面向彝文网页的敏感内容分级系统研究
2019-03-27李炳泽王嘉梅
王 清,李炳泽,王嘉梅
(1.云南民族大学 云南省高校少数民族语言文字信息化处理工程研究中心,云南 昆明 650504;2.文山学院,云南 文山 663000)
云南作为一个多民族、多宗教的边境省份,因其跨境民族种类最多、民族分布边境线长等特点,涉外信息的传播和民族网络监管成为了网络信息安全比较棘手的问题[1].特别是,近年来随着互联网的发展和对外门户的开放,边疆民族地区的涉外信息交流频繁,而网络舆情工作的监管和处置将会越加困难.与此同时,由于跨境语言网络缺乏有效的技术和统一的管理,大量有关政治、宗教等敏感信息充斥其中,给当地的民族稳定和社会和谐构成了极大的威胁[2].由于跨境民族网络上的敏感内容大多以文本形式呈现,因而检测、过滤敏感内容并对其进行敏感度分级成为了我们维护跨境网络舆情安全的关键[3].鉴于跨境民族语言的多样性和复杂性,本研究以个案研究为切入点,选择使用较多的跨境语言-彝文为例,构建面向彝文网页的敏感内容分级系统.
1 系统框架概述
目前,国内外对于边疆民族网络舆情分析技术的研究,大多关注在舆情信息的采集、传播和监管等理论分析方面.2009年—2016年,国家相继资助和开展以国家自然科学基金或社会科学基金为代表的多项边疆舆情研究性课题,研究了维吾尔文、藏文、蒙文的舆情观点挖掘、网络舆情监测等民族语言舆情处理的关键技术[4-5].但由于跨境民族文字的特殊性和跨境舆情传播的复杂性等综合因素,相较于汉语,国内对于跨境民族语言文字的舆情技术研究尚处于发展中阶段,民族舆情研究领域缺乏学科体系的支撑及全面系统的成果[6].针对国内外以上研究,本研究设计了面向彝文网页的敏感内容分级模型,包含4个关键模块:网络信息获取、文档的预处理、敏感内容检测、敏感文档分级,如图1所示.

2 彝文信息获取模块
2.1 彝文网页采集结构
通过对彝文的分析得知,彝文不管是在音节上还是结构上,用计算机的方式很难将其从网页中与中文区分开来[7].因此,本研究设计了针对彝文的网页信息采集方法,和中文不同的是增加了彝文网页判断模块,结构如图2所示,其主要包括6个模块,分别初始化彝文URL种子、彝文网页判别、页面解析、URL提取和去重、信息提取和数据库等.

2.2 彝文网页URL选取
彝文网页中HTML编写的半结构化文档中混杂着中英文字符和多媒体信息(如音频、图片等),这些噪声给信息的采集带来一定的难度[8],但彝文网页与中英文网站相比较少,这又带来有利的一面.因而我们统计了部分主流彝文网站的特征,并以初始种子URL链接和网页编码属性作为爬虫的初始URL选取依据,如表1所示.

表1 选取彝文网站的特征属性分析
2.3 彝文爬虫网页的判别
通过对彝文HTML文档分析得知,彝文不管是在音节上还是结构上,单纯的正则匹配很难将其抽取出来[9].而基于网页编码类型的判别方法,网页HTML源代码的“encoding”和“charset”标记字段是区别彝文特征的关键属性[10],大多数彝文编码类型是GBK或UTF-8,字符类型是方正彝,因而可共同作为彝文特征属性(文字类型、字符编码)来判断和识别网页文字中的彝文字符.而基于彝文网页链接判别方法,可采用正则表达式匹配次级URL链接(*代指字符串,用于分级标记),以找到所有爬虫的URL链接.网页地址链接的匹配(提取URL队列)可用于读入彝文网页,网页编码类型的特征(方正彝/GBK)可用于解析彝文网页中的彝字.本研究创新性地采用了基于网页编码类型与基于网页地址链接相结合的算法,一方面克服了前者对于HTML源代码中文字的编码属性识别效率较低的问题,一方面避免了后者对网页中包含混杂中英文而出现误差的情况.采用的彝文爬虫网页判别流程如图3所示,具体算法流程如下:
Step 1 对选取好的初始彝文URL种子,分析其内部网页链接结构,对每个网站设计出能够判别其彝文网页的正则表达式;
Step 2 单线程的比对,当新抽取的URL符合正则表达式匹配规则,则判别为彝文网页,否则转到步骤3;
Step 3 抽取彝文网页源代码中的FONT-FAMILY标记字段,判断字段中是否为方正彝的字体类型并检测是否包含在Face属性值中;如果是,则识别为彝文网页,否则转到步骤4;
Step 4 进一步判别,是否包含在该网页源码节点的Style属性中;如果是,则识别为彝文网页,否则转入步骤5;
Step 5 最后一次判别,是否包含在该网页源码节点的Face属性值中;若是,则识别为彝文网页URL,否则结束流程.依次读取并处理下一个彝文网页,转入步骤1.从人工后台URL链接数据库审查看,改进的判别算法比较适用于目前含混合文字的彝文网页,判别流程分层次进行,直观简单,而且识别结果比较准确.
其中在提取的URL队列中,为了防止相同的彝文网页重复爬取而造成信息冗余,本研究在网页判别的流程中,还加入了将新识别的URL连接与后台已采集URL地址数据库比对操作,当比对重复时,应加以滤除,整个彝文信息采集一直重复这个比对过程,直到所有的URL地址抽取完毕.
2.4 彝文爬取信息的解析
彝文网页的HTML解析就是通过应用正则表达式,分别在HTML文件中解析出网页中对应的URL地址、content文本内容、title标题、time时间等,通过对比分析得到我们想要的内容,并对其他内容进行过滤,把以上关键属性等信息存储到后台ACCESS数据库,对解析的内容统一转换成UTF-8编码的TXT文本文件进行保存.本研究抽取的彝文网页信息的属性信息如表2所示,对爬取的每个彝文网页,都有对应的以URL作为表头链接网页标题、发布时间、网页来源、正文数据等字段信息.
表2 彝文网页数据的存储字段
以中国彝学网为例,其爬取的彝文网页文本进行去冗余和编码后的TXT文本如图4所示.

