一种结构和语义兼顾的综合分析思想在复句依存句法分析中的运用∗
2019-03-26黄文灿胡金柱
李 源 黄文灿 胡金柱,2
(1.华中师范大学计算机科学系 武汉 430070)(2.华中师范大学语言与语言教育研究中心 武汉 430070)
1 引言
近些年来,从中文信息处理的角度下探讨建立现代汉语依存关系的层次体系的研究过程中,对于依存关系的普遍性的这一特点认识越来越深刻,即依存现象普遍存在于汉语的词汇(合成词)、短语、单句、复句直到句群的各级能够独立运用的语言单位之中[1]。目前该体系在复句上的具体任务就是构建复句依存关系层次体系,现阶段对构建复句依存关系层次体系的研究,可划分为基于关系词搭配[2]和基于语料统计的决策式分析[3]两种。但二者主要区别在于分析分句内成分间的依存关系的手段不同。
基于关系词搭配的研究方法在分句内成分间的依存关系的确定上,多以哈工大社会计算与信息检索研究中心研发的“语言技术平台(LTP)[4]”为基础的“语言云”在单句依存句法分析上的优势,直接通过其提供的单句句法分析器来获取分句内成分间的依存关系。而基于语料统计的决策式分析的研究方法则改进了MaltParser句法分析器中关于Niver的Arc-eager算法,以解决对动宾与介宾等右依存情况下的过早规约问题[5]。但二者在分析复句中分句内成分间依存关系时都是从分析语法成分间的关系出发,并通过句子内词与词之间的依存关系来揭示句子的句法结构,但容易忽略语言结构的层次,导致在语义理解上有明显的缺陷。
