基于PF_RING的高速网络数据捕获方法∗
2019-03-26吴克河王冬冬
吴克河 王冬冬
(华北电力大学控制与计算机工程学院 北京 102206)
1 引言
当前网络传输速度已经普遍达到10 Gbps,主干网速度甚至达到了40 Gbps,种类繁多的网络应用每天产生了海量网络数据,对网络数据进行数据挖掘、安全分析有着重要的学术和商业价值,这一切都离不开高性能的网络数据包捕获技术。目前网络数据包捕获的方式主要有两种:一是采用专用硬件实现,如Endace的DAG数据采集卡可以对40Gbps的网络数据进行高效捕获,效率高,并具备一定数据过滤和处理功能,但售价高昂,扩展性较差,应用不是很广泛[1~2];二是基于软件实现,目前比较成熟的技术有Netmap,PF_RING以及DPDK等,成本相对专有硬件较低,并只在普通网卡上就能实现,扩展性很强。
近年国内外对网络数据的捕获的研究多是应用Netmap、PF_RING或DPDK,结合网卡多队列、多线程、及无锁编程技术,设计与实现网络数据并行捕获与处理框架。随着硬件技术的发展,服务器CPU核心数可能是普通网卡队列的数量的几倍,仅仅基于网卡多队列进行并行数据捕获,并行处理的效率有限,并不能充分发挥服务器的性能优势。而且目前大多数框架适用于对网络数据进行捕获、统计以及分析,对于需要转发与发送数据的服务器来说并不适用。
本文在研究了各种网络数据捕获机制优劣的基础上,利用多线程、高并发无锁队列以及PF_RING网络数据捕获技术,设计出了能够充分利用服务器CPU多核心优势的高速数据并行处理框架。
2 网络数据包捕获技术
2.1 问题分析
传统Linux系统数据捕获过程如图1所示,数据从网卡到用户缓冲区的步骤为
1)首先网卡驱动程序将数据从网卡寄存器拷贝到内核为网卡分配的缓冲区(FIFO或Ring Buffer)中,这是第一次拷贝。
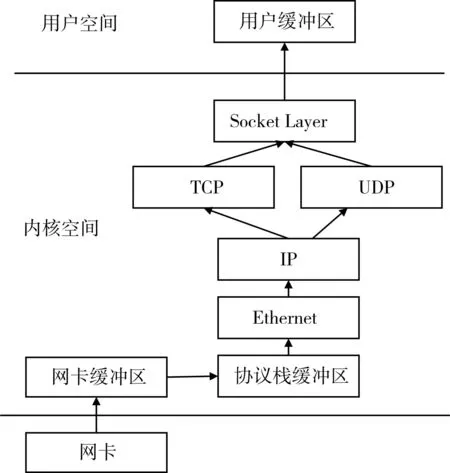
图1 传统Linux数据捕获过程
2)然后驱动程序发送中断请求给CPU,中断处理函数将网卡缓冲区的数据拷贝到内核专用数据结构(mbufs或skb_buffs)中[1],这是第二次拷贝。
