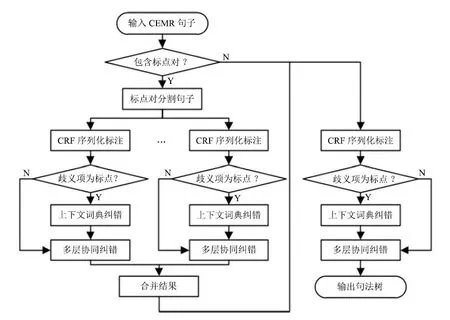
图3 引入标点符号分割和纠错的句法分析流程Fig.3 The parsing process with segmentation and error correction for punctuation
3.1 树片段相关定义
参照Sangati等[14]对树片段的划分方式,首先给出标准树片段和局部树片段的相关定义,然后为两类树片段分别设计算法抽取公共树片段,形成两个树片段库.
定义 1(标准树片段).标准树片段stf是句法树T的连通子图,并且stf中任意结点的子结点或为空,或与T中对应结点的子结点相同.
定义 2(局部树片段).局部树片段ptf是句法树T的任意连通子图.
定义 3(公共树片段).公共树片段ctf是在句法树库中至少出现两次的标准树片段或局部树片段.
定义4(公共叶结点).公共叶结点ct属于公共树片段ctf,并且ct的子结点或为空,或不属于ctf.
定义5(公共非叶结点).公共非叶结点cnt的子结点不为空,并且cnt及其子结点全部属于公共树片段ctf.
从上述定义可以看出,标准树片段相当于局部树片段的特殊形式,所以其抽取和匹配的耗时更少,为了对比两类树片段对模型融合的贡献,本文分别抽取了两个树片段库.公共树片段可以较好地表现CEMR中重复出现的模式,下文提及的标准树片段和局部树片段都默认为公共树片段.
以CEMR中的句法树为例,图4(a)为CEMR句法树,图4(b)和图4(c)分别表示从该句法树中抽取的部分标准树片段和局部树片段.共现模式是CEMR中的高频模式,图4中实线框内的标准树片段能够体现“心率失常”和“室早”这两个病症的共现模式,而通过将“室早”泛化为名词词性,形成虚线框内的局部树片段,则能够表现“心率失常”与其他病症的共现模式,例如常见的“心动过速”、“房颤”等.由此可见,CEMR中的共现模式与树片段能够很好地吻合,所以本文将其形式化为树片段,用于改善句法分析模型在CEMR上的解析效果.
3.2 标准树片段抽取
Sangati等[14]抽取标准树片段的过程由两部分组成,第1部分遍历句法树库中每一对树结点,算法时间复杂度为O(n2m2),其中n为句法树的数量,m为单棵句法树的最大结点数,第2部分抽取父子结点均相同的片段,最坏情况下,算法时间复杂度为O(m2),最终算法时间复杂度为O(n2m4).为避免重复比对问题,我们利用动态规划思想改进了Sangati的抽取算法,如算法1所示.
