基于CNN的Webshell文件检测
2019-04-12傅建明王应军
傅建明,黎 琳,王应军
(1.武汉大学 国家网络安全学院 湖北 武汉 430072;2.武汉大学 空天信息安全与可信计算教育部重点实验室 湖北 武汉 430072)
0 引言
Web服务是企业对外服务的接口,因其后台企业数据和消费者数据的巨大价值,吸引了大量的攻击者.根据Internet Live Status 2018年1月的数据[1],全球每天大概有100 618个网站被攻击.并且根据《2018年全球风险报告》[2],网络攻击的次数正在逐步增多,仅2016年就有3.75亿个新型恶意软件和木马程序出现在被攻破的Web服务器上.为了便于攻击者对破袭后的Web服务器进行长期的控守,攻击者会上传一个远程访问工具到Web服务器,该Web服务器上的远程访问控制工具俗称为Webshell.
Webshell本质上是一个采用ASP、JSP或PHP编写的脚本程序文件,驻留在Web服务器的公开访问目录中,攻击者利用浏览器或者定制的客户端软件可以对其直接访问.Webshell提供了对各种关键功能的远程访问,例如执行任意命令、遍历文件目录、查看和修改任意文件、提升访问权限、发送垃圾邮件和钓鱼邮件[3].2018年5月的统计数据[4]指出,PHP在网站服务器编程语言中占据了83.4%;同时,已有的研究主要关注PHP编写的Webshell.因此,本文只关注PHP Webshell,如China Chopper、WSO、C99和B374K等[5-6].当然,其检测方法也可以推广到其他脚本的Webshell.
学术界和安全公司都研究检测Webshell的方法,包括Webshell日志的检测[7]、Webshell流量的检测[8-9]、Webshell文件的检测[10-12].从网页访问的日志中容易检测Webshell,这归因于访问Webshell的IP比较单一、访问次数少、Webshell网页比较孤立,这是一种攻击事后溯源的方式.利用启发式规则或者统计模型从网络流量中检出Webshell流量一直是安全界和企业界常用的方式,Webshell的正则表达式大量用于Web服务器边界的WAF(web application firewall)中,但正则表达式容易被混淆绕过[13],且只能检测已知的Webshell.而Webshell的统计模型一般采用人工构建的特征作为输入参数,这些特征一旦被攻击者感知到,则攻击者可以绕过这种模型[14].
Webshell是一种恶意代码,传统基于特征值匹配的恶意代码检测方法同样适应于Webshell文件的检测[10-12],其优点是检测速度快、检测精准,但变形和混淆会引发漏报,且对未知的Webshell缺乏感知能力.同时,传统机器学习模型检测Webshell文件也需要人工构建的特征作为输入参数,而攻击者可构造绕过模型的Webshell文件.但是,Webshell文件检测非常重要,入侵检测系统在Web服务的边界捕获到可疑文件,需要快速得到检测结果;同时,攻击者在上传Webshell到Web服务器之前,也会测试该Webshell是否能被安全工具和各种公开的Webshell沙箱检出.
Webshell是由脚本语言编写的一种语言文本.因此,可以采用自然语言的语言模型例如N-gram模型、马尔可夫模型处理Webshell,把Webshell看作是不同语言符号构建的、有特殊含义的文本.为了对抗混淆和加密,本文把Webshell转换为脚本编译后的操作码(operation code,opcode),从而把Webshell文件的检测转化为Webshell opcode序列的检测.与此同时,深度学习已经广泛应用于图像识别、声音识别、自然语言处理中[15-18].本文引入深度学习,用以对抗传统机器学习中Webshell的绕过人工特征,同时也希望深度学习模型可以记忆混淆操作和加密操作,从而提高检测的泛化能力.
本文关注Webshell文件检测,提出了基于词汇表模型和深度学习算法卷积神经网络(convolutional neural network,CNN)的检测方法,具体工作包括3个方面:
a) 为了降低Webshell混淆和加密操作对检测的干扰,将对文件的检测转化为对opcode序列的检测,并通过实验证明基于opcode的检测相较于基于原始文本的检测,能够提高检测精度.
b) 分别利用词袋模型和词汇表模型对opcode序列提取词频特征和词序特征,实验证明词序特征对Webshell检测的影响优于词频特征,能够提高检测的精确率.
c) 将改进后的CNN模型应用到Webshell文本检测这个二分类问题,并通过实验证明优于传统的机器学习算法和现有安全工具.
