基于上下文感知的汤普森采样推荐算法研究
2019-04-12郑操
郑操
(四川大学计算机学院,成都610065)
0 引言
伴随着互联网不断的发展,普通用户可以接触到的信息产生了翻天覆地的变化,人们可以通过不同渠道获取大量的信息,随着数据量的日益增长,我们已经不再仅仅关注基本需求的满足,而是更加注重个性化需求。同样,在推荐系统中如何更好的在用户和信息之间扮演好桥梁作用也变得越来越重要,人与人之间存在很多个体性的差异,人们对于同一个事物的口味和偏好也往往不同,在这其中,个性化推荐就起到了十分重要的作用。
个性化推荐中,十分重要的一点在于如何发掘用户和信息之间的联系,或者说如何发掘用户的兴趣和偏好,由此我们需要一种策略来对用户的兴趣和偏好进行学习,通过用户的行为对用户的特征进行拟合,在推荐系统中常常采用探索与利用框架来描述这一问题,我们既需要通过对用户已知的历史行为来向用户进行推荐,又需要尝试新的方式,探索用户可能存在的潜在偏好。例如某个用户喜欢牛奶和茶,在用户的历史行为中发现存在用户购买牛奶的信息,于是我们可以利用这个历史行为给用户进行推荐,但由于没有购买茶的历史行为,因此无法利用已有的经验向用户推荐茶,所以有时候也需要跳出用户的历史行为,探索用户潜在的兴趣和偏好。
1 算法模型
对于某一个用户,系统存在若干类物品可以推荐,用户对这些物品的偏好是不同的,每类物品都有相对应的上下文信息,用户的偏好未知,现在需要制定一个策略使得在一定轮次的推荐内,用户的满意度越高越好。对于这个问题,本文采用了Bandit 算法框架,并且利用上下文信息以及汤普森采样以及粒子学习来选取每一轮实验所推荐的物品,用正态高斯函数来拟合用户的特征,然后观察每一轮实验的结果,用户对本轮推荐的满意程度,通过不断的实验对正态高斯函数的参数进行迭代训练,使得其能更好地表示用户的特征信息,从而使得推荐的效果随着实验次数增加越来越好。
本文通过概率分布采样的方式来表现不确定性,a*()t 代表第t 轮实验中回报期望最高的那一项,μ代表用户的采样信息,利用回报期望最高项进行推荐,观察实际的真实回报ra(t)。然后对用户特征的高斯函数参数进行更新:
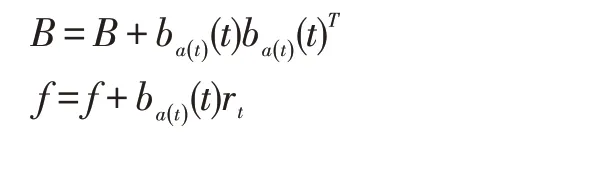

本文还采用了粒子学习(Particle Learning),即一个用户的特征由多个粒子来表示,每个粒子都有各自的参数,用来储存用户的特征以及状态信息,每次会从粒子中选择回报期望最高的那组粒子代表用户的特征参数,并从该粒子对应的正态高斯分布中进行采样。
为了对不同算法的有效性进行评价,本文采用了探索与利用问题中最常用累积遗憾(Accumulated Re⁃gret)和累积回报作为评价指标,首先我们先定义在一个时间轮次上的遗憾R(t):

其中ra*(t)表示在本轮实验中可能取得的最高回报。我们将所有轮次的遗憾累积起来就可以得到累积遗憾的定义:

如果在一个轮次的实验中实际产生的回报和最大可能的回报越接近,那么这个轮次的遗憾就会越小,所以遗憾越小就能表示用户的满意度越高,推荐的效果越好,于是我们的目标就是使得算法模型所产生的累积遗憾尽可能越小越好,或者累积回报越大越好。
2 对比模型
LinUCB[1]是一种基于置信区间上界(Upper Confi⁃dence Bound)的算法,传统的UCB 算法一般都没有考虑到推荐情境中的上下文信息,忽略了待推荐事物本身蕴含的各种特征信息,这样就会导致在实验早期轮次的回报较低,算法的收敛速度慢,而LinUCB 是在UCB 算法的基础上加入了上下文信息,考虑到了不同用户在在不同情境下对事物的接受程度可能不同,所以可以加快系统参数学习的速率,非常适合个性化推荐。
PTS[2]是基于汤普森采样的一种算法,它的特点是利用正态分布来拟合事物和用户的特征信息,在每一轮实验中分别进行采样,将采样得到的特征向量作为本轮实验的事物特征和用户特征,由于采样本身就是一个随机的过程,所以是通过采样的方式实现探索与利用的平衡。
还有一种通过矩阵分解的算法UCB-PMF[3],这种算法是通过对UCB 算法进行了改进,假设每轮实验的回报可以通过正态分布进行拟合,利用这个分布的参数进行调节。
3 实验
本文实验的数据来自HetRec 国际推荐系统信息异质性与融合研讨会上发布的公开数据集Delicious 和LastFM,Delicious 数据集记录的是用户在该网站上收藏的书签以及相应的标记信息,LastFM 数据集则是用户收听音乐家、歌手的相关记录,以及一些好友关系等信息。我们会对这两个数据集进行数据预处理,提取出对应的特征向量并且保留前25 个主要的特征。我们设定在一次实验中,利用LastFM 数据集给用户进行推荐,如果用户曾经收听过这个音乐家的作品,那么本次实验回报为1,否则为0。同样在Delicious 数据集中,如果用户收藏过对应的网址,那么回报为1,否则为0。
实验采用的是一种在线学习的方法,每一次实验都会迭代算法的参数,使得算法参数能更好地拟合用户的历史行为,观察每次实验的回报,计算累积遗憾,通过和对比算法进行实验结果的比较来分析模型的有效性。图1-2 分别为Delicious 数据集和LastFM 数据集对应累积回报实验对比结果。
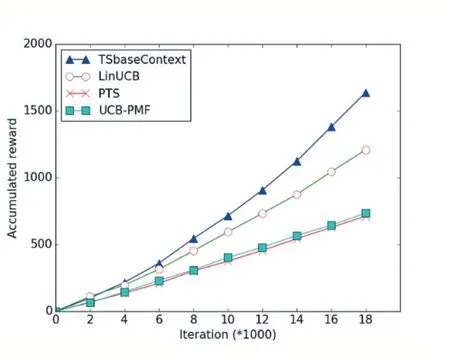
图1 Delicious数据集实验轮次和累积回报关系图

图2 LastFM数据集实验轮次和累积回报关系图
我们从图中可以得出TSbaseContext 算法的累积回报无论是在Delicious 数据集还是LastFM 数据集上都是最高的,这说明利用上下文信息和汤普森采样以及加入粒子学习可以有效地提升推荐算法的有效性,能更快地训练模型参数,对于其他的算法而言,LinUCB算法表现仅次于TSbaseContext 算法,因为LinUCB 算法也考虑到了上下文特征,但由于参数学习没有TS⁃baseContext 算法快,导致在初期的实验轮次,TSbaseC⁃ontext 算法的累积遗憾一直低于LinUCB,另外两个模型虽然考虑到了特征因素,但是没有利用到上下文信息的影响。本文的采用的模型不仅利用采样以及粒子学习的方式拟合用户的特征信息,还充分考虑到了场景中物品的上下文信息,在这两者基础上构建的模型可以比较好地在探索和利用之间找到一个合适的平衡点,使得算法具有比较好的性能。
4 结语
本文采用了上下文特征和汤普森采样以及粒子学习构建的推荐算法模型,在两个真实数据集Delicious和LastFM 上进行了有效性验证,并且根据累积回报作为算法性能的评价指标和其他几个对比算法进行了比较分析,实验结果表明该模型可以比较好地拟合用户的偏好,提高推荐的效率。