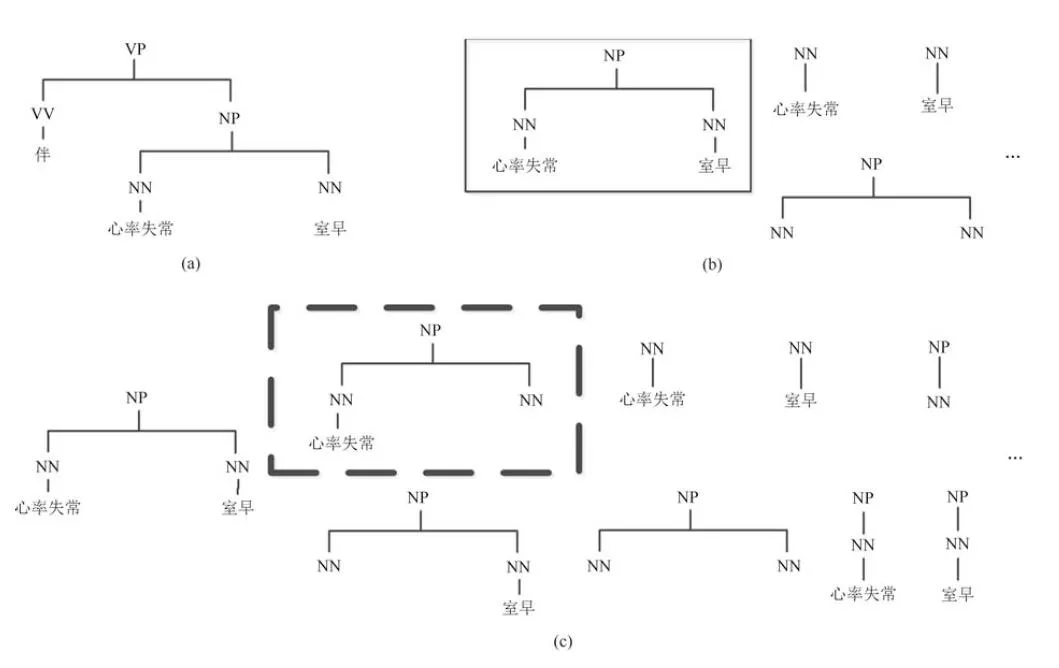
图4 句法树及其片段样例Fig.4 Examples of a parsing tree and its fragments
算法1.标准树片段抽取算法

不同于Sangati的抽取算法,本文的标准树片段抽取算法围绕公共非叶结点展开,其中,SIZE函数用于计算树库中句法树的数量,CHILD-SIZE函数返回子结点数目,算法第1∼5行是树库结点对的遍历过程,第6行的变量visited用于保存已访问的公共非叶结点对.在调用EX-TREE-STF函数抽取标准树片段之前需要查找visited,visited中存在的公共非叶结点对不再遍历.算法第11∼26行用于识别公共非叶结点,具体地,在遍历结点对时,当两个结点相同并且子结点数也相同时,递归调用EX-TREE-STF算法遍历所有子结点,如果所有子结点相同,则该结点对为公共非叶结点对;否则,当两个结点相同,但其子结点不同或为空时,该结点对则为公共叶结点对.由于不需要重复遍历公共非叶结点,使得EX-TREE-STF算法时间复杂度降至O(d),d为单个结点的最大子结点数,整个算法的时间复杂度降为O(n2m2d).
3.3 局部树片段抽取
与标准树片段抽取算法类似,Sangati等[14]在抽取局部树片段时同样需要先遍历句法树库中每一对树结点,再抽取局部树片段.不同之处在于,两个树结点可能共享多个公共子结点序列,形成多种公共局部树片段的组合.为抽取所有可能的公共局部树片段,Sangati等提出了基于二次树核的结点映射算法,该算法类似于最长公共子序列查找,需要遍历每个子结点对,其时间复杂度为O(d4),d为单个结点的最大子结点数,整个算法的时间复杂度为O(n2m2d4).
事实上,在抽取公共树片段时,如果两个父结点的产生式不同,其子结点没有必要再进行比较.Moschitti[15]提出了基于快速树核的结点映射算法,只考虑父结点产生式相同的结点匹配情况.受该思想启发,本文利用Moschitti的快速树核替换二次树核算法,获取树结点映射集,算法2是改进后的局部树片段抽取算法.
算法2.局部树片段抽取算法

算法2中,SORT函数将结点的产生式按字母顺序排序,POP函数返回有序表中首个结点并将其弹出,PROD函数返回结点所在的整个产生式,NEXT函数返回有序表中当前结点的下一个结点.第1∼3行为树库的遍历过程,该过程与算法1相同.第4∼17行为基于快速树核的结点映射算法,该算法首先对树的结点按字母顺序排序,然后逐个比较产生式相同的结点,对所有公共结点进行标记,与标准树片段抽取不同,这里不需要区分公共叶结点和非叶结点.第18行递归调用EX-TREE-PTF算法获取ni和nj的公共局部树片段集合,该算法与Sangati等[14]提出的算法3相同,功能是对结点映射组maps进行合并,最终加入到整个局部树片段集合中.
由于产生式排序过程在进行结点映射之前仅执行一次,时间复杂度为O(mlogm),结点映射过程最坏情况下执行m2次,而EX-TREE-PTF算法对整棵树也只需遍历一次,所以改进后的局部树片段抽取算法时间复杂度为O(n2m4).