3)内核协议栈根据数据包的头结构进行解析,将报头部分去除交由相应上层协议处理。
4)各层协议的部分处理完成以后,由Socket层的系统调用(recv或recvfrom)将数据从内核空间拷贝到用户空间,这里发生了第三次拷贝。
上述过程中影响捕获速度的因素主要有:
一是频繁的资源分配与释放。系统会为每一个到达的数据包动态分配一个存储数据的缓冲区(mbuf或skb_buffs)及其分组描述符,直到数据传递到用户态空间,才被释放。
二是过多的数据拷贝。除了第一次拷贝是将数据从网卡寄存器拷贝到网卡缓冲区以外,其他拷贝都是从内存中的一部分拷贝到内存中的另外一部分[3]。频繁的拷贝数据会占用带宽有限的总线,占用CPU周期,同时也会频繁刷新缓存,影响缓存命中率,进而增加处理时间。
三是频繁中断与上下文切换。每一个数据包到达网卡缓存后都会触发一次中断,以及一次从用户态到内核态的上下文切换。当数据包流量变大时,大量CPU时间被用于处理中断和上下文切换。同时由于硬中断的优先级比较高,致使其他进程无法获得CPU资源,接收缓冲区中数据包得不到及时处理,就会造成数据大量丢失[4]。
2.2 解决方法
针对以上因素,总结了目前高性能网络数据捕获技术中常用的提高捕获效率的技术。
1)预分配固定大小的数据包存储空间。消除每个数据包存储时动态分配内存导致的系统开销。
2)零拷贝,即减少数据拷贝次数。将网卡缓冲区、内核缓冲区以及用户缓冲区进行合并,网卡驱动程序以及用户应用程序使用同一共享缓冲空间进行数据操作,减少缓冲区之间的拷贝。
3)用户空间IO。完全绕过Linux内核,报文存储与处理工作都在用户空间完成,避免内核态与用户态上下文切换的开销。网卡驱动工作在用户态,避免因内核更新而频繁修改网卡驱动问题。
4)使用大内存页。主要优点是利用大内存页提高内存使用效率,通过增加页尺寸从而减少内存分页映射表的条目,大幅减少TLB旁路缓冲器的查询Miss,提高内存页检索效率[5]。
5)CPU亲和性。可以人工分配给CPU的每个核心要完成的任务,减少一个核心进行任务切换的开销,充分发挥CPU多核心的优势。
6)数据批处理。为了减少单个报文调用的开销,提供批量接收和发送数据包的功能。
2.3 技术对比
