Python程序设计教学的NLTK模块应用案例设计
2019-04-01刘卫国
刘卫国,李 晨
(中南大学 信息科学与工程学院,湖南 长沙 410083)
0 引言
Python语言不仅语法优雅、清晰、简洁,而且具有大量的第三方函数模块库,很适合作为程序设计入门语言,对学科交叉应用也很有帮助[1-2]。
NLTK模块是Python常用的自然语言处理(Natural Language Process,NLP)工具,能方便快捷地处理自然语言文本。NLTK模块中有用于处理自然语言任务的函数,与Python其他第三方模块库进行协同操作,能对处理结果进行二次处理。此外,NLTK包含丰富的语料库,这些语料资源在教育学、文学、史学等领域均有应用[3]。
在管理、英语、法学等文科类专业程序设计教学中,利用NLTK模块并结合其他第三方模块,可以设计适合教学需要的应用案例[4]。在Python程序设计教学中,结合专业应用案例进行教学,能培养学生的学习兴趣,引导学生将Python应用到专业领域中。
1 就职演说语料库文本内容提取与统计案例分析
笔者以就职演说语料库(Inaugural Address Corpus)作为英文研究对象进行分析,从中挖掘词句结果及高频词,以此论证挖掘出来的结果与语料库主题的相关性。就职演说语料库包含1789—2009年美国历任总统就职演讲,共55个文本,总词汇数为145 735个。语料库以演说年代作为标准区分,演说年代对应独立的子文本。本案例使用到的NLTK知识点包括语料库的调用、分词分块处理、停用词的信息过滤、频率统计类函数的应用[5]以及NLTK与Matplotlib模块的协同作用。案例流程见图1。
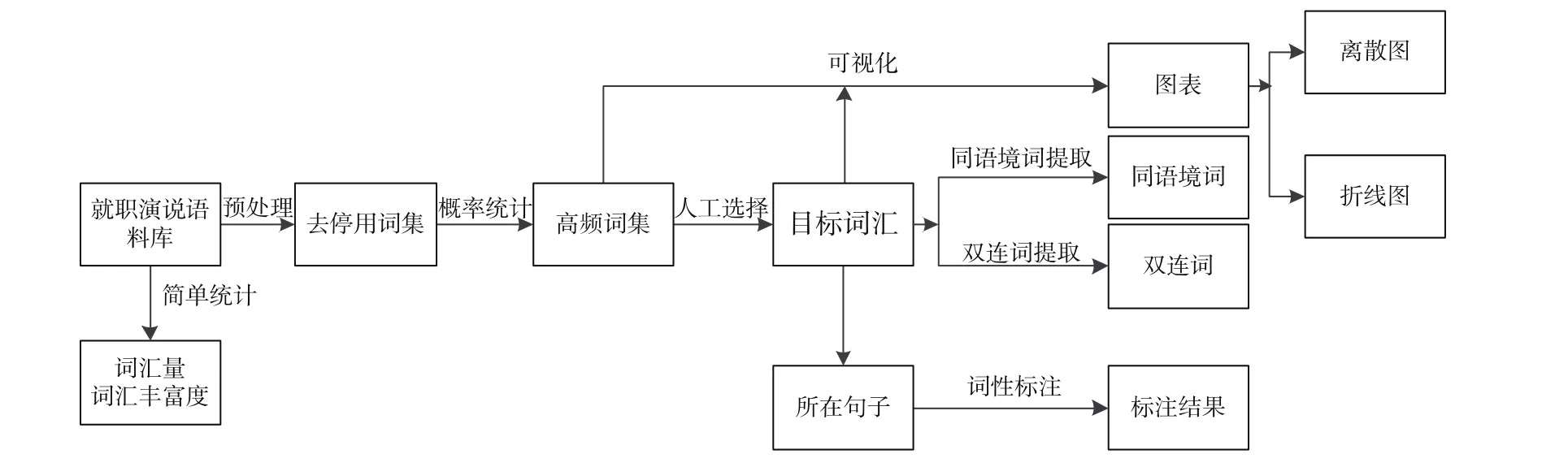
图1 就职演说语料库案例流程图
1.1 语料库获取与预处理
本案例使用的语料库来源于NLTK的语料库,导入NLTK模块即可调用。使用NLTK计算文本长度的内置函数len()计算词汇丰富度T值。词汇丰富度是用于分析文本中词汇出现的多寡,反映文本词汇的总体使用情况。就职演说语料库的词汇丰富度为6.692%,T值越大说明文本词汇丰富度越大,对文本词汇的使用情况得到数字上直观的展示。