4 DOP与层次句法分析的融合模型
前文将CEMR重复出现的模式形式化为树片段,并分别抽取标准树片段和局部树片段,形成了两个树片段库.与树片段关联最紧密的句法分析框架就是DOP框架,然而单独使用DOP模型进行句法分析的效果并不理想.模型融合是提高模型解析精度的有效方法,将DOP与层次句法分析模型进行融合,既合理利用了CEMR模式化强的特点,又避免了单独使用DOP模型精度不高的问题.
目前常用的模型融合方式包括特征融合和后处理融合,特征融合通过融合多个模型的特征,对其进行共同训练,联合解码.后处理融合则更倾向于多个模型结果的重组或选择.由于特征融合并不适用于DOP模型,所以我们选择后处理融合进行扩展,提出了面向CEMR的DOP与层次句法分析融合模型.
4.1 预处理
预处理阶段的工作分为两部分:1)树片段的匹配;2)基于匹配结果的树片段初选.张 杰等[10]在匹配树片段时先匹配词汇再匹配词性,只有词汇完全匹配的树片段才能直接成为最终结果.与张 杰等的做法不同,我们没有将词汇和词性单独处理,而是采用词汇和词性混合的方式匹配树片段,不局限于词汇完全匹配的约束条件,充分发挥词性在树片段匹配过程中的泛化作用.树片段初选主要选择两类树片段,一类是能够与输入句子完全匹配的树片段,另一类树片段与输入句子部分匹配,且存在不包含边界结点的独立子树,这里边界结点特指处于树片段最左端或最右端的结点.其中,第一类树片段能够直接成为输出结果,第二类树片段是后续树片段组合替换的基础.
初选的第二类树片段可能是不规范或不合法的树片段,图5虚线框内为不规范的树片段,该类树片段可能包含多棵子树,将在第4.2节中进一步筛选.另外,仅依靠词汇词性匹配会抽取到不合法树片段,如图5实线框所示,由于只匹配到““(双引号)脑卒中、(顿号)”,所以形成了错误的NP,为了避免抽取这类树片段,增加了“存在不包含边界结点的独立子树”的约束,在该约束条件下,用于替换的树片段必须从初选树片段内部获得(不含边界结点),该约束条件虽然减少了初选树片段的数量,但也解决了后续步骤中不合法树片段带来的错误替换问题.
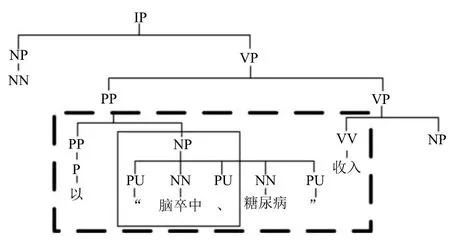
图5 初选树片段样例Fig.5 The sample of selected tree fragment
受连续公共子序列查找算法启发,本文提出了词汇词性混合初选算法,如算法3所示.
算法3.词汇词性混合初选算法

算法3中,ls1为树片段的叶结点及其父结点集合,ls2为输入句子的词汇和词性集合.UPDATE函数用于词汇和词性的混合匹配,同时将局部树片段扩展为标准树片段,具体分为4种情况:1)词汇与叶结点匹配,直接返回TRUE;2)词性与叶结点匹配,将词汇追加为该叶结点的子结点,返回TRUE;3)词性与父结点匹配,将词性替换为父结点,返回TRUE;4)词汇、词性均不匹配,返回FALSE.算法第11行和第17行是第二类树片段的约束条件,由于在后续工作中,用于替换的句法树必须在树片段内部且独立,所以我们抽取的第二类树片段至少包含三个结点,或处于句子边界位置且包含两个结点.该算法最后返回所有匹配的边界对,除了树片段与句子完全匹配的情况,当局部树片段边界包含句子边界,并且局部树片段为独立句法树时,该局部树片段也能够直接输出,否则该句子进入层次句法分析模型解析阶段.算法单次执行的时间复杂度为O(m×w),由于需要遍历整个树片段库,所以最终时间复杂度为O(n×m×w),其中,n为树片段个数,m和w分别为树片段叶结点数以及输入句子的词数.