3 彝文文本预处理模块
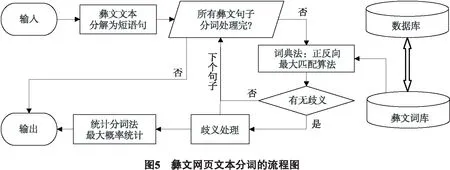
因而,提出将词典和统计相结合的算法来实现彝文文本的分词,从而发挥各自的分词优势.前者可在匹配过程中,将彝文字串与词典进行结合,能够深度检测和识别歧义字段,以提高分词准确率;后者可在词频统计下,根据最大概率计算原则消除存在的分词歧义,可加快分词的效率[13].彝文网页的文本分词流程如图5所示,其具体算法流程如下:
Step 1 把待切分的彝文文本进行断句预处理,即根据标点符号标记,如句号,逗号,破折号等断句符号来进行切分,从而把待切分的彝文文本切分成几个连读较短的彝语短句,并把彝文短句作为步骤2中的输入;
Step 2 对步骤1中断句切分出的彝文短句运用词典分词法,根据彝文词库(章节4.1说明)进行正向最大匹配和反向最大匹配的双向扫描,并把本次彝文分词结果作为步骤3的输入;
Step 3 对步骤2的两次彝文分词结果比较后可以清楚地发现,按照基于统计分词法中的最大贝叶斯概率计算来判断一个分词结果是否具有歧义,只需比较一下两次的切分结果,倘若相同则无歧义,倘若结果不同,那么就表示这种分词是具有歧义的,则接下来就要消除所具有的歧义;
Step 4 重复操作步骤2和步骤3,直至切分完步骤1中断句所切分出的全部彝文句子单元.彝文网页文本分词的示例如图6所示.

4 彝文词汇语料的构建
4.1 彝文分类词库的标注
本文所采用的分词算法是词典法改进而来的,其中最大正反向匹配模块是以彝文词表作为支撑[14],词表的规模在一定程度上决定了分词的准确率,从而影响最终彝文词过滤和敏感内容分级的准确性.课题组一直致力于彝文信息化的研究,共计收录了8 000个彝文词条,覆盖不同的领域.具体分为16类,包括:其他类别、人物杂记、成语典故、生化医药、学科教育、生理卫生、文史哲学、产业服务、政治军事、政策法规、社会生活、宗教迷信、植物动物、事物用品、文化艺术.彝文分类词库的构建采用纯Excel文件编辑,以中文词为模板一对一标注,并添加词性和拼音标识.彝文分类词库的标注结构如表3所示.

