基于改进PSO和FCM的模糊辨识
2019-04-10刘楠刘福才孟爱文
刘楠,刘福才,孟爱文
(燕山大学 电气工程学院,河北 秦皇岛 066004)
系统的建模与辨识一直是人们研究的重点与难点,它的好坏直接影响着控制系统的性能。尤其对于现在控制系统越来越复杂,要求也越来越高,控制系统呈现出多变量、强耦合、非线性等特点,这就使得传统的方法很难对这些系统进行建模。模糊理论的产生为这些系统提供了新方法,现在已经应用于自动控制、电力系统和预测控制等领域。T-S模型是在模糊辨识方面应用较广的模型,它是由Takagi和Sugeno于1985年提出的一种模糊模型[1]。国内外学者对此方法进行了深入研究,主要研究的内容有前提参数辨识、结论参数辨识、规则库优化、输入变量选择等。随着人工智能技术的不断发展,智能算法也越来越多地应用到了T-S模型的优化上。如文献[2]采用模糊聚类优化模型的前提结构,并应用遗传算法(genetic algorithm, GA)对前提参数进行了优化,但是计算时间长,而且精度不是很高。文献[3]采用菌群优化算法(bacterial foraging optimization algorithm, BFO)优化T-S模型前提参数,虽然辨识精度有提高,但是收敛速度还是太慢,耗时太长。文献[4]采用粒子群算法(particle swarm optimization algorithm, PSO)和最小二乘算法提出一种模糊自适应函数逼近器,由于标准粒子群算法本身的局限性而使辨识精度不高。
随着模糊聚类理论的发展和成熟,已经成功应用到了很多的领域。目前,学者们已经提出了很多模糊聚类算法,比较典型的有基于相似关系[5]和模糊关系[6]的方法、基于目标函数的方法[7]、基于模糊图论的最大支撑树方法[8]等。其中研究最多的是基于目标函数的模糊聚类方法。该方法主要思想就是求解一个带约束的非线性规划问题,得到数据集的模糊划分和聚类结果。模糊C均值(fuzzy C-means, FCM)聚类算法是基于目标函数聚类算法的一种,它的应用也最为广泛。FCM算法是由K均值聚类算法加入模糊因子改进而来,内平方误差和(within-groups sum of squared error, WGSS)是聚类目标函数的常见形式,1973年,Dunn扩展了内平方误差和函数,提出了类内加权平均误差和函数作为目标函数[9]。此后一年,Bezdek提出在目标函数中引入了新的参数 m ,把原先的类内加权平均误差和函数改进为目标函数的无限簇,从而形成了广泛应用的FCM聚类算法[10]。从此,FCM聚类算法蓬勃发展,已经成为聚类算法中研究的热点。
