基于深度学习的回环检测算法研究∗
2019-03-26罗顺心张孙杰
罗顺心 张孙杰
(上海理工大学光电信息与计算机学院 上海 200093)
1 引言
21世纪的今天,机器人渐渐的浮现在人们的视线中,它给人们带来了更多的便利。例如扫地机器 人 ,它 通 过 SLAM[1](Simultaneous Localization and Mapping)系统构建出一个房间的地图,同时定位出自己在房间中的位置,然后在根据SLAM系统构建的地图规划出自己清扫的路径,打扫整个房间。同时它也会计算自己剩余的电量,当电量低到一定的时候,根据建立的地图,自动导航到充电的位置,不需要人参与操作。又如餐厅机器人,它也是通过SLAM系统构建出地图,然后根据路径规划将餐点送到需要的客人附近。当然,生活中还有很多机器人的例子,我们同样可以看出在机器人的使用中,SLAM扮演着一个不可缺少的角色。近些年,传感器的发展也越来越精密和多样化,尤其是摄像头的发展,给SLAM系统带来了重要的改革。例如单目摄像头、双目摄像头、Kinect、RGBD相机等,我们把基于摄像头的SLAM系统称为V-SLAM[2~4](Visual Simultaneous Localiz-ation and Mapping)。
在V-SLAM系统中,回环检测[5](Loop Closure Detection,LCD)一直是一个重要的环节,它能够使得机器人更加准确地去识别自己曾经去过的位置,通过进行辨识过去的位置,检测回环来解决位姿的漂移问题。当判断当前位置是曾经到过的地方,那么机器人记录的轨迹就会形成了一个局部的回环,使用G2O[6]来对位姿进行重新修正,可以减少机器人的积累误差,使得地图的建立更加准确。传统的视觉 SLAM 中回环检测的方法视觉词带模型[5,7~8](Bag of Words,BOW),它通过收集大量的图片,提取图片中的特征点,然后通过K-means[9]的方法聚类,把特征点分成K个类别,建立一个特征点集合的字典。将一张图片输入,提取图片的特征点,然后查阅字典,该特征点属于哪一类别,以向量的形式的输出。它使用字典中的聚类特征,描述图像,进而判断两张图片的相似程度。人是根据比对图片中出现的物体、颜色、背景等诸多因素判断出是否是曾经经过的地方。那么机器人应该也能够像人一样,摆脱像素点,从更高的层次去实现回环检测。深度学习[10](Deep Learning)的发展越来越火热,它的快速发展为我们的这一想法提供了实现的可能性。通过使用深层的卷积神经网路[11](Convolutional Neural Network)提取图像更高层次的特征信息,判断图片的相似程度。在本篇文章中,基于深层卷积神经网络实现了回环检测的,它拥有着更高的准确率,更好的实时性。