表3 彝文分类词库标注的结构表
4.2 彝文敏感词库的筛选
彝文分类标注词库是按类别进行划分的,可以帮助快速的筛选彝文敏感词集,共计收录732个彝文敏感词条.其中,“政治反动”敏感词类的整理来源于彝文标注词库中的“政治军事”和“政策法规”两个类别,“淫秽色情”敏感词类的收集主要源于彝文标注词库中的“生理卫生”类别,而其他“暴力恐怖”、“毒物传染”、“不良言语”的敏感词类则需要进行全部的整合.全库共计收录暴力恐怖类敏感词条共计302条,政治反动类敏感词条共计63条,淫秽色情类敏感词条共计143条,毒物传染类敏感词条共计64条,邪教赌博类敏感词条150条,不良言语类敏感词条共计10条.敏感词集也是数据库(Excel)文件形式保存,便于词库的新增、删除、修改等操作.部分淫秽色情类彝文敏感词库标注的结构如表4所示.

表4 彝文敏感词库标注的结构表
4.3 彝文敏感词的分级
彝文网络的敏感信息形势各样,而且还在不断地演变新的内容,要对其进行全部的敏感标记和危害区分存在较大的难度.但为了区分不同类别的敏感信息对于网络的危险性,我们参考国内对不良网站的分级标准[15],对彝文网络的敏感内容进行了初步分类,以提高敏感信息监管和危害评级的可操作性.将所有彝文敏感词的敏感级别划分6个子项,如表5所示,其中一级敏感包含不良言语和邪教赌博;二级敏感含毒物传染和淫秽色情;三级敏感包含(政治反动和暴力恐怖,每个子项设置为3个敏感等级,从“一级→二级→三级”依次表示此敏感类别对舆情安全的危害程度.因此,对于不同种类敏感内容过滤或关注的优先级排序为:{暴力恐怖、政治反动}>{毒物传染、淫秽色情}>{不良言语、邪教赌博}

表5 彝文敏感等级的分级体系表
5 彝文敏感内容的检测
5.1 敏感词的模式匹配方法
本研究参考敏感词决策树[16]的敏感词模式匹配方法,采用彝文敏感词库构建的敏感词决策树,以数据流形式检测网页文本中的敏感词串,综合衡量相对词频、敏感辞别对文本整理敏感度的计算,并结合敏感阈值完成危险分级.为了提高搜索效率和解决空间存储,彝文敏感词决策树将彝文敏感词汇按一一特定构词或分类规则嵌入到决策树中.

5.2 敏感词决策树的构建
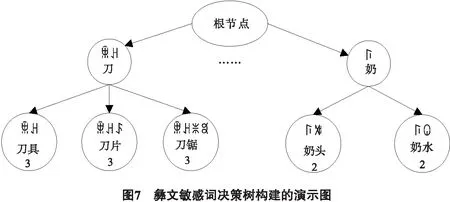
定义敏感词库Aford={a1,…,ai,…,an},1≤i≤n,其中,n为敏感词个数,ai表示敏感词,ai={ai1,…,aij,…,ain},1≤j≤n,aij表示第i个敏感词的第j敏感字,m表示敏感词长度,彝文敏感词决策树构建算法如下:
1)初始化i=1,j=1,k=1,k为记录孩子节点序号;
2)输入敏感词ai,获取其文本长度为,并提取其首部1彝文字或2个彝文字S;
3)进入S子树查询,将aij与S子树的第k个孩子节点childk进行比较;