本文提出一种改进的粒子群算法和模糊C均值聚类算法相结合的模糊辨识新方法。采用模糊C均值聚类算法对聚类中心进行初步优化,然后通过改进粒子群算法的全局搜索能力优化聚类中心。这样既保持了模糊C均值聚类算法的优点,又达到了对模型的全局优化,显著的提高了算法的辨识精度和效率。
1 PSO算法基本原理
Kennedy等于1995年提出了PSO算法[11],它具有进化计算和群智能的优点,是一种启发式全局优化算法。与其他进化算法类似,PSO算法也是通过个体间的协作与竞争,实现复杂问题的全局优化。
PSO算法可以描述为:设粒子在 D 维空间搜索,粒子个数为 N 。 第 k个粒子所处的位置为向量Xk=(xk1,xk2,···,xkD), 粒 子 的 飞 行 速 度 为Vk=(vk1,vk2,···,vkD),每一个粒子都是所优化问题的一个解,粒子通过不断的改变自己的位置和速度找到新解。第 k个粒子到目前为止搜索到的最优解Pk=(pk1,pk2,···,pkD),整个群体经历过的最优位置为Pg=(pg1,pg2,···,pgD)。每个粒子的速度和位置按照式(1)、式(2)进行变化:
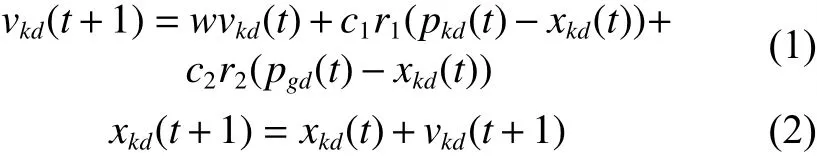
式中: r1,r2为 [0, 1]之间的随机数; c1,c2为正常数,称作加速因子;w为 惯性权重。每个粒子第 d维的速度和位置的变化范围为 [- vd,max,vd,max]和 [- xd,max,xd,max]。粒子的最大速度 vd,max太大,可能会使得粒子飞过最好解; vd,max太小,会使得搜索速度太慢,而且容易陷入局部最优解。惯性权重 w 可以很好地控制粒子的搜索范围。 w 较大时,粒子进行较大范围的搜索; w 较小时,粒子进行小范围的挖掘。
2 搜索模式动态调整的PSO算法
改进的PSO算法(SMPSO)分为两种搜索模式:局部搜索模式和全局搜索模式。局部搜索模式就如同自然界中大部分动物觅食一样,它在搜索到的疑似最优位置周边都会进行更加细致地搜索,然后根据视觉、味觉、听觉等因素更加准确地判断全局最优解的位置。这样既避免了种群过早的收敛,陷入局部最优解,而且通过在疑似最优位置四周的搜索,更容易找到全局最优位置。在全局搜索模式时,粒子之间会协同合作,共享最优位置信息,使整个种群向着全局最优位置逼近,以更短的时间寻找到最终目标。由于每代粒子都具有“自我”学习提高和向“他人”学习的优点,从而能使种群在较少的迭代次数内找到最优解。