2 深度学习回环检测算法原理
本模块主要是实现回环检测功能。回环检测的实现主要由SSD[12](Single Shot Detector)网络、特征向量预处理、判断回环三个部分组成。SSD网络是深度学习中实现目标检测[13~14]的方法,它有着非常好的准确率,同时在实时性方面也非常出众。本文中使用SSD网络作为特片特征的提取。特征向量预处理则是把通过SSD网络提取出来的特征信息,进行筛选,大大提高了回环检测判断的实时性。回环检测的判断则是通过计算图片之间相似度的得分,判断是否有检测到回环。算法流程图如图1所示。
2.1 SSD网络原理
SSD是一种用于物体检测(Object De-tection)的方法,它能够预测输入图片中的物体,以及物体所在的位置。我们利用SSD网络,来提取图片的特征信息,利用物体的类别建立一个检测回环的特征向量。
SSD的网络(如图2所示),它的输入是300*300 的图片,使用了 VGG-16[15]的网络框架作为基础,将两个全连接层FC6和FC7转化为卷积层conv6和conv7,当然,你也可以自己去更改使用Googlenet[16]、Alexnet[17]等作为基础网络框架。然后在VGG-16的基础网络之后添加了几个辅助的网络结构,产生了多尺度特征图检测、检测的卷积预测器,默认框与宽高比三个部分。
多尺度特征图检测:从SSD网络中可以看到在VGG-16之后使用卷积网络添加了几个辅助网络结构,产生了一系列的特征图,这些特征图随着网络变深,特征图逐渐的尺寸也逐渐减小。例如38*38、19*19、10*10、5*5等都是产生的不同尺寸的特征图。
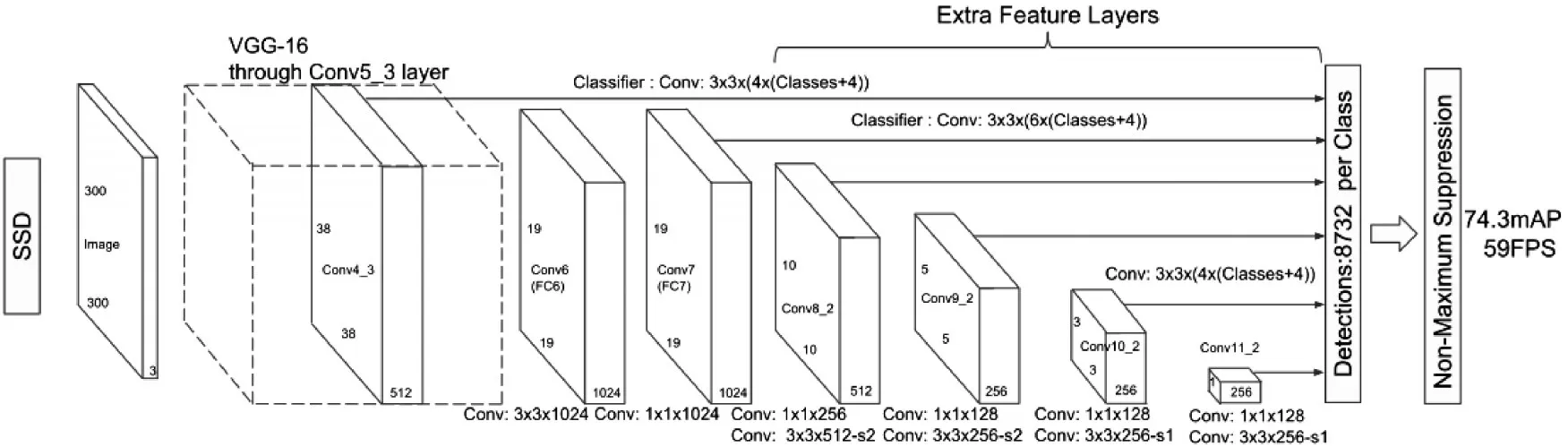
图2 SSD网络
检测的卷积预测器:由于在基础网络之后,又生成了不同尺寸的特征图,这些特征图通过使用卷积预测器生成一组固定的预测集合。例如在5*5的特征图,先对该特征图进行归一化,然后使用了6*(classes+4)个3*3卷积核对该特征图进行卷积,得到一个5*5*(6*(classes+4))Tensor,为什么使用该数量的卷积核数呢?