4.2 后处理融合
后处理阶段是基于预处理初选的树片段集和层次句法分析结果,进行树片段的筛选、组合与替换,进一步改进句法分析结果.为了不影响层次句法分析结果中其他树片段,用于替换的树片段必须从初选树片段内部获得,并且是高度大于1的标准树片段,即不考虑仅包含词汇和词性的树片段.初选树片段可能包含多棵子树,也可能与其他树片段发生交叉,所以需要先对初选树片段进行筛选.筛选后的树片段集合是不含边界结点的全部标准树片段,以图6为例,图6(a)和图6(b)分别为初选树片段与筛选后的树片段集合.
张 杰等采用先拼接再计算相似度的方式组合树片段[10],在实验中我们也尝试了他们的最左优先原则拼接树片段,但该方式会生成更多无效句法树,带来更多噪声.我们的最终目的是以树片段替换方式改进已有句法树,所以组合树片段时可以绕开拼接过程,转变为最大化叶结点替换数目.基于动态规划思想,本文提出最大树片段组合算法,如算法4所示.
算法4.最大树片段组合算法

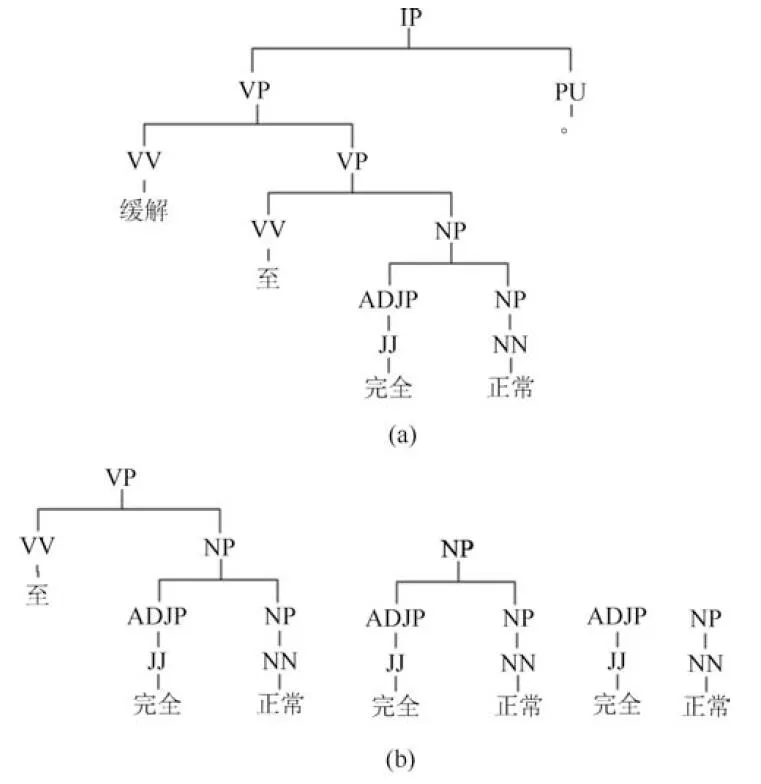
图6 初选树片段与筛选树片段集合Fig.6 The selected tree fragment and its filtered tree fragments
算法4不需要考虑拼接时边界结点的匹配情况,而是直接获得叶结点数最大时的树片段集合.算法三个参数分别为:当前树片段的右边界(end),按右边界从小到大排序的树片段边界集合(borders),所有右边界对应的最大树片段集合(spans).now和max用于保存当前树片段集合及当前右边界对应的最大树片段集合,SPAN函数为now或max包含的叶结点数.当两个树片段集合叶结点数相同时,遵循高度优先原则,选择层数更高的树片段集合,因为叶结点相同时层数高的树片段往往会包含层数低的树片段.最大树片段组合算法的时间复杂度为O(p2),p为筛选后的树片段个数.