SMPSO算法首先要选择粒子的数目 N ,每个粒子都有自己的位置、适应度和处于局部搜索模式或者全局搜索模式的标识值。粒子的位置根据求解的需要由 D 维向量表示,适应度可由目标函数的适当变形得到,所处模式的标识值可以用数字0和1表示。粒子的两种模式分别代表着算法的不同进程。在程序的运行中,一部分粒子执行局部搜索模式,其余的粒子执行全局搜索模式。它们各自的数量由搜索模式动态调整参数 S M控制, S M表示处于全局搜索模式的粒子所占种群的比例,按照式(3)计算得到,其中 S Mmax和 S Mmin分别为 S M 的 最大值和最小值, D T为当前的迭代的次数, M axDT 是 最大的迭代次数。随着 D T的增加, S M 从 S Mmin线 性地增加到 S Mmax,这样可以使得粒子群在开始时搜索能力比较强,而到后期随着种群的最优适应度越来越好,增大 S M,有利于粒子群聚集到更好的位置,进行更细致的搜索。
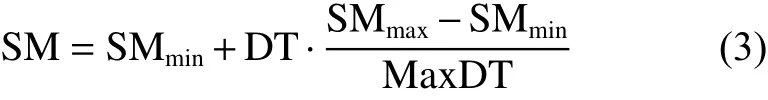
SMPSO算法整体进程描述如下:
1) 选择粒子群个体数为 N ;
2) 随机初始化粒子的位置为 D 维向量,按照SM随机分配粒子进入局部搜索模式和全局搜索模式;
3) 根据适应度函数计算每个粒子的适应度值,选择适应度值最好的粒子为当前的最优解;
4) 根据粒子所处模式的标识值,判断粒子处于哪种搜索模式。如果粒子处于局部搜索模式,应用局部搜索模式的程序;如果粒子处于全局搜索模式,应用全局搜索模式的程序。具体步骤详见 2.1和 2.2;
5) 按照 S M 重新分配粒子进入局部搜索模式和全局搜索模式;
6) 如果程序满足了终止条件,则终止程序;否则返回3)继续执行。
2.1 局部搜索模式
在此模式下,主要有两个基本的要素:局部搜索次数(S N),表示每个处于局部搜索模式的粒子迭代一次搜索的次数。粒子将按照之后描述的规则,从中选择一个位置;局部搜索范围(S R),表示粒子局部搜索最大能抵达的范围。局部搜索模式步骤如下:
1) 复制 S N份当前粒子的位置;
2) 对于每个粒子的候选位置,按照式(4)更新粒子的候选位置。
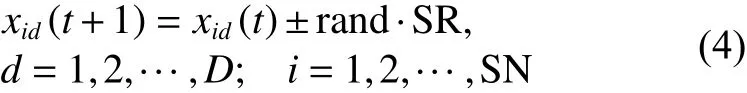
式中: xid表 示粒子的第i个 候选位置在第 d维的位置, r and表示位于0~1之间的随机数;
3) 计算所有候选位置的适应度(F S);
4) 计算所有候选位置和它本身被选择的可能性。如果所有的 F S都相同,将所有候选位置的可选择性设置为1;否则按照式(5)计算候选位置的可选择性:
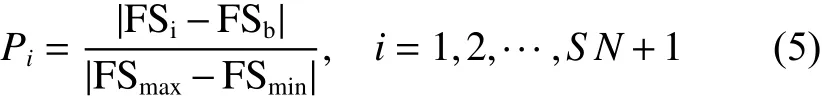
式中: Pi表 示候选位置的可选择性, F Si表示候选位置的适应度值, F Smax和 F Smin表示候选位置中最大适应度值和最小适应度值。如果求解目的是要找到最大适应度值,则 F Sb=FSmin, 否则 F Sb=FSmax;
5) 根据候选位置和它本身的可选择性 Pi,运用轮盘赌方法选择粒子的下一个位置。每个候选位置和本身被选中的概率 Pi为
