基于改进模糊支持向量机的汽轮机热耗率预测模型
2019-03-28黄昕宇张栋良李帅位
黄昕宇,张栋良,李帅位
基于改进模糊支持向量机的汽轮机热耗率预测模型
黄昕宇,张栋良,李帅位
(上海电力学院自动化工程学院,上海 200090)
针对现有方法难以准确预测具有复杂非线性特征的汽轮机热耗率问题,本文提出一种改进模糊支持向量机(FSVM)的汽轮机热耗率预测模型。首先采用间隔统计算法计算热耗率数据最佳聚类个数,防止出现聚类数目的不确定性,然后利用模糊C均值聚类(KFCM)算法将热耗率数据划分,生成聚类子样本,将聚类子样本代入经粒子群算法优化的FSVM中,建立基于FSVM的汽轮机热耗率预测模型。将现场采集的某超超临界660 MW机组汽轮机热耗率数据输入模型进行预测,并与传统支持向量机的预测结果进行比较。结果表明,改进的FSVM方法具有更高的预测精度和更强的泛化能力。
汽轮机;热耗率;聚类算法;模糊支持向量机;预测模型;间隔统计
汽轮机热耗率是火电厂技术经济重要指标。为了更好地对机组经济性以及运行参数进行分析和优化,精确预测热耗率数值十分必要[1-3]。
支持向量机(SVM)克服了以往预测算法训练时间长、预测结果存在不确定性等问题,在多年的研究和发展后,SVM已经在预测诊断领域有了一定的应用基础[4-6]。但是,应用SVM建立热耗率预测模型还存在一些亟待优化之处。首先,影响汽轮机热耗率的因素较多,而且各个影响因素与热耗率之间存在复杂非线性联系,导致部分数据样本和最优超平面的距离较远,干扰模型的预测精度;其次,SVM的参数选择也会干扰预测的结果。
针对以上问题,Lin Chunfu等[7-8]提出了模糊支持向量机(FSVM)算法。该算法通过给不同的样本加上相应的模糊隶属度值,进而反映不同样本的重要程度。但是,该算法中没有明确定义模糊隶属度值的计算方法,而且对影响FSVM算法结果的参数未进行优化。张战成等[9]研究了一种提高SVM预测精度的算法,该算法通过训练SVM并对支持向量集使用模糊C均值聚类(FCM)算法,将获得的聚类中心当作新的支持向量来优化模型。不过FCM算法本身也有不足之处,聚类个数的选择在很大程度上会干扰聚类的效果。
基于上述研究,本文采用改进模糊支持向量机(FSVM)算法对汽轮机热耗率进行预测分析。首先通过间隔统计(gap statistic)算法计算最佳聚类个数,并将其代入核模糊C均值聚类(KFCM)算法中,对热耗率进行分类,生成聚类子样本,并求取模糊隶属度值μ;其次,根据不同的聚类样本分别建立模糊支持向量机(FSVM),对热耗率样本进行预测分析,同时,应用粒子群算法(PSO)解决FSVM的参数优化问题;最后,建立某超超临界660 MW机组汽轮机热耗率预测模型,将本文提出的算法与传统支持向量机和经过粒子群算法优化的支持向量机方法进行仿真比较。结果表明本文所提出的算法具有更高的预测准确率和泛化能力。
1 聚类算法
1.1 间隔统计算法
在现有的聚类算法中,聚类数在很多情况下难以确定。聚类数不同,聚类结果也可能产生变化。确定样本集的最优聚类数是聚类算法中一个很困难的问题。
为了计算出最优聚类数,得到更好的聚类结果,本文采用间隔统计算法首先对数据进行分析,以计算出最优聚类个数。
间隔统计算法的计算方法可以分为以下3步。
步骤1 将故障数据分为类,1,2,3, …,,表示数据点属于类,计算W,
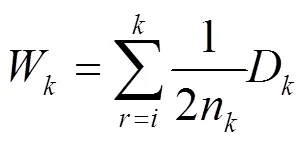
式中:n表示属于类的数据的个数,表示第类中任两点的距离和,W表示类离差程度的总和。
步骤2 生成个参考数据集,并计算每个参考数据集的离差程度总和W*,1, 2, …,,=1, 2, …,,计算Gap值,