鉴于上述的缺陷,本文从汉语语法在分析句子的基本方法理论上的自身实用性特点入手,将分析句子的基本方法中的综合分析法[6]的思想引入到复句中分句内成分间依存关系界定中,提出了一种适用于解决由于句子语法环境复杂导致的语义理解缺陷问题的汉语依存句法分析方法,并以汉语结构类型模板为桥梁,得到结构和语义兼顾的依存关系分析结果。实验结果表明该方法能有效提升依存关系界定的性能,在与传统的分析方法相比较时,具有一定的优势。
2 汉语句子综合分析法的提出
汉语句子综合分析法主要是针对传统的分析句子基本方法各自存在的缺陷而提出的,其中传统的分析句子基本方法主要包括句子成分分析法和句子层次分析法,再逐步发展到把这两种分析方法结合起来,取长补短,形成“综合分析法”[6]。
2.1 句子成分分析法
句子成分分析法又称为中心词分析法,对中国的语言教学产生了深远的影响。它的要点就是把构成句子的成分分为主谓宾定状补这六种,将分析句子的过程形式化为说明句子成分的搭配情况的流程。分析步骤:第一步找到句子的主语和谓语,然后再把其他连带成分逐个加上去。例如:
他的腿颤颤地发抖。(例句1)
中心词是“腿”和“发抖”,其中“腿”是主语,“发抖”是谓语。“他的”是“腿”的定语,“颤颤地”是“发抖”的状语。该方法能够促进句子的语义理解,但句子成分分析法最大的不足就是不重视语言结构的层次。例如,在区分以下两个句子时显得无能为力:
这位员工的提议很棒!(例句2)
这项员工的提议很棒!(例句3)
中心词分析法对这两个句子的分析结果均是:定语——定语——主语——状语——谓语;但这两个句子的层次不同,语义上也有区别。
2.2 句子层次分析法
在讨论层次分析法之前,首先要了解汉语的结构类型这一概念。汉语句法的不同平面(词、短语、句子)基本上由偏正结构、兼语结构、述补结构和联合结构等十一种结构组成[6],这里的结构反映的是语言结构的层次性,汉语的结构类型就是这十一种结构在不同平面下的集合。句子层次分析法又叫“二分法”,要点是把每层的语言片段一分为二,一直分到不可再分为止。例如,“这位员工的提议”和“这项员工的提议”的层次就不同。
