基于分布式学习自动机和用户反馈的网页排序算法研究
2019-04-01姜金川
王 冲 姜金川
(桂林电子科技大学计算机与信息安全学院 广西 桂林 541004)
0 引 言
寻找高质量的网页是搜索引擎的重要目的之一,页面的质量是根据用户的请求和偏好定义的。通常,每个查询请求都有数百万个相关页面,但是用户特别感兴趣的只是这些页面中的10到20个。网页根据其质量进行排序,目前关于网页排序的算法多种多样,主要分为以下3类:(1) 基于链接结构分析的排序算法;(2) 基于网页内容分析的排序算法;(3) 基于网络用户行为分析的优化排序算法。传统的基于Web内容分析的排序算法因其仅考虑网页之间的内容相关性而降低了排序效果。基于网络用户行为分析的优化排序算法尚未成熟,主要是在过滤虚假网页链接作弊、忽略用户兴趣等方面存在不足。例如:网页主题词之间的多次故意链接并没有得到有效过滤,用户点击量高、浏览时间长、用户转载回复次数多甚至下载量大等体现用户兴趣的网页并没有获得相应的影响因子及合理权值。PageRank算法基于网页间链接结构中隐含的信息进行网页排序,其成功运用于Google搜索引擎,证实了它所具有的实践应用价值和理论研究价值。
本文在综合分析与比较经典网页排序模型Page-Rank算法及其相关研究的基础上,一方面利用页面内容的相似性、页面之间的超链接和用户遍历的路径使用分布式学习自动机来确定网页之间的超链接权重,以缓解PageRank算法平分链接权重和主题漂移的问题;另一方面选取用户的转载、回复以及有效点击特征作为用户的行为特征,获得用户反馈因子,以缓解忽略用户兴趣问题。仿真环境通过MyEclipse、Heritrix和Lucene工具搭建,对比PageRank、WPR算法验证DUPR算法的排序质量,并以查准率和用户满意度评估网页排序效果。
1 相关算法及技术
1.1 PageRank算法
传统的PageRank算法是一种完全依赖网页链接结构的网页排序算法,它根据链接到该页面的网页链接数量和对网页的贡献值对其进行排序。该算法的主要思想为:网络中的网页通过超链接链接到其他网页,代表该网页投给链向网页一票,并将其网页的Page-Rank值均等分配给链向网页。显然,网页自身PR值越高,其对于链出网页的贡献值就越大,链出网页获得的PageRank值也就越高;页面的反向超链接数目越多,它的PR值也就越高;一个网页链入页面的链出数量越少,该页面获得的PR值也就越高。PageRank算法的计算公式如下:
(1)
式中:U代表当前要计算PR值的页面;d是阻尼系数,代表用户停留在当前网页的概率,介于0到1之间,通常为0.85[1];N代表网络中总网页数;Out(Vn)表示网页Vn的出链数量。
虽然PageRank算法已成功运用于Google中,但是它仍然存在以下不足:
(1) 权值平均分配。传统的PageRank算法链接权重均等分配,导致无法区分权威页面与普通页面。
(2) 忽略用户反馈。用户反馈包含大量有价值的信息,但PageRank算法却没有对其作出分析,导致忽略用户兴趣和网页欺诈等问题。
(3) 主题漂移问题。由于与查询词无关,导致查询到的网页虽然PR值高但与查询意图并不相关。
1.2 学习自动机