1 相关工作介绍
1.1 Webshell流量检测
攻击者利用SQL注入漏洞或者文件上传漏洞等把Webshell文件上传到Web服务的文件目录中,然后像正常使用Web服务一样利用Webshell.攻击者在利用Webshell时,会在网络中产生网络流量,也会在Web服务器中产生Web日志.利用已知的正常网络流量(日志)和Webshell流量(日志),就可以构建识别Webshell的模型.
文献[7]统计Web日志的分布发现,Webshell的URI资源和URI查询字符比较简短、随意、杂乱,甚至出现畸形字符,Webshell文件的单位时间窗口的访问次数较少,Webshell文件访问的入度和出度比较小,甚至接近于0.这些启发式知识有利于从大量Web日志中发现Webshell的使用痕迹,属于攻击事后的取证.文献[19]把Web流量的每一个记录分为URI资源和URI查询,分别对这两部分以4-gram分割,建立各自修正的TF-IDF权值,最后根据累计的权值识别恶意Web流量,包括Webshell流量.这种加权累加的结果也是一种启发式知识,可以用于在线检测.利用启发式知识识别Webshell的好处是检测速度快,但其对混淆和加密比较敏感.
文献[9]把HTTP请求转换为一个带统计特性的符号序列,采用变阶的马尔科夫模型(variable-order Markov model,VMM)描述该变长的符号序列,然后根据模型出现的概率识别恶意流量,其中包括Webshell流量.该模型可以缓解概念漂移、变长符号、高熵带来的识别干扰.CNN-Webshell[6]引入Word2Vec和CNN[20-21]识别网络流量中Webshell的请求,其检测结果优于朴素贝叶斯、支持向量机、K邻近、随机森林等传统的机器学习算法,其检测准确率比SVM提高了2.6%.
1.2 Webshell文件检测
Webshell文件属于恶意代码的一种,传统恶意代码分析和检测技术同样适用于Webshell文件的检测.理解Webshell文件的结构、内容、特性,可以更好地服务于检测.
文献[18]指出,Webshell习惯性地使用混淆技术逃避特征值的检测,并使用去混淆操作还原Webshell中混淆代码,最后采用一种上下文触发的片断哈希(context-trigger piecewise hashing)对去混淆的Webshell聚类,样本间的聚类关系有助于识别未知Webshell.文献[22]通过静态和动态分析已有的Webshell,发现其可见的特性,如口令的暴力破解、SQL数据库的访问、端口扫描、安全工具的检测等;也发现许多不可见的特性,如一半的Webshell有认证机制,且其中1/3可以绕过,1/3 Webshell执行时会通知某个第三方(不是攻击者),泄漏安装Webshell的Web服务器.如果注册被弃用的第三方域名,则可以捕获感染Webshell主机.该研究揭示了Webshell的生态系统,包括攻击者、感染的Web服务器以及Webshell内置的后门代码,这些后门代码会泄漏攻击者的信息和感染的Web服务器的信息.
文献[23]利用污点分析获取Webshell文件的模式,该模式可以识别未知的Webshell.从已有的Webshell文件中抽取可以标识Webshell的特征.Linux恶意软件探测扫描器[10]、PHP Webshell Detector[11]、D盾[12]等都是利用这些特征的正则表达式检测Webshell.同时,NeoPI[24]通过文件信息熵、文件可压缩比、文件重合指数、单词最大长度、恶意代码片断等统计特征识别Webshell,该统计特征可以对抗部分混淆和加密,提高对未知Webshell的感知能力,但检测阈值是人为经验设定,会出现误报和漏报.文献[25]分析敏感函数和敏感字符串在正常PHP文件和Webshell文件中的使用分布,提出了一种打分机制识别可疑的Webshell,但没有解释如何确定阈值.
文献[26]选取文档属性(如单词数量、分割符数量)、字符串操作函数、命令执行函数(如eval,exec,system)、加解密函数、系统调用函数(如文件操作、数据库操作)等作为特征集,其基于决策树的检测模型取得了较好的检测结果.基于类似的特征集,文献[27]采用了基于SVM的检测模型,其准确性优于决策树模型.文献[28]首先采用NN(nearest neighbor)剔除样本中的可疑噪声,选取NeoPI[24]中特征集,然后应用SVM识别Webshell,其准确性比传统的SVM高2.1%.
