图正则化字典对学习的轻度认知功能障碍预测
2019-04-10魏彩锋孙永聪曾宪华
魏彩锋,孙永聪,曾宪华
(1. 重庆邮电大学 计算机科学与技术学院,重庆 400065; 2. 重庆邮电大学 计算智能重庆市重点实验室,重庆400065)
目前,多媒体技术飞速发展,图像数量呈指数级增长,图像分类技术也得到了飞速发展。图像分类方法主要包括分类器的设计和特征提取两个部分,目前对图像分类的研究主要集中在分类器性能的改进和改善特征提取方法两方面。稀疏编码(字典学习)[1-10]是图像分类的有效技术之一,用于图像分类的字典学习算法也可以分为2类:1)学习字典把原始图像映射到有利于图像分类的空间上,用传统的分类器去分类;2)用稀疏系数所表示出来的样本属性进行分类。
在用于图像分类的字典学习算法中,字典和编码系数的设计从中起着关键作用[3]。基于稀疏表示的分类算法[4],将整个训练样本作为字典,利用测试样本在字典上的重构误差分类。在字典中的每个原子都是一个样本,由于样本数量的限制,字典原子中有相同或相似的,还有一些则不包含在内造成分类错误。而Aharon M等提出的KSVD算法[5]学习的字典具有自适应性,能够更好对信号进行稀疏表示。虽然,使用重构误差作为损失函数,可以用于图像分类,但是还有许多因素没有考虑到。Yang等[6]提出Fisher字典学习在自适应字典基础上,考虑到相同的样本之间的类内散度较小,类间散度大,在目标函数上加入了识别系数项,提高分类能力。Jiang等[7]提出的LC-KVD算法,在KSVD算法[5]基础上加入了标签约束项。在文献[8]中,由于分别学习特征影射矩阵和字典,会影响特征影射矩阵的判别信息,提出了同时学习投影矩阵和字典,为了能够提取更多的判别信息,加入图正则项。构建近邻图,近邻且同类相似度为1,近邻但不同类相似度为-1,其他为0。在文献[9]中图正则化中的相似度矩阵定义为两近邻样本的相似度为两样本之间的欧氏距离,不近邻样本之间的相似度为0。使用不同的相似矩阵,分类效果也不同。另一方面,由于字典学习[3-9]大多是使用编码系数的0或1范数作正则项,在训练和测试阶段效率较低,运行时间长。2014年在NIPS上Gu等[10]提出了字典对学习,联合学习一个综合字典和分析字典,用分析字典去分析编码,由于综合字典的重构效果比较好,使用综合字典去重构图像。它不仅减少了在训练和测试阶段的时间复杂度,也提高了模型的分类能力。但是,字典对学习模型没有考虑图像的几何近邻拓扑关系。为了提高模型的分类能力,基于同类样本的系数之间的距离小,不同类系数之间的距离大的思想,提出了基于图正则化字典对学习(GDPL)算法。
在最近的综合研究[11]中,用十倍交叉验证的方法评估轻度认知功能障碍(MCI)到阿尔兹海默症(AD)的预测,只有4种方法的实验结果比随机分类的结果好,因此,提出新的方法提高MCIAD的预测是十分必要的。在图像分类中,并不是所有的特征都与识别分类有关,其中有一些是无关特征,将这些特征用于分类会出现过拟合现象。由于稀疏表示中表示系数具有稀疏性,将本文提出的图正则化字典对学习算法用于轻度认知功能障碍预测。