为了实现对网络数据的快速捕获。Netmap对原数据结构做了精简,并利用NIC环使用户应用可以调用API直接访问网卡缓冲区[5]。PF_RING利用DNA(Direct NIC Access,直接网卡访问)技术,使用户应用程序可以直接访问网卡的寄存器和缓冲区[7]。而DPDK主要利用了大内存页和用户空间IO 技术[8]。
从表1中可以看出各技术都满足10Gbps网络速度的要求,速度方面并没有明显差异。其中使用DPDK技术需要具备一定的硬件以及内核知识,故学习和开发周期较长[9]。Netmap相对PF_RING和DPDK未提供完善的API开发接口,开发工作较多[10~11]。所以在充分考虑性能以及时间的基础上,本论文应用PF_RING实现网络数据捕获框架。
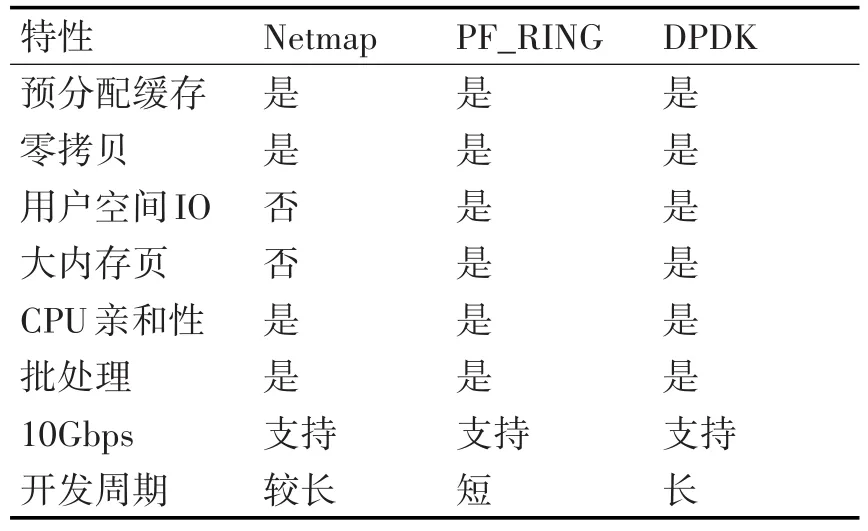
表1 网络数据捕获技术对比
3 无锁队列
虽然锁机制能够很好地解决多线程场景下数据同步问题,但系统开销比较大,无法满足高并发场景,故近年来开始对无锁数据结构进行研究[12]。
3.1 相关技术
无锁队列实现主要依赖的技术有:
1)CAS原子指令操作
CAS(Compare and Swap,比较并替换)原子指令,用来保障数据的一致性。指令有三个参数,当前内存值V、旧的预期值A、更新的值B,当且仅当预期值A和内存值V相同时,将内存值修改为B并返回 true,否则什么都不做,并返回false[13]。
2)内存屏障
执行运算的时候,每个CPU核心从内存读到各自的缓存中,结束后再从缓存更新到内存,这会引起线程间数据的不同步,故需要内存屏障强制把写缓冲区或高速缓存中的数据等写回主内存。主要分为读屏障和写屏障:读屏障可以让cache中的数据失效,强制重新从主内存加载数据;写屏障能使cache中的数据更新写入主内存。在实现valotitle关键字中就用到了内存屏障,从而保证线程A对此变量的修改,其他线程获取的值为最新的值。
3.2 实现分析
生产者head和tail两个变量,分别标识申请与发布的过程,且类型为volatile uint32_t。入队过程如图2所示,步骤如下:
1)申请过程。prod1和prod2同时入队,首先读取出队列头部head以及计算出入队后头部需要移动的位置next。由于prod1率先执行CAS将队列head进行更新,当prod2执行CAS更新队列head时,发现已被其他生产者改变,而CAS是一个原子操作,prod2意识到当前生产区已被其他生产者占据,就会根据新head值重新计算自己生产的位置。
2)入队过程。prod1和prod2可同时进行数据入队,提高了入队的效率。
3)发布过程。生产者生产结束,且在此之前的生产也都结束后,移动队列头部tail到实际生产的位置,来通知后面的生产者自己已经结束。如prod2结束时等到prod1完成后才进行tail的更新。
下面是上述过程的伪代码,其中head和tail都定义为volatile uint32_t类型,使得对数据的修改可以及时通知其他线程:
do{
head=queue->prod.head
next=prod.head+len;
判断是否有足够剩余空间;
success = CAS (queue->prod.head, head,next);
}while(unlikely(success==0));数据入队;
smp_wmb();//写内存屏障
while(unlikely(queue->prod.tail!=head){
pause();
}
queue->prod.tail=next;
出队的操作和入队列十分接近,把判断是否有剩余空间变为判断队列是否有数据,填入数据变成读取数据,smp_wmb()变成smp_rmb()读内存屏障即可。通过上述方法可以实现多生产者多消费者安全的高并发无锁队列。
4 高速数据捕获框架的设计
4.1 问题分析
本框架基于配电安全网关进行开发,其网络拓扑如图3所示,其主要功能为对配电终端进身份认证,以及转发认证成功后的配电终端与配电主站之间的业务数据。框架需要具备的功能主要有以下几点:
1)捕获主站与终端发送的数据;
2)根据数据内容做出处理;
3)转发主站与终端的数据,或向终端或主站发送自己的数据包,丢弃不合法的数据。
4.2 总体设计
设计目标:设计与完成具有通用性的基于PF_RING的高速网络数据处理框架,框架能够充分利用CPU的多核心优势,提供简单易用的API接口。主要适用的目标为部署在内外网安全边界的网关服务器。基本工作流程主要如图4所示。
