基于一维卷积神经网络的多特征社交网络流行度预测研究
2019-04-12林锦发程良伦应稼田
林锦发,程良伦,应稼田
(1.广东工业大学计算机学院,广州510006;2.广东工业大学自动化学院,广州510006)
0 引言
社交网络(例如Facebook、Flickr 和微博)的流行度预测旨在利用在线系统中传播的媒体信息(例如照片、视频)或社交网络元数据(例如媒体信息的发布时间、观看次数和转发次数等)预测某些事物在未来一段时间内的流行度。随着移动互联网的兴起,社交网络也变得越来流行。人们在这些社交网络平台上即时发布文字、图片、视频等内容,促使社交网络信息的爆炸式增长。如此规模巨大的社交网络信息无疑给流行度预测带来了新挑战与新难度。
目前,国内外学者对在线社交网络流行度预测已有一定的成果且研究方向大致可以分为两大类。第一类则通过时间因素或具有固有时间信息的属性来估计某一事物的受欢迎程度。Wu 等人提出通过展开用户社交媒体信息的背景动态并将时间背景纳入其中来预测受欢迎程度[1]。He 等人将用户评论建模为时间感知的二分图,提出了一种基于正则化的排序算法[2]。虽然这些模型成功地使用了时间信息来预测流行度,但只使用了关于时间信息的元数据特征,基本的非时间信息元数据特征(如观看次数、转发次数)缺乏考虑。如何将多种元数据特征纳入社交网络流行度预测研究仍然是一个值得研究的问题。
第二类侧重于研究整体流行变化的演变趋势,即关注于内容的统计量分析。在早期,Szabo 和Huber⁃man 利用一种称为模式特征分析的方法来预测社交网络人气趋势[3]。Roy 等人提出了一种新颖的学习框架,利用来自社交流的背景知识来捕捉突然流行的趋势[4]。Mathioudakis 和Koudas 通过社交网络中的突发关键词来检测社交媒体的流行趋势[5]。虽然以上模型可以成功地理解流行度趋势的一般演变进化机制,但是面对大规模社交网络信息,其数据量巨大与复杂,存在许多不同因素的影响,例如内容的质量、内容与用户个体的相关性,这些都难以衡量,这将促使前期特征工程巨大。其次,真实世界中事件之间的关系和事件本身都很难提取,也很难建模。从微观层面来看,整体流行度的演变可能通过复杂的用户行为和内容属性描述,这些行为也很难提取出具有代表的特征。
为了解决上述问题,本文提出一种基于One-DCNN 的多特征社交网络流行度预测方法。这也是首次使用卷积神经网络进行社交网络流行度预测的特征提取任务中。该方法首先使用先验知识规则对多种元数据进行先验特征预处理,接着搭建One-DCNN 对预处理后数据进行特征提取,最后使用基于直方图算法的LightGBM 对其进行回归分析与预测。
1 整体框架
提出的基于One-DCNN 的多特征社交网络流行度预测方法由三部分组成:先验特征构造、基于One-DCNN 的多特征提取和LightGBM 回归分析。整体框架如图1 所示,具体如下:
(1)先验特征构造:首先对输入的社交网络元数据根据先验知识进行预处理,接着采用独热码(One-Hot Code)编码机制将映射值转为0-1 特征表。
(2)基于One-DCNN 的深度特征提取:考虑到预处理后的数据为1*N 的一维向量,使用三个卷积层和三个全连接层组成的One-DCNN 来提取特征。
(3)LightGBM 回归分析:使用LightGBM 对上一阶段倒数第二层全卷积层提取的特征进行回归与预测。
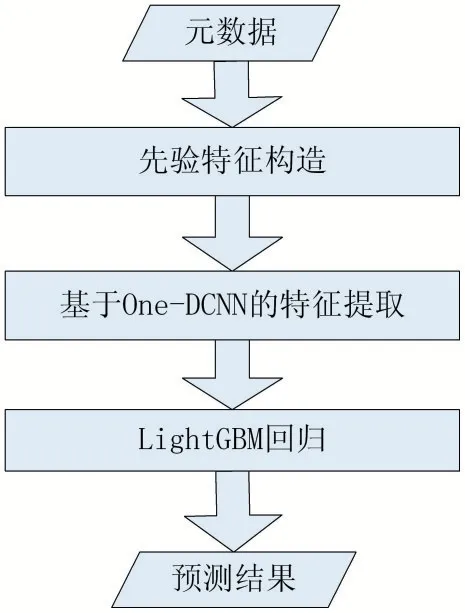
图1 整体模型框架
1.1 元数据
本文使用图片分享网站Flickr 公开的超大规模数据集,包含超过432000 条元数据。一条元数据为一张照片对应的基本属性与社交活动的统计描述等元数据,每一种元数据将其视为一个特征属性,其中包括唯一标识号(pid)、关联的用户标识号(uer_id)、发布日期(postdate)、评论计数(commentcount)、人物数(haspeo⁃ple)、标题和标题的字符长度(titlelen 和deslen)、帖子中标签的数量(tagcount)等。同时,也包括了以用户为中心的信息,如平均观看次数(avgview),组数(group⁃count)和参看照片的平均成员数量(avgmembercount)等。在训练集数据集中,每条数据都有一个标签,即社交网络流行度值,值越大,表明该照片在Flickr 平台上越热门。本文最终预测的结果也是一个数值,数值越大则该事件越热门。
1.2 One-Hot编码
One-Hot 编码是指用N 位状态寄存器来对N 个状态进行编码。例如将[0,0.3],(0.3,0.6],(0.6,1]表示为100,010,001,此时N 为3。One-Hot 编码将离散特征的取值扩展到了欧氏空间,离散特征的某个取值就对应欧氏空间的某个点。在回归、分类、聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而常用的距离或相似度的计算都是在欧氏空间的相似度计算。
1.3 先验特征构造
因为特征属性中含有与时间相关的特征和与时间不相关的的特征,在进行One-Hot 编码前,需要使用先验知识规则对其进行预处理。
(1)处理与时间不相关的属性:使用特征映射方法来获得原始特征的统计信息。特征映射步骤如图2 所示,即在同一区间相同数值大小间隔中,元数据映射到相同的值中。这样就能成功减小每个属性所占用的区间值即数据的跨度,减少后续的计算量。然后采用独热码编码机制将映射值转化为具有0 和1 的特征表。经过独热编码之后,属性的特征变成稀疏了。这样做的好处有:
①解决分类器不好处理属性数据的问题;
②在一定程度上也起到了扩充属性特征的作用;
③连续变量经过编码后,从一个权重变为多个权重,提升了模型的非线性能力;
④随着将大权重拆分成几个小权重管理特征,降低了异常值对模型的影响,增加了模型稳定性。
映射规则如公式(1):