1 相关工作
1.1 字典学习
设 X =[X1···Xk···XK]∈ Rp×n是一个 K 类 p 维的训练样本,第 k 类样本 Xk=[x1···xi···xnk],Xk∈ Rp×nk,k=1,2,···,K 是第 k类训练 nk样本,n=n1+n2+···+nk+···+nK。字典学习模型的分类任务是通过利用训练数据的类标签信息学习一个有效的数据表示模型去进行分类。在使用字典学习算法的图像分类研究中,如何设计对特征提取有效的字典和编码系数是决定算法性能的关键因素[1]。对于字典学习算法设计考虑的有三方面:1)稀疏表示残差(重构误差)小,使样本在稀疏表示时尽可能的接近原始样本;2)对表示系数约束,使表示系数稀疏;3)考虑能够更好提取更多的判别信息的判别项。用于图像分类的判别字典学习模型[6-7,12-13]可通常以表示为:

式中: λ 、η 是常量(平衡因子);Y 是样本 X 的标签向量;D 是学习的综合字典;A 是 X 在综合字典 D上的编码系数矩阵。在训练模型时,数据保真项||X-DA|是为了保证字典 D 的表示能力,使训练数据的重构误差最小,重构出来的图像尽可能的接近原始样本。正则项用于约束编码系数的稀疏性,其通常应用范数表示为:

式中: || ·||p是编码系数 A 正则项的常用形式(p <2),使编码系数 A 在重建误差满足要求的情况下尽可能地稀疏。 f (D,A,Y) 是字典学习用于分类的判别函数项,保证 D 和 A 的判别能力。
1.2 字典对学习
在1.1中描述的判别式字典学习模型是学习一个共享字典,对系数的约束都是使用 l0或者是l1范数对编码系数进行系数正则化约束,使训练模型在训练阶段和测试阶段效率降低。Gu等[10]为了提高模型在训练阶段和测试阶段的效率和整体的识别能力,提出了联合学习一个综合字典和分析字典的字典对学习(DPL),不使用 l0或者是l1范数对编码系数进行稀疏正则化,而是找到一个分析字典 P,使训练样本X 在分析字典 P上线性投影得出编码系数 A,即 A = PX 保持稀疏性,重建误差与判别约束保证下使训练样本 X 的稀疏表示变的更加有效且解决了out-of-sample问题。字典对模型描述表示如下:
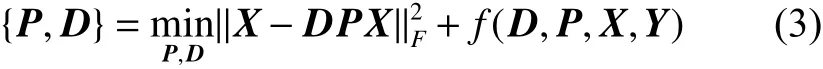
式中: f (D,P,X,Y) 表示判别函数。D 和 P 是一个字典对:分析字典 P 用于编码 X,综合字典 D 用于重构 X。学习一个结构综合字典D=[D1···Dk···DK] 和 结构分析字典 P =[P1···Pk···PK],其中 { Dk,Pk} 是第 k 类的子字典对。对于分析字典P 使其满足第 i (i ≠k)类样本在第 k 类的子字典Pk上的投影系数为空,即 PkXi≈ 0,∀k≠ i,也就是编码系数矩阵 PX 接近块正交。对于合成字典D,使其子字典 Dk与投影编码矩阵 PkXk能够很好的重构样本 Xk,要求字典对有最小的重构误差:

因此,DPL模型的目标函数可以写为:
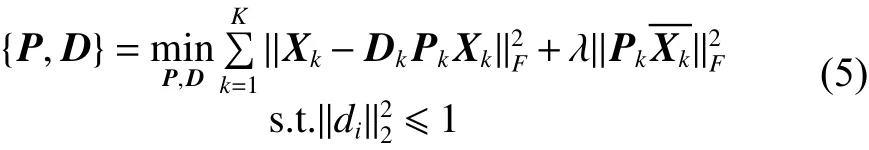
式中: Xk是 Xk在整个训练集中的补集;λ 是一个标准常量; di是合成字典的第 i 个原子。
2 图正则化字典对学习
字典对学习只考虑图像的重构误差和不同类的分析字典和样本的投影系数尽可能的小,没有考虑原始样本的近邻几何结构,引入图正则化,使低维表示能够保留原始样本的近邻结构。
2.1 图正则化字典对学习
在流形学习中,假设两个高维空间的相邻的两点,在其对应的低维空间仍保持其在高维空间的几何近邻拓扑关系。为了使样本之间可区分,并同时保持原始图像的几何近邻结构,且使同类样本在分析字典 P 上的投影系数之间距离小,不同类之间的距离大。对编码系数的图正则项约束表示为:
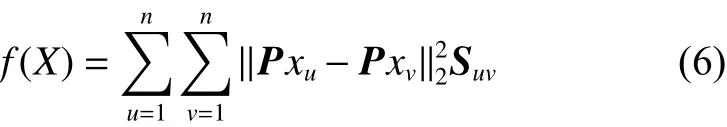
式中:n 是所有样本总数;u 和 v 是第 u (v) 训练样本; P xu和 P xv是训练样本 xu和 xv在分析字典 P的投影,即分析编码系数。
在大多数图正则项,都是对数据集构建近邻图[9],用图的边的权值表示数据之间的关联度。但是本文利用样本总数去平衡类内和类间的距离,已经证明能够提高在字典上的编码系数的判别能力[12],因此,本文中相似度矩阵 S 是依据xu和 xv的标签保证相应系数之间的相似性[12]。用训练集构建近邻图,用标签信息判读样本是否近邻。如果 xu和 xv标签相同,则为近邻,相似度为Suv=1/nl(xu); 如果 xu和 xv标签不同,则不近邻,相似度为 Suv=-1/(n-nl(xu))。 相似度矩阵 S 的第 u 行v列的元素为:
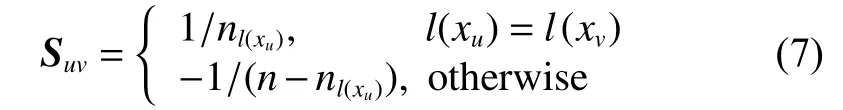
式 中 : l (xu) 和 l ( xv) 表 示 的 是 样 本 xu和 xv的 类 标签; nl(xu)是训练样本中标签为 l ( xu) 的样本总数。矩阵 L =C∑-S , 其中 C =diag{c1,c2,···,cn} 是对角矩阵,且 cv=v=1Suv。
在DPL算法的基础上,构建近邻图保持原始图像间的近邻关系,由此提出了图正则化字典对学习(GDPL)算法。GDPL算法的目标函数可写为:

式中: λ 和 β 是平衡因子,在公式(9)中的第1项是重构误差项,重构误差项尽可能的小,使重构出来的图像与原图像尽可能的接近。 X¯k是 Xk在整个训练样本上的补集,第2项是第 K 类以外的训练样本,在第 K 类的分析字典上的编码系数尽可能小,使编码系数尽可能的稀疏。第3项是图正则项,使图像在字典上的编码系数仍旧保持原始图像的近邻关系。
