机器学习方法在消费金融反欺诈模型中的应用进展
2019-04-02
(德勤管理咨询 北京 100738)
一、反欺诈技术是行业参与者的核心竞争能力
消费金融机构向个人提供信贷额度或资金。近年来,消费金融在全球范围内蓬勃发展。在我国,消费金融市场规模(不含房贷)已由2010年1月的6798亿元攀升至2018年10月84,537亿元,占境内贷款比重由1.7%上升至6.3%[1]。由于消费金融以线上业务为主,申请人与贷款人之间的信息不对称问题更为突出。加上客群下沉、业务准入门槛低等原因,欺诈成为妨碍行业发展的关键痛点。近年来,欺诈甚至呈现“团伙化、地域化、年轻化、专业化、产业化”趋势。某普惠金融机构称被其拒绝的客户中,一半以上存在欺诈的可能。反欺诈技术是消费金融机构的核心竞争能力。
一笔正常的金融交易,是客户本人以自己真实完整的身份信息及相关信息申请开立账户,由本人(或代理人)进行交易并愿意承担对应义务的行为。虽然具体欺诈形式多、且易变,但可将其简单概括为以下4种形式:1.欺诈者以虚假身份信息或通过虚拟技术(如机器人)申请账户开立。2.欺诈者盗取他人真实身份申请开立账户开立,这种欺诈形式在消费金融中占比较高。3.欺诈者本人以虚假个人信息、资产或财务信息等申请账户开立,例如隐瞒真实债务情况、提供虚假银行资金流水等。4.欺诈者以骗取资金为目的的恶意借贷。消费金融机构进行反欺诈,需要充分收集各类数据,利用经验与规则、借助于模型与技术,全面防堵上述各种欺诈行为。
二、数据驱动的反欺诈模型面临五大关键挑战
与其他机器学习问题相比,反欺诈模型的突出特点是其面临着五大关键挑战。
挑战一:非平衡样本(Class imbalance)[2]。数据中正样本(欺诈)的比例过低,有时不足1%,绝大多数样本属于负样本(非欺诈)。若不对非平衡样本采取针对性处理措施,建模中将不可避免地导致分类器偏好数据集中占多数的一类,甚至产生单边分类器,即使将全部样本判定为“正常”,未能成功识别任何欺诈,该分类器的准确率还是超过99%。这是数据驱动欺诈侦测模型构建中最主要问题之一。
挑战二:概念漂移(Concept drift)[3]。概念是一个模型要去预测的目标变量;概念漂移是指目标变量随着时间的推移发生改变。正常客户的行为习惯会随时间变化而改变,欺诈者也会不断变换欺诈方法和手段来躲避侦测,在反欺诈模型的动态数据流中表现为非独立同分布。概念漂移导致的直接后果,是将训练的模型应用于新数据时模型预测能力衰减很快,且很不稳定,泛化性能差,通俗说是“老办法难以解决新问题”。
挑战三:验证延迟(Verification latency)[3]。通常情况下,从业务准入到欺诈发生需要较长时间(观察期平均在半年以上)。在常规方法下,建模人员只能在欺诈实际发生后,才能将带标注的数据加载到训练数据集中重新训练模型。在这段被动等待期间,欺诈模式可能也发生变化。建模人员拟通过更新数据集,重新或增量训练模型的方法来解决概念漂移问题,其效果就大打折扣。
挑战四:代价敏感(Cost-sensitive)、错判损失易变(Variability in misclassification cost)[4]。反欺诈模型上线后,某笔业务被分类器错判后的代价可能是不一样的。具体到消费金融业务中,将正常客户判定为欺诈客户,错判损失是该笔业务的预期利息收益(通常低于本金的10%);而若将欺诈客户判定为正常客户,错判损失是该笔业务的本金,数倍于预期利息收益。并且,对于不同客户而言,可以申请到的贷款金额(本金)是不同的。