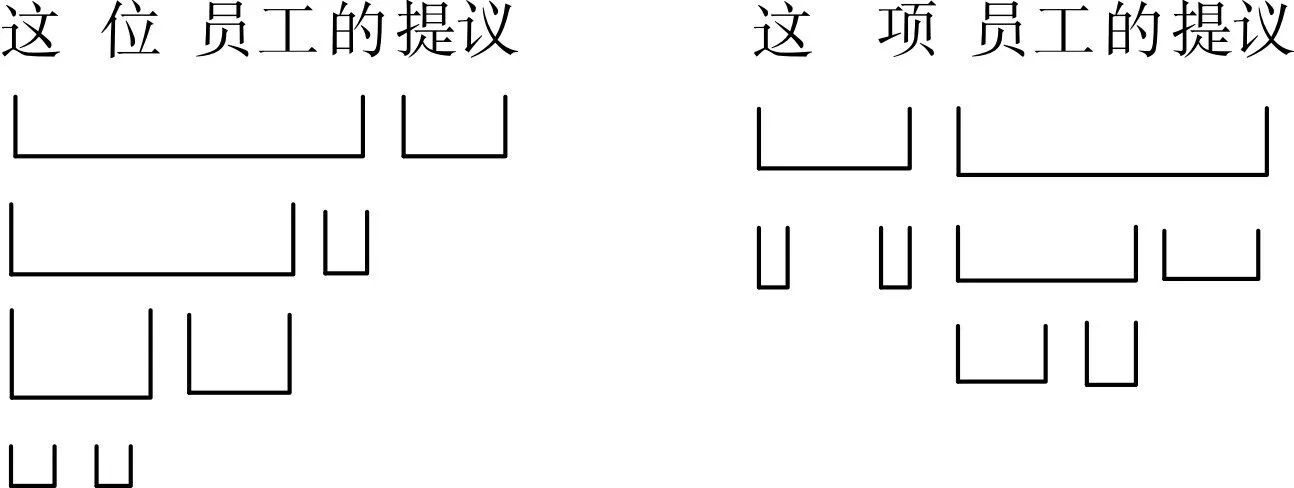
图1 “这位员工的提议”和“这项员工的提议”的层次分析
由上述图1的分析可知,“这位员工的提议”先分成“这位员工的”和“提议”两个直接成分;而“这项员工的提议”则先分为“这项”和“员工的提议”两个直接成分,然后逐层分析下去,一直分析到词为止。这种分析方法能够简洁明了地把句子结构显示出来,特别在分析多义的短语和句子时表现突出。例如:
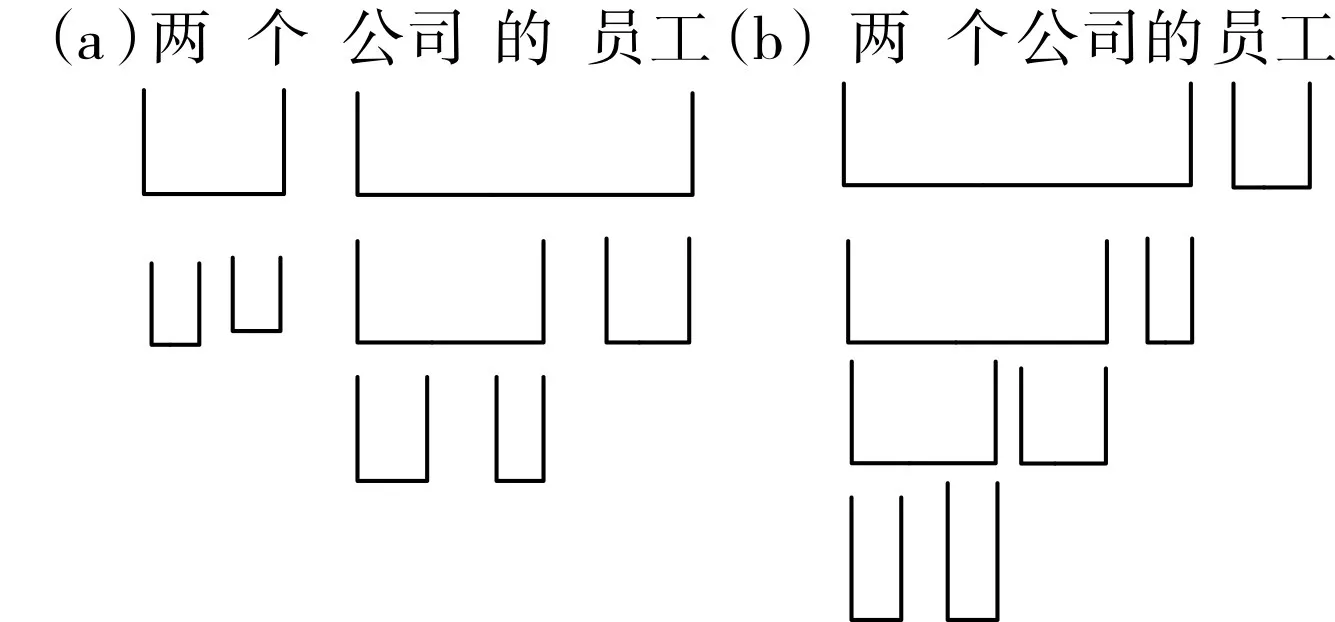
图2 “两家公司的员工”的层次分析
但是,层次分析法也有必要汲取句子成分分析法的优点,因为它并没有将直接成分间的结构关系显现出来。例如:分析“烤羊肉”时可以出现层次相同,但直接成分间的结构关系不同的情况。
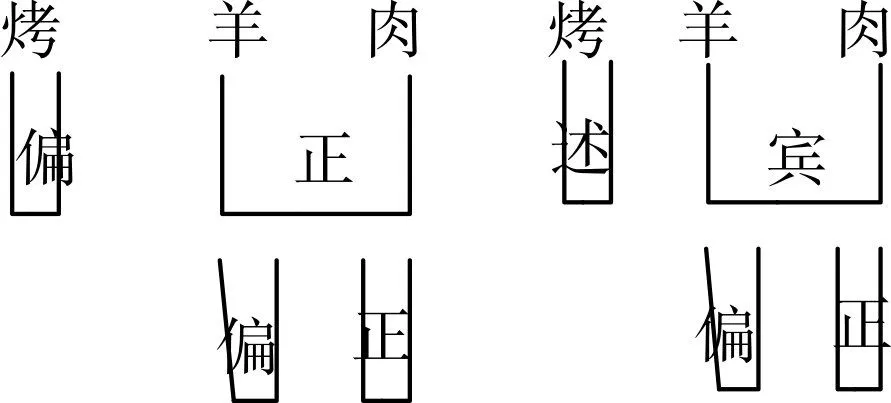
图3 “烤羊肉”中直接成分间结构关系
由上图可知:当“烤羊肉”成为偏正式名词短语时,表示一种食物;而当“烤羊肉”成为述补式动词短语时,表示一个动作。
2.3 句子“综合分析法”
针对传统的两种句子分析方法均有一定的长处和不足的情况,有学者指出只要某种分析法有利于解释复杂的语言现象,并且这种方法更简便、更系统、更符合汉语的特点,该方法就应该被采用,可以综合采用层次分析法和成分分析法的一些长处,并定名为“综合分析法”[6]。该方法的要点是先划分出主语和谓语两大直接成分,再层层解剖出由述语和宾语,述语和补语,状语和中心语,定语和中心语分别组成的述宾结构、述补结构、偏正结构,同时又都可以切分为处于不同层次的直接成分。例如:
同学们的陪伴和帮助渐渐增强了小明走出阴影的决心和信心。(例句4)
下面是它的分析图:
总而言之,综合分析法是根据汉语自身特点形成的特有的分析方法,带有明显的成分分析法的印记又注重语言结构层次,对于汉语句法分析有重要的指导意义。
3 引入综合分析法的思想的汉语依存句法分析方法
本文中复句分句中各成分间的依存关系的初步确定将直接通过语言云LTP的单句依存句法分析器分析得到,再经过本文提出的汉语结构类型模板转换后得到兼顾语义和结构的依存句法分析结果。
3.1 汉语结构类型模板
汉语结构类型模板作为将综合分析法思想与依存句法分析相结合的桥梁,它由一系列的与汉语结构类型相关的转换规则组成。鉴于与汉语结构类型关系密切,将其取名为“汉语结构类型模板”,考虑到依存语法将谓语作为句法分析树的根节点的特性[7]以及作为依存语法的形式化描述的五条公理约束[8],该模板内目前包含了4条精心设计的转换规则。
下面详细介绍该模板内目前包含的4条转换规则。特别说明:下面所有的转换规则图的左边是语言云LTP对单句依存句法分析结果,右边是根据与图中粗体加黑的依存相似子树匹配后的转换结果;这里除了使用语言云LTP上的句法分析依存关系标注集外,转换后添加的新依存关系类型参考了相关文献[1]中提到的依存关系类型。
规则1:偏正结构转换规则
偏正结构又可以更细一步划分为定中结构、状中结构等结构。规则1.1和1.2分别是针对定中结构和状中结构的。
规则1.1:定中结构转换规则
如图5所示,例句“他是镇压人民的刽子手”中“镇压人民的刽子手”这种定中结构没有在现行的单句依存句法分析中得到更好的处理,先分析主干“他是刽子手”才能体现出句子成分分析法提纲挈领的优点,再去分析“镇压人民的刽子手”内部的层次,体现了层次分析法层次分明的优点,即是引入了综合分析法的思想进行句法分析来达到促进句子的语义和结构兼顾的效果。