学习自动机[2-6]是在未知的随机环境下运行的自适应决策设备,自动学习的方法涉及从一组允许的动作中确定一个最佳的动作。一个自动机可以被认为是一个具有有限动作数量的抽象模型。在每个决策过程中,自动机从其有限的动作集中选择一个合适的动作,此动作适用于随机环境。随机环境对所选动作进行评估并给出自动机应用动作的等级,环境的随机响应(即动作等级)被自动机用于进一步的动作选择,通过继续这个过程,自动机选择最佳等级的动作。作用于未知的随机环境下并通过某种特定的方式改善其性能的自动机,称为学习自动机LA(Learning Automata)。学习自动机主要分为两类:一类是固定结构学习自动机;另一类是可变结构学习自动机,因可变结构学习自动机能够适应环境条件改变其状态,收敛速度更快,可达到自适应学习的目的。故本文使用可变结构学习自动机。
1.3 可变结构学习自动机
可变结构学习自动机[7]可以用一组四元组<α,β,P,T>表示,其中:α={α1,α2,…,αr}是学习自动机的r个动作集合;β={β1,β2,…,βr}是环境响应集合;P={p1,p2,…,pr}是包含r个概率的概率集,分别是在当前内部状态下执行每个动作的概率;T是强化算法,其功能是针对所执行的动作和所接收的响应来修改动作概率向量p。如果环境响应β仅有两个值,即β={0,1},这样的环境称为P模型。如果β有两个以上元素的有限输出集合,则这样的环境称为Q模型,如果环境的输出是在[0,1]区间内连续的随机值,该环境称为S模型。更新动作概率的学习算法是影响可变结构学习自动机性能的关键因素。设α是在步骤n中被选择的动作,作为概率分布p的一个样本实现。其更新动作概率向量p的递归方案定义如下:
(1) 奖励响应:
pi(n+1)=pi(n)+a[1-pi(n)] ∀jj≠ipj(n+1)=(1-a)pj(n)
(2)
(2) 惩罚响应:

(3)
在一些实际应用中,我们需要LA有更多的动作,一个具有变化动作数量的LA在任何时刻n都可以从一组活动动作V(n)中选择一个动作。对于所选动作,学习自动机首先计算其动作概率的和,然后计算向量p^(n)。自动机根据动作概率随机选择其活动动作,自动机将所选动作应用于环境并获得响应,对于响应的理想与否,更新向量p^(n)。然后进入第n+1次循环,最后学习自动机根据向量p^(n+1)更新动作概率向量p(n)。
1.4 分布式学习自动机
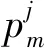
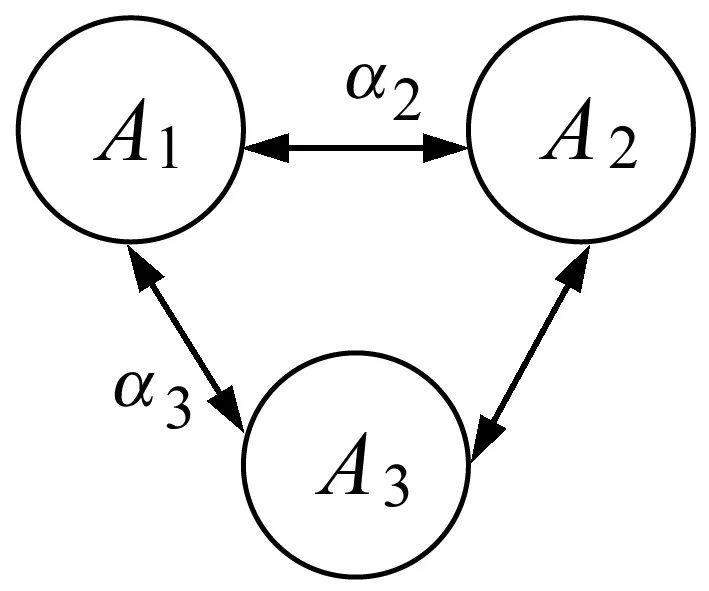
图1 分布式学习自动机
2 改进的PageRank算法
本文方法中,用户扮演DLA中当前自动机随机环境的角色。为了确定网络文档的结构,使用具有n个学习自动机的DLA,其表示n个网页,每个学习自动机都有n-1个动作。DLA中可用自动机的内部结构根据学习算法更新,对于每个学习自动机,任何时候只有一个动作子集被激活。
算法包括两大步骤:第一步使用已存储在日志文件中每个用户导航路径和页面之间的相似度以及网页链接基于分布式学习自动机计算网页超链接之间的权重,改善PageRank算法中的链接权重均等分配和主题漂移问题;第二步计算用户反馈因子,选取用户的转载、回复以及有效点击特征作为用户的行为特征,该特征反应了用户对搜索主题下的网页质量、内容等的认可度,缓解忽略用户兴趣和网页欺诈等问题,算法公式如下所示:
(4)
式中:N是系统中所有网页的数量;d是阻尼系数;DLA(V,U)是两个页面V和U之间的链接权重;R(U)是用户反馈因子。
2.1 基于分布式学习自动机确定网页超链接权重

(1) 用户遍历的路径;
(2) 页面之间存在链接;
(3) 页面之间的相似度。
所选动作的惩罚取决于2个因素:
(1) 用户移动路径中存在环路;
(2) 用户移动路径中的页面之间缺乏相似性。
学习自动机动作的奖励或惩罚是根据式(2)和式(3)的学习算法完成的。因此通过使用惩罚或奖励,自动机的动作概率将会被更新。用户从页面i移动到页面j,当页面i与j之间的相似度大于0.45时,相应的动作将得到奖励,奖励值根据页面相似度的大小和两页之间的链接确定。奖励系数公式如下:
a=sim(i,j)×ω+γ
(5)
式中:sim(i,j)是网页i和网页j之间的相似值;ω和γ为调整系数,如果网页i和网页j之间没有链接则为0。
本文中的页面相似性度量方法采用向量空间模型中的余弦相似度[10],如果文档i和文档j的文档向量是I=(i1,i2,…,in),J=(j1,j2,…,jn),则它们的相关程度计算公式如下:
(6)
如果用户在行进路径中存在环路则表示用户可能对遍历路径的不满意而导致用户返回已访问过的页面并开始再次浏览该页面。对于用户在循环中移动的动作将受到惩罚。惩罚步长与周期中的页面i和页面j的距离成比例,因此环路中的存在页面根据式(7)受到惩罚。
b=d(i,j)×β
(7)
式中:b是惩罚参数;d(i,j)是环路中的页面i和页面j之间的距离;β是惩罚参数的调节系数。如果用户移动路径中不存在环路,但两页间的余弦相似度小于0.45时,将发生第二种惩罚状态,根据式(8)更新相应动作概率。
b=β
(8)
2.2 用户反馈因子
为了增加PR值,某些网页存在人为的多次链接作弊,忽略了网页本身的质量。用户对网页的响应,例如回复、收藏、评论、转载等,反映了用户对搜索主题下的网页质量和内容的认可度。用户反馈因子选取用户的转载、回复以及有效点击特征作为用户的行为特征,用户反馈因子的公式如下:
(9)
式中:λ、∂、为特征系数,满足三者算术相加之和等于1。在实际应用中,λ、∂、三个特征系数应根据实际应用数据集的大小进行合理调整,本文中λ、∂、的取值为本实验数据集下对比结果的最优值。Vc(p→k)表示网页k获得的有效点击次数;Rs(p→k)表示用户对页面k的评论或回复的数量;Sh(p→k)表示用户对页面k的转载次数;S(p)表示网页的总数量。使用页面k的有效点击次数与总点击次数的比率,即有效点击率;网页k的回复或评论数量在总网页回复或评论数量中所占比例,即网页回复率;网页k的转载量占总转载量的比率,即网页转载率,衡量用户对网页的认可度。有效点击率、回复率、转载率越高,在一定程度上认为网页冲浪者对网页的认可度越高,即用户反馈因子R(k)值越大,用户对当前检索结果的满意度越高。
设置时间阈值,以用户在网页的停留时间来判断用户的此次点击是否作为有效点击从而将次数记入有效点击量中。如果浏览者通过单击超链接p→k浏览网页的时间大于tc,则意味着该页面可能会引起用户的浏览兴趣,则此次点击应作为有效点击计入有效点击量中;如果浏览时间小于tc,则意味着浏览者对该网页没有兴趣,即无效点击,不会计入有效点击量中。tc为普通正常人阅读所有页面内容以及思考和评论的时间,计算公式如下:
(10)
式中:cw、cp和cv分别代表网页正文中的文本数量、网页中的图片数量以及网页视频的数量。为了便于计算,这里将图片与视频依据其含义转化为描述的文字量,分别近似于50和100个字,正常人一般阅读速度为280字数/分钟[11],k是评论系数,取值一般介于1.2到1.5之间。
3 实验仿真
3.1 实验主要步骤
本文使用Java作为前端开发,编译环境使用My-Eclipse、Lucene 3.0 jar包和Heritrix等,对DUPR算法进行实验仿真,步骤如下:
(1) 用户数据收集。使用Heritrix网页爬虫工具从“巨细热点网站”抓取5 000个IP用户近一个月的访问信息。
(2) 网页数据收集。根据抓取的网页数据,生成网页链接结构图,获取链接关系,将其作为记录存入数据库中。
(3) 搭建MyEclipse实验平台,在实验项目中添加Lucene 3.0 jar包,添加中文分词器IKAnalyzer3.2.8 jar包,配置相关停用词,放在项目的根目录中。
(4) 在既定环境中,使用Java语言分别实现传统的PageRank算法、WPR算法和本文算法。在本文算法中,ω为0.01,γ为0.02,β为0.002,λ为0.3,∂为0.4,为0.3。
(5) 比较并分析查询得到的页面。
3.2 实验结果分析
为了显示本文算法的优越性,分别选取“旅游”、“Iphone”、“理财”、“手机”、“疫苗”作为五组关键词进行对比实验。首先确定用户反馈因子中λ、∂、的取值,随机给出多组数据组合(λ,∂,)进行实验。多次查询后观察到,当其中一个因子的取值大于或等于0.5时,用户满意度大大降低,因此在精度为0.1的情况下,λ,∂,∈(0.2,0.3,0.4)。由于λ、∂、满足三者算术相加之和等于1,也就是说(λ,∂,)可以采取六组实验数据。如表1第5和第7行所示,不同查询关键字的多个查询结果表明,当λ=0.3,∂=0.4,=0.3时,即用户反馈因子中的有效点击率、回复率、转载率的分配比重分别为0.3、0.4、0.3时用户满意度最高。查询“旅游”关键字的一些实验数据如表1所示。
表1 λ,∂,不同值对应的用户满意度
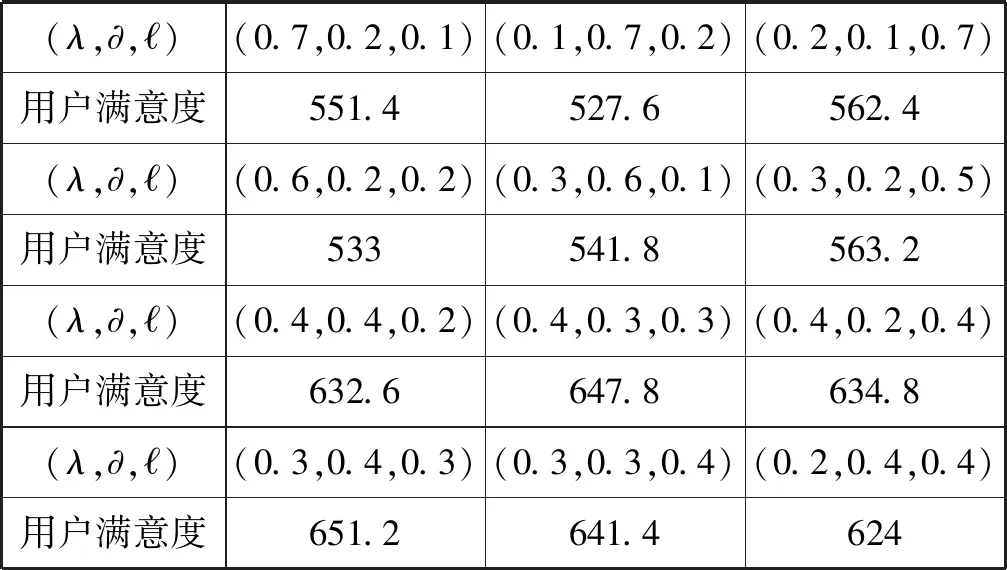
表1 λ,∂,不同值对应的用户满意度
(λ,,ℓ)(0.7,0.2,0.1)(0.1,0.7,0.2)(0.2,0.1,0.7)用户满意度551.4527.6562.4(λ,,ℓ)(0.6,0.2,0.2)(0.3,0.6,0.1)(0.3,0.2,0.5)用户满意度533541.8563.2(λ,,ℓ)(0.4,0.4,0.2)(0.4,0.3,0.3)(0.4,0.2,0.4)用户满意度632.6647.8634.8(λ,,ℓ)(0.3,0.4,0.3)(0.3,0.3,0.4)(0.2,0.4,0.4)用户满意度651.2641.4624
对比3种不同查询算法的结果并进行分析,以“旅游”为关键字的查询结果如图2-图4所示。为了节省篇幅,给出了查询结果排名前十的排序结果。

图2 PageRank基于“旅游”关键词查询结果

图3 WPR基于“旅游”关键词查询结果