2 检测框架
CNN是深度学习中一种被广泛应用的网络,常用于图像识别领域,由于其方便性、可靠性等特点,已经成为图像识别领域的主要研究方法.近些年来,研究者将CNN引入自然语言处理领域用于处理文本分类问题,而Webshell检测也属于文本二分类问题,所以本文将其应用于对Webshell的检测.
本文基于CNN的Webshell检测框架如图1所示,主要包括数据预处理、特征提取和表示以及检测模型3个模块.

图1 检测框架Fig.1 Framework of detection
2.1 数据预处理
数据预处理的工作包括文件去重和opcode获取,本文基于MD5值哈希以去除重复文件.
MD5去重是根据文件内容计算每个文件的MD5值,如果MD5相同,则认为文件相同进行去重.opcode是PHP脚本编译之后的中间语言,其和PHP的关系就类比于jvm字节码和JAVA的关系,它包括操作符、操作数、指令格式及规范以及保存指令及相关信息的数据结构.PHP脚本执行包括4个阶段:词法分析、语法解析、opcode编译、opcode执行.编译器在第3阶段会将opcode与相应的参数或函数调用绑定,即使对Webshell危险函数进行混淆加密,在编译时依然会出现与正常文件编译结果不同的opcode语句.因此可以根据这一特点,利用opcode区分Webshell和正常文件,把对文件的检测转换为对opcode序列的检测,本文利用PHP插件逻辑扩展模块(Vulcan logic dumper,VLD)编译获取PHP文件opcode.
2.2 特征提取及表示
无论是机器学习还是深度学习都无法直接应用于文本,因此需要将2.1节获得的opcode特征向量转变成算法所能处理的数学形式.鉴于本文研究的对象是静态PHP文件,因此在opcode的基础上,通过词袋模型&TF-IDF和词汇表模型分别提取词频和词序特征.
2.2.1词袋模型&TF-IDF 词袋模型是应用于NLP领域的特征提取模型,该模型不考虑词法、语法和语序关系,将文档看作是一袋子独立的单词,基于单词构建字典(dictionary),并根据字典将文档表述为向量.该模型假设存在一个包含正常文件和Webshell文件的文档集合D,里面共有M个文档,提取文档里的所有单词构成包含N个opcode单词的字典(N可根据实际情况进行选择),利用字典将每个文档表示成一个N维向量,向量每一维的值代表该单词在该文档中出现的次数.
但仅凭词频无法反映词的重要性,为了寻找到能更好地概括特征、区分正常文件与Webshell的opcode单词,本文在词袋模型处理之后引入TF-IDF进一步处理.TF-IDF算法利用词的逆文档频率(inverse document frequency,IDF)修正仅仅用词频表示的词特征值,基于词的TF-IDF值过滤掉区分能力较小的单词而保留重要的词语.图2是词袋模型的处理示例.

图2 词袋模型处理示例Fig.2 Example of bag-of-words model
2.2.2词汇表模型 由2.2.1节可知,词袋模型在构建文档向量时,并没有保留单词词序特征,而词序往往包含更多的语义信息,因此本文采用词汇表模型提取PHP脚本opcode序列的词序特征.
词汇表模型假设存在一个包含正常文件和Webshell文件的文档集合D,里面共有M个文档,提取文档里的所有单词构成带有词序序号的N个单词的字典(序号是单词出现的顺序),利用字典将每一个文档表示成一个P维向量(P即代表所选取的最大文档长度),P维向量的每一维的值即是该文档中的单词出现在词典里的序号,而不是单词出现在文档里的次数.图3是词汇表模型的处理示例.