规则1.2:状中结构转换规则
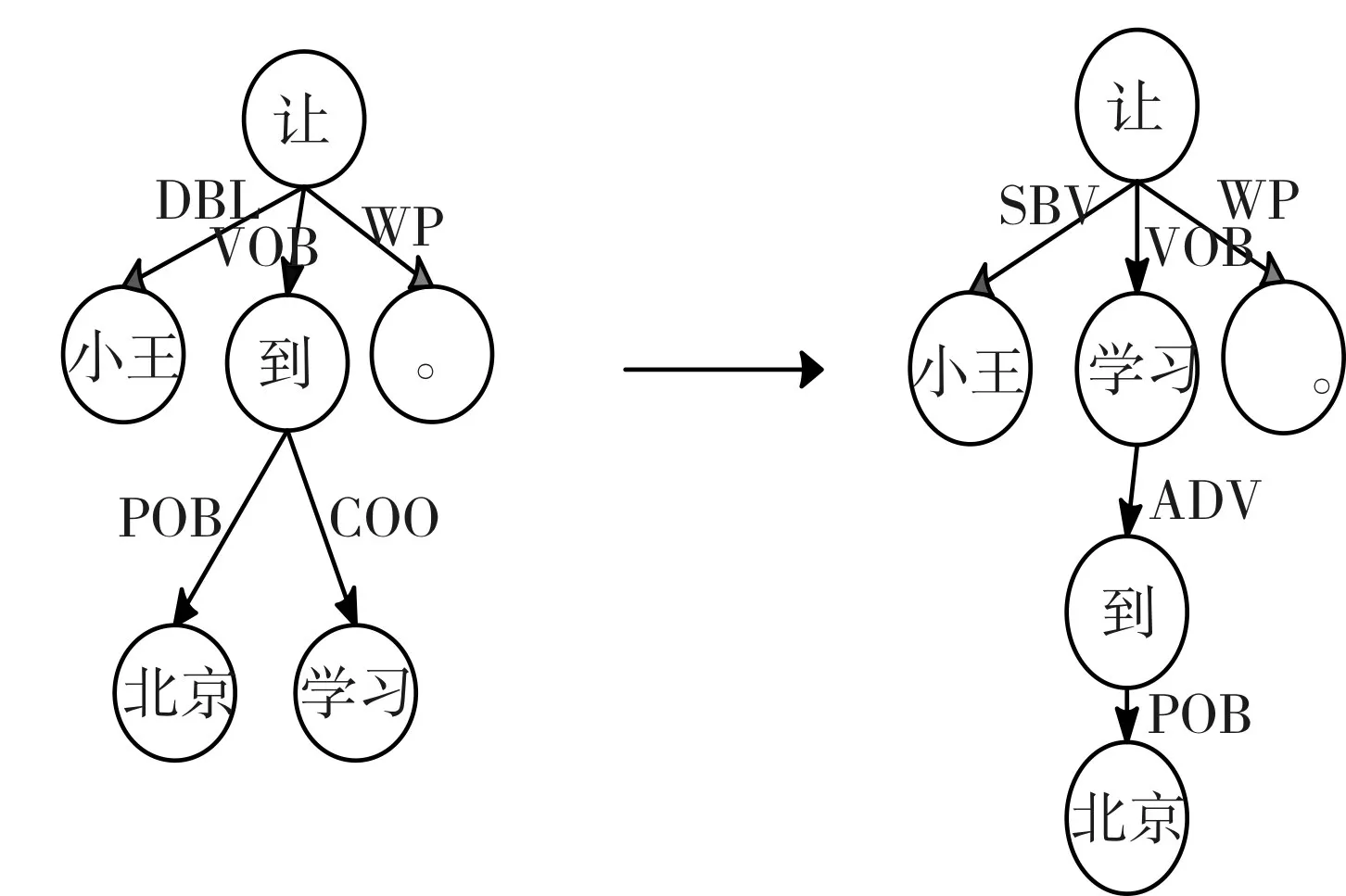
图6 状中结构转换规则
如图6所示,例句“让小王到北京学习”中“到北京学习”这种状中结构没有在现行的单句依存句法分析中得到更好的处理,应先分析主干“让小王学习”,再去分析“到北京学习”内部的层次。
规则2:述补结构转换规则
如图7所示,例句“他念语文念的很熟”中“念得很熟”这种述补结构没有在现行的单句依存句法分析中得到更好的处理,它是由述语“念”+“得”+补语“很熟”构成述补短语;“得”等结构助词连接的述补短语应被标示为两段,一段是由述语指向结构助词“得”,记为SD;另一段由“得”指向补语,记为DB。虽然现行的方法分析“他念语文念的很熟”的主干部分没有问题,但是忽略其中“念得很熟”这种述补结构的层次性。
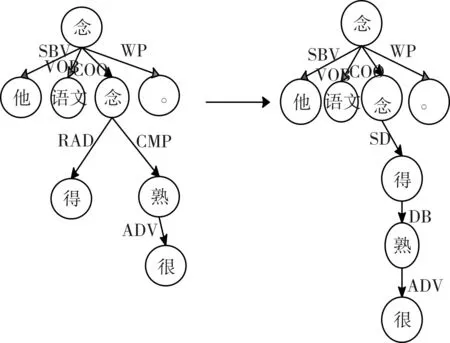
图7 述补结构转换规则
规则3:联合结构转换规则
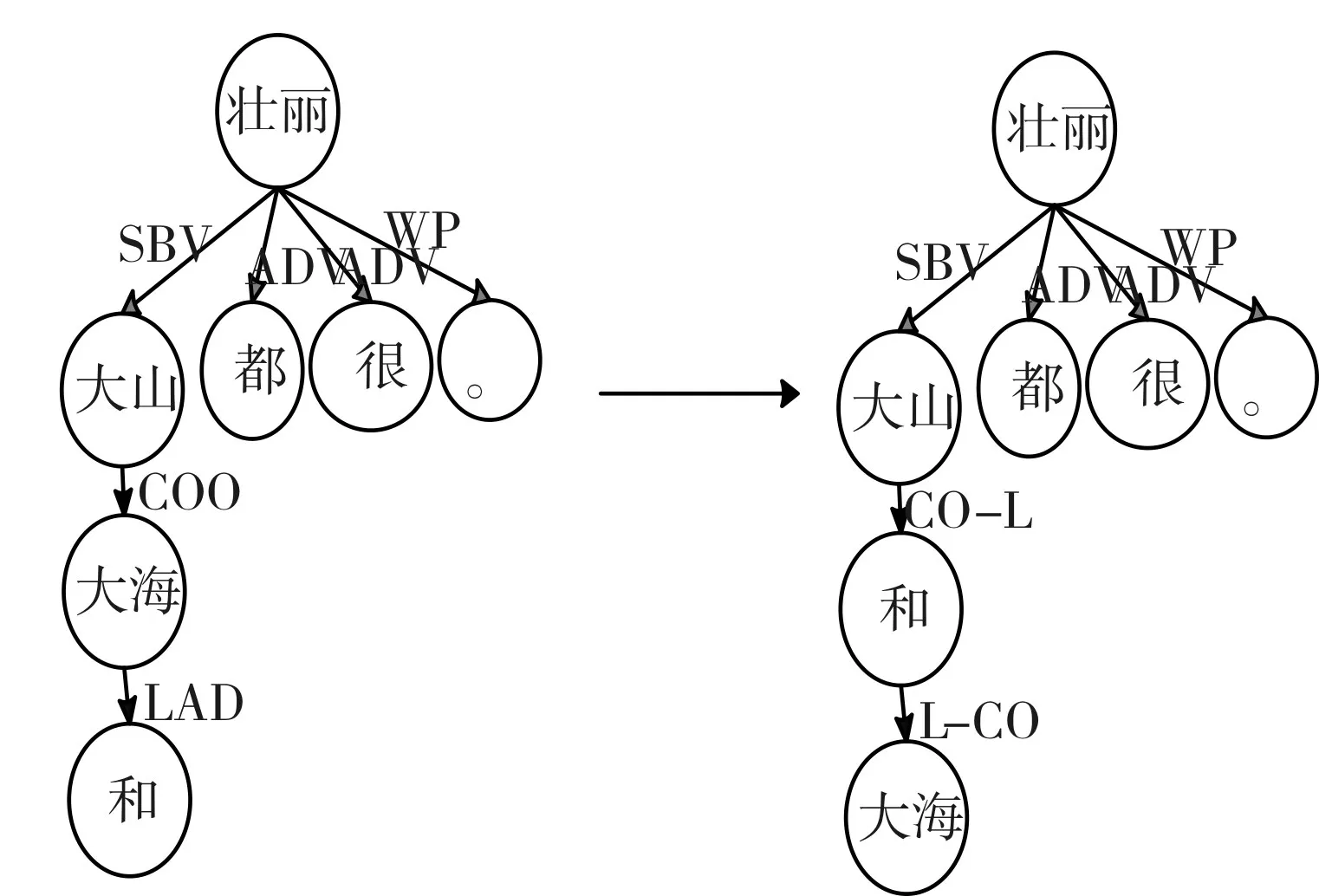
图8 联合结构转换规则
如图8所示,例句“大山和大海都很壮丽”中“大山和大海”这种联合结构没有在现行的单句依存句法分析中得到更好的处理。“和”作为并列连词虽然能够被COO(并列关系)和LAD(左附加关系)共同解释为标识并列关系,但是一旦出现“又阴又冷”等多个并列连词时会错误分析为ADV(状中关系),所以这里统一起见,由并列成分指向连词、副词或顿号的关系记为L-CO;由连词、副词或顿号指向并列成分记为L-CO。
规则4:兼语结构转换规则

图9 兼语结构转换规则