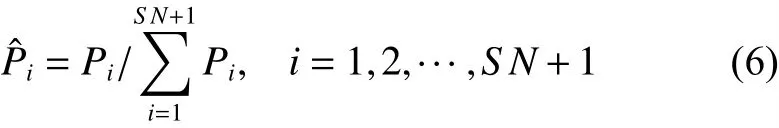
在局部搜索模式,采用了遗传算法常用的轮盘赌选择法,正是借鉴了“物竞天择,适者生存”的生物进化理论,并且还保留了物种的多样性,利用概率选择的方法,选择优胜的个体,淘汰劣质个体。
2.2 全局搜索模式
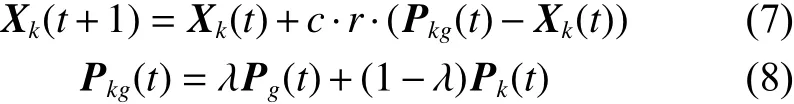
全局搜索模式对标准PSO进行简化处理,提高算法运行速度。粒子群按照式(7)、式(8)更新粒子的位置。式 中 : Xk表 示第 k 个 粒子 的 位 置; Pkg表 示 第 k个 粒子的最佳搜寻位置; Pg表示粒子群经历的最好位置; Pk表 示第 k 个 粒子经历的最好位置;λ是0和1之间的一个常数;r是一个位于0和1之间的随机数;c是一个正常数,称作加速因子。
从式(7)和式(8)可以看出本文方法与标准粒子群算法的不同之处如下:
1) 本文方法省去了粒子的速度,由于本文加入了局部搜索模式,使得粒子在两种模式之间切换,粒子的历史速度对于粒子的影响并不是很大。只要控制好参数 S M 和 S R,粒群体将不容易早熟,陷入局部最优解。同时,省去速度参数,也避免了对粒子速度的限制,进一步减少了算法的运行时间。
2) 种群的每个粒子对局部最优解 Pk和全局最优解 Pg的位置进行判断和权衡,找出最佳搜寻位置 Pkg,随后对此最佳位置进行跟踪。从式(8)可以 看 出 最 佳 搜 寻 位 置 Pkg在 Pg和 Pk的 连 线 上 ,λ 越接近1, Pkg离 全局最优解 Pg的 距离越近;λ越接近0, Pkg离 局部最优解 Pk越近。
2.3 算法参数分析
本文算法不同于标准PSO算法的参数主要有 S N、 λ、 S Mmax、 S Mmin和 S R。对于不同的优化问题参数选择不同,本文按照优化时间最短和优化结果最优原则,通过大量的仿真实验,总结了参数的选取方法:
1) 搜寻个数 S N选取的越大,耗时越多,但是相应的优化精度越高,一般选取3~5之间。
2) λ是控制最佳搜寻位置的参数,调节整体和局部的关系。针对参数 λ 的选择,本文采用了黄金分割点的位置 λ =0.618或 者 λ =0.382。黄金分割已经在众多领域取得了成功的应用,例如在数学上具有广泛应用价值的优选法,在股市上的应用,在战术布阵中的应用等。黄金分割被认为是建筑和艺术中最理想的比例,达到了局部与整体的辩证统一。
3) S M表示处于全局搜索模式的粒子所占种群的比例。 S M越大,全局搜索模式的粒子越多,算法收敛到最优解的速度越快,但是容易早熟,陷入局部最优解; S M越小,局部搜索模式的粒子越多,算法找到最优解的速度太慢,耗时太多,所以一般情况下 S Mmax为 1, S Mmin为0.5。