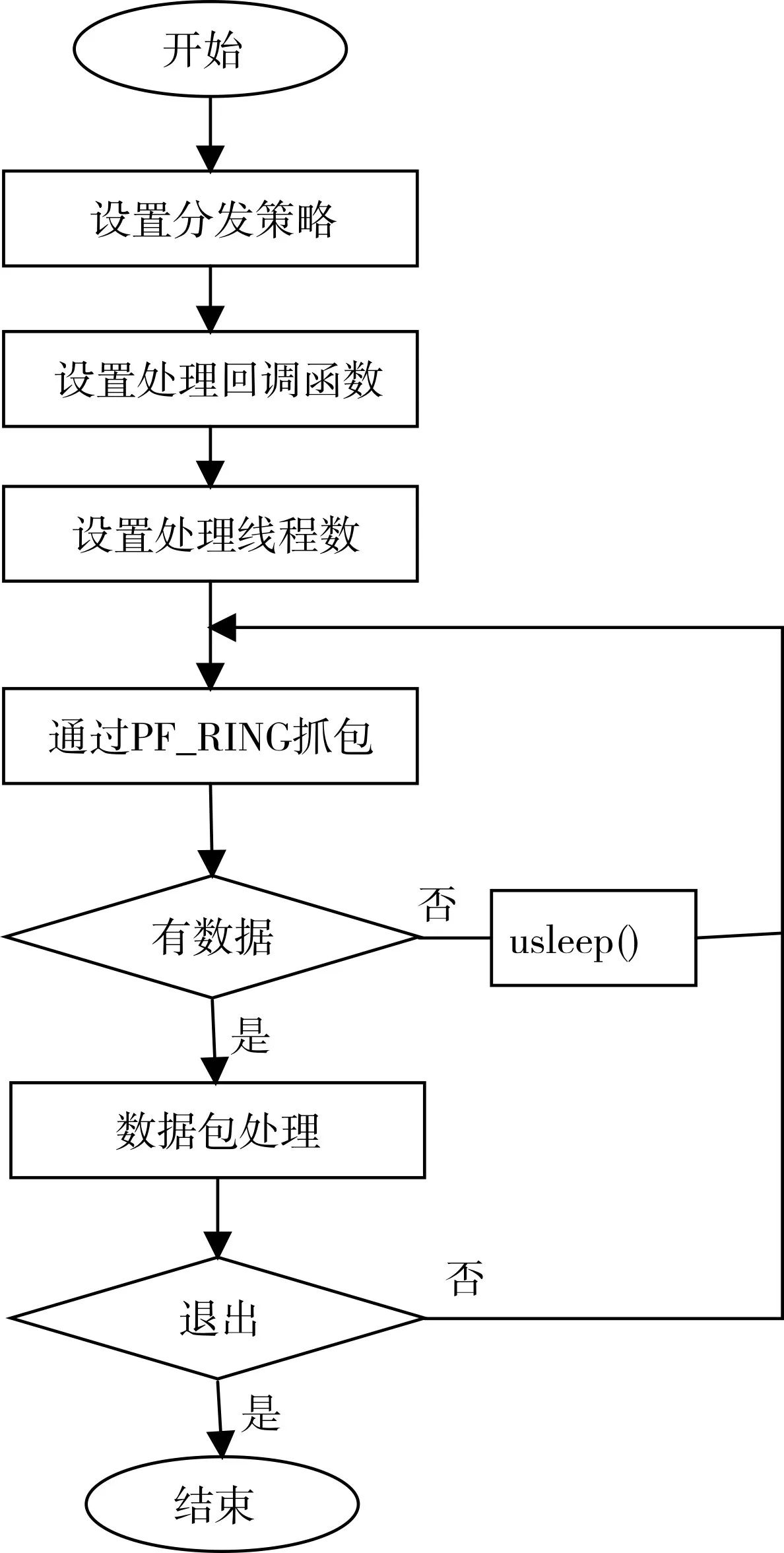
图4 配电网关总体处理流程
4.3 详细设计
4.3.1 整体结构
设计思想:数量应多于数据收发线程,多个线程同时进行数据处理,这样可以增加处理效率;将每个处理线程绑定到不同的CPU核上,充分发挥服务器多CPU核心的优势;处理过程中应尽量避免数据包的拷贝,在不同模块传递的应该是数据在缓冲景区的地址。
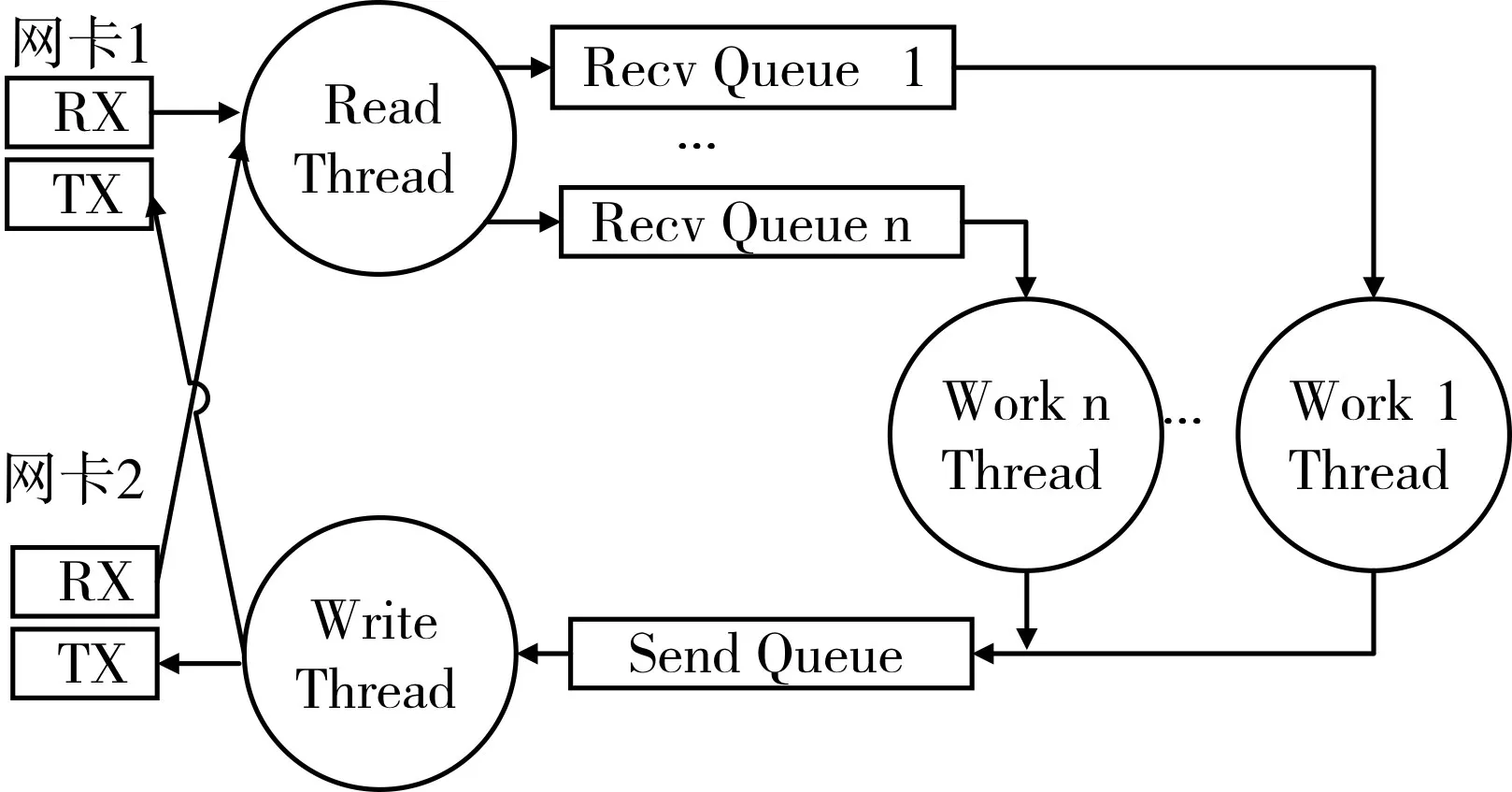
图5 基于PF_RING的数据收发框架
框架主要由以下几部分构成:
1)Read Thread:数据接收线程。负责读取网卡1和网卡2接收到的数据,即终端和主站发来的数据,并根据分发策略把数据添加到相应Recv Queue等待CPU处理。
2)Recv Queue:待处理队列。应用无锁队列实现。应用多个Recv Queue的优点是可以软件模拟网卡多队列,实现并行处理,并可根据上层应用的实际需求自定义处理线程的数量十分灵活。
3)Work Thread:数据包处理线程。从Recv Queue读取数据,调用数据处理接口对数据包报头的解析和处理。如果没有数据将调用usleep(),防止过度消耗CPU资源。
4)Send Queue:待发送队列。多线程同时向网卡同一TX队列发送数据会产生冲突,需要此队列最为发送数据的缓冲队列。该队列应用第3节实现的高并发无锁队列实现,在多消费者多生产者的情况下是安全的,所以其他非Work Thead线程也可以直接向该队列添加要发送的数据。
5)Send Thread:发送数据线程。从Send Queue中读取需要发送的数据进行发送。
4.3.2 细节分析
1)线程的绑定
其 中 Read Thread、Recv Queue以 及 Work Thread完成工作如图6所示,完成了数据的捕获与分发处理。为了充分发挥CPU多核的优势,将第一个CPU核心供操作系统使用,利用CPU亲和性使Read thread和Write Thread工作在接下来的两个CPU核心上,然后将Work Thread依次绑定到剩余CPU 核心[14]。
2)区分数据包来源