如图9所示,例句“他请我吃饭”中“请我吃饭”这种兼语结构(述宾短语“请我”中的宾语“我”作主谓短语“我吃饭”的主语)显然没有在现行的单句依存句法分析中得到更好的处理。上述的处理既不利于语义的理解(即是他请的我,我吃的饭),又忽略其中“请我吃饭”这种兼语结构的层次性。这里将兼语关系的标示分为两段,第一段由述宾短语中的述语指向其宾语并记为JYSB,第二段由主谓短语的主语部分指向其谓语部分并记为JYZW。
3.2 融入综合分析法思想的依存句法分析
之所以要求依存句法分析结果做到语义与结构兼顾,是因为事实上结构和语义之间存在着内在的必然的联系,它们互为存在的条件,进行语法分析不可能抛开语义和结构中的任何一个,只有语义和结构相结合,才能进行全面的科学分析[6]。这里通过举例来剖析该方法的分析流程。
他们派我到上海学习。(例句5)
下面是用该方法来分析例句5的流程图:
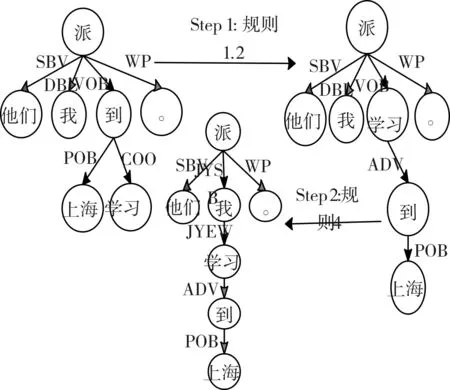
图10 融入综合分析法思想的依存句法分析方法的例句流程分析图
如图10所示,例句“他们派我到上海学习”的依存树首先匹配汉语结构类型模板中的规则1.2来转换“到上海学习”这种状中结构,然后让改变拓扑后的依存树再匹配规则4来转换“他们派我学习”这种兼语结构,值得注意的是:此时树节点“学习”有子节点,再将以“学习”为根节点的子树作为整体一并进行转换,最终得到图10中间位置的依存树,该依存树就是用融入综合分析法思想的依存句法分析方法来分析该例句的最终结果。
4 在构建复句依存关系层次体系中的应用及实验分析
4.1 在构建复句依存关系层次体系中的应用