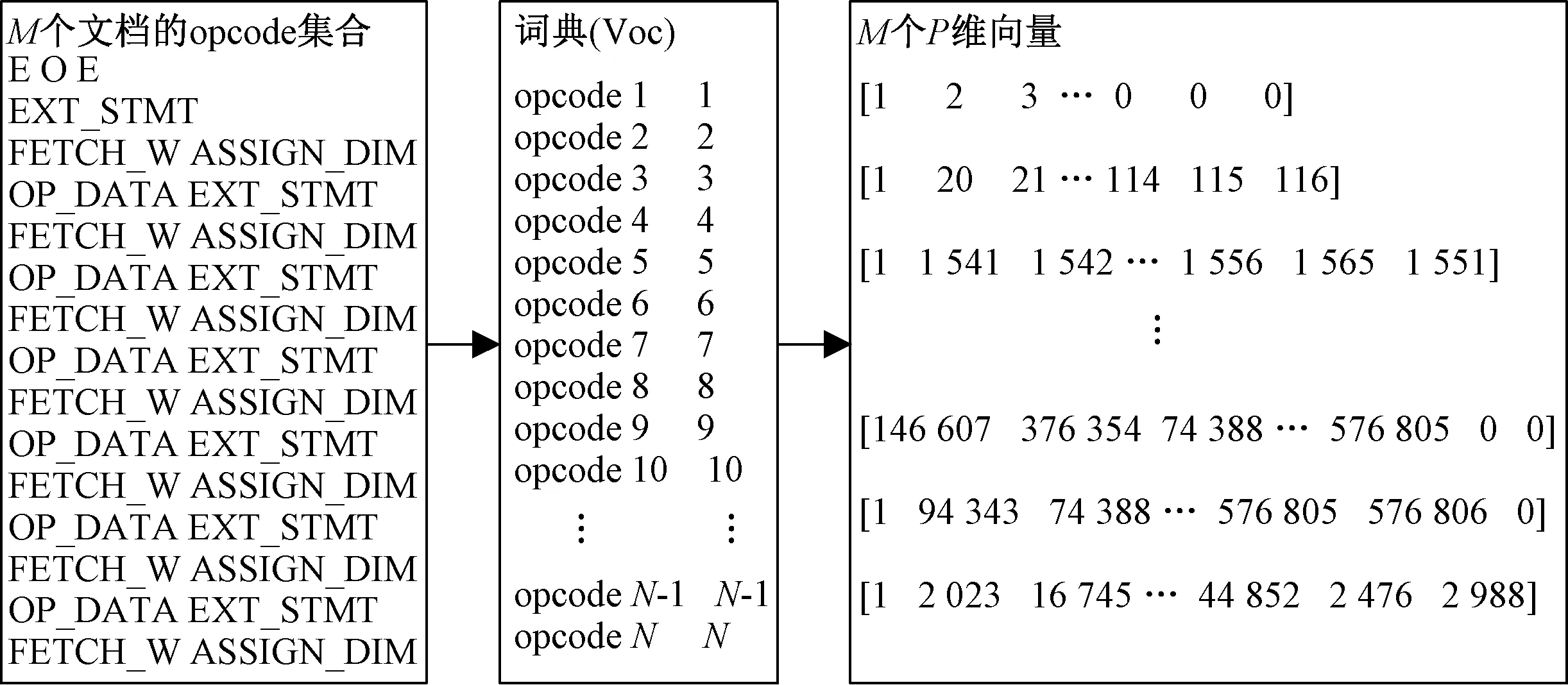
图3 词汇表模型处理示例Fig.3 Example of vocabulary model
2.3 检测模型
传统的用于文本分类问题的CNN结构主要都源于文献[15]一文中的结构,而考虑到数据的稀疏性,本文所用CNN模型结构增加了一层卷积层,并改变原先池化卷积层输出后再合并的方法,而采用先合并卷积层输出再池化的方式.模型结构如图4所示,由两层一维卷积层、全局池化层、softmax层构成.