PF_RING应用pfring_zc_pkt_buff结构体来描述缓冲区中每个数据包的信息,其定义如下:
typedef struct{
uint16_t len; //数据包长度
u_nt16_t flags; //校验后标志
uint32_t hash; //网卡计算的hash值
pfring_zc_timespec ts;//时间戳
uchar user[];//数据
}pfring_zc_pkt_buff;
在Recv queue和Send Queue队列中存储的使存出每个缓冲区信息的pfring_zc_pkt_buff类型指针,而不是真正的数据,避免了数据处理中的拷贝。其中的user变量允许用户自己在原始数据头部插入自己的数据,但要在PR_RING初始化时作出声明。利用这个特性可以在数据包头部添加接收网卡与发送网卡的信息。
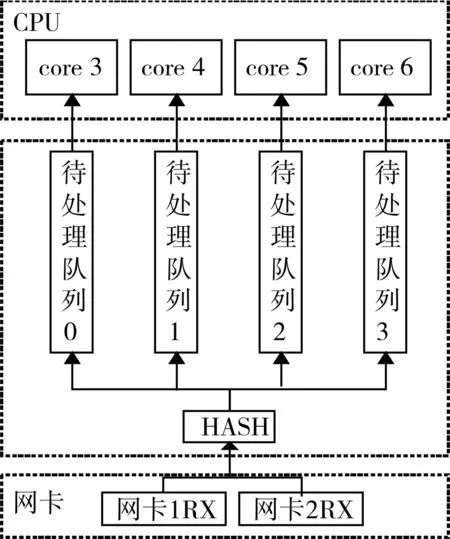
图6 数据的分发与处理
3)队列长度的设置
在初始化PF_RING时,会创建Ring Buffer(环形缓冲区)来存储网卡收到的数据,其长度为n,所以Recv Queue的长度应为2n,即能够缓存两个网卡收到的数据,相应的Send Queue的长度应为n乘以Work Thread的数量。
4.4 使用框架
为方便用户使用该框架,使用户不必关心具体的实现细节,设计与实现了应用接口,如下所示:
1)首先定义分配数据包和处理数据包回调函数接口,当接收到数据时会自动调用。
int hash_fun(const unsigned char*data,int data_len);
该接口可根据原始数据包内容和长度,计算Hash值并返回,根据该Hash值把数据分配给相应待处理队列。
void recv_fun(packet*pkt);
在该接口中,用户可根据pkt获取数的内容与长度,完成数据处理。
2)接着在程序中依次调用以下接口。
int init( hash_callback hash_fun,recv_callback recv_fun);
该接口完成分配接口与处理接口的注册。
device*open_device(const char*dev_name);