基于最大树片段组合算法获得树片段集合,下一步进行树片段替换工作.树片段替换依然遵循高度优先原则,首先利用广度优先搜索遍历层次句法分析模型输出的句法树中所有非终结符,当非终结符的叶结点与树片段的叶结点完全匹配时,用树片段替换以该非终结符为根结点的子树,直到集合内所有树片段替换完成后,输出新的句法分析结果.树片段替换算法的时间复杂度为O(p×s×m),其中p为筛选后的树片段个数,s为层次句法分析模型输出的句法树中非终结符个数,m为单个树片段的最大叶结点数.另外,在实验中发现,先对最大树片段集合按叶结点数进行排序,再选择前5个树片段替换,比直接使用集合中的全部树片段替换效果更好.
5 实验结果与分析
在前期的工作中,我们以PCTB标注规范为基础,通过迭代的方式不断调整规范,结合CEMR中特有的标注样例对PCTB规范进行细化、扩充、删减,首次提出了适用于中文电子病历的分词、词性和句法标注规范,并获得了较高的标注一致性和准确率,其词性和句法标注体系与PCTB完全相同.本文实验所用语料为前期标注的CEMR句法树库[12−13].该树库为神经内科和普通外科的出院小结和首次病程记录,共138份CEMR,包含2555棵句法树,语料统计信息如表3所示.语料采用的5折交叉验证的方式构造,每次随机平分为5份,4份作为训练集,1份作为测试集,同时从训练集随机抽取1/5作为调试集.
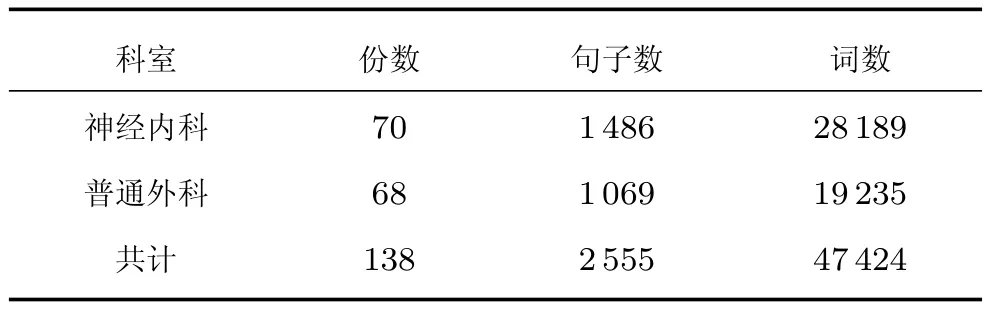
表3 CEMR句法树库统计信息Table 3 Corpus statistics of CEMR treebank
5.1 树片段抽取实验
为了对比句法分析模型,每次交叉验证从上述训练语料中抽取出现2次以上的标准树片段和局部树片段,形成了两个树片段库,并改进两类树片段的抽取算法,从而提高抽取效率.树片段抽取结果如表4所示,实验环境为64位Ubuntu系统,1.2GHz的CPU.从抽取速度可以看出,利用FTK算法改进后,抽取效率明显提高,抽取速度相当于QTK的4倍左右.表4中给出树片段种类数而非树片段数,是因为树片段种类的多少与文本模式化强弱相关,直接影响DOP的性能,通常来说,文本模式化越强树片段的种类应该越少.从表中可以看出,局部树片段的种类约为句子数的19倍,明显多于标准树片段,所以相比标准树片段抽取速度也更慢.
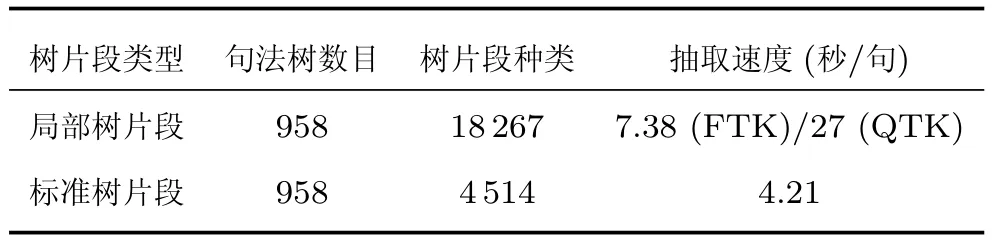
表4 树片段抽取结果Table 4 Results of fragment extraction
5.2 DOP与层次句法分析模型融合实验
本文的对比模型包括引入标点符号纠错和分割算法的层次句法分析模型(CLPU)、引入DOP的融合模型,以及开放领域最优的Stanford parser和Berkeley parser.首先在单一科室CEMR上进行训练测试,即神经内科CEMR按5折划分,随机抽取1/5作为测试集,其余作为训练集.实验结果如表5所示,在前期工作中,CLP和Berkeley parser在开放领域测试集(TCT)上句法分析精度相近[11],这里利用上下文词典进一步修正了CLP结果中的标点符号错误,并引入标点对分割组合策略,得到了CLPU模型,句法分析F1值达到78.23%.受语料规模影响,Berkeley parser产生了52个空输出,导致F1值降为78.17%,落后于CLPU结果.为解决Berkeley parser的空输出问题,本文对产生空输出的句子使用另一个PTCB训练的Berkeley parser解析,最后Berkeley parser(CEMR+PCTB)的F1值能够提高到79.8%,由于其他模型不涉及空输出问题,所以不需要额外训练模型解析.