其中j0为k0到k1+C0区间的映射,以此类推到整个k 区间。Ci>=0,该值决定了图2 中两个区间之间重叠区域的大小,这个重叠区域避免区间分界处的特征出现偏差。

图2 与时间无关的元数据特征的数据预处理
对于与时间无关的元数据特征,可以灵活地选择适当的时间间隔。于是,设计了三条基于元数据观测值的先验知识规则,如下所示:
●规则1:每个间隔应覆盖数据样本的一些特征值,以使每个特征更具代表性。
●规则2:每个间隔的大小被设置为使得每个间隔大致包含相似数量的数据样本。
●规则3:间隔的大小与每个元数据特征的平均值有关。例如,第一个区间的范围可以设置为某个特征的平均值的1/3,而第二个区间的范围可以设置为1/2的平均值。
在对与时间无关的元数据特征进行分析之后,发现相当多的特征值在相邻区间的分界点附近。这些特征值可能具有两个相邻区间的特征。所以我们将图2虚线框所示的重叠区域的值同时映射到两个相邻区间。
与时间无关的元数据特征预处理伪代码如下:

(2)处理与时间相关的属性。时间特征在预测任务中起着重要作用。不少文献[15-16]通过时间对上下文语境进行建模来预测事物的流行度,并提出了在多时间尺度上研究社交网络流行度。受到这些论文的启发,将元数据中的时间戳,即“发布日期(postdate)”这个属性转换为具有不同时间尺度的新特征,包括年转为季、月、周;月转为周、天;周转为天;天转为时刻,等等。对于“时间区域”这个属性,我们将它们中的每一个都视为一个特征。另外地,考虑到用户上网行为具有时段性,人们正常使用网络的高峰期为8 点-12 点;14 点-17 点;20 点-22 点。所以在特征映射阶段,将24 小时进行错分,使其时间特性更加精确,即:与时间相关的元数据特征预处理伪代码如下:

在对时间相关和时间无关的元数据特征进行上述数据预处理之后,可以通过前后连接来自上述处理过程的结果来获得数据样本的特征表示。获得的特征表示为一个一维的向量。
2 One-DCNN网络结构设计
2.1 卷积神经网络
卷积神经网络主要部分是卷积层和采样层。