因为要使得输出的结果是我们想要得到的一个矩阵形式,矩阵的宽和高等于特征图的宽和高,可以理解为将输入的图片分成了5*5的栅格,矩阵的深度代表的是6*(classes+4),代表着每一个栅格中输出6个边界框,每一个边界框中包含预类别概率大小,以及该边界框相对于默认边界框[16](Default box)的位置偏移量(位置的偏移量由4个参数组成),同样的在38*38、19*19、10*10、3*3、1*1的特征图中都进行了卷积操作,得到上述所需要的矩阵。
默认边界框与宽高比:每一个边界框相对于其对应特征图中的位置都是固定的,在每一个特征图中,要预测得到的边界框与默认边界框之间的偏移值,以及每一个边界框中包含物体的置信度得分,在同一个栅格中假设有k个默认的边界框,那么在该特征图中就需要k*(C+4)个卷积预测器,对于m*m大小的特征图,就会产生(c+4)*k*m*m个输出结果。对于每一个默认边界框它具有如下规定,它的宽高比使用如下公式:
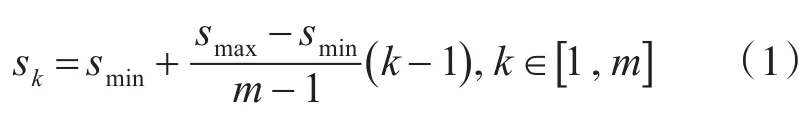
其中,smin取值为0.2,smax取值为0.95,m是特征图的个数,k代表的是第几个特征图(最底层的特征图为k=1,最高层的特征图为k=m)在最底层的特征图的尺度是0.2,最高层的特征图尺度是0.95,使用不同的宽高比得到每一个默认边界框的宽度和高度:

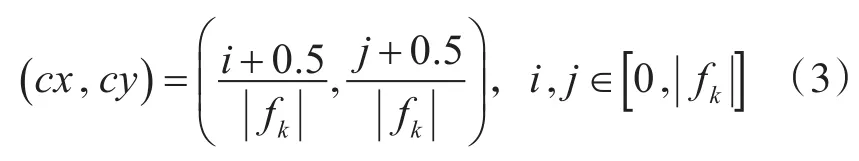
其中 ||fk表示第K个特征图的尺寸大小(可以理解为默认边界框的中心点对应特征图映射在图像栅格的中心点)。
SSD的损失函数:SSD的损失函数主要由两个部分组成,一个是物体类别的置信度分数,一个是物体的位置,其中对于置信度采用的是Softmax Loss函数,物体的位置回归采用的是Smooth L1 Loss函数。Loss函数如下:(根据 α参数调节confidence loss和location loss之间的权重,默认设置为1,指的是预测位置,g指的是真实人为标注的位置)
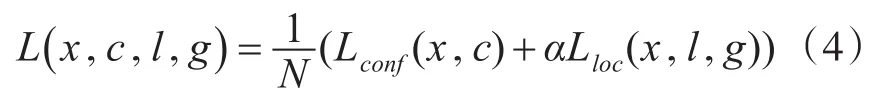
位置回归Loss函数:
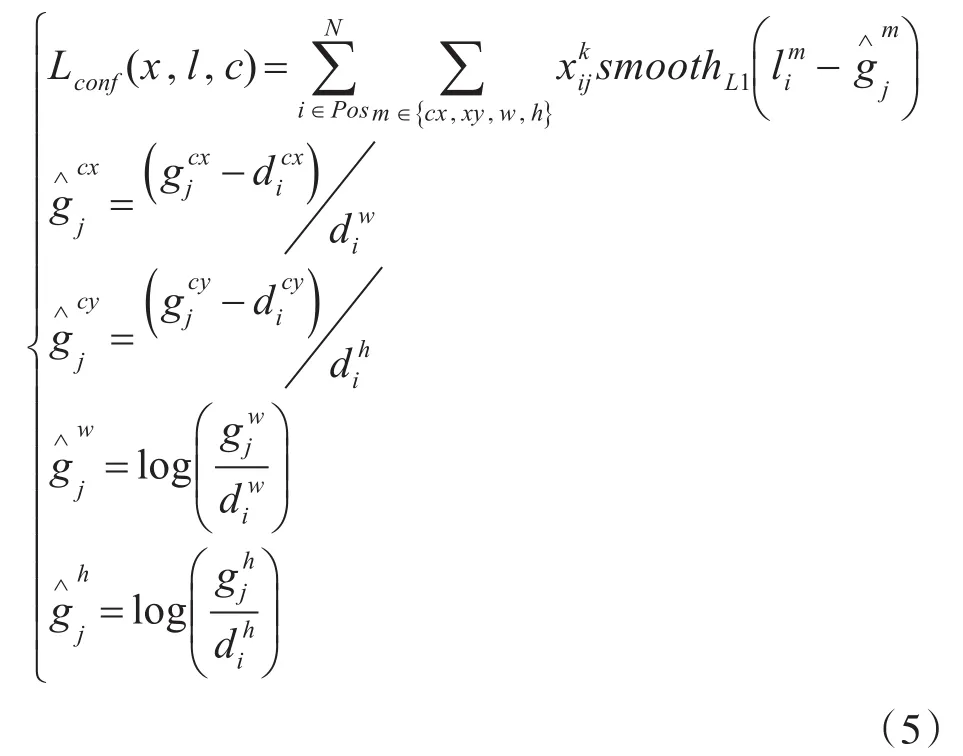
物体置信度Loss函数:
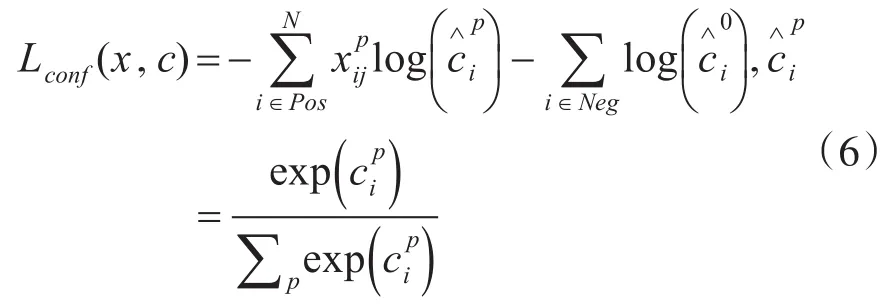