挑战五:模式匹配(Pattern matching)困难[4]。欺诈者往往通过各种手段努力地伪装成正常客户,其行为特征与正常客户的典型行为特征差异非常小。
三、基于多维数据的主动学习、实时反欺诈系统是行业领先的解决方案
基于多维数据的反欺诈系统可分为批量识别与实时扫描两类。前者指在交易发生后对全体交易进行扫描,批量识别欺诈;后者通过基于数据流挖掘(Data stream mining)[5]构建实时侦测系统[6-8],在线实时侦测欺诈行为。
(一)领先反欺诈系统的整体架构
当下行业领先的方案为实时扫描方案,具有场景化、事件驱动、多维度、专家经验与数据驱动相结合等多个特点。下图展示了一个典型的实时反欺诈模型架构(基于文献[3]、文献[9]的工作整理):
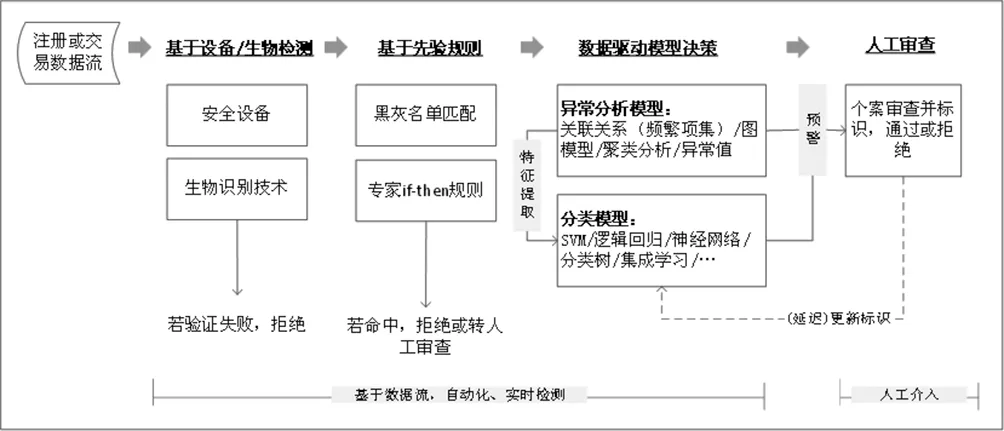
图1 反欺诈侦测模型整体架构示意图
上图所示的反欺诈侦测系统采用了概率递减的决策规则。客户的注册申请或交易数据,首先通过基于终端设备(UKey,Token等)/生物检测技术(人脸识别、虹膜识别等)的反欺诈侦测,然后进入黑名单匹配(犯罪人员名单、司法老赖名单、马甲库、黑中介、手机号码欺诈库、终端设备欺诈库等),专家if-then规则或组合规则(代理IP、IOS越狱/或Android root,安装虚拟机、多个消费贷APP等)筛查环节。这两个环节命中的客户存在较高的欺诈概率,其注册申请或交易会被系统直接拒绝。成功通过上述检测的数据会进一步流到机器学习模型中,基于多维数据进行异常分析、分类评估。在这个环节检出的客户存在一定的欺诈概率,系统不会直接拒绝其注册申请或交易,而是对该笔业务发出欺诈预警,提示进行线下个案审查。线下调查结束后,系统将更新标识后的数据添加到训练数据集,在设定的时间窗内对模型进行增量训练。虽然筛查规则多、且模型复杂,但反欺诈系统或服务的供应商称完成上述筛查处理耗时不到1分钟,甚至更短。
为了解决概念漂移和验证延迟问题,上述架构中可嵌入主动学习(Active learning)策略[7]以及增量学习(Incremental learning)策略[10]。在处理不带标识数据时,采用主动学习策略的学习器能主动选择包含信息量大的、未标注样本推荐给专家进行人工标注。一方面,仅将少量可疑交易提取交由线下专家审查,减少了人工标注量、缩短了欺诈观察周期,验证延迟的影响被减弱;另一方面,将与专家交互后的带标识信息(上图中的人工审查、打标识)更新到训练集中重新训练,可对分类器进行重新优化、调整,捕捉欺诈手法的新变化、新模式,提高模型的泛化性能。上述主动学习过程可表示为:AL=(C,L,U,Q,E)。其中,C是一个或者一组分类器;L是一组已标注的训练样本集;U是未标注的数据集;Q是查询函数,用于在未标注的样本中查询信息量大的样本;E是专家,对选择的未标注数据进行标注。主动学习的过程,是首先利用C训练L,得到一个训练好的分类器,然后Q选择U中的未标注数据给E进行标注,标注后再由C来进行训练,不断循环迭代直到达到预设的停止条件。
(二)反欺诈异常分析中采用的机器学习方法
可用于异常分析的数据包括:1.申请人提供的个人基本信息;2.移动端SDK采集技术获取的申请人设备信息及行为数据;3.导入外部数据库、或网络爬虫爬取的数据,如个人消费信息、社交网络信息、地理位置信息等。这些数据聚合后,不但可描述申请者个人基本情况,还可以描述申请者的各类行为(网购行为、社交行为、上网习惯),甚至个人使用设备的方式和习惯,例如使用设备的角度、按压屏幕力度等。