文本预处理是对文本进行简单处理的过程,本案例的预处理过程包括清洗过滤与词形还原。首先过滤文本中无实际含义的停用词、符号,英文词汇有单复数、时态等不同形态,如果不进行词形还原,统计结果会存在很大的偏差。
清洗过滤通过调用停用词语料库完成,首先将文本中词汇使用lower()方法统一归并为小写,导入NLTK的英文停用词语料库,提取就职演说语料库包含且停用词语料库不包含的词汇。词形还原通过编写函数实现将复数单词转化为单数,根据预先定义好单词的单复数转换规则,对输入单词的末尾字母作选择判断,将输入的单词末尾字母转换为单数形式的后缀。使用到的知识点有判断结构if-else语句、词汇运算符word.endswith()。具体代码如下:


1.2 分析与统计
分析阶段是抽取过程的核心,涉及文本的一系列处理操作。使用的方法有同语境词提取、双连词提取、上下文提取、词性标注以及统计分析,其中统计分析是最常使用的工具。
NLTK中使用函数similar()查找与目标词汇出现在相似上下文位置的词,即在文本中可用作替换的词汇。在美国作家梅尔维尔所写的《白鲸记》中寻找名词的同语境词,小说讲述的是主人公亚哈船长与一头白鲸的故事,使用text.similar("captain")找到以下同语境词:whale ship sea boat deck world other devil wind body mate crew air head,可以发现得到的词汇与目标词汇词性均为名词。
双连词搭配提取是在文本中检索得到频繁出现的双连词以及文本中的固定搭配。例如在古腾堡语料库中调用《哈姆雷特》提取双连词搭配,具体代码如下:

NLTK有两个方法可以实现目标词汇的上下文输出,使用concordance()对目标词汇所在的句子进行检索输出,common_text查找词汇集合的相同临近词汇,例如text2.common_contexts(["monstrous","very"])得到结果“a_pretty am_glad a_lucky is_pretty be_glad”,其中a_lucky表示a monstrous lucky与a very lucky。
词性标注(Part-of-Speech Tagging, POS tagging)将分词处理后的词汇按词性(POS)分类并标注的过程。在词性分析阶段使用NLTK内置的词性标注器(POS tagger),处理一个词序列,为每个词附加一个词性标记。词性标注可以帮助分析句子成分,划分句子结构。