在模型融合方面,本文首先对比了引入标准树片段(SDOP)和局部树片段(PDOP)的模型效果.可以看出,引入标准树片段和局部树片段后F1值均有较大的提升,最多提高了2.64%.虽然标准树片段产生错误替换的可能性更小,但也限制了树片段的多样性,导致最终与局部树片段的F1值相差1.32%.另一方面,通过错误分析发现,单个树片段匹配的叶结点越多,错误替换的概率越小,所以对筛选组合后的树片段集合先排序再替换,实验证明保留前5个树片段进行替换的F1值最高,达到80.87%,获得了目前CEMR上句法分析的最优结果.

表5 神经内科CEMR句法分析结果Table 5 Parsing results on CEMR of neurology department
为了对比各模型在不同领域中的性能,本文在PCTB上进行了句法分析实验.为公平起见,PCTB上采用与CEMR相同的实验设置,仅从PCTB中随机抽取1207句训练,277句测试,实验结果如表6所示.根据已公布的结果,当训练语料充足时(训练测试语料的比例达到50倍),Stanford parser和Berkeley parser在PCTB上句法分析F1值能够达到84% 左右,而在表6中,当PCTB的训练语料规模与CEMR同样小时,Berkeley parser的F1值最高只有64%左右,Stanford parser更下降到61.16%,相比之下,CEMR在仅需要少量标注语料的情况下,F1值却能够达到80%左右,在一定程度上也证明了其模式化强,句法清晰的特点.进一步对比各模型的实验结果,DOP在PCTB上无论是解析速度还是F1的增幅上都有较大下降.究其原因,解析速度变慢是由于从PCTB中抽取的树片段库相比CEMR规模要大,其局部树片段种类达到句子数的43倍之多,所以在树片段的遍历匹配时需要消耗大量时间.如此多的树片段种类说明PCTB并不像CEMR模式化那么强,导致DOP带来的增幅仅为0.42%.同时,标点符号在PCTB所占比例的下降,使得CLPU的F1值只有63.6%,最终引入DOP后仍落后Berkeley parser 0.36%.尽管本文提出的融合模型在PCTB上的表现并不理想,但是也从另一个角度验证了其更加适用于模式化强的子语言文本的假设.
在跨科室句法分析实验中,本文选择已标注的两个科室上进行交叉测试,实验设置与表5相同.分析结果如表所示.从表7可以看出,由于不同科室间的词汇存在较大差异,使得词性标注时未登录词率升高,各模型词性标注准确率均有不同程度的下降,最终句法分析F1值只能达到69%左右.其中受未登录词率影响最大的是Stanford parser,特别是在普通外科训练、神经内科测试时,Stanford parser词性标注准确率仅为75.23%,导致最后句法分析F1值只有57.85%.相比之下,本文提出的CLPU及融合模型表现出色,尽管在词性标注准确率上也有所下降,但是标点符号的高使用率、文本模式化强的特点是不同科室的共性,所以两个模型的跨科室性能相比Stanfrod parser和Berkeley parser有较大的优势,融合DOP后F1值能够超过最好结果2%以上.但是,在进行错误分析时,我们发现词汇差异使DOP错误替换的几率增加,导致引入DOP后词性标注准确率反而有较大下降,所以相比CLPU的提升只有1%左右.