引入变量编码系数 A, 使 A =PX ,目标函数可以写为下面式子:
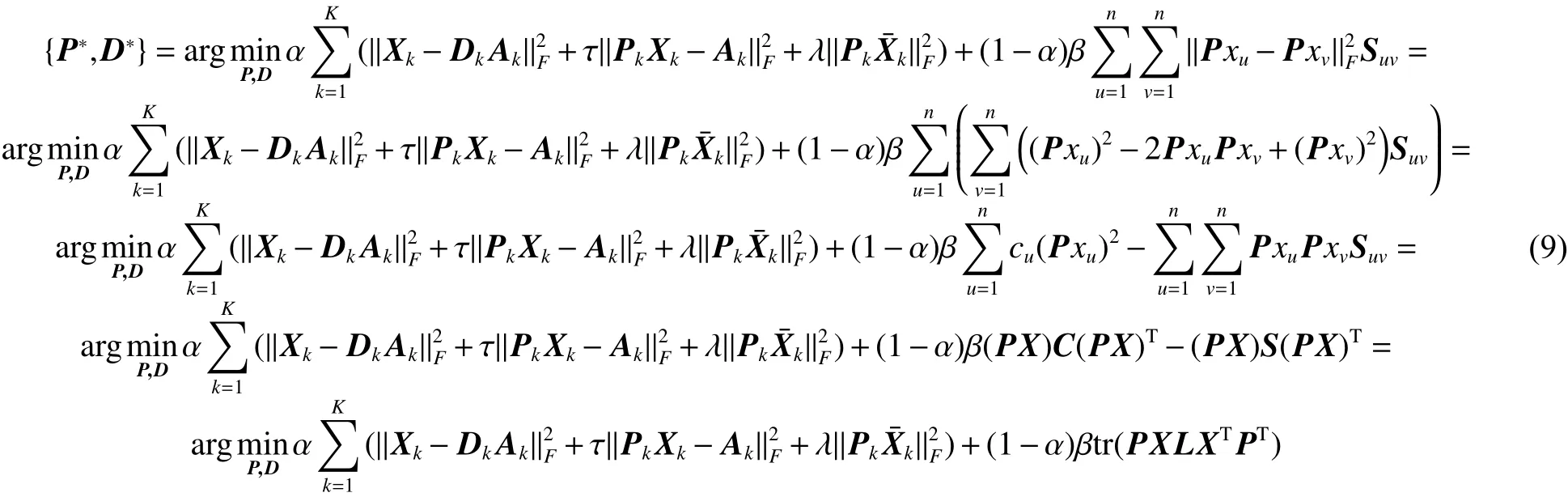
式 中 : t r(·) 表 示 矩 阵 的 迹 。 矩 阵 L =C-S,C=diag{c1,c2,···,cn}该对角矩阵的对角元素是 S 的行(列)的元素之和。
2.2 图正则化字典对学习
在流形学习中,假设两个高维空间的相邻的两随机初始化分析字典 P 和综合字典 D,之后,迭代更新编码系数 A 和 { P ,D}。
1) 固定综合字典 Dk和分析字典 Pk,更新编码系数 Ak, 由于含有 Ak的式子前面有相同的系数 α,在计算的过程中可以消去,所以可以利用式(10)解出 Ak:
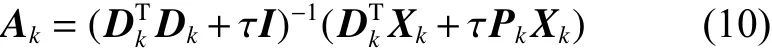
2) 固定编码系数 Ak, 更新综合字典 Dk和分析字典 Pk。
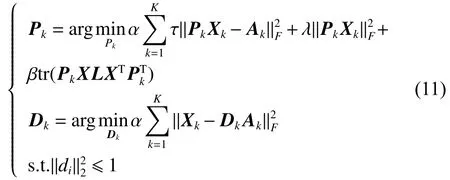
对 Pk封闭求解,即
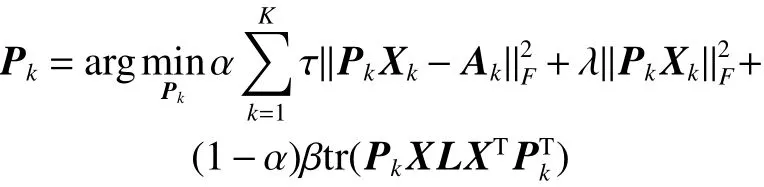
对 Pk求导,得
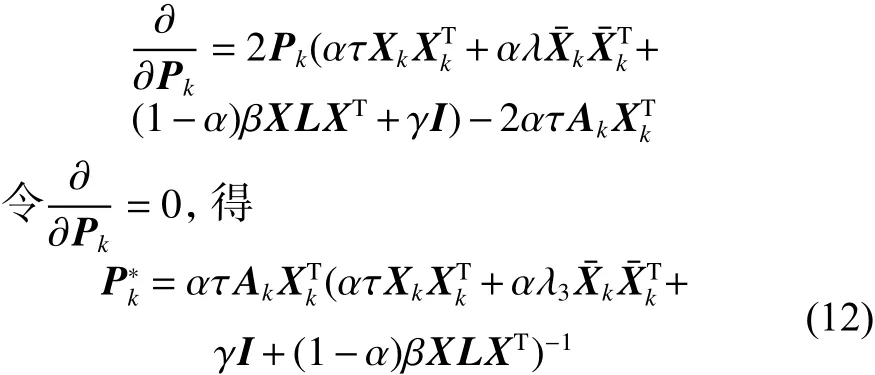
式中: γ =10e-4,I 是单位矩阵,在公式加入(一个极小的常数)是为了保证逆运算有解。
在公式(13)中用交替方向乘子算法(AMMD)[8]对 D 优化求解。具体的求解过程如下所示:
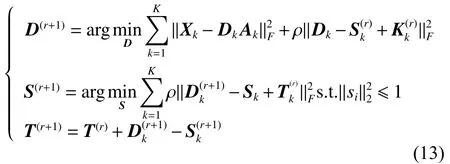
对 Dk求导:
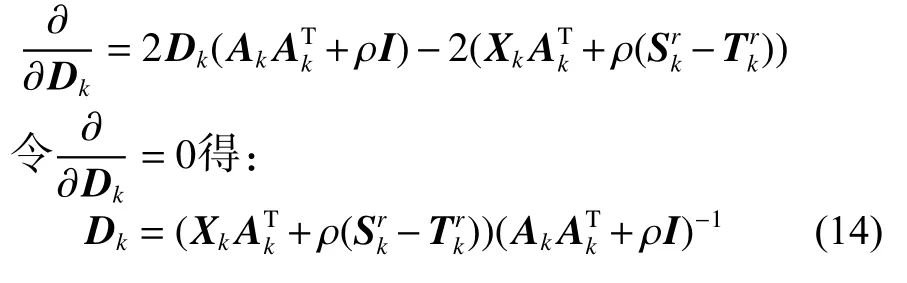
对 Sk求导:
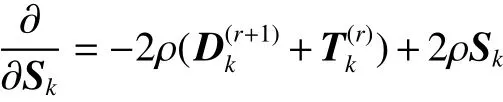

2.3 图正则化字典对学习训练算法
由于算法中的图正则项,需要先用训练样本构建近邻图,计算出相似矩阵 S 和拉普拉斯矩阵L。利用目标函数优化过程进行迭代更新,学习字典对 { P ,D}。图正则化字典对学习算法的训练过程在算法1中详细描述。
算法1 GDPL训练算法
输入训练样本 X =[X1X2···XK],训练样本标签信息 Y =[Y1Y2···Yk], 参数 α ,τ,λ,β,子字典原子数 m。最大迭代次数max。
1) 利用样本标签信息构建近邻图。根据样本标签信息判断样本是否为近邻点。若 xu和 xv标签相同,则为近邻点,相似度 Suv=1/nl(xu); 若 xu和xv标签不相同,则不是近邻点,相似度 Suv=-1/(n∑-nl(xu))。对 角 矩 阵 C =diag{c1,c2,···,cn}, 其 中 cv=v=1Suv,拉普拉斯矩阵 L =C-S。
2) 初始化:随机生成综合字典 D0和分析字典 P0, 迭代次数 t = 0。
3)Fori=1:K
While 未收敛(具体的在收敛性分析中)执行下面步骤:
1) 固定字典 Dk和 Pk, 由目标函数中含有Ak的式子求解得出式(10),根据式(10),更新编码系数 Ak;
2) 固定编码系数 Ak, 由式(11)中 Dk使用ADMM算法得出式(14)更新字典 Dk;在ADMM算法中 Dk、 Sk、 Tk根据式(14)、(15)、(13)中最后一个式子更新直到达到ADMM算法的收敛条件停止。
3) 固定编码系数 Ak, 由式(11)中 Pk解出式(12),根据式(12)更新字典 Pk;
End While
End For
输出综合字典 D,分析字典 P。
2.4 分类方法
在图像分类中,并不是所有的特征都与识别分类有关,其中有一些是无关特征,将这些特征用于分类会出现过拟合现象。另一方面,稀疏表示是在超完备字典中用尽可能少的原子去表示原来的图像信号,其中的表示系数具有稀疏性。用表示系数作为特征去分类,可以减少无关特征的影响,提高模型的判别能力。用ADNI1数据集进行验证,具体的实验结果在第4部分中,使用编码系数用分类器分类效果比直接使用分类器[14]的效果好。
在分类模型中,输入训练样本 X 使用算法1训练出来的综合字典 D 和分析字典 P,由 A,计算出训练集在分析字典上的投影系数即稀疏表示中的编码系数 Atrain=PX , 由测试样本 Xtest和分析字典 P,可以计算出测试集的编码系数 Atest=PXtest。将编码系数作为特征,用分类器对测试样本进行分类。
3 算法分析
本节主要对提出的图正则化字典对算法(GDPL)进行时间复杂度分析和收敛性分析,该算法通过联合学习一个综合字典和分析字典,将样本在分析字典上的投影作为表示系数,减小了算法的时间复杂度。
3.1 时间复杂度分析
在GDPL算法中主要是计算训练阶段的时间复杂度。在训练阶段 Ak和 { Pk,Dk} 交替更新,每次更新过程相同,在此以一次更新为例。固定{Pk,Dk} 由 式(10)更新 Ak, Ak更新的时间复杂度是一个逆矩阵和一个矩阵相乘的时间复杂度即m×m 的矩阵, {Dk+τI} 的 时间复杂度为 O (m3),在 m ×nk的矩阵 { τ PkXk+Xk} 中 , PkXk的时间复杂度为 O (mpnk),Xk的时间复杂度也是 O (mpnk),所以矩阵 { τ PkXk+Xk} 的 时间复杂度为 O (mpnk)。矩阵 (Dk+τI)-1和 ( τ PkXk+Xk) 相乘的时间复杂度为 O (m2nk), 整个更新 Ak的时间复杂度为O(m3+mpnk+m2nk)。 固定 Ak, 更新 { Pk,Dk}。 Pk由式(12)进行更新,在式(14)中 p ×p 的矩阵(τXk+λ3+γI+βXLXT)的 时 间 复 杂 度 为O(p2nk+p2(n-nk)+pn2+p2n),但是在迭代过程中该矩阵值不变,在初始化阶段提前计算出来,在迭代过程中不需要重复计算,因此不影响更新 Pk的时间复杂度。只需计算(τXk+λ3+γI+βXLXT)逆矩阵的时间复杂度为 O (p3)。 