其中N指的是正样本数(正样本:首先选出默认边界框与真实边界框(ground true box)的 IOU[18~19](Intersection over Union)最大的默认边界框作为正样本,然后将剩余的未匹配的IOU>0.5作为正样本,剩余的为负样本,IOU指的就是交并比),xpij∈当=1时,指的就是第i个默认边界框与类别为p的第j个真实边界框相匹配,即第i个默认边界框为正样本。反之,不匹配则为0。d指的是默认框的位置,g代表的是人为标注的真实框的位置。
由于SSD网络在预测的时候对于同一个物体拥有很多个边界框,所以使用非极大值抑制[20~21](Non Maximum Suppression,NMS)的方法,筛选出最优的边界框。首先对预测的物体进行归类,对每一类都进行下面的操作,每从所有预测的中选出置信度最高的,剔除掉剩余的边界框与其IOU>0.5的边界框,在剩余的边界框中再次选择最后置信度的边界框,重复上面的操作,直到所有边界框都被执行。
2.2 特征向量化
在通过SSD网络之后,将会得到物体的位置信息,数量信息以及类别信息,把它以{“类别”,“位置”}的向量形式保存,其中类别的特征向量表示形式如图3,是n*1的向量。在图3中,类别特征向量的每个方格即为对应的种类,方格中的数值指的是该种类物品的个数,如果输入的图像中没有该物体,那么该方格中的数值为0。第二列为“位置”特征向量,如果输入的图像中含有A类物品有3个,那么该第一行的位置特征向量就保存了三个该种类物体的位置,物体的位置是由包裹的物体的边界框组成,因此每一类物体的位置是以[xmin,ymin,xmax,ymax]的形式保存的,xmin、ymin指的是物体边界框的左下角像素坐标,xmax、ymax指物体边界框的右上角像素坐标。所以位置的表示形式:Location=[xmin,ymin,xmax,ymax]。

图3 向量化示意图
在图3中,左边的白色大框表示一张图片,A、B、C、D、E、G分别为该图中所包含的物体,右图为图片经过向量化之的形式,A~G为物体的不同类别(这里根据情况建立字典中类别的种类),第二列为每个对应种类在该图片中的数量,第二列称为类特征向量,第三列称为位置特征向量,在图3中物体的位置分别用PA1、PA2、PB1、……表示,图片中每个种类包含几个物体,那么在对应的位置特征向量的行中就会有几个位置保存。