概率统计作为NLTK中最常用的数学分析手段,用于文本中数据的处理分析。在Python中借助NLTK频率分布类中定义的计算频率的函数,对文本出现的单词、搭配、常用表达或符号进行统计词频、词长等相关操作。代码如下:

1.3 结果展示与总结
利用停用词语料库得到的高频词集,部分统计结果为[('government',593),('people', 563),('state s',329),('world',329)],括号内数字为高频词在文本中出现的次数。
对语料库双连词搭配提取:
nltk.Text(nltk.corpus.inaugural.words()).collocations()
部分结果如下:
United States; fellow citizens; American people。
对出现词频最高的词汇“government”的同语境词进行提取:
nltk.Text(nltk.corpus.inaugural.words()).similar("government")
部分结果如下:
people country union nation constitution power peace。
对高频词数据可视化,将结果转化为词频折线统计图、离散图以及关键词对比折线图,分别见图2—图4。
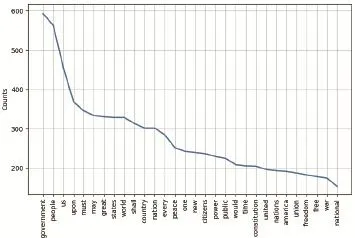
图2 频率折线图
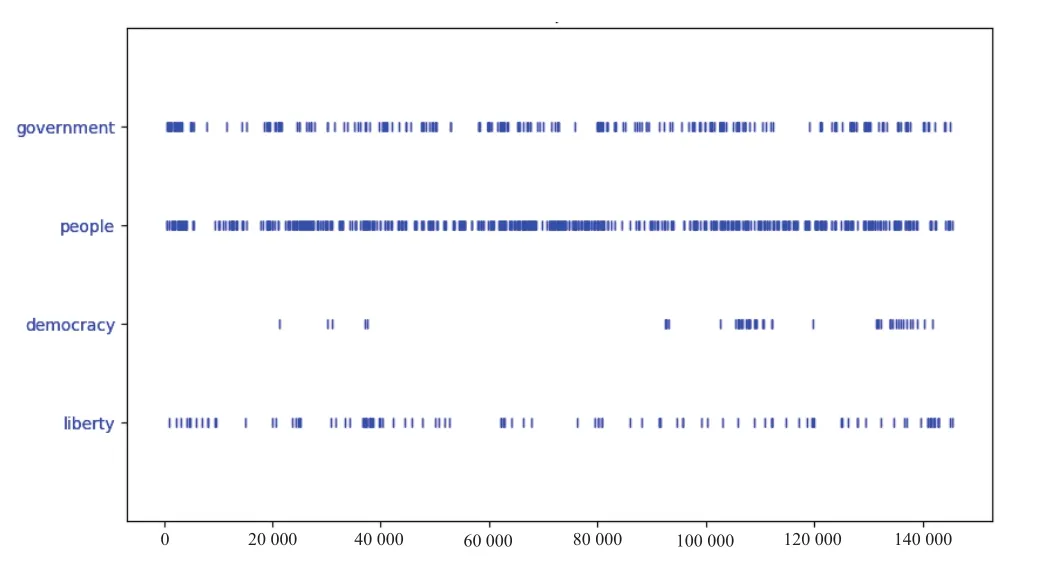
图3 离散图
图2折线图是以高频词集作为数据来源进行可视化,横轴为词汇,纵轴为出现的次数。
图3离散图是用于展示词汇在文本中出现的位置,发现“people”一词在文本中出现密集而“democracy”则较稀疏,仅在后半部分出现较多。结合就职演说语料库文本按时间顺序排列的结构,可以看出不同演讲用词随时间在使用频率上显著的差异。
图4关键词频率折线图是对不同年代美国总统在就职演讲中使用“economy”“politics”两个词的频率结果进行可视化输出。可以看到“economy”一词在“1925”“1958”两个文本中达到峰值。
2 十九大报告高频词可视化统计分析