Ak的时间复杂度为 O (mnp),两矩阵相乘的时间复杂度为O(mp2), 更新 Pk的时间复杂度为 O (mnkp+p3+mp2)。使用ADMM更新 Dk,将ADMM算法中迭代更新次数记为H,ADDM算法中,主要计算在式(13)中 D 更新过程的时间复杂度。 Dk根据式(14)更新的,式(14)中 Xk、 Ak、 ( Ak+ρI) 的逆矩阵、 Xk(Akk+ρI)-1的时间复杂度分别为O(pnkm)、 O (m2nk)、 O (m3)、 O (pm2), 更新 Dk整个过程的时间复杂度为 O (H(pmnk+m2nk+m3+pm2))。
3.2 收敛性分析
在目标函数式(1)中对于 { ( D,P),(A)} 的迭代更新是一个双凸问题。在优化求解的过程中,固定A对 D 和 P 求解是一个凸问题;固定 D和 P对 A求解也是一个凸问题,因此目标函数是一个双凸问题。根据文献[10]的补充材料,收敛时目标函数的能量值达到一个局部最小值。为了避免在更新过程中达到收敛条件,不同类之间单个样本的能量不在同一个数量级上,所以,本文的收敛条件是单个样本的能量到达某一局部最小。目标函数中各项的曲线如图1所示。图1只是以GDPL算法过程中使用其中一类迭代过程中的目标函数值画出曲线为例。算法1中while后面的收敛条件为前后两次迭代的整个目标函数值之差小于0,单个样本的重构误差的绝对值小于1,保证目标函数值在每次迭代过程中逐渐减小,最大迭代次数为50。
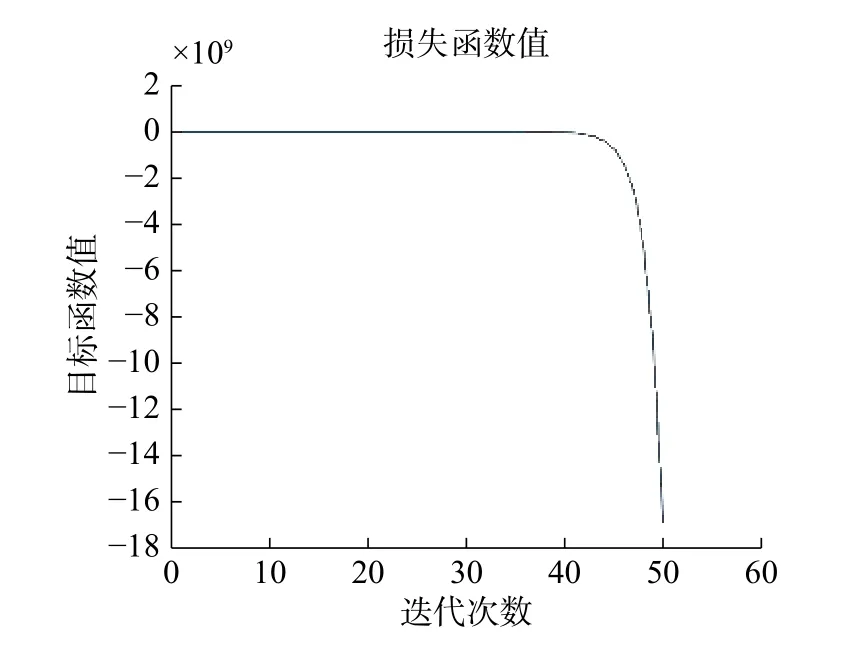
图1 目标函数值随迭代次数变化Fig.1 The value of the objective function varies with the number of iterations
图1 中单个样本的整个目标函数值在开始到40次的变化趋势是平行趋于0,之后变成一个比较大的负值,由于相似度矩阵不是半正定矩阵,由此使图正则项的值变成负值,并引起其他项的变化。并且由于图像的损失函数一般都不会小于0,所以,从图1可以看出算法在2~40次之间是局部收敛的。所以,有的实验在第2次迭代就达到最优值。
4 实验结果与分析
为了验证图正则化字典对学习算法在图像分类中的性能,本文在ADNI1数据集上进行验证。ADNI由国际老年研究所、生物医学成像和生物工程研究所、美国食品和药物管理局、民营医药企业和非营利组织在2003年启动,资金为60万美元。ADNI的主要目标是测试是否能通过组合MRI、PET、其他生物标志物,以及临床和神经心理学评估来测定MCI和早期AD的进展。
在ADNI1[14]中,根据MCI患者在36个月之后的状态,将36个月之后仍表现出MCI的状态,则记为SMCI;36个月后表现为AD的病况,记为PMCI;没有36个月之后的信息的患者,记为uMCI。实验中只利用表1中显示的有标签的164个PMCI患者信息和100个SMCI患者信息,对MCI进展进行识别,提前预测AD。
