基于CNN 的中文机器阅读理解模型
2019-04-12钱小龙
钱小龙
(四川大学计算机学院,成都610065)
0 引言
机器阅读理解目标是使机器能像人一样阅读文本,根据对文本资料的理解回答问题。对于学术研究而言,它是自然语言处理中最具挑战的也是最有趣的任务之一,是学术研究的最前沿;对于工业界,提高机器对语言的理解能力,对信息检索、问答系统、机器翻译等自然语言处理研究任务有积极作用,同时也能够直接改善搜索引擎、智能助手等产品的用户体验。
机器阅读理解任务中,常用循环神经网络进行序列建模,并取得很好的效果,特别是在单文档答案抽取任务[1]中,很多模型超越了人类水平;多层卷积神经网络用于序列建模[2],极大地提高了模型的训练推理速度,在SQuAD 数据集上也表现极佳[3]。机器阅读理解的最终目标是在大量文本中找到问题答案,例如,在搜索引擎返回的结果里计算正确答案,单文档的任务过于简单。为解决此问题,多个基于Web 日志的机器理解数据集构建产生[4-5],并设计新的文档机器阅读理解任务。该任务中,机器阅读理解系统需要综合所有文档信息,抽取正确答案。此类任务主要面临的问题是由不同文档产生的备选答案中,可能有和正确答案表述不同或错误的内容,有研究[6]指出,这些非正确答案对于机器阅读理解模型训练中是来说是难和正确答案区分的,最终导致错误的答案输出,所以,在多文档机器阅读理解任务上必须重新考虑如何进行答案选择和验证的问题。
在本文中,我们假设不同文档中抽取的答案中,正确答案出现频率应该是最高,而错误答案和其他所有备选答案都是不同的,采用多层膨胀卷积神经网络,设计了一种序列到序列的轻量级模型,能够自动在备选答案进行相印证后给出正确答案[7]。
1 模型构建
1.1 模型整体架构
模型整体架构如图1,主要由四大模块组成。首先是编码模块,让问题和文档使用卷积和注意力机制进行信息融合,产生包含问题信息、文档信息和词语位置信息的语义序列;第二部分是答案抽取模块,采用一个简化版的指针网络的方法,用来预测每篇文档中的答案边界;第三部分是答案内容模型,针对不同文档给出的每一个候选答案,对内容建模评估其是正确答案的可能性;最后是答案验证模块,让所有候选答案进行信息交互验证,给出答案正确与否的可能性。模型最后给出的答案由三个模块评分共同决定。

图1 模型整体架构
1.2 模型构建
(1)数据编码
模型直接加载预训练好的词向量,将问题的词向量序列的经过卷积层进行信息融合后,用注意力机制编码成一个融合了问题语义的固定向量。将该固定向量一起拼接到文档序列的每一个词向量中;为了增加卷积网络对于位置的敏感性,将序列中向量的位置信息也拼接进文档词向量,最后将该向量序列输入到多层卷积网络进行信息交互,输出包含问题信息、文档信息和词语位置信息语义的向量序列。
位置向量:
位置向量的产生可以有两种方案:一是直接当作模型参数进行训练得到,这种方式会增加模型参数和模型大小;二是用计算方式给定位置向量参与计算。其位置向量的计算方式如下:

其中,pos 是位置,i 指的是维度,dpos是向量大小。
实验结果表明[8],用计算方式给定位置向量和训练得到的位置向量效果几乎相同,本文采用后者。
注意力机制:
传统的卷积神经网络中,信息融合主要采用的池化方式。考虑语言序列中不同词语对于序列的语义信息表达具有不同的贡献度,模型对平均池化的方式进行修正,采用一种注意力机制的方式进行问题序列的语义融合。x 为最后问题的语义编码向量。

卷积网络设计:
在卷积结构中,经验[9]表明,在自然语言处理中,使用门线性单元(Gated Linear Unit,GLU)作为激活函数,效果最佳。因此模型采用带门激活机制的卷积神经网络(Gated CNN,GCNN):

在阅读理解模型进行计算时,需要极大地依赖原始文档的信息,为了使信息尽可能地向后流动模型在GLU 之上引入了残差结构:

本文模型使用的上面等价的GCNN 结构,如图2所示。

图2
即:

化简以后得到:
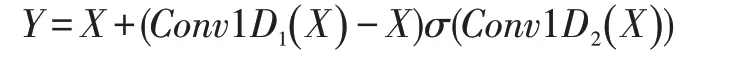
模型中卷积操作采用膨胀CNN 实现。膨胀CNN,又叫空洞CNN,它通过在卷积核中增加“空洞”,从而在不增加参数量的情况下让捕捉更远的距离。普通CNN和膨胀CNN 计算方式如图3 所示。
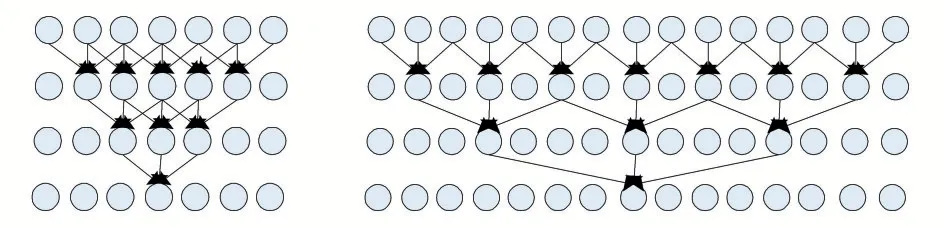
图3
同样三层卷积神经网络,窗口大小为3。左侧是普通CNN 在第三层时仅能融合7 个输入的信息位,而右侧能融合15 个输入的信息位。模型采用该CNN 结构堆叠,能够较好地扩大CNN 的感受野,从而捕获长文档中词序列之间的关系。
(2)答案抽取模块
数据编码模块输出了一个整合了问题和文档信息的序列,模型采用类似于指针网络的方式,直接对序列处理,得到候选答案的开始与结束的位置,如下:

使用pQA对整个问题和文档信息作为编码,使用模型能够在文档没有答案时,用pQA对候选答案边界生成进行调控。
对于损失函数可以写作以下形式:

(3)答案内容模型
为了从多个候选答案中得到正确答案,除了得到答案边界信息,还对上面模型产生的候选答案的内容进行建模。模型计算文档中单个词在答案中的概率:

为了训练这个模型,我们可以将序列中答案词和非答案词标注为1 和0,则损失函数可以定义为交叉熵形式如下:
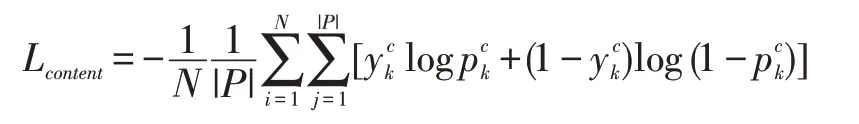
根据得到的每个单词概率,对文档所有词语的向量进行加权求各得到该文档中的答案编码:

(4)答案验证模块
答案抽取模块中单独考虑各个文档中产生的答案,文档间的交互信息考虑很少。产生正确答案需要让答案能够相互间进行信息交互,选出出现最多的答案作正确答案。模型采用注意力机制,让各文档的答案编码之间进行计算,得到可视为收集了其他答案支持证据以后的答案编码。计算方法如下:

将rAj和送入一个全连接层,并归一化为概率,即得到候选答案为正确答案概率为

定义该模块的损失函数如下:

总体损失函数:
模型定义了三个模块,作用分别计算答案边界、预测词语成为答案内容的可能性和选择最优答案。为了能够对三个模型一起进行联合训练,我们把模型的总损失函数定义如下:

在进行答案预测时,计算每个文档答案边界的得分:

对每个Ai中的词计算内容模型概率的均值,对Ai计算,最后答案得分:

输出sc ore 最大的答案即为最后预测的正确答案。
2 实验
2.1 实验数据
本文采用大型开放中文机器阅读理解数据集Du⁃Reader 作为计算数据。该数据集上,问题和文档均来自于百度搜索和百度知道,答案由手动生成,提供了多种问题类型和丰富注释。该数据集包含了201574 个问题,每个问题保留了其中的top-5 的搜索结果,数据集中有超过67.28%的问题有多个答案,有56.38%的问题存在多个答案抽取区间,这些数据表明,如果模型可以合理地利用答案,可以为验证正确答案提供强力的证据。各种类型问题具体分布如表1。

表1 DuReader 问题类型分布
由于模型处理方式的不同,可能在不同的问题类型上,会有不同的表现。
2.2 实现细节
本文使用数据集已经分词序列预先训练词向量,词向量围度300,模型训练过程中作为固定向量载入。对问题的词向量序列进行了两层卷积运算,在问题文档编码信息融合中使用四层膨胀GCNN 堆叠。由于数据集中文档经常较大,参照数据集基线系统用启发式的策略选择代表文档的段落提交给模型训练。超参数初始化β1,β2设置为0.5,使用训练模型使用Adam 算法,学习率0.0004,批量大小32,对所有训练参数进行指数平滑,衰减率0.999。
3 实验结果及分析
数据集提供了两个Match_LSTM 和BiDAF 两个基线系统,采用BLEU-4 和Rough-L 两个指标对模型进行评价。

表2 模型实验结果
从表2 可以看出,本文的模型效果较其他经典RNN 模型好,但相对人类得分还是有不少差距。
本文模型架构的简单,采用膨胀卷积做信息融合,训练计算时间是基线系统的1/5 左右。
答案内容模型的引入,可以比较好地降低答案中停用词级别的词语权重,能够使不同候选答案更好的区分度,特别是对数据集中的是非类型的问题效果较好。而对于实体和描述类的问题,验证模块通过交互验证,能够较好地区分答案的正确与否。
4 结语
本文采用带残差机制的膨胀GCNN 作问题和文档做信息融合,根据多文档阅读理解的任务和卷积模型特点试图设计一个更快速的端到端模型,使用了一种比较简便的答案边界确定方法,采用答案内容模型和答案验证模型对正确答案内容进行确认。实验结果表明基于卷积神经网络络的多文档机器阅读理解模型,能够在更快的时间内完成模型训练,并超过BiDAF 和LSTM 模型结果。由于引入的答案内容模型和答案验证模型两个模块,需要在候选答案产生以后进行计算,文档信息整合也必须在问题的语义向量计算完成以后进行,模式并行性有所降低。可以考虑调整模型结构,将所有计算并行起来,提高计算效率。