NLTK的主要适用场景是英文,在处理中文文本时需要安装中文分词工具包并进行字符转换。本文选择十九大报告作为中文分析素材,使用Jieba作为分词处理工具[6]。本案例采用Beautiful Soup模块对网页上的案例文本进行爬取,Beautiful Soup是Python中用于网络爬虫的第三方模块,它可以提供一些简单的函数提取网页中的内容。
2.1 具体操作
本案例将爬取后的文本内容保存在TXT文件中,首先对爬取得到的素材文件过滤标点符号、数字与停用词等,对全文内容进行词性标注。分析过程中使用同语境词查找、关键词所在句子输出等方法,使用概率统计对高频出现的词汇进行查找输出,最后导入Wordcloud模块实现词云可视化,展示统计分析结果。案例实现具体代码如下:



2.2 结果展示与分析
将案例运行结果打印并可视化,得到十九大报告高频词折线图、名词高频词折线图、离散图、词云展示结果见图5—图8。
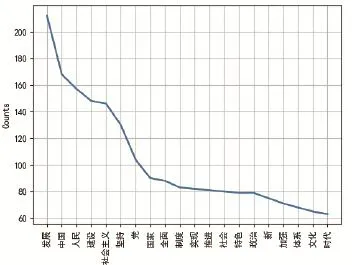
图5 十九大报告高频词折线图
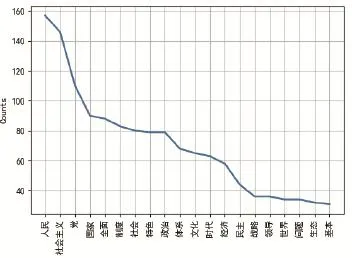
图6 名词高频词折线图
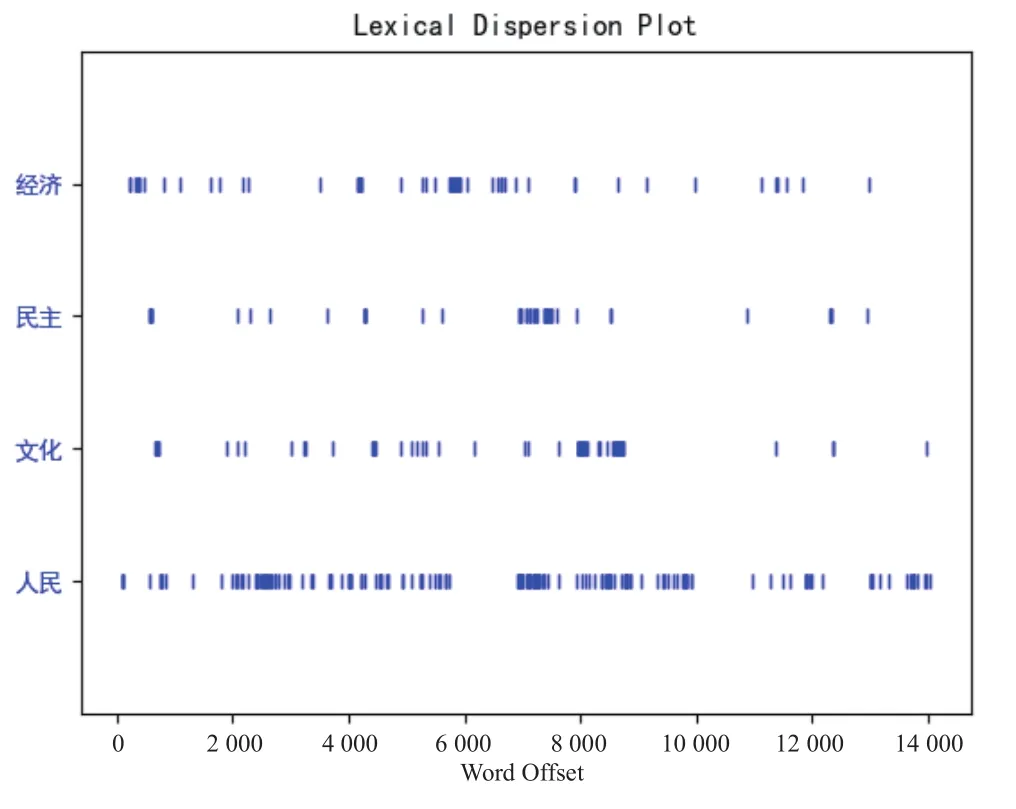
图7 离散图

图8 高频词词云展示
从图5中可以发现“发展”“中国”“人民”是报告中频率最高的3个词。在高频词中利用词性标注结果筛选出名词高频词,得到图6名词高频词折线图,图7离散图用于展示目标词汇在文本中所处位置,每一个竖线代表一个词汇在十九大报告中出现的位置,从图7中可以发现“人民”在报告中的各个位置均有分布,与其他词汇相比出现位置最为密集。图8选择部分高频词汇以词云的形式展示统计结果,增强了结果可视化的艺术性。
3 结语
本文选择中文、英文两篇素材的分析进行教学案例设计,利用NLTK模块和其他第三方模块的一系列方法,从素材中提取词句结果,完成有效信息查找与提取、统计分析以及词频可视化展示。教学案例结合文科类专业的特点,综合运用Python程序设计方法和第三方模块的功能,既体现了Python程序设计的特点和规律,又能更好地促进计算机在不同学科的交叉应用。文科类专业程序设计教学更需要直观、具体的教学展示,利用案例组织教学,让学生在边学边做中建立学习兴趣,培养学习热情,能获得更好的教学效果。