在向量化的过程中,由于一张图片中可能存在多个相同种类的物体,因此在位置特征向量中需要对物体的位置顺序统一放置,使用像素距离(如图4)进行统一约束。通过图4,利用物体位置的左上角像素坐标 [xmin,ymax],获得物体到像素坐标系原点的距离,通过使用物体到原点的距离对物体的位置进行排序。
在图4中,A,B,C指的是不同种类的物体,PA1,PA2,PA3分别为三个A类物体的位置。利用PA1,PA2,PA3的左上角像素坐标,分别算出对应的三个物体到原点的距离,因此,得PA1<PA2<PA3到原点得距离,所以在对应得位置向量中分别以PA1、PA2、PA3得顺序保存。
2.3 判断回环
在视觉SLAM中,机器人不断通过移动,拍取了一帧帧的关键帧,每拍取得一帧关键帧,就使用SSD网络,提取所需要的特征,然后对其向量化得到对应的向量化特征向量,回环得判断主要是把当前帧图片与历史帧得图片进行比较,而本文中,则是通过把图片通过向化描述,因此,即是把当前特征向量和之前所保存的关键帧的特征向量进行比较,判断是否回环。回环检测流程图如图5。主要包含以下四个步骤:
步骤一:首先对历史帧图片进行预处理,在视觉SLAM中,由于拥有着大量的历史关键帧对应得特征向量,找到回环变得相当繁琐,本文采取了预处理得方式,对大量的历史帧进行简单判断是否有回环的可能性,大大提高了回环检测得实时性。计算图片中所包含的物体的数量总和:classes_num=然后对当前帧和历史帧的所包含的物体数量总和进行判断,即判断classes_num 1是否等于classes_num 2,如果相等,则执行第二步,如果不相等,则与下一个历史帧重新执行本步骤。
步骤二:在第一步成立的条件下,第二步也是对历史帧在进行回环判断得时候进行预处理,通过两次简单的预处理,排除了大量的历史关键帧,大大提高了判断回环检测的实时性。在第一步成立的条件下,判断当前帧特征向量和历史帧特征向量中每一种类别的数量是否相等,用 f表示,即:,n代表的是类别数,C1代表当前图片的类别特征向量,C2代表输入得历史帧的类别特征向量。若 f等于0,则表示当前帧和历史帧中中每一种类的数量相等,若不为0,则对下一个历史帧重新执行第一步。
步骤三:通过前面两步的预处理之后,得到了有可能是回环的关键帧,将该帧与当前帧进行相比较,计算两帧的相似度:

Areaij即为第i个种类第j个物体的区域面积,Area1表示当前帧的区域面积,Area1表示历史帧的区域面积。为第i个种类第j个物体的像素坐标。 p为计算出的两张图片相似程度,取值范围为 p∈[0,1]。