图4 本文算法基于“旅游”关键词查询结果
图2是基于链接关系的传统的PageRank算法基于“旅游”关键词的网页排序结果,可以看出与主题无关但权威度高的网页占据了绝大部分。图3是改进了权值均等分配缺点的WPR算法基于“旅游”关键词的网页排序结果,可以看到WPR算法对于权威度很高的网页并没有做出很大的调整,权威度高但与用户查询意图无关的网页依然排在很靠前的位置。图4是本文算法,可以看出与主题无关的网页数量大大减少,证明了本文算法有力地削弱了主题偏移现象。此外,前十个网页中有9个和用户相关的网页,证明了本文算法更能筛选出用户感兴趣并且认可度高的页面,使其排名得到提升,而与用户查询意图完全无关的页面使其排名得到下沉。例如,图2和图3中排名第1的页面标题为“石材产业亮出你的文化牌”、排名第3的页面标题为“中国酒店运营国际标准”等均得到了大幅下降。
通过查准率进一步说明本文算法的排序质量。本文研究的查准率是指通过小规模模拟实验得到的统计结果,其语义含义是,在采样的样本数量中用户对查询结果满意的样本数量占总样本数量的百分比,是根据用户主观判断,确定查询结果与用户需求相关度的一个衡量标准。其中用户评价分为4个不同级别:不满意、较满意、满意和非常满意,标记结果为满意、较满意和非常满意的页面为和用户查询主题相关的页面。查准率的计算公式如下:

(11)
本实验为测试查询结果中的前30个网页,随机选取1 217名学生来测试查询信息,对查询关键词为“旅游”、“Iphone”、“理财”、“手机”、“疫苗”的查询结果进行查准率测评。测试结果如图5所示。

图5 三种算法查准率对比图
从图5实验结果看出,本文算法的查准率平均值为93%左右,而传统的PageRank算法的查准率平均值大约为63%,WPR算法的查准率平均值估计为73%。本文算法搜索结果的查准率明显高于传统PageRank算法和WPR算法,表明本文算法受到学习自动机和用户反馈因子的影响,搜索结果更加具有合理性,更符合用户的需求。
用户满意度评估[12]公式如下:
(12)
查询结果分为4个级别:非常满意、满意、较满意和不满意。Si是满意度系数,不同级别的满意度系数分别为:1.0,0.6,0.2,0.0。其中n是页面总数,在此实验中n是不同排序算法结果中的前30个页面,i是计数器。通过用户满意度评估公式与算法测试,比较结果如图6所示。
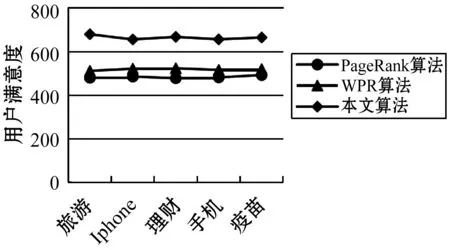
图6 三种算法的用户满意度对比图
仿真实验证明,本文算法在一定程度上可以提高网页排序质量、信息查询的精准度和用户检索的满意度。
4 结 语
本文提出一种基于分布式学习自动机和用户反馈的页面排序算法。该算法首先基于分布式学习自动机确定网页间的超链接权重,以缓解PageRank算法平分链接权重和主题漂移问题,计算超链接权重是根据页面内容的相似性、相关链接的存在以及用户遍历的路径;其次考虑到用户反馈中包含大量的价值信息,其某些行为反应了用户对搜索主题下的网页质量、内容等的认可度,选取用户的转载、回复以及有效点击特征作为用户的行为特征,获得用户反馈因子。仿真实验表明,该算法在一定程度上提升了信息检索的精准度和用户满意度。下一步工作是考虑尝试在学习自动机中使用用户在网页中的停留时间作为奖励进行网页排序对算法进行改进。