步骤3 计算出满足式(3)的最小值,以此值作为最优聚类数,
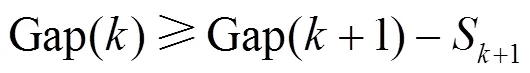
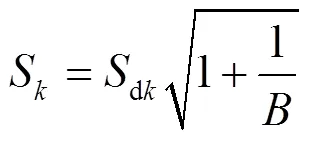


1.2 核模糊C均值聚类算法
KFCM算法是通过隶属度确定每个数据点属于某个类的程度,从而划分数据点类别[10-11]。假设特征空间中的输入样本定义为
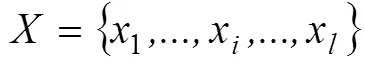
式中x∈R。
采用高斯核函数把映射至特征空间中展开聚类。高斯核函数定义为
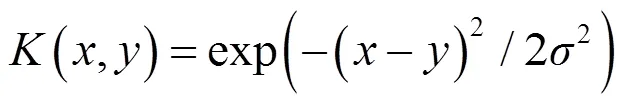
式中为核带宽。
KFCM算法的目标函数表达式为

式中:2(x,v)=(x, x)-2(x, v)+(, v),表示x到v的距离,v为第个聚类中心;(0≤≤1)为模糊指数;μ为第个样本属于第类的隶属度。
满足如下约束条件:

以式(9)为约束条件,使用Lagrange法求解m,计算出隶属度μ以及聚类中心的表达式:
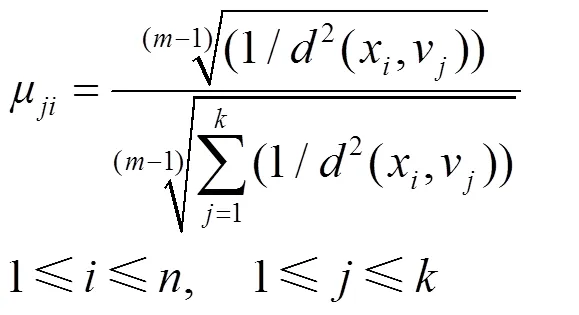
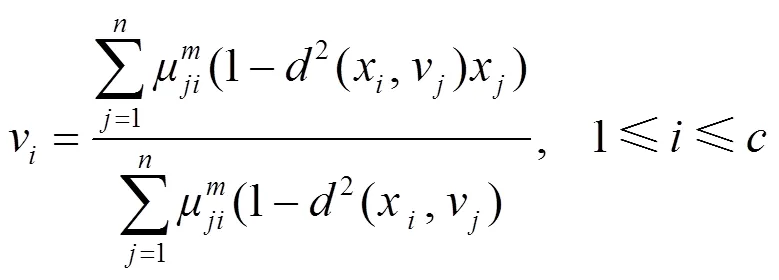
KFCM的详细计算过程如下。
步骤1 初始化聚类的个数,的值为间隔统计算法计算出的最佳聚类数,模糊参数的范围为0≤≤1,确定终止参数。
步骤2 根据式(10)计算模糊隶属度μ。
步骤3 由式(11)更新聚类中心矩阵。
步骤4 重复步骤2和3的优化过程,直到满足设定的终止条件:max{x|μ–μ|}<。结束后得出个聚类中心以及模糊隶属度μ。
2 汽轮机热耗率预测模型
2.1 模糊支持向量机预测模型
FSVM算法可以有效克服SVM在复杂非线性样本预测过程中存在的过拟合问题,FSVM算法利用模糊隶属度函数来模糊化输入的样本,对于重要程度不同的样本赋予不同的隶属度值[12-14]。假设每个样本的隶属度值为,则模糊化的输入样本为={(1,1,1), (2,2,2), …, (x,y,μ)},其中x∈R,y∈,≤≤1(=1, 2, …,),其中为足够小的正数,μ表示x在样本中的重要程度。将求解FSVM最优超平面问题转换为如下的规划问题:

该规划问题的约束函数为:

式中:为分离超平面的向量,为经验风险系数,和均为松弛变量,为常数。隶属度值越小,其对应的样本点x对上述规划问题的目标函数所起的作用就越小。为求解该规划问题,构造拉格朗日函数



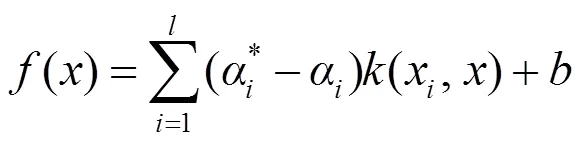
在式(15)中,(x,)为核函数,本文选取径向基(RBF)核函数,其表达式为

式中为核带宽。
2.2 模糊支持向量机的参数优化
在FSVM模型中,需要优化的主要参数包括核带宽参数以及经验风险系数。其中是用来权衡损失和置信范围之间的权重,参数则可以反映训练样本的特征[15-16]。这2个参数对模型的分类精度会产生较明显的影响,传统FSVM算法采用交叉验证的方法对参数进行优化,该方法寻优时间较长,本文采取PSO来优化FSVM中的参数[17]。通过计算这2个参数的最优值,提高模型的诊断效率。PSO寻优的具体步骤如下。
步骤1 设置粒子群的惯性权重、学习因子、迭代次数以及种群规模,确定需要优化的2个参数的极值以及迭代速度的范围。
步骤2 定义适应度函数,本文采取基于倍交叉验证的方法来确定适应度值,

式中:l为第个验证集合中样本的数量,l,T为第个验证集中预测正确的样本数量,首先将训练集随机置换,然后将其分为个集合,在第次迭代后,将第个集合(称为验证集合)的训练成果用来训练其他–1个集合(称为训练集合),从而计算样本的适应度值。
步骤3 对粒子进行速度和位置更新,比较更新粒子的个体最优适应度值和群体最优适应度值。
步骤4 确定是否达到终止条件,满足则结束运算输出最优解,否则返回步骤3。
2.3 预测模型的建立
基于核模糊C均值及粒子群算法优化参数的模糊支持向量机对汽轮机热耗率进行预测的的具体步骤如图1所示。
1)初始化聚类参数,其值是通过间隔统计算法计算出的最佳聚类个数;
2)采取KFCM算法对样本进行聚类划分,按照式(10)—式(11)更新模糊隶属度以及聚类中心,直到满足条件后,生成模糊聚类子样本;
3)对于每一种经过聚类后热耗率子样本分别建立经PSO优化相关参数的FSVM预测模型;
4)将各个子模型进行叠加,建立最终的预测模型;
5)将测试样本输入预测模型中检验模型精度。

图1 改进的FSVM预测模型算法流程
3 汽轮机热耗率预测模型应用实例
根据某火电厂超超临界660 MW汽轮机组(N660-25/600/600)的数据建立热耗率模型,其中数据样本每个月随机选择7天采集,每天在DCS数据库中采集5组数据,共采集6个月,一共得到210组数据,基本包含机组运行的各种工况。表1为部分热耗率数据。把其中160组样本作为训练集,其余50组样本作为测试集。
汽轮机热耗率的计算表达式为