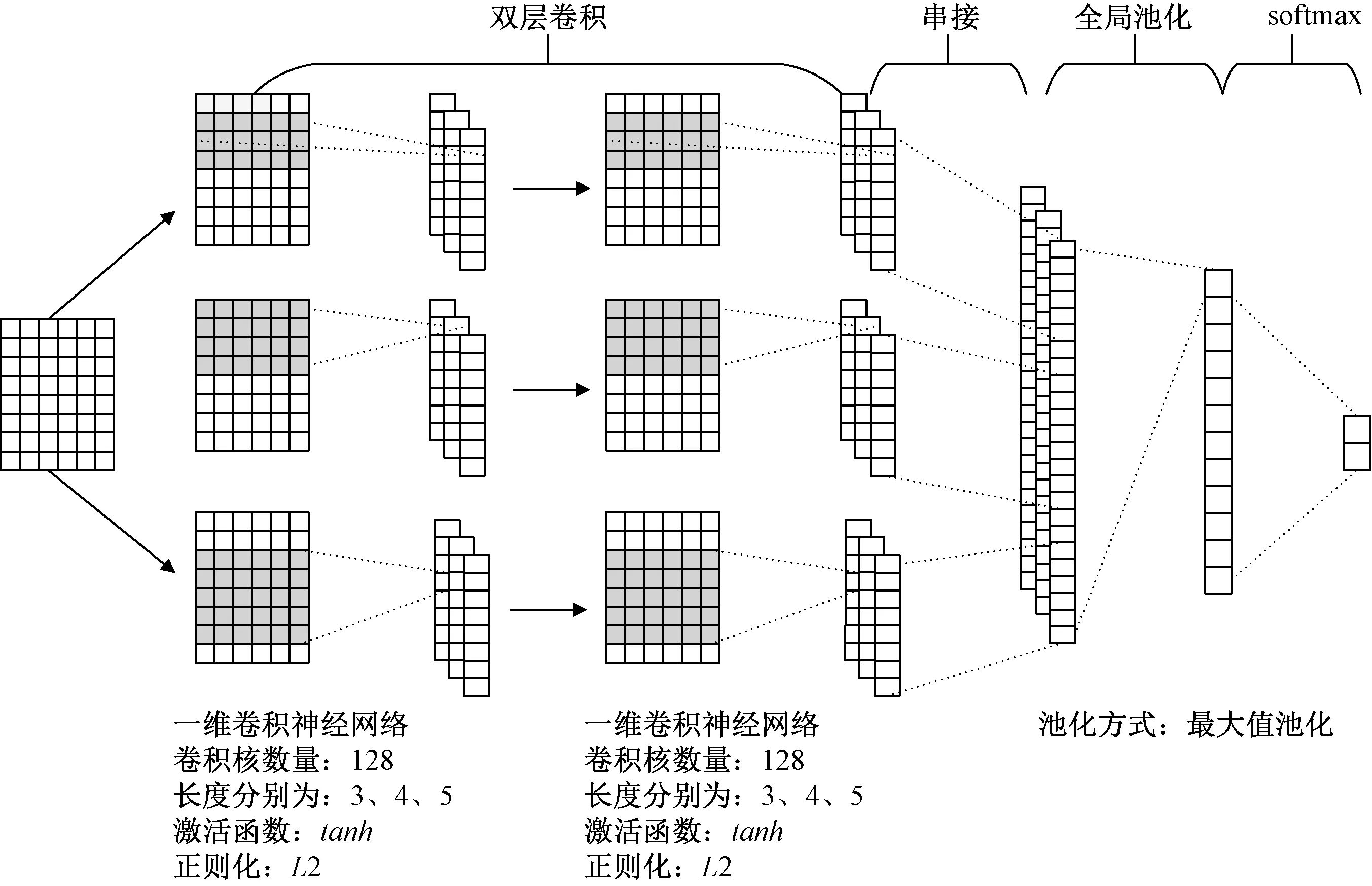
图4 CNN模型结构Fig.4 Architecture of CNN model
卷积层共有两层,每层包含3个卷积核数量为128、长度分别为3、4、5的一维卷积神经网络,通过卷积运算抽取局部特征.给定输入矩阵n*k,n为文档个数,k为特征维数,该卷积层进行卷积时只对列进行卷积.在给定矩阵的位置i,卷积结果为Ci=f(W·Xi:i+h-1+b)∈R,h为卷积核长度,b是偏移量,而f是非线性修正函数,经过实验对比relu和tanh激活函数,发现tanh对准确率、精确率和召回率的影响都优于relu,因此最终f选用了tanh.整个矩阵的卷积结果被表示成一个特征向量C=[C1,C2,…,Cn-h+1]∈Rn-h+1.