图3 卷积神经网络基本结构
如图3 所示:mi×ni,mc×nc,ms×ns分别为输入层、卷积层和采样层中特征图的维度大小,C1×C2为卷积核的维度大小,S1×S2是两个维度上下采样的比例。卷积层中的特征图大小是由上一层特征图和卷积核的大小共同决定的,而采样层的特征图大小由上一层特征图和下采样的比例决定。具体关系如下:

卷积层通过卷积核对输入信号的卷积操作进行特征提取。卷积核的形状和个数直接决定了网络的整体性能:卷积核越小,提取的特征会越细致,但是会丧失输入信号的相关性信息,使得网络的泛化性降低.相反,卷积核越大,虽然会保留相关性信息,但是会造成信号的细节缺失。同时,卷积核的形状也应与输入信号的特征相匹配。卷积核个数的不同代表着输入信号的特征提取方式的不同,即观察输入信号的角度不同。一般情况下,卷积核个数和网络整体性能呈正相关关系,但是在增长到一定的上限后,在增加网络计算规模的同时,其给性能带来的提升会变得非常有限[6]。所以,卷积层的设计是针对不同目标任务的调优过程。
采样层会对卷积层提取出的特征进行下采样,采样方法有均值采样(Mean_Pooling)、最大值采样(Max_Pooling)等。采样比例的增大会提高网络泛化能力,降低网络规模,但是过大的降采样比例会丢失大量特征信息,造成网络性能的下降,所以采样比例的选择要适中。这种对提取出的特征进行高层聚合的行为是除了局部卷积以外,提高网络泛化能力的第二个重要途径。最后,在输出层之前会添加一个全网络层,用以将之前的局部观察结果进行整合连接,进而在输出层得出分类回归结果或后验概率。
2.2 一维卷积神经网络
卷积神经网络起初被广泛应用在图像等领域,网络的输入大多是图像等二维矩阵。卷积核、特征图等网络内部结构也都是二维的。随后卷积神经网络被应用于语音识别任务中,因为语音是典型的一维信号,为了适应语音信号的一维特性,文献[7]提出一维卷积神经网络用于语音信号的处理。因为一维卷积神经网络中的输入是一维向量,所以网络内部的卷积核、特征图也都是一维的即图3 中的mi、mc、ms和C1、S1均等于1。表示第i 层第j 个特征图上第y 个位置的值,该值可以通过上一层的一维向量和一维卷积核进行卷积得到:
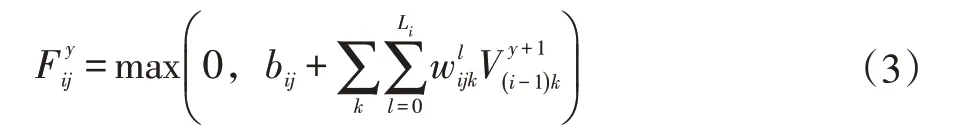
式中,max(0,x)为激活函数,bij是偏置项,k 为在(i-1)层中连接到此特征图的特征图集合的序号,表示连接到序号为k 的特征图的卷积核中第l 位置的值,Li 第i 层中卷积核的长度。
受到语音识别在一维卷积神经网络任务中获得成功的启发,在保留卷积神经网络的局部观察、权值共享以及高层聚合等特性[8]的同时,为了适应先验特征构造后的一维特征向量,本文构建出One-DCNN,用于提取元数据特征,如图4 所示。