4) 局部搜索范围 S R越大,越有利于算法摆脱局部最优解,加快算法找到全局最优解,但是局部搜索能力比较弱; S R越小,局部搜索能力比较强,但是容易陷入局部最优解。根据具体问题的取值范围合理的选择 S R的大小。
3 基于SMPSO和FCM的建模方法
3.1 T-S模糊模型
在1985年,Takagi等[1]提出了T-S模糊模型,第i条规则的形式为
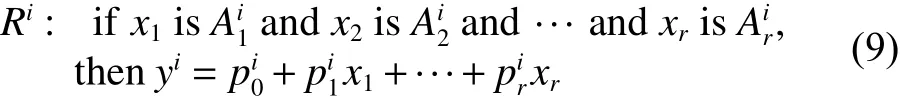
式 中 : i =1,2,···,c ; j =1,2,···,r; xj是 第 j 个 输 入 ;是一个模糊集合;yi是 第i条 规则的输出;是结论参数。
那么由各规则输出 yi(i=1,2,···,c)的加权平均可求得系统的总输出 y为
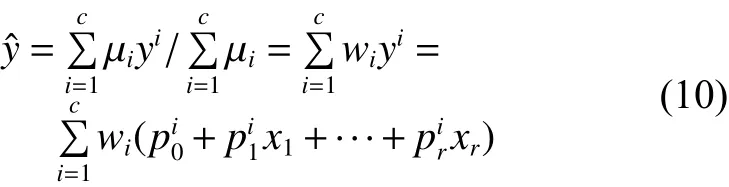
如果T-S模糊模型具有统一的前件结构,参照文献[12]的定义,T-S模糊模型的另一种表示方法如下:
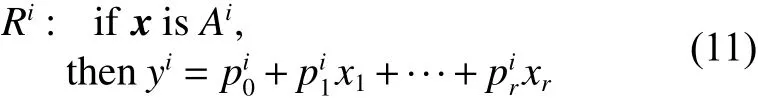
式中: x =(x1,x2,···,xr)为输入变量向量,这样可以使得模糊规则数等于输入变量的模糊集合数,明显的减小了算法的复杂度。
代入 N 对输入数据可得矩阵等式:

由式(12)可得模型输出 Y 是 参数向量 P 的线性组合,采用递推最小二乘法求取参数 P,算法如下:
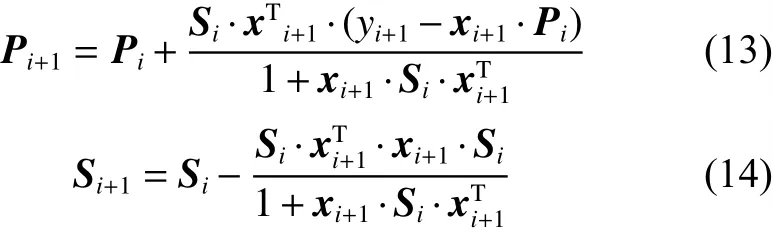
3.2 模糊C均值聚类算法
模糊C均值聚类算法是一种自动对样本点进行分类的方法,是当前应用较为广泛的一种模糊聚类算法。聚类的目标函数 Jm(U,V)如式(15),聚类的最终目的是求得目标函数 Jm(U,V)的极小值,具体实现步骤如下:
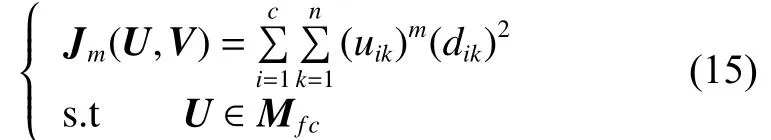
1) 设定聚类中心数 c (2≤c≤n),n为样本个数,给聚类中心 V0赋初值,设定模糊权重指数 m 、最大迭代次数 Cmax和 停 止阈值 ε;
2) 根据聚类中心 Vr, 用式(16)计算第 r +1次迭代的隶属度矩阵 Ur+1, 对于 ∀ i,k , 如果,则有:
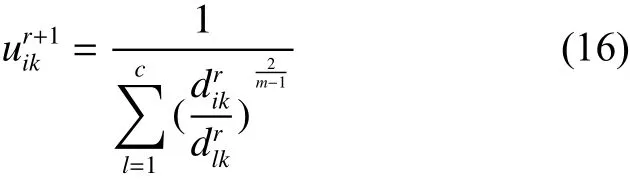
3) 根据隶属度矩阵 Ur+1, 用式(17)计算第r+1次迭代的聚类中心 Vr+1:
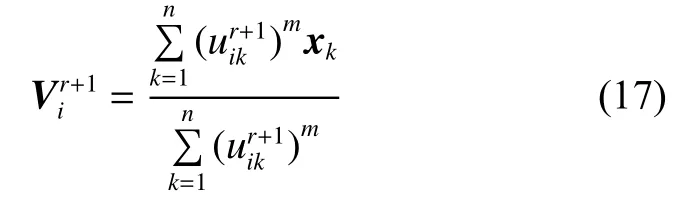
4) 根据给定的阈值 ε,如果 Vr+1-Vr< ε或者迭代次数大于 Cmax,则停止迭代,最后一次的迭代结果就是隶属度矩阵 U 和聚类中心 V ,否则令r=r+1,转到 2)。