该接口完成初始化网口工作。
int dispatch(unsigned int thread_count);
该接口依据处理线程数初始化框架。
3)发送数据的接口
int send_packet(device*send_to,packet*pkt);
该接口用于转发从网卡收到的数据。
int send_data(device*send_to,const unsigned char*data,int data_len);
该接口用于发送服务器自身需要发送的数据。
4.5 分发策略
此小节主要讨论的是如何将数据包分配给各待处理队列。需要实现如下接口。
int hash_fun(const unsigned char*data,int data_len);
基本分配策略的实现如下:
1)平均分配。把每一个收到的数据包依次分给每一个Recv Queue。定义全局变量static int r=0,函数体的实现如下:
return r++;
这种方式实现简单,效率高,但同一个TCP连接的数据数据包会分配到不同Worker Thread进行处理,需要线程之间进行通信才可以准确处理数据包乱序、重发等问题。
2)根据<源IP地址、目的IP地址、源端口、目的端口>四元组计算HASH值。函数体的具体实现如下:
int hash=0,i=0;
for(i=26;i<38;i++){
hash^=data[i];
}
return hash;
因为异或运算满足结合律和交换律,且具有较好的随机性能以及较低的计算复杂性[15~16],同时四元组在相同两台主机的不同传输方向上只是字节顺序不同,且在原始数据中位置相对固定,一般存储在原始数据的26到37字节,所以HASH算法可以设计为对四元组进行逐字节异或,就能使相同主机之间的IP数据或相同TCP连接数据就会交由同一个Worker Thread进行处理。这种方式会影响数据的接收与处理速度。
3)根据<源IP地址、目的IP地址>二元组进行分配。由于一个配电终端和配电主站之前的TCP连接只有一个,故可以应用IP二元组来对TCP数据进行分组,实现方式同上,i的范围变为26到33即可。此种方式适用于特定场景。
5 实验分析