图4 One-DCNN结构
由三个卷积层和三个全连接层组成:
(1)对于卷积层,它是提取数据结构特征的必不可少的层。每个卷积层后面都有一个Max_Pooling 层,并由ReLU 函数激活。Max_Pooling 有效地减少了网络的大小,加快了计算速度。
(2)对于全连接层,紧随其后的是Dropout 操作,并由ReLU 函数激活。Dropout 操作可以有效避免过度拟合。先前的卷积层提取相对具体的特征,而全连接层提取相对抽象的特征。依据U-Net[9]神经网络的思想,将第二个卷积层的输出与最后一个卷积层的输出拼接为第一个全线性层。这样能更好地融合高低层特征。
2.3 One-DCNN获取特征的有效性
为了说明One-DCNN 在大规模社交网络数据集中能有效提取出多种元数据特征,展示了One-DCNN 提取到的一些特征例子,如图5 所示,其中子图(a)和(b)是两个数据样本的特征直方图,其标签值都为1.0,而子图(c)是标签值为2.0 的数据样本的特征直方图。从这三个直方图的形状中,可以观察到样本1 和样本2的直方图分布非常相似。相比之下,样本2 和样本3的直方图分布差异很大。因此,可以得出这样的结论:One-DCNN 可以提取出有效的特征表示,从而很容易地区分具有不同标签值的样本。在数学上,可以计算它们的特征向量之间的欧氏距离。如表3 中的距离矩阵所示,样本1 和样本2 的特征值之间的欧几里得距离为0.10,而样本1 和样本3 的特征值之间的距离为11.47。同样地,欧几里得距离越大,获取的特征区分度大,说明One-DCNN 在本模型中提取特征的有效性。
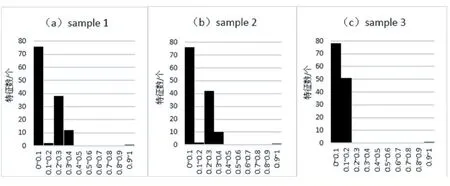
图5 One-DCNN提取不同样本获得的特征分布
此外,表2 中绘制了另一个距离矩阵。如表2 所示,其欧几里得距离值是直接在先验特征构造阶段获得的特征计算的,而表1 中的值是根据One-DCNN 提取特征后计算得来的。对于具有相同标签值的数据样本(即样本1 和2),表1 和表2 中的距离值分别是0.10和1.41。对于具有不同标签值的数据样本,例如样本1和3,表1 和表2 中的距离值分别是11.47 和1。从表2 可以看出,具有相同标签值的样本sample1 与sam⁃ple2 之间的欧氏距离大于具有不同标签值的样本sam⁃ple1 与samlpe3。这更加表明了使用One-DCNN 对大规模数据集进行多特征提取的重要性。

表1 One-DCNN 获取不同样本特征的欧几里得距离

表2 先验特征构造阶段不同样本特征的欧几里得距离
3 基于直方图算法的LightGBM
LightGBM 是一个梯度boosting 框架,采用直方图算法,其思想是将连续的浮点特征离散成k 个离散值,并构造宽度为k 的直方图。使用直方图算法的Light⁃GBM 具有降低内存消耗的优点,直方图算法不仅不用额外存储预排序的结果,而且可以只保存特征离散化后的值,这值一般用8 位整型存储就足够了,内存消耗可以降低为原来的1/8。LightGBM 还使用按层生长(level-wise)的决策树生长策略,level-wise 过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,也好控制模型复杂度,不容易过拟合。
将One-DCNN 的第二层全连接层(即图3 中的Full-linear2)的输出接入到了LightGBM 作为其输入,因为第二层全连接层提取了输入数据的具体和抽象的特征,经One-DCNN 统一处理后得到的特征向量数据量大且具有稀疏性,而这些特征可以被LightGBM 模型无缝地用于网络热点的预测。
4 实验与分析
本文采用深度学习框架PyTorch 进行实验研究,PyTorch 能够在强大的GPU 加速基础上实现张量和动态神经网络。服务器配置如下:Ubuntu-16.04LTS,CPU为Intel 酷睿i7-8700K 处理器,主频3.70 GHz,64 GB内存,GPU 为NVIDIA GeForce GTX 1080ti,11GB 显存。
根据时间顺序将数据分成训练集和测试集,训练集包含389155 个样本和一个测试集包含43235 个样本。因为每条数据都有一个真实的标签,在训练阶段会得到一个预测结果,所以使用Mean Absolute Error(MAE)和Mean Squared Error(MSE)进行性能评估。实验结果如下:MAE:0.7862,MSE:1.1386,SPR:0.8524。
4.1 One-DCNN的调参
对于One-DCNN 网络的参数优化,首先正常的卷积神经网络模型通常会出现过度拟合。因此,引入Dropout 和L2-regularization 技术。然后尝试两种卷积核组合,一种是“3,5,4”的卷积核,另一种是“2,3,2”。并且做了对比试验,如图6 所示,分别测试了CNN,CNN+Dropout,CNN+L2-regularization,CNN+Dropout+L2-regularization 的性能。从图中可以看出,CNN+Dropout+L2-regularization 可以获得更好的性能。特别是“3,5,4”的卷积核优于“2,3,2”的卷积核,这表明更大的卷积核往往适用于大规模的数据集。