最后,综合比较各模型在单一科室CEMR,PCTB以及跨科室CEMR的句法分析性能.Stanford parser的解析速度最快,但是也最不稳定,容易受未登录词影响,当未登录词率较高时,句法分析F1值有较大幅度的下降.Berkeley parser的性能中规中矩,但是对语料规模依赖较强,当标注语料充足时,句法分析性能更好,但是考虑到CEMR的文本特殊性,除了数据来源受限,还要求标注者同时具备语言学和医学相关知识,所以构建大规模CEMR语料库更加困难.本文提出的CLPU和DOP的融合模型在CEMR上的句法分析性能要优于Stanford parser和Berkeley parser,特别是跨科室句法分析时表现更为突出,证明引入树片段对于模式化强的子语言分析是行之有效的方法.进一步对比DOP中各算法的时间复杂度,由于初选过程需要遍历整个树片段库,而树片段库的量级远大于其他参数,占用了大量的解析时间,导致融合模型的句法分析速度相比Stanford parser和Berkeley parser差距较大.但是,由于目前还没有在树片段的存储和查找上做任何优化工作,所以未来在解析速度上仍有上升空间,例如遍历树片段库时引入剪枝策略,通过对树片段进行编码提高匹配效率等.
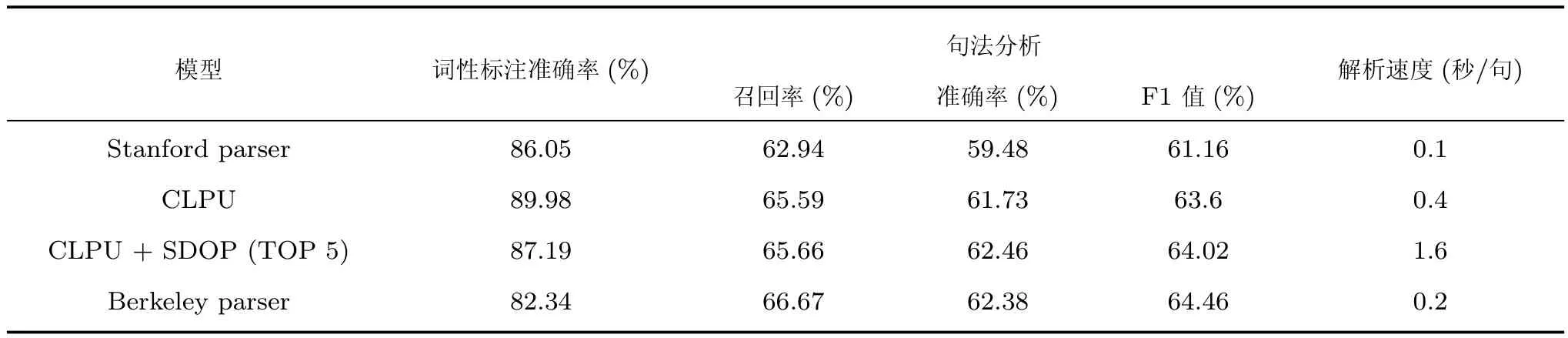
表6 PCTB句法分析结果Table 6 Parsing results on PCTB
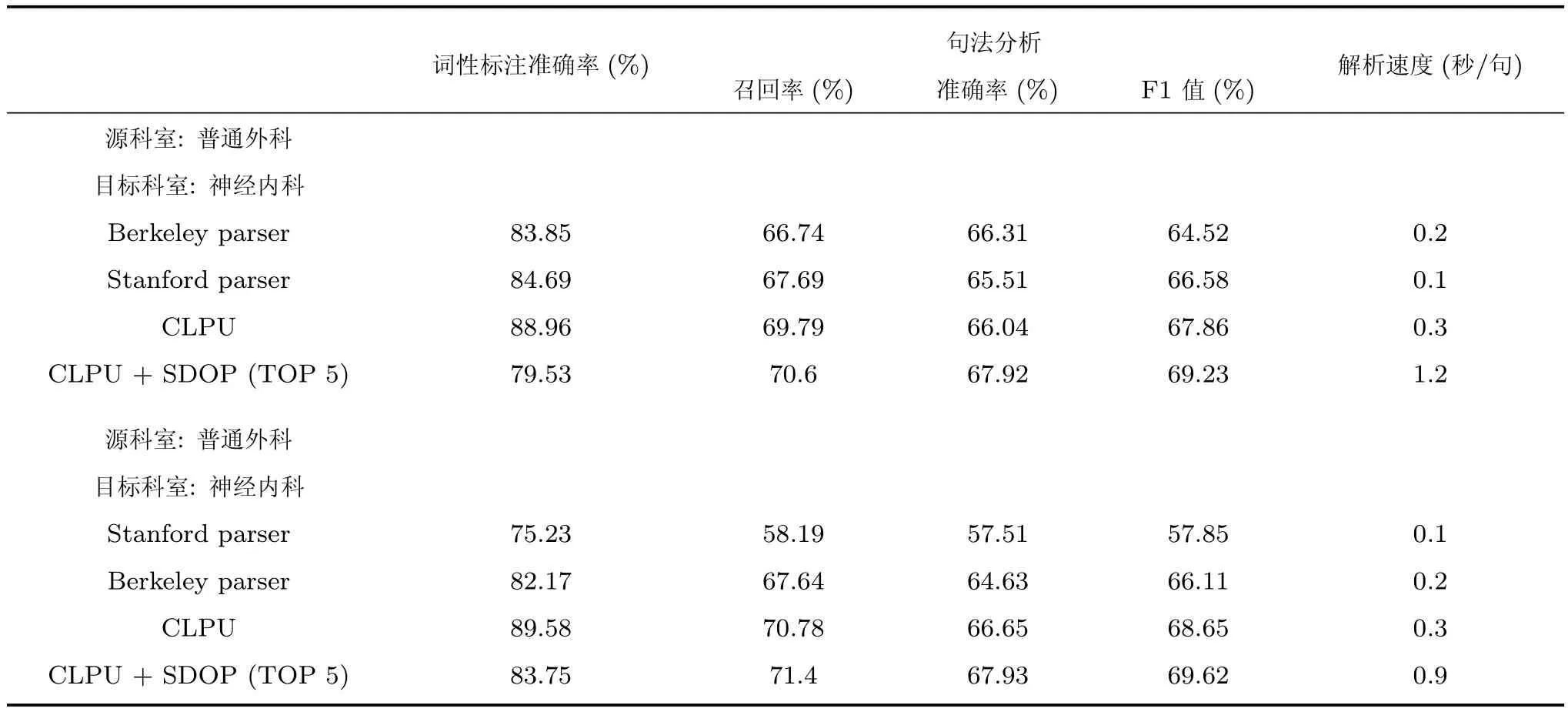