由卷积的运算定义可知,卷积得到的特征向量个数与卷积核的个数相等,因此需要对多个特征向量进行融合,本文采用串接方式将多个向量进行连接,形成固定长度的融合特征向量.而后全局池化层对融合特征向量提取最大值,即C(h,m)=max{C(h,m)},降低特征维数,避免过拟合现象发生.
池化层之后是softmax层,池化层的输出通过全连接的方式连接一个softmax层,根据本文工作需要输出两类概率分布,即Webshell和正常文件的概率分布.
在训练中,本文采用Adam算法对参数进行训练.为了提高模型的准确度,本文采用Dropout策略使得部分神经网络单元失效,防止模型过拟合.
3 实验设计与评估
3.1 数据来源
Webshell文件样本主要通过使用“Webshell”关键字搜索下载github公开项目得到,由于本文只关注PHP语言编写的Webshell,所以经过筛选后一共有188个公开项目,例如tennc/webshell、ysrc/webshell-sample、xl7dev/WebShell、tdifg/WebShell、bartblaze/PHP-backdoors等.
正常PHP样本主要使用互联网常见的基于PHP开发的开源软件样本,主要包括WordPress、PHPCMS、phpMyAdmin、Smarty和Yii.
经过MD5文件排重处理后共获得777个Webshell样本和2 437个正常PHP样本.
3.2 实验设置
3.2.1实验条件 本文实验基于python实现,python版本为3.6.4.实验环境是Win10 64bit操作系统,处理器为Intel Core i7-8700K@3.70 GHz,内存为32 GB.
3.2.2实验参数 对数据样本所得opcode个数统计分析如图5所示.大多数文件的opcode个数都在4~50之间,但92%的Webshell文件和73%的正常文件的opcode个数分布在4~300之间.选取50、100、150、200、300作为词汇表模型的最大文档长度参数进行实验验证,最终选择300作为最大文档长度参数.
CNN模型的丢弃率设置为0.5,学习速率为0.001,批处理大小为100,训练周期为5轮,测试集与训练集比例为40%和60%.
3.3 评价标准
Webshell的检测是一个二分类问题,本文选取精确率、召回率以及F1值这3个评估指标用以评估方法性能.实验模型对数据检测分类的所有可能情况如表1所示.精确率(P)、召回率(R)、F1值计算如下:

图5 opcode个数分析Fig.5 Analysis of opcode

表1 分类情况Tab.1 Classification
3.4 实验结果与分析
3.4.1方法性能评估 实验从算法和特征两个角度评估本文方法性能,实验结果如表2所示.
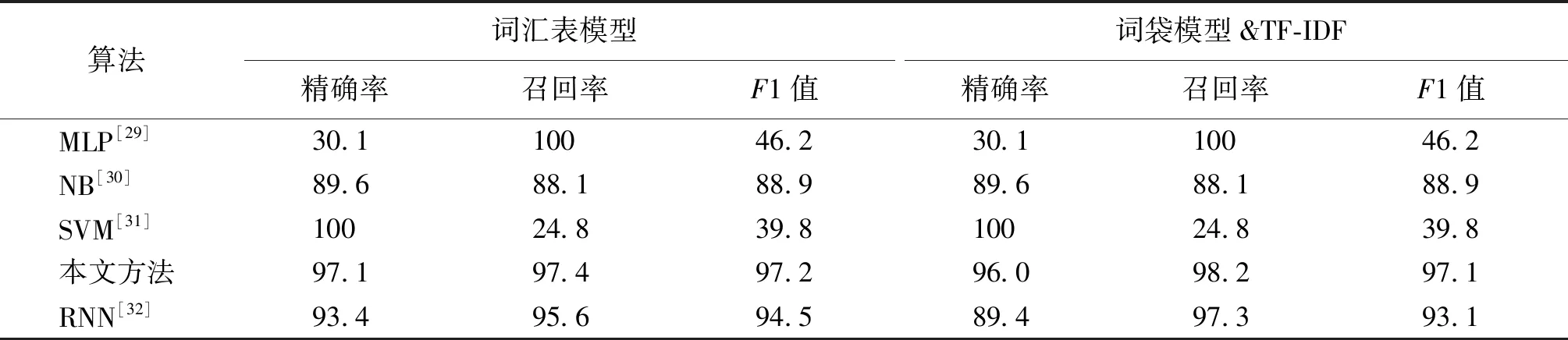
表2 实验结果比较Tab.2 Comparison of experimental results %
在特征方面,本文比较了词汇表模型和词袋模型.由表2可知,前3个算法对于特征的改变并不敏感,但对于CNN和RNN算法来说,基于词序特征的词汇表模型提高了精确率和F1值,其中CNN的精确率和F1值分别提高了1.1%和0.1%.