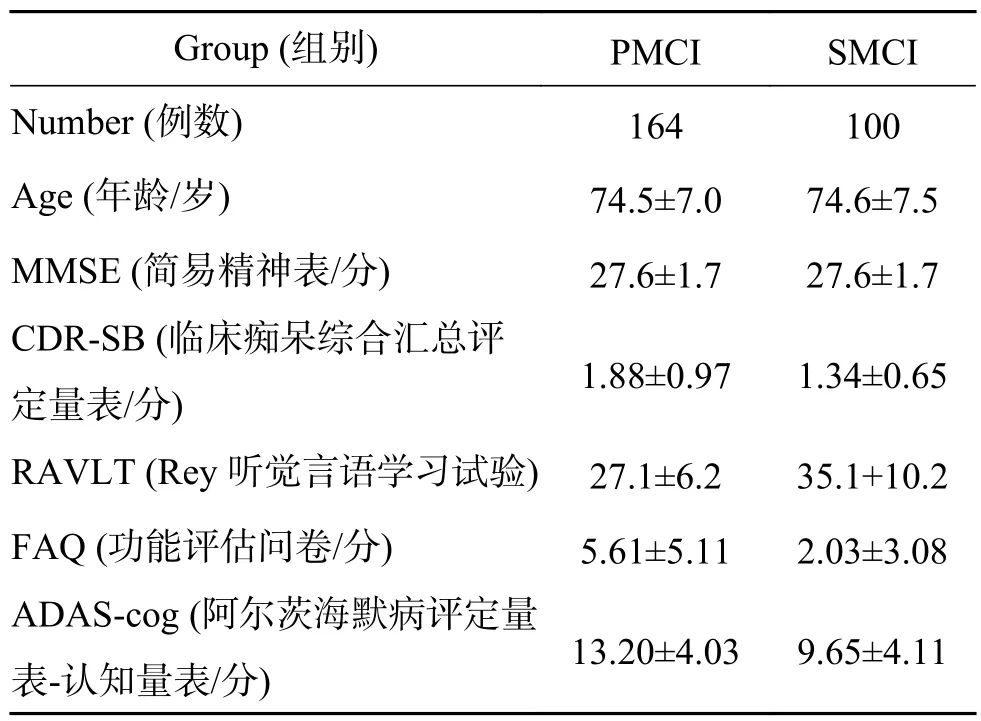
表1 PMCI和SMCI相关信息Table1 PMCI and SMCI related information
所有实验是使用中全局生物标志[14]和表1中显示的 Age、MMSE、CDR-SB、RAVLT、FAQ、ADAS-cog信息的结合生物标志作为特征表示样本,使用算法1中学习的字典对 { D ,P},计算出样本的编码系数作为特征。在实验中选择较常用的分类器 SVM[11,14-17]、LDA[17]、KNN 作为比较方法。为了避免实验结果的随机性,运行100次10倍交叉验证取最终的平均准确率(ACC)和平均ROC曲线下面的面积(AUC),对于分类器的性能进行评价。
为了验证提出的基于图正则化的字典对学习方法的实验效果比其他的实验效果好,直接使用结合生物标志用SVM、LDA、KNN分类器分类,使用DPL方法训练出来的字典对上的稀疏系数作为特征用分类器(SVM、LDA、KNN)做出的实验效果,和使用GDPL方法训练出来的字典对上的稀疏系数作为特征用SVM、LDA、KNN分类的实验结果。最终的实验结果是取100次10倍交叉验证结果的平均值,对于具体实验数据的精确度取小数点后3位。
在使用字典对算法训练字典的过程中,算法中参数设置是选择一个参数变化,固定其他参数,进行遍历。选取3次十倍交叉验证平均准确率最好。经过遍历参数,算法中的参数设置如表2、3所示。
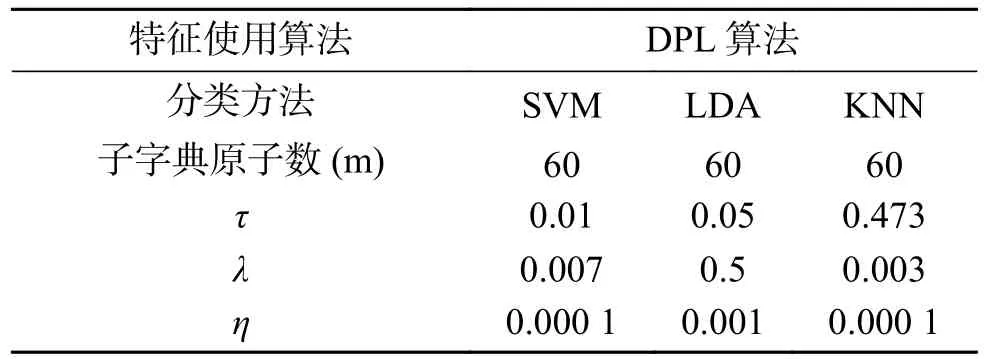
表2 使用DPL稀疏系数作为特征的参数设置Table2 Parameter setting using DPL algorithm

表3 使用GDPL稀疏系数作为特征的参数设置Table3 Parameter setting of the GDPL algorithm
1) 为了验证在基于图正则化的字典对(GDPL)算法学习的字典对上的系数作为特征效果比直接用结合生物标志作为特征的实验效果好。本文使用准确率(ACC)和ROC曲线下的面积(AUC)作为评价标准。
从图2可以看出直接用结合生物标志作为特征的准确率与使用字典对学习方法的准确率相差较大,使用SVM和GDPL+SVM的实验结果相差了2个百分点,K近邻(KNN)和GDPL+KNN相差了6个百分点。用GDPL方法的准确率比DPL方法的准确率高。从图2整体上看使用GDPL方法的实验效果比DPL方法和直接使用综合特征的效果好。图3从算法AUC性能评价,从中可以看出使用GDPL的稀疏系数作为特征的实验中,除了SVM外,其他的方法都比使用DPL的效果好,其中KNN的AUC最高到达92.1%。从图2、3中整体的结果可以看出GDPL方法的实验结果比DPL的实验结果好。
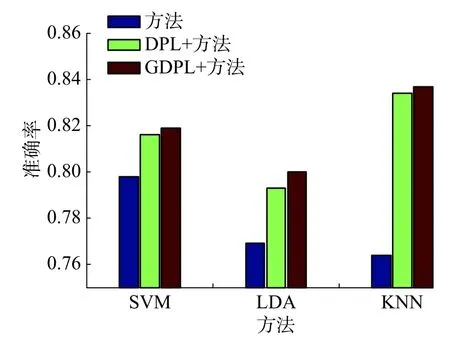