在Linux系统上实现了这个高性能数据收发框架,使用了PF_RING ZC库版本为6.4.1。测试中使用zsend、zcount作为数据发送和接收的工具。用三台服务器模拟数据发送服务器、配电主站以及数据接收服务器。服务器系统均为Centos6.9,硬件配置:CPU:Intel(R)Xeon(R)CPU E3-1231 v3;内存,16GB;网卡,Intel 82599ES,最大传输速率 10Gbps。测试拓扑如图7所示。
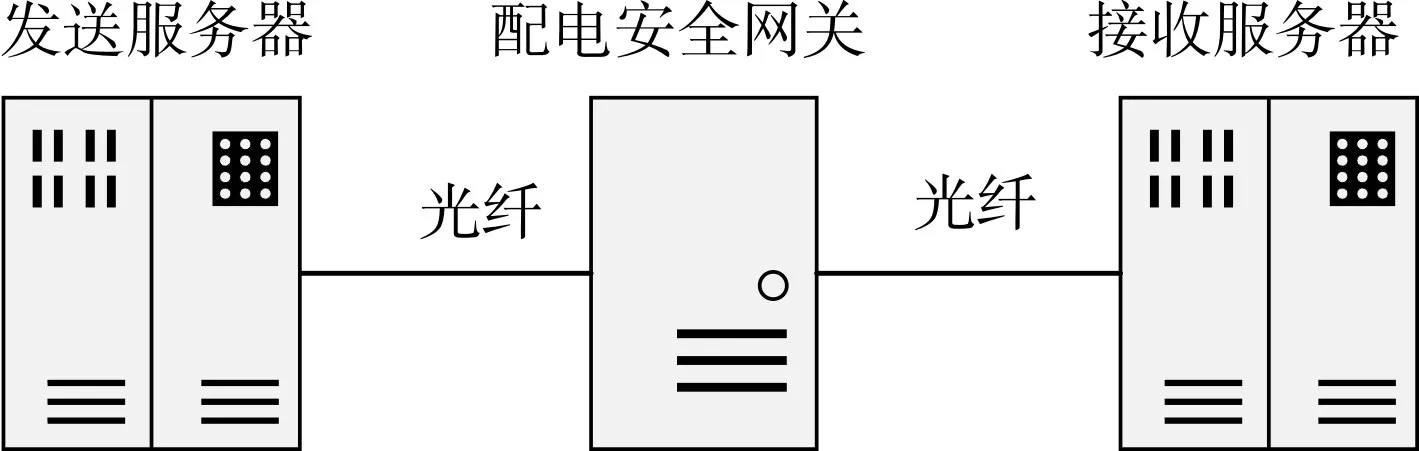
图7 测试网络拓扑
服务器CPU共有8个逻辑线程,PF_RING_NEW代表了本文设计的框架,共初始化了5个Recv Queue和Work Thread,采用平均分配策略。PF_RING、Netmap以及DPDK为应用官方接口实现的只具有数据转发功能的工具软件。测试过程如下:
1)数据传输速率从1Gbps逐步增加到10Gbps,数据包大小固定为128B,测试结果如图8所示。
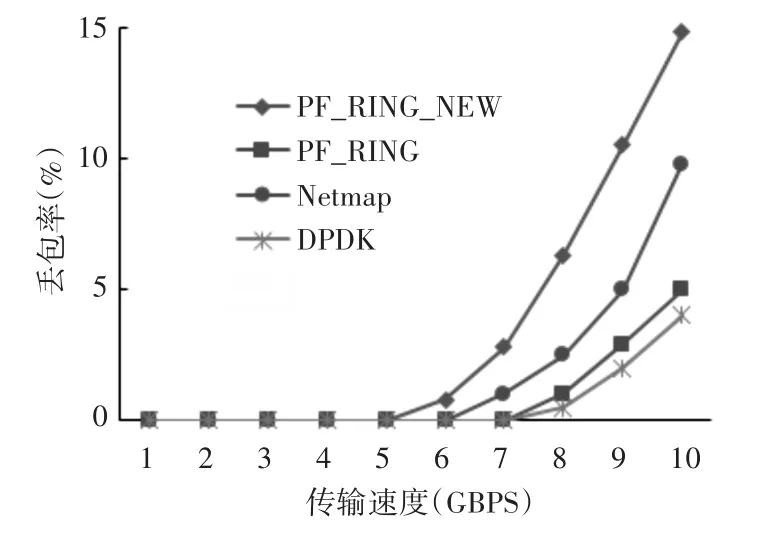
图8 随传输速率增大的丢包率
2)数据包大小从64B逐步增加到768B,数据传输速率固定为8Gbps,测试结果如图9所示。
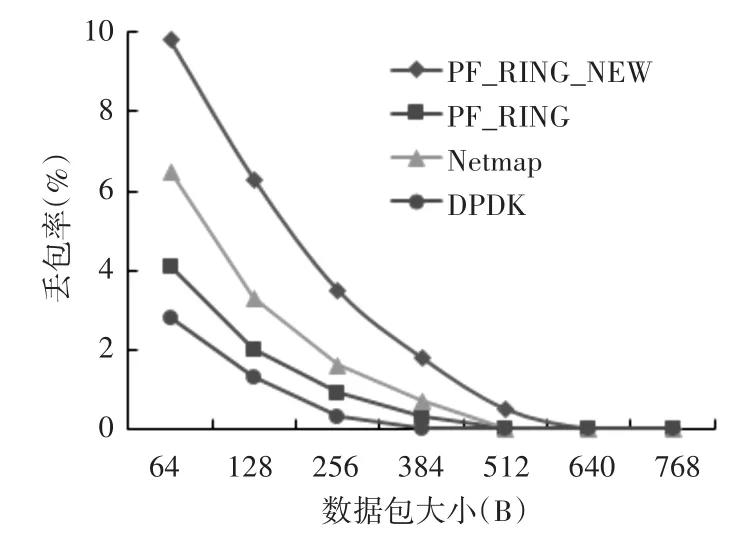
图9 随数据包长度增大的丢包率
由测试结果可以看出,应用PF_RING设计与实现的数据收发框架,在捕获和传输不同速率或不同长度的数据包时丢包率较低,能够满足服务器在高速网络环境的需求。但对比于只进行数据转发的PF_RING、Netmap与DPDK来说有所增加,主要是因为数据在服务器上需要经过待处理队列以及待发送队列后才能进行发送。
6 结语
本文首先介绍了Linux传统数据包捕获机制存在的主要瓶颈,接着总结了目前流行的捕获技术解决这些问题的方法,对各技术的特点做了全面对比以及分析。最后结合无锁队列设计了一种基于PF_RING的高速并行网络数据包处理框架,对实现的细节、框架的使用以及分发策略的实现做了全面阐述。经过初步的实验验证,该数据收发框架在不同传输速率和不同数据包长度情况下的丢包率满足服务器的需求。