3.4.2同类工具比较 本文选取对比了现有的4个安全工具:D盾、河马在线查杀[33]、OpenRASP[34]以及深信服[35],这4个工具都支持PHP脚本上传检测.
实验将777个样本上传至4类工具检测,检测结果如表3所示,D盾检测率最高达到了87.4%,但依然低于本文方法的97.1%.

表3 同类工具比较Tab.3 Comparison of similar tools
3.4.3opcode有效性 为了评估opcode的有效性,采用词汇表模型进行特征提取,在原始数据集和opcode数据集上分别进行了实验,实验结果如表4所示.由表4可知,采用PHP opcode作为数据集时,能够提高检测的精度,其中CNN的3个评估指标分别提高了1.2%、1.4%、1.2%.
4 结论
本文提出了一种基于CNN的Webshell检测方法,该方法基于PHP opcode序列,利用词汇表模型提取其词序特征,基于特征向量训练构建CNN检测模型.实验证明该方法无论在精确率、召回率还是F1值,都优于传统的机器学习算法;其次,实验还对比了两类特征模型,证明词序特征相较于词频特征更有助于Webshell检测;此外,通过对比在opcode和原始文本数据集上的实验结果,证明opcode比原始文本更加利于检测;最后,本文还比较了现有安全工具,现有安全工具大多是基于特征匹配的方法,而实验结果表明本文方法检测率优于安全工具,证明了本文检测方法的有效性.与文献[6]相比,本文方法关注的是Webshell文本而非Webshell网络流量,是长文本而非短文本,但两者都使用了CNN来处理检测这个二分类问题,并且实验也证明了CNN解决此类问题的有效性.
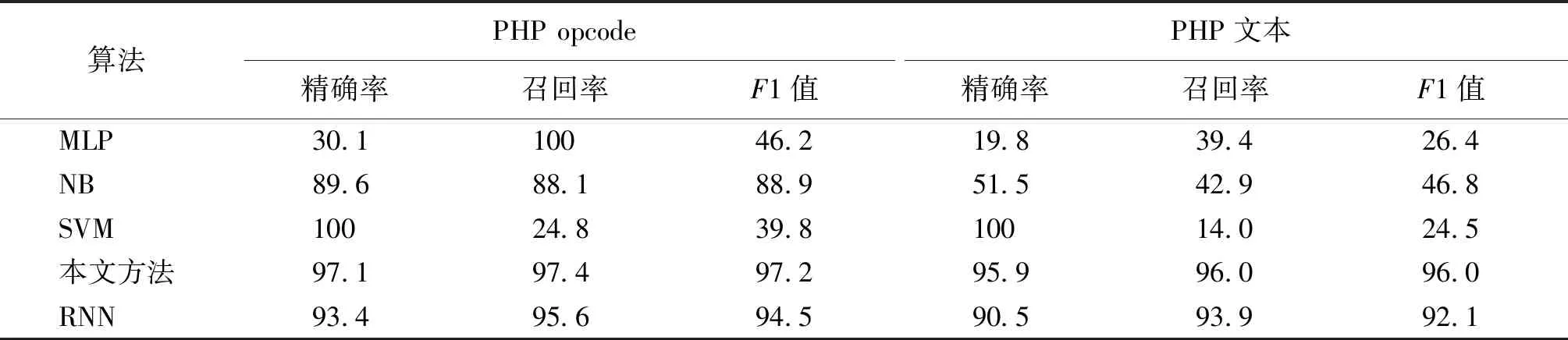
表4 opcode有效性实验结果Tab.4 Effectiveness of opcode %
同时,本文的工作也存在一定的局限性.首先,Webshell样本收集难度大,样本收集数量少,导致检测模型会出现过拟合.其次,检测模型的输入长度是固定的,而样本的长度并非固定,这种长度的不一致会影响模型的检测率.以上两个问题是下一步需要研究和解决的问题.