式中:r为热耗率,kJ/(kW·h);e为发电机端功 率,MW;b为汽轮机背压,kPa;(ms,ms,ms)、(crh,crh,crh)、(hrh,hrh,hrh)、(ffw,ffw,ffw)、(rhs,rhs,rhs)分别为主蒸汽、冷再热蒸汽、热再热蒸汽、最终给水、再热减温水的流量(t/h)、温度(℃)、压力(MPa)。各加热器端差τ也会影响汽轮机热耗率,本文选择在数据采集现场中出水温度最高的高压加热器给水端差作为输入变量,代入汽轮机热耗率的计量中。
机组运行参数中主蒸汽流量和再热蒸汽流量需要计算得到。本文数据来源的火电厂主蒸汽流量的计量过程是通过在除氧器入口管道上安装节流孔板测量凝结水流量,计量凝结水至除氧器的凝结水流量,然后计算各个高压加热器进汽流量及除氧器进汽流量,最终计算出主给水流量以及主蒸汽流量。
冷再热蒸汽流量一般通过热平衡方法计算出高压加热器的抽汽流量,再根据式(19)计算得出,
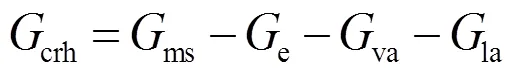
式中,e为抽汽流量,la为高压缸前轴封漏汽总量,va为高压缸后轴封漏汽总量。热再热蒸汽流量的计算公式为
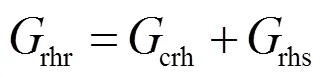
3.1 数据聚类
通过间隔统计算法确定最佳聚类数,根据 式(3)—式(5)寻找,得到的Gap值如图2所示。由图2可知最佳聚类数为5。

图2 Gap值与聚类数曲线
表1 某超超临界660 MW 机组热耗率数据样本

Tab.1 The heat rate data of an ultra-supercritical 660 MW unit
图3为目标函数的曲线,在迭代30次后,趋于稳定,记录所生成的聚类子样本。热耗率数据在聚类算法下分为7 450.6、7 800.2、8 020.5、 7 695.0、7 536.4 kJ/(kW·h)这5类。

图3 目标函数J的曲线
3.2 预测结果分析
为了更好地验证改进FSVM算法在汽轮机热耗率预测模型上的优化程度,分别采用SVM、经PSO优化参数的SVM和本文提出的改进FSVM进行仿真对比,图4为采用改进FSVM方法预测结果,图5为3种预测模型对测试样本的误差曲线。
从图4和图5可以看出,改进FSVM预测模型预测精度更佳,与其他2种预测方法相比,预测误差更小,预测误差的波动性小,说明本文提出的预测模型能更准确地预测汽轮机热耗率。
为了更准确地表示预测精度,采取以下4种预测性能指标对结果进行对比,不同预测模型在训练集和测试集的误差对比分别见表2和表3,各项指标定义如下:
1)平均相对百分比误差MAPE
式中x为对热耗率数据预测分析后得到的数值。
3)最大绝对偏差MAD
4)最大绝对误差max
表2 不同预测模型在训练集的误差对比

Tab.2 The errors of different prediction models for training sets
表3 不同预测模型在测试集的误差对比