这些看似和欺诈侦测没有直接因果关系的大数据,在预测欺诈、群体欺诈上有一定的效果。例如有研究表明,可通过申请人打字速度和用鼠标浏览网页的方式等行为特征进行在线反欺诈侦测。因为相较于真实用户本人,欺诈者在填写陌生人生日和名字等个性化信息时较慢,在填写具有共性的信息时较快。再从群体欺诈上看,由于欺诈者往往团体作案,所以他们的行为呈现出高度一致性和聚集性。这与正常用户分散的、不统一的行为模式明显不同。在海量大数据的助力下,不断优化的机器学习方法正逐渐减轻模式匹配困难对欺诈侦测的影响。
异常分析可从横向、纵向两个方面进行。横向行为分析主要侧重于与客户相同的群体行为分析,根据群体共性来判断个体行为的偏差情况;而纵向历史行为分析主要侧重于客户自身行为比较,将客户在不同时期行为进行对比。具体的机器学习方法,包括关联分析/频繁项集挖掘[11]、聚类分析[12]、图异常检测[13]等。例如,在文献[12]中,李旭瑞提出一种基于流式聚类及增量隐马尔可夫模型的实时反欺诈模型,根据特定账户的历史交易模式判断当前交易是否可疑。作者利用CLIQUE算法对账户交易特征进行网格聚类,并结合隐马尔可夫(HMM)算法对账户交易行为建模,根据该模型进行实时欺诈侦测。
(三)反欺诈分类模型中采用的机器学习方法
分类模型是反欺诈系统的核心组成部分。异常分析通常以非监督学习为主,通过机器学习方法从多维数据中提炼正常、欺诈的多个模式,并通过数据可视化技术展示申请人与不同模式匹配情况,基于预设规则对客户或交易进行分类。例如,申请人若匹配上任何一个正常模式,则判定为正常;否则判定为欺诈。而分类模型通常采用监督学习方法,从多维数据中提取特征,利用带标记样本训练分类器。分类器能给出申请人欺诈的概率。
如上文所述,使用机器学习方法训练反欺诈分类器时,会受到非平衡样本、代价敏感等问题影响。近期文献[3,6-10,12,15]中构建分类器时,对上述问题都进行了特殊处理,如使用SMOTE抽样或通过正则化对误判进行惩罚。在分类器的选择上,逻辑回归、支持向量机、随机森林、神经网络、集成学习方法等被广泛使用,但目前尚无在任何数据集上表现都绝对占优的方法。在文献[4]中,Aderemi概述了近年来代表性研究的创新点、模型局限性和模型结果。在文献[8]中Hao Zhou在真实绑卡数据集上运用了多种机器学习分类算法,最终使用效果更好的XGBoost方法实现对移动设备支付中绑定银行卡环节的欺诈侦测。在文献[14]中,陈沁歆对比使用了逻辑回归、决策树、随机森林、Ada Boost集成学习方法。其研究表明,虽然作为一种传统方法,逻辑回归在关键性能指标上与集成学习方法非常接近。在文献[15]中,Jon Ander Gómez,et al.使用神经网络构建了一个反欺诈深度学习模型,该模型在真实数据集上预测欺诈的准确率,十分接近其他分类算法。
四、结论及思考
欺诈是消费金融企业面临的重大挑战。不断发展的机器学习方法应用到消费金融大数据中,使得欺诈风险得到一定的控制。但机器学习在反欺诈中的作用却不能过于高估,即使是越来越好机器学习方法,也只能无限接近问题解的上限;高质量、多维度的数据才能促进问题的最终解决。在保护隐私的前提下实现跨行业信息共享和合规合法使用,配合不断进步的机器学习方法,才能从行业整体层面上较好地解决欺诈问题。
【注释】
①文章不代表所在单位观点,文责自负。