步骤四:通过步骤三,得到当前帧和历史帧的相似程度P,判断是否P≥相似度阈值,若为真,则检测到回环。若为假,则没有检测到回环,对下一个历史帧执行步骤一。相似度阈值是一个经验值,由于本方法得到的结果相对准确,因此可以适当地降低阈值,增大现实生活中存在的有各种环境因素导致的误差。
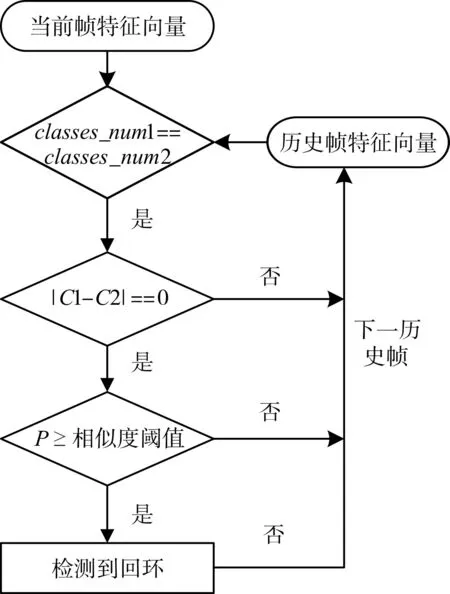
图5 判断回环流程图
3 实验结果
在本实验中,使用的环境是基于Ubuntu16.04系统,GPU为英伟达GTX1080,使用caffe的深度学习框架,搭建SSD网络环境。SSD的网络使用的是COCO的训练集和训练的权重,没有针对性的对本文中所建立的字典进行单独训练,所以权重参数并不是最优的,但是已经达到到了非常不错的效果。如果想要获得更好的效果,可以重新建立更合适的字典特征,重新训练SSD网络的权重,以达到更好的判断回环的效果。
如图6所示,图(a)和图(b)为同一时刻在相同的位置拍摄的两张图片,图(c)为与图(a)和图(b)在不同的光线下拍摄的图片。

图6 实验数据图
通过SSD网络获取如下数据:

表1 SSD网络获取的图(a)数据

表2 SSD网络获取的图(b)数据

表3 SSD网络获取的图(c)数据
通过SSD网络,提取特征数据,计算相似度。
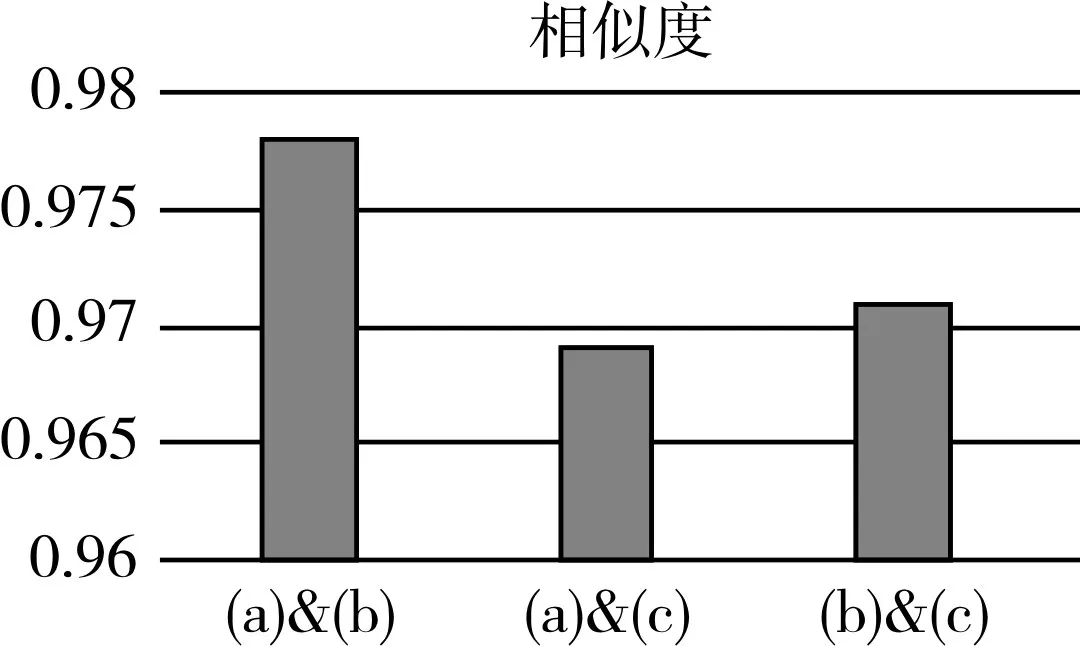
图7 比较相似度
根据上述图表,得到了图7(a)、(b)、(c)的描述向量以及相似度情况:图(a)和图(b)相似度为0.97,图(a)和图(c)的相似度为0.97,图(b)和图(c)的相似度为0.97。通过实验,我们可以看出,当移动机器人在移动过程中,到达曾经经过的位置时,能够判断出回环检测,且判断的相似度为高达98%。根据图(a)与图(c)、图(b)与图(c)的相似度图表中,可以看出在不同的光线下都能准确地识别出回环,相似度高达97%,说明光线对该方法检测回环的影响不大,能够在光线变化的环境中仍能非常好地检测出回环。
4 结语
本文使用了基于图像的方式,解决了移动机器人在移动过程中产生的漂移问题。提出了基于深度学习的方法实现回环检测。使用SSD的卷积神经网络来提取图片的特征,然后基于提取的特征,对图片使用向量化描述,通过两次预处理,能够筛选掉大量的图片,大大提高了回环判断的实时性,最后通过IOU的方法,对两张图片的相似度进行计算,判断两张图片的相似度,实现回环检测。