前文讨论了在构建复句依存关系层次体系时分析分句内成分间的依存关系的过程中引入综合分析法的思想,但它只是构建复句依存关系层次体系中的一个重要的环节而已。从构建整个复句依存关系层次体系的视角下对复句实例进行具体观察,将本文提出的方法应用在复句依存关系层次体系构建中。这里需要强调的是:1)构建过程中对复句的预处理工作包括分词、关系词识别、分句识别、分句类别识别,其中这里分词使用的是ITCAST分词工具,关系词识别采用舒江波的关系词搭配理论[9]、胡金柱的规则标注方法[10]与决策树结合的识别方法[11],分句上采用李琼的标点符号分句[12]和书读语言片段的非分句识别[13]相结合的思路,复句的关系分类类别划分采用刑福义的三大类十二小类[14];2)分句间的依存关系是该体系中的“第一层”依存关系,每个分句内成分间的依存关系是该体系中的“第二层”依存关系,最后通过n+1(n为复句中的分句个数)棵依存树的可视化形式来描述整个复句的句法结构规律和特点;3)复句分句间依存关系树采用树存储结构中的孩子兄弟表示法,分句内成分间依存关系树则采用树存储结构中的孩子表示法;4)复句分句间依存关系树中提到的依存关系标记集(如因果关系GCR)沿用了分句间依存关系标记集[2];由于如何确定并得到复句分句间依存关系树不是本文的研究重点,这里使用基于关系词驱动的确定性移进-规约算法[2],该算法是在鲁松提出的具有预测机制、自底向上、部分数据驱动的确定性移进-规约关系层次分析算法[15]的基础上做了相应的改进。
下面举例说明:
海瑞懂民情懂得很深刻,他是体恤百姓的官员,声誉也很好。(例句6)
图11就是该例句的复句依存体系分析。
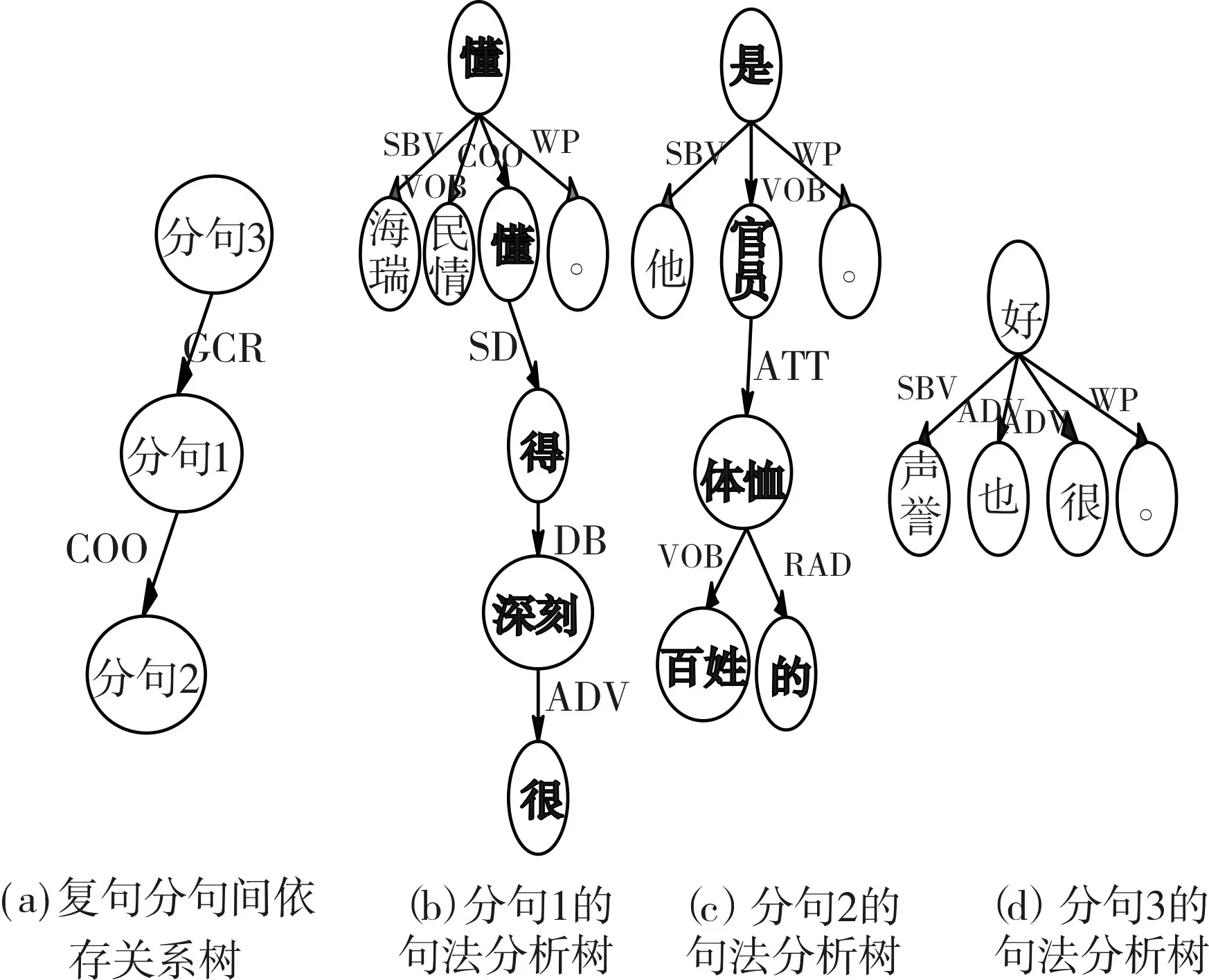
图11 复句依存体系分析