图2 不同方法上的准确率 (ACC)Fig.2 The accuracy of different methods
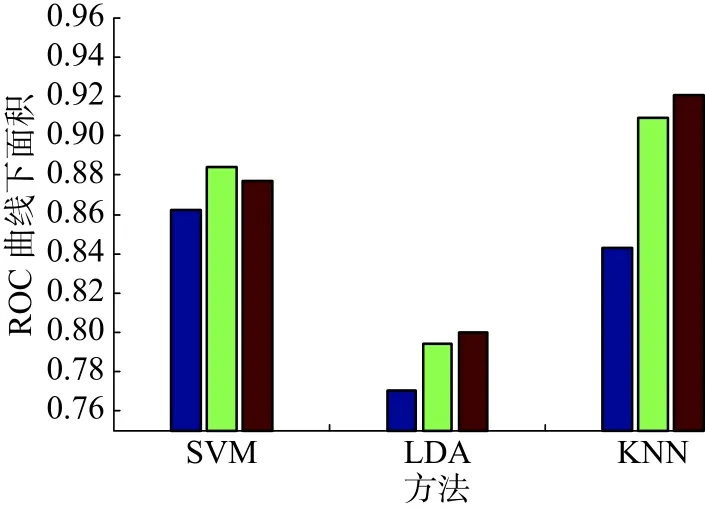
图3 不同方法上的ROC曲线下的面积(AUC)Fig.3 Area under ROC curve in different methods
2) 将结合生物标志直接作为特征用SVM、LDA、KNN分类,使用DPL方法的稀疏系数作为特征的分类方法记为DPL+SVM、DPL+LDA、DPL+KNN,和使用GDPL方法的稀疏系数作为特征的分类方法记为GDPL+SVM、GDPL+LDA、GDPL+KNN,所用实验结果都是记录使用100次十倍交叉验证的结果(平均值)画出的盒形图。使用准确率(ACC)、ROC曲线下面的面积(AUC)对于分类器的性能进行评估,具体实验结果在图4、5中显示。
从图4中整体上可以看出使用GDPL算法的稀疏系数作为特征的平均准确率比DPL算法的稍微好一点,比直接使用结合生物标志作为特征的平均准确率高,GDPL+KNN算法的平均准确率最高达到了83.7%。图5显示ROC曲线下的面积(AUC)最好的是GDPL+KNN算法,AUC达到92.1%。在图4、5,100次实验结果中GDPL+KNN算法结果相对集中稳定。整体上看使用GDPL方法训练出来的字典对上的稀疏系数作为特征的实验结果比直接使用结合生物标志特征的结果好,GDPL+KNN实验结果最好,并且结果比较集中稳定,每次实验的结果的变化不大。
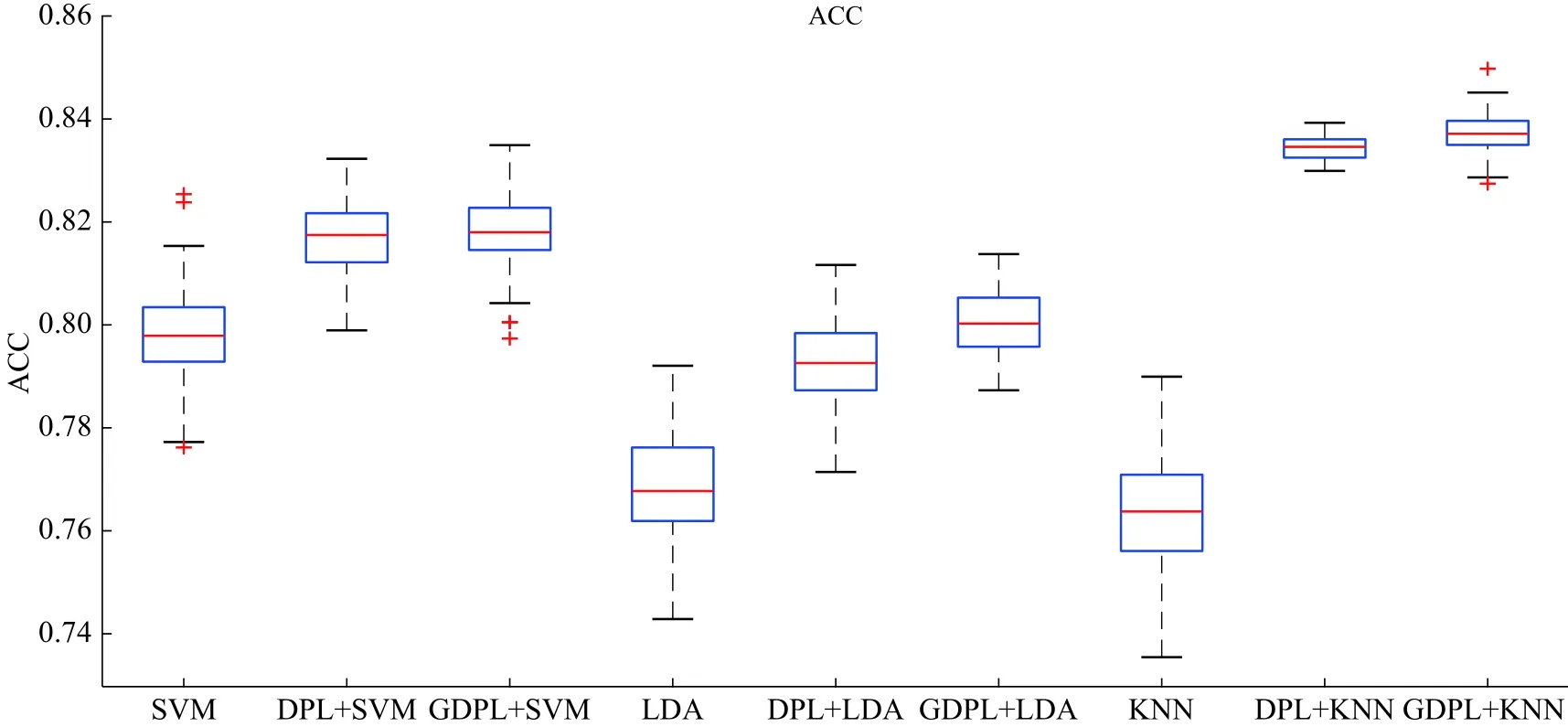
图4 使用100次十倍交叉验证的ACC画出的箱型图Fig.4 Box plot for the ACC of 100 times 10-fold cross-validation
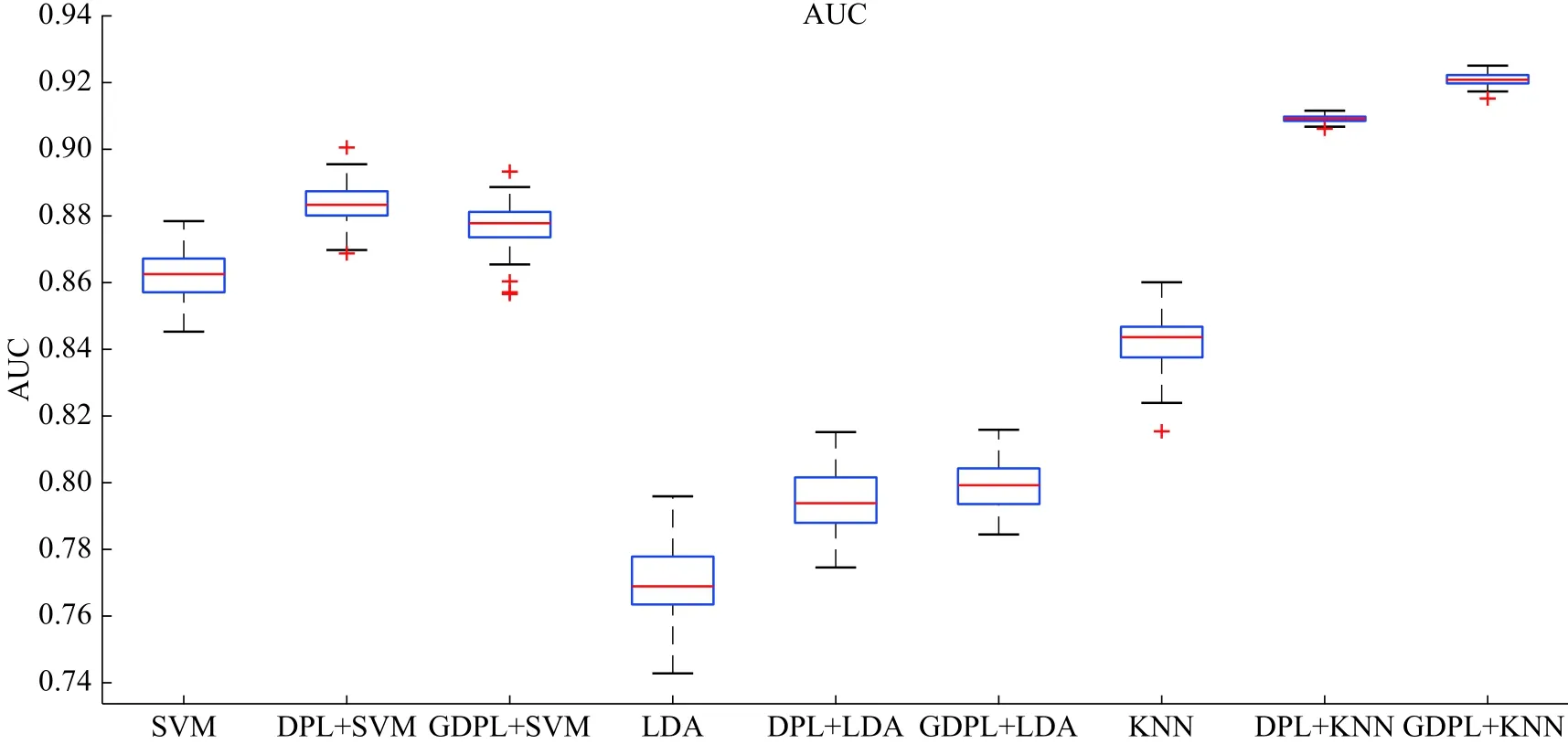
图5 使用100次10倍交叉验证的AUC画出的箱型图Fig.5 Box plot for the AUC of 100 times 10-fold cross-validation
5 结束语
本文实验结果表明在字典对学习算法中加入图正则项,可以提高字典对模型的识别能力,能够更好地对图像进行分类。另一方面,使用在字典对上的稀疏系数作为特征对轻度认知功能障碍预测可以取得更好的效果,并且在GDPL算法上的稀疏系数作为特征的实验结果比DPL上的实验结果好。随着科技的发展,图像资源越来越丰富,用户想在大量的图像中找到需要的图像信息比较困难。在现实生活中带标签的数据相对于不带标签的数据少很多,获得带标签的图像比较困难。并且训练样本较少不能获得足够的特征去学习字典,下一步可以将无标签的样本用于实验中,学习一个更完备的字典,提高模型的识别能力。可以进行半监督字典对学习,提高模型的判别能力。