表7 跨科室CEMR句法分析结果Table 7 Parsing results on cross-department CEMR
6 结论
本文针对CEMR模式化强的特点,提出以树片段形式化CEMR复用的模式.首先描述了树片段的相关概念,举例说明标准树片段和局部树片段的区别,然后针对标准树片段的重复比对问题,提出更加高效的标准树片段抽取算法,又利用快速树核算法替换二次树核算法,降低了局部树片段抽取算法的时间复杂度,并通过实验对比了改进前后局部树片段抽取速度的变化,最终获得了标准树片段库和局部树片段库.基于抽取的树片段库,提出了DOP与层次句法分析的融合模型,该模型属于后处理融合,以模型融合的方式避免了单独使用DOP模型精度较低的问题.在预处理阶段,提出了词汇词性混合匹配的初选策略,充分发挥词性在匹配时的泛化作用.在后处理阶段,一方面,从初选树片段内部筛选标准树片段,减少了错误树片段的替换,另一方面,提出了最大化树片段组合算法,简化DOP组合分析过程,缓解了无效树片段带来的噪声.实验结果表明,DOP与层次句法分析的融合模型能够利用CEMR模式化强的特点,有效改善句法分析效果.
CEMR模式化强的特点为DOP创造了更大的发展空间.未来的工作,一方面可以探索更加深入的模型融合方法,进一步提高DOP在融合模型中的比重;另一方面,CEMR高昂的句法标注成本使得无监督句法分析方法更具实用价值,如何充分发挥DOP在无监督句法分析上的优势,提出适用于CEMR的无监督DOP模型是值得研究的问题.