由以上算法步骤可以看出,整个迭代过程就是不断优化聚类中心和隶属度矩阵的过程。Bezdek等对算法进行了完善,并给出了收敛性说明[13-15]:模糊C均值聚类算法可以从任意给定的初始点开始收敛到目标函数 Jm(U,V)的局部极小点。
3.3 基于SMPSO和FCM的模糊辨识
模糊C均值聚类算法是一种局部搜索算法,容易陷入局部最优解。为了解决这一问题,本文首先采用模糊C均值聚类算法对聚类中心进行初步优化,然后利用改进粒子群算法的全局搜索能力优化聚类中心。这样既保持了模糊C均值聚类算法的优点,又达到了对模型的全局优化,显著的提高了算法的辨识精度和效率。具体算法步骤如下:
1) 由辨识的目标得到输入输出数据。
2) 采用模糊C均值聚类算法对聚类中心 V 进行初步优化,算法步骤详见3.2。
3) 选择输入变量个数为 r,即聚类中心的维数为 r,那么粒子的位置表示为
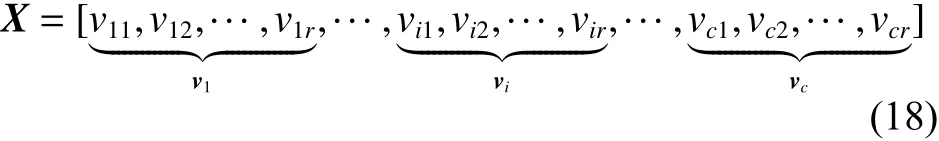
式中: X 为 r ×c维向量,即粒子群优化参数编码。
4) 根据聚类中心 Vλ, 用式(19)计算第 λ +1次迭代的隶属度矩阵 Uλ+1, 对于 ∀ i,k , 如果,则有:

5) 采用递推最小二乘法求取结论参数 P ,用结论参数 P 和输入数据集计算模糊模型的输出。SMPSO算法的适应度函数如式(20),根据适应度函数算出每个个体的适应度值,由式(3)~(8)更新个体位置。
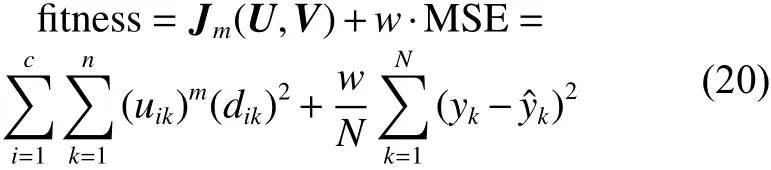
式中: w 为建模均方误差 M SE的比例因子。因为,一般建模均方误差都很小,这样对适应度函数就起不到明显的作用,所以加入比例因子 w ,可以调节 Jm(U,V)和 M SE对适应度函数的影响,从而达到更好的寻优效果。
6) 如果程序满足了终止条件,则终止程序;否则返回4)继续执行。
4 仿真研究
4.1 Box-Jenkins煤气炉数据辨识
著名的Box等煤气炉数据[16]已经被许多学者用作检验辨识方法的标准试验数据。输入量u(k)是 流向煤气炉的流量,输出量 y( k)是出口二氧化碳的浓度。
这组数据有296对输入输出测量值,是一个SISO动态系统。本文选择 r =2,c=6,输入变量选择 y (k-1)和 u (k-3), 输出量为 y( k)。改进的粒子群算法的参数选择如表1所示。辨识模型需要优化的聚类中心的参数为 r c=12个;结论参数为(r+1)c=18个。仿真结果如图1和图2所示,与其他方法的对比结果如表2所示。

表1 SMPSO的参数设置Table1 Parameters setting of SMPSO