Tab.3 The errors of different prediction models for test set
由表2可见,针对训练集,KFCM-PSO- FSVM预测模型的4项预测指标比其他2种预测模型都低,因此,KFCM-PSO-FSVM预测模型在拟合精度上更佳。由表3可见,在测试集中,经过聚类算法优化预测模型后,4项预测误差的指标相比其他2种预测模型明显降低,尤其是MAD仅为0.232 0。对比表2和表3可见,KFCM-PSO-FSVM预测模型中的各项数据指标没有明显增大,这说明对测试集而言,KFCM-PSO-FSVM预测模型有更好的泛化能力和预测精度。综上所述,本文提出的改进FSVM预测模型在预测精度及预测效果上更好,综合性能更佳。
4 结 论
本文在传统支持向量机的基础上,提出了基于核模糊C均值聚类算法和粒子群优化算法的模糊支持向量机算法,建立了该算法针对汽轮机热耗率的预测模型。该算法中FSVM作为预测模型,其核函数选择RBF核函数;采用KFCM算法确定FSVM训练样本的模糊隶属度值;采用间隔统计算法计算KFCM中的最佳聚类个数;采用PSO算法优化FSVM的2个重要参数以及。以某超超临界660 MW机组汽轮机热耗率为对象进行预测仿真,结果表明本文提出的算法能够更好地对复杂的汽轮机热耗率进行预测,预测效果更佳,泛化能力更强,对热耗率预测研究提供了一种新的思路。
[1] 王惠杰, 范志愿, 许小刚. 基于FOA-LSSVM的汽轮机热耗率预测模型研究[J]. 热力发电, 2017, 46(5): 36-42. WANG Huijie, FAN Zhiyuan, XU Xiaogang. Research on prediction model of heat consumption rate of steam turbine based on FOA-LSSVM[J]. Thermal Power Generation, 2017, 46(5): 36-41.
[2] 翟兆银, 王际洲, 李建兰, 等. 基于功率的汽轮机组实时热耗率计算方法[J]. 热力发电, 2015, 44(10): 15-19. ZHAI Zhaoyin, WANG Jizhou, LI Jianlan, et al. A real-time monitoring model for heat consumption rate of steam turbine unit based on unit power[J]. Thermal Power Generation, 2015, 44(10): 15-19.
[3] 牛培峰, 吴志良, 马云鹏, 等. 基于鲸鱼优化算法的汽轮机热耗率模型预测[J]. 化工学报, 2017, 68(3): 1049-1057.NIU Peifeng, WU Zhiliang, MA Yunpeng, et al. Prediction of steam turbine heat consumption rate based on whale optimization algorithm[J]. CIESC Journal, 2017, 68(3): 1049-1057.
[4] 韩中合, 刘明浩. 基于支持向量机的汽轮机振动故障诊断系统[J]. 汽轮机技术, 2013, 55(2): 127-130. HAN Zhonghe, LIU Minghao. Vibration fault diagnosis of steam turbine based on SVM[J]. Turbine Technology, 2013, 55(2): 127-130.
[5] 吴广宁, 袁海满, 宋臻杰, 等. 基于粗糙集与多类支持向量机的电力变压器故障诊断[J]. 高电压技术, 2017(11): 3668-3674. WU Guangning, YUAN Haiman, SONG Zhenjie, et al. Fault diagnosis for power transformer based on rough set and multi-class support vector machine[J]. High Voltage Engineering, 2017(11): 3668-3674.
[6] 李燕青, 袁燕舞, 郭通. 基于AMD-ICSA-SVM的超短期风电功率组合预测[J]. 电力系统保护与控制, 2017, 45(14): 113-120. LI Yanqing, YUAN Yanwu, GUO Tong. Combination ultra-short-term prediction of wind power based on AMD-ICSA-SVM[J]. Power System Protection and Control, 2017, 45(14): 113-120.
[7] LIN C F, WANG S D. Fuzzy support vector machines[J]. IEEE Transactions on Neural Networks, 2002, 13(2): 464-471.
[8] 赵克楠, 李雷, 邓楠. 一种构造模糊隶属度的新方法[J]. 计算机技术与发展, 2012, 22(8): 75-77. ZHAO Kenan, LI Lei, DENG Nan. A new method to construct fuzzy membership[J]. Computer Technology and Development, 2012, 22(8): 75-77.
[9] 张战成, 王士同, 邓赵红, 等. 一种支持向量机的快速分类算法[J]. 控制与决策, 2012, 27(3): 459-463. ZHANG Zhancheng, WANG Shitong, DENG Zhaohong, et al. A fast decision algorithm of support vector machine[J]. Control and Decision, 2012, 27(3): 459-463.
[10] 李状, 柳亦兵, 滕伟, 等. 基于粒子群优化KFCM的风电齿轮箱故障诊断[J]. 振动、测试与诊断, 2017, 37(3): 484-488. LI Zhuang, LIU Yibing, TENG Wei, et al. Fault diagnosis of wind turbine gearbox based on KFCM optimized by particle swarm optimization[J]. Journal of Vibration, Measurement & Diagnosis, 2017, 37(3): 484-488.
[11] 朱晓东, 倪秋华. 基于模糊聚类的支持向量机在振动故障诊断中的运用[J]. 汽轮机技术, 2013, 55(3): 232-234. ZHU Xiaodong, NI Qiuhua. Application of support vector machines based on the fuzzy clustering for fault diagnosis[J]. Turbine Technology, 2013, 55(3): 232-234.
[12] 牛培峰, 刘超, 李国强, 等. 基于双层聚类与GSA-LSSVM的汽轮机热耗率多模型预测[J]. 电机与控制学报, 2016, 20(3): 90-95. NIU Peifeng, LIU Chao, LI Guoqiang, et al. Multi-model for turbine heat rate forecasting based on double layer clustering algorithm and GSA-LSSVM[J]. Electric Machines and Control, 2016, 20(3): 90-95.