5)若childk兄弟节点为空,创建新节点childk+1,值为aij,记录aij的字符,j++;
6)若j 7)若childk兄弟节点不为空,k++,返回步骤2),处理下一个敏感词; 本算法构建的彝文敏感词决策树深度为4(敏感词最长字符单位为4),树中每个节点存储了敏感字符以及其对应的汉语,叶节点还记录了敏感词的词汇频率、敏感级别,并且将各个词的频率都进行了初始化. 定义彝文文本流Yitext={b1,…,bi,…,bn},1≤i≤n,其中n为文本长度,bi表示彝文网页文本中的单个字符,彝文文本中敏感词的搜索算法如下: Step 1 初始化i=1,j=1,k=1,k为记录进入第一个分支的字符序列号; Step 2 输入bi,k=i,j=1,提取其首部1彝文字符或2个彝文字符; Step 3 将bi与S的孩子childj相匹配; Step 4 若bi=childj节点值,i++,直到i≥n,算法结束. Step 5 若bi≠childj节点值,查询childj兄弟节点是否为空; Step 6 若兄弟节点不为空j++,则,转步骤3; 在敏感词决策树结构的支持下,通过查找树来处理文本,便于以数据流的形式识别彝文文本中的所有敏感词.为过滤这些敏感词汇,可用字符/*/替换以达到屏蔽的目的. 在敏感词搜索过程中,可并记录其词汇频率和敏感级别提供后续文本敏感度计算,并根据计算值和敏感阈值的比较,给出敏感文本的危险级别分类. 词频可表征词在文本中的重要性,为了衡量某个彝文词在单个彝文文本的贡献,本研究采用了绝对词频的计算方法.假设文本d中的某一个敏感词条为si,那么词条si的绝对词频权重计算如下式. 其中,ni(d)表示词si在文本d中出现的次数;∑ini(d)表示文本d中所有的词语出现的频次之和. 但在敏感文本中,实际上敏感词的词频统计工作已经在上文的敏感决策树构建过程中通过程序计算完成,再此只是对计算原理加以概述. 文本敏感度的计算流程图如下图8所示: 通过查树处理文本之后,文本中敏感词的绝对词频权重以及敏感级别权重都可计算完成.敏感级别权重记为levs,levs=3,2,1;相对词频权重记为fres,则可得其计算方式: 最终对单个敏感词条si的权重计算采用下式,其中α,β都是调节的因子,需要实验设置合理的调节因子. weightsi=α·fres+β·levs. 对于一个彝文文本流d,假定被搜索的敏感词个数为k,计算其敏感词的平均权重W. 因上式是对所有的彝文敏感词统计平均权重,可将W值的大小作为文本敏感性的度量. 在彝文网页敏感内容识别中,考虑到信息安全的要求,需要将敏感内容的危险评级考虑在内.具体操作是根据已设定的敏感阈值(φ1,φ2,φ3),对文本的敏感值W进行比较,进而区分文本的危险等级.敏感阈值的设置可根据的反馈识别结果进行调整,以提高敏感内容分级的准确率.因而,敏感阈值设置是影响信息过滤模型的关键因素,是评判敏感文本的危险等级的参考.具体值调整人工审查的原则,当检出的文本集合的危险评级普遍过低时,需降低φ1的值,增强对敏感内容过浅评判的程度;相反当危险评级普遍过高时,就要提高φ3的值,减弱过度评判的程度.彝文网页内容的敏感分级标准如表6所示. 表6 彝文网页内容的敏感分级标准表 综合以上讨论的彝文信息爬虫、彝文本分词以及敏感词决策树构建等技术,本研究进一步优化和开发了面向彝文网页舆情分析的敏感内容分级系统,设计了7个要素(标题、来源、时间、URL、类别、敏感词、内容),其中“敏感等级”项是关键性要素,用以标识危险级别,“敏感词”项指在文本中所有敏感词汇(中文和彝文).因而系统相比于本课题组开发的首款彝文敏感信息过滤系统,不仅可识别、标记和过滤彝文敏感词,还兼具敏感文本的危险分级,追踪敏感源的URL、时间等信息.彝文网页的敏感内容分级系统演示如图9所示. 由于彝文是特有的少数民族语言文字,因而实验结果评测依靠人工判别来完成.在敏感度计算中设置影响因子α=0.7,β=0.3,敏感阈值φ_1=1.5,φ_2=2,φ_3=2.5,运行本系统共识别出176篇彝文文档是包含敏感内容的,经过彝学专家的现场查看和危险评级打分,基本上有140篇文档检测和标记出包含敏感词,敏感词检测的准确率是80%;而有92篇危险评级是有误的,分级检测的准确率约84%.通过分析发现,主要是43篇“毒物污染”文档被分到“淫秽色情”,以及49篇非敏感文档被检测识别成不同的敏感评级,敏感文档的危险评级普遍被系统识别偏高,可能存在2个方面: 1)收集的敏感等级词库包含词汇量本身比较小,甚至有的敏感词类只有两位数量级,明显不足; 2)敏感文本的敏感度计算和敏感文本的评级标准中,实际上影响因子和敏感阈值的设置都会对危险评级产生影响. 本文依次对彝文信息获取、彝文文本分词、彝文词汇语料的构建、彝文敏感内容的检测、敏感文档的危险分级等模块展开彝文网页敏感内容分级系统的研究,综合这一系列彝文信息化技术成果,可为其他少数民族语言网络的舆情监测提供重要的理论支撑,并且本研究构建的彝文网页敏感内容分级系统在跨境民族语言的网络舆情监管中具有一定的示范作用.同时,本研究构建的彝-汉分类标注词库和彝-汉敏感分级词库,可作为彝文舆情研究领域的重要语料资源. 由于本文借鉴中文的方法,而彝文本身有些地方和中文还是有很大的区别,因而在彝文舆情分析领域还有待进一步研究.比如在未来工作中收集更多的敏感词汇库,以及改进和完善敏感内容的检测算法来提升彝文网页敏感内容分级系统的准确率.5.3 敏感词的搜索过滤
6 敏感文档的危险分级
6.1 敏感词的相对词频权重
6.2 敏感文本的敏感度计算

6.3 敏感文本的评级标准

7 彝文敏感过滤系统

8 结语