图1 SMPSO模糊模型辨识结果Fig.1 Identification result of fuzzy model with SMPSO
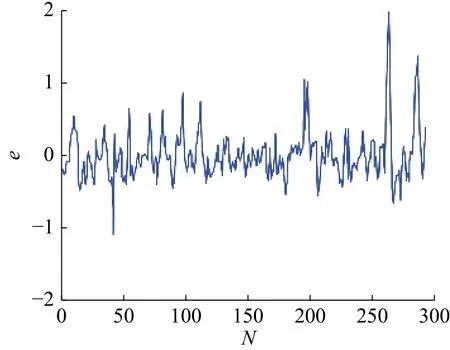
图2 SMPSO模糊模型辨识误差Fig.2 Identification error of fuzzy model with SMPSO
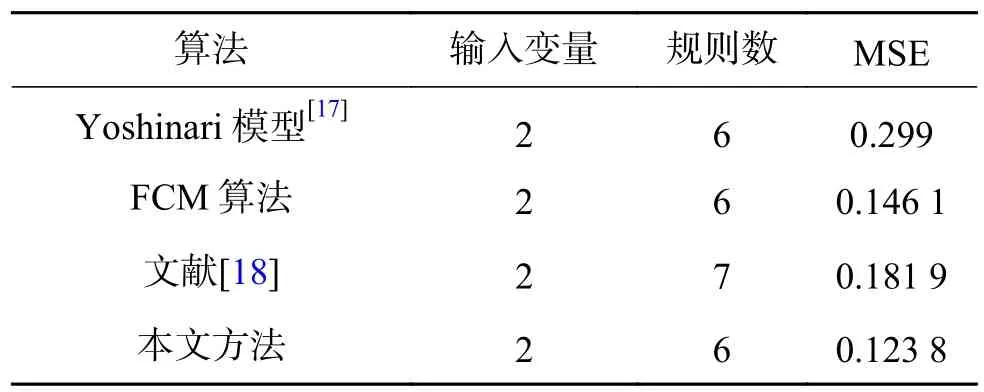
表2 不同辨识方法下的MSETable2 MSE of different identification methods
由仿真结果可以看出,本文方法所用模糊规则数少,但是辨识精度高,是一种有效的辨识方法。
4.2 非线性动态系统
本节以式(25)的非线性动态系统为仿真对象,由 u (k)=sin(2kπ/100)产生输入数据。选择r=3,c=6 , 输入变量选择 u (k)、 y (k)和 y (k-1),输出量为 y (k+1), y (1)=0,训练数据500组。改进的粒子群算法的参数选择如表4所示。辨识模型需要优化的聚类中心的参数为 r c=18个;结论参数为(r+1)c=24个。仿真结果如图3和图4所示,与其他方法的对比结果如表3所示。
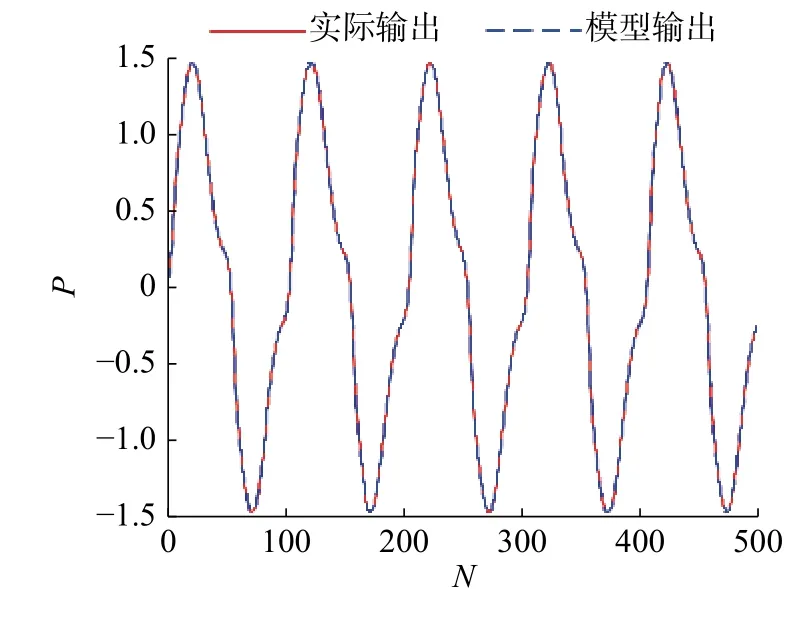
图3 SMPSO模糊模型辨识结果Fig.3 Identification result of fuzzy model with SMPSO
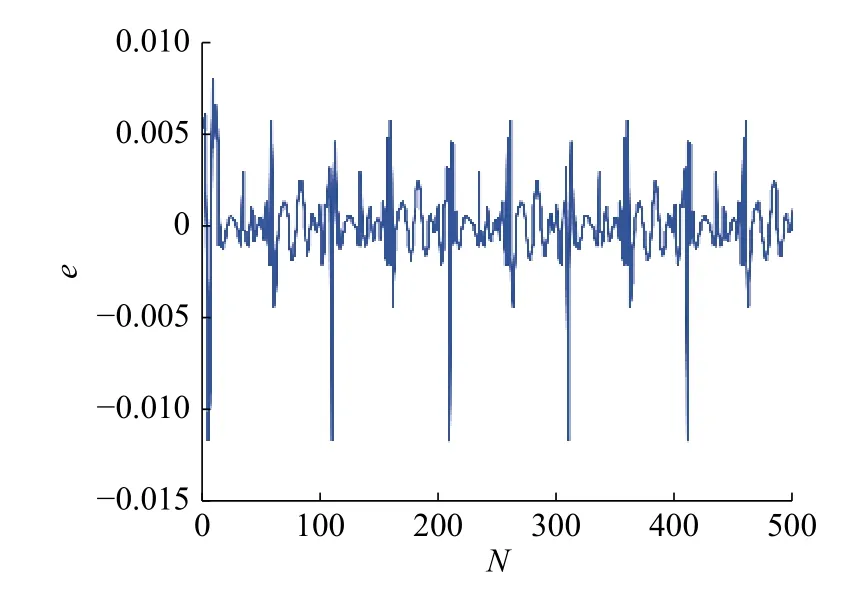
图4 SMPSO模糊模型辨识误差Fig.4 Identification error of fuzzy model with SMPSO
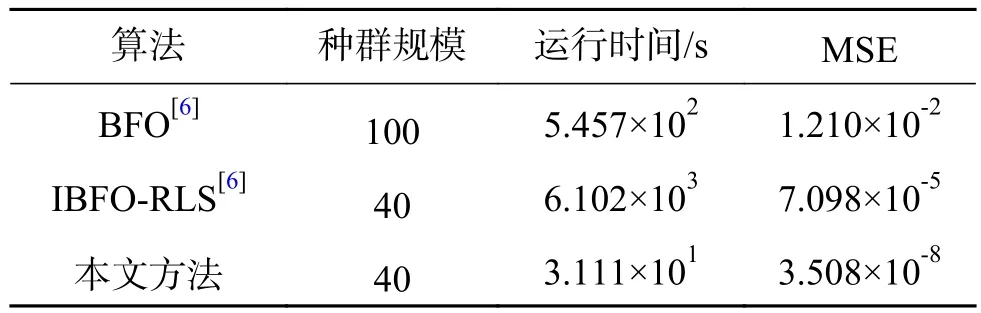
表3 不同辨识方法的仿真结果Table3 Simulation results of different identification methods
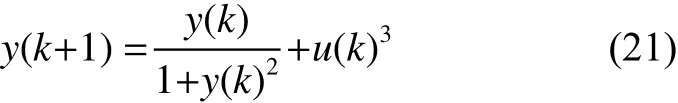
从仿真结果可以看出,本文方法不仅提高了辨识精度,而且大幅度的缩短了程序运行时间,验证了本文方法有很高的效率。
5 结束语
本文将改进的粒子群算法和模糊C均值聚类算法相结合,提出一种新的模糊辨识方法。首先采用模糊C均值聚类算法对聚类中心进行初步优化。然后对粒子群算法进行了改进,提出一种搜索模式动态调整的PSO算法,显著提高了PSO算法处理复杂问题的全局优化能力。并且将改进的PSO算法运用到聚类中心的优化中,有效的解决了FCM算法容易陷入局部最优的问题,提高了模糊辨识的精度和效率。最后通过建模仿真,表明了本文方法的有效性和优越性。