[13] 李小辉, 朱莉, 吴坚. 基于模糊支持向量机的毫米波辐射计目标识别[J]. 微波学报, 2017, 33(增刊1): 203-206. LI Xiaohui, ZHU Li, WU Jian. Target identification of millimeter wave radiometer based on fuzzy support vector machines[J]. Journal of Microwaves, 2017, 33(Suppl.1): 203-206.
[14] HANG J, ZHANG J Z, CHENG M. Application of multi-class fuzzy support vector machine classifier for fault diagnosis of wind turbine[J]. Fuzzy Sets & Systems, 2016, 297(C): 128-140.
[15] DOU D, ZHOU S. Comparison of four direct classification methods for intelligent fault diagnosis of rotating machinery[J]. Applied Soft Computing, 2016, 46: 459-468.
[16] XU H, CHEN G. An intelligent fault identification method of rolling bearings based on LSSVM optimized by improved PSO[J]. Mechanical Systems & Signal Processing, 2013, 35(1/2): 167-175.
[17] 叶小岭, 顾荣, 邓华, 等. 基于WRF模式和PSO-LSSVM的风电场短期风速订正[J]. 电力系统保护与控制, 2017, 45(22): 48-54. YE Xiaoling, GU Rong, DENG Hua, et al. Modification technology research of short-term wind speed in wind farm based on WRF model and PSO-LSSVM method[J]. Power System Protection and Control, 2017, 45(22): 48-54.
Prediction model of steam turbine heat consumption based on improved fuzzy support vector machine
HUANG Xinyu, ZHANG Dongliang, LI Shuaiwei
(School of Automation Engineering, Shanghai University of Electric Power, Shanghai 200090, China)
To the problem that the existing methods are difficult to accurately predict and analyze the heat consumption of steam turbines with complex non-linear characteristics, this paper presents an improved prediction model of steam turbine heat consumption based on fuzzy support vector machine (FSVM). Firstly, the gap statistic algorithm is used to calculate the optimal number of clusters to avoid the uncertainty of the number of clusters. Then, the kernel fuzzy C mean clustering (KFCM) algorithm is applied to divide the heat consumption data, generate cluster subsamples, and replace it into the FSVM optimized by particle swarm optimization (PSO), and establish a thermal consumption rate prediction model based on the FSVM. Finally, this model is employed to predict the heat consumption rate of an ultra-supercritical 660 MW unit steam turbine based on the data collected in the field, and the results are compared with that of the conventional support vector machine. The research results show that the improved FSVM method has higher prediction accuracy and stronger generalization ability.
steam turbine, heat consumption rate, clustering algorithm, fuzzy support vector machine, prediction model, gap statistic
National Natural Science Foundation of China (61503237); Shanghai Natural Science Foundation (15ZR1418300); Shanghai Key Laboratory of Power Station Automation Technology (13DZ2273800); Shanghai Scientific Research Plan Project (18020500900)
TK26
A
10.19666/j.rlfd.201806119
黄昕宇, 张栋良, 李帅位. 基于改进模糊支持向量机的汽轮机热耗率预测模型[J]. 热力发电, 2019, 48(3): 22-27. HUANG Xinyu, ZHANG Dongliang, LI Shuaiwei. Prediction model of steam turbine heat consumption based on improved fuzzy support vector machine[J]. Thermal Power Generation, 2019, 48(3): 22-27.
2018-06-10
国家自然科学基金项目(61503237);上海市自然科学基金项目(15ZR1418300);上海市电站自动化技术重点实验室(13DZ2273800);上海市科研计划项目(18020500900)
黄昕宇(1994—),男,硕士研究生,主要研究方向为汽轮机运行优化与故障诊断,642552867@qq.com。
(责任编辑 杜亚勤)