图11中粗体加黑部分就是匹配到到汉语结构类型模板中的规则后得到的最终结果。图(a)是例句5中三个分句间依存关系,其中分句1与分句2构成并列关系(COO)的小句关联体[16]再与分句3形成复句最外层的因果关系(GCR);图(b)、图(c)和图(d)分别揭示各分句内成分间依存关系。
4.2 实验结果分析
从中文信息处理角度下以CCCS语料库中随机抽取的500条三句式(吴锋文提出了三句式有标复句层次关系自动识别研究的丰富理论,而且也便于计算分句个数)复句作为实验数据集,通过用本文提出的方法实验分析这500条复句中的1500条分句来证明该方法在一定程度上提升了依存关系界定的性能,即促进了依存关系结果更加兼顾语义和结构,更好地解释语言现象。表1说明本文提出的4条针对非其他结构的汉语结构类型规则在进行依存结果分析统计时的覆盖率高达58.1%(即实验数据集中58.1%的复句在传统方法的基础上都进行了复句依存分析结果的优化)。
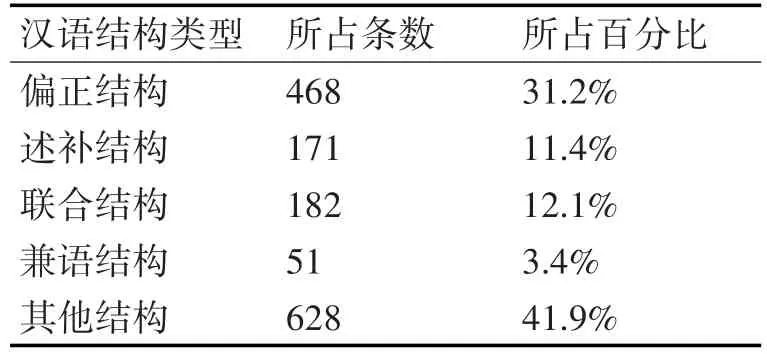
表1 11种汉语结构类型的实际分布
但该方法仍然有改进之处:1)汉语结构类型模板中的规则只有4条,而汉语结构类型有11种,所以很难覆盖所有的复句实例,可以进一步丰富汉语结构类型模板中的规则;2)LTP上得到的单句句法分析器同样存在句法分析错误,本方法的预处理就是该单句句法分析器上的结果,如何对预处理结果进行句法矫正后再进行模板规则匹配,也是本文下一步值得思考的地方。
5 结语
本文的目的是以汉语复句语料库CCCS中抽取的复句为例,探讨在构建复句依存关系层次体系时分析分句内成分间的依存关系的过程中引入综合分析法的思想的必要性和有效性。从实验分析来看,本文提出的方法能在一定程度上提升依存关系界定的性能,更好地解释语言现象,同时也对构建复句依存树库的研究奠定了基础。