图6 不同卷积核在不同优化模型中的性能表现
One-DCNN 网络结构的参数如表3 所示。其中卷积层的值以“input,output,kernel,stride”格式表示,即输入通道的大小,输出通道的大小,卷积核大小和每个卷积层的步长。Max_Pooling 层的值为“kernel,stride”,即Max_Pooling 层的卷积核大小和步长。Dropout 的值是一个概率。全连接层表示神经元的数量。
4.2 LightGBM的调参
LightGBM 中有许多参数,如“num_leaves”、“max_bin”、“learning_rate”、“min_data_in_leaf”、“min_child_weight”、“feature_fraction”和“bagging_fraction”等。该实验使用交叉验证来调整参数以寻求最佳参数组合。
特别对于“num_leaves”(即叶节点数),这是控制树模型复杂性的重要参数之一。理论上,可以通过设定num_leaves=2(max_depth)。但这样容易过拟合,因为当这两个参数相等时,leaf-wise-tree 的深度要远超depthwise-tree。因此在调参时,往往会把num_leaves 的值设置得小于2(max_depth)。如图7 所示,“num_leaves”值对LightGBM 性能的影响。从图中可以看到,较大的“num_leaves”值往往会获得更好的性能。但是,较大的“num_leaves”会导致更多的时间成本。
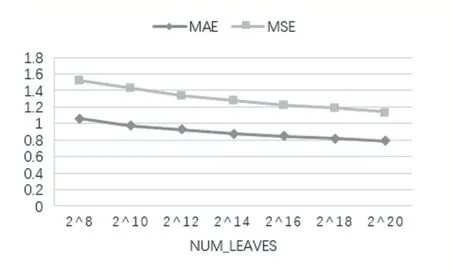
图7 不同的“num_leaves”在LightGBM模型的表现
LightGBM 是一个非常复杂的模型,有很多参数。其参数设置如表4 所示。
4.3 与传统模型对比

图8 与单一模型对比
采用时间序列分析法(ARIMA)、多项式核函数相关向量机(Kpoly-RVM)作为对比模型。如图8 所示,展示了不同模型的性能。从对比结果可以得到如下结论:
(1)相对于ARIMA 模型,本文模型针对大规模网络热点事件的预测性能更优,这表明本文模型克服了ARIMA 只能描述网络热点事件线性变化、周期性变化的特点,具有较好的非线性预测能力。

表3 One-DCNN 网络结构参数

表4 参数设置
(2)相对于单一函数的Kpoly-RVM 模型,预测值与真实值吻合得相当得好,预测误差明显低于单一核函数预测误差,能够达到理想的预测效果。这表明One-DCNN 在特征提取阶段可以进一步挖掘隐含于社交网络动态变化信息,促使预测结果更加可靠。
4.4 与其他回归模型对比
由于预测社交网络流行度可被视为回归问题,因此现有机器学习模型可直接应用于Flickr 数据集的元数据特征。因此,将本文的模型与一些常用方法,包括线性回归(Linear Regression,LR),决策树回归器(Deci⁃sion Tree Regression,DTR),AdaBoost 回归器(AdaBoost Regression,ADR)和梯度提升回归器(Gradient Boosting Regression,GBR)进行比较。如图9 所示,本文模型在所有三种性能指标方面均优于其他方法。
5 结语
针对传统的社交网络流行度预测模型只考虑了少数的特征,致使预测结果在大规模数据集中表现不好,提出基于一维卷积神经网络的多特征预测模型。该模型充分考虑了10 种元数据特征,首先进行先验特征构造,形成具有一维特性的0-1 向量,接着搭建一维卷积神经网络,以卷积核作为观察窗,提取数据的深层特征。随后,使用LightGBM 对倒数第二层的全卷积层提取到的特征进行回归。最后,选取多种常见社交网络流行度预测模型进行对比实验,实验结果验证了该模型较其他模型在大规模数据集上效果更好。未来工作需要对一维卷积网络结构进行改进与完善,进一步提升网络训练速度。
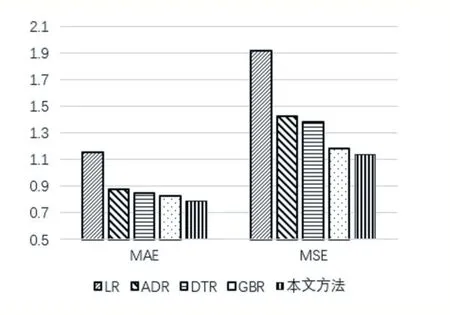
图9 与其他回归模型对比
