基于密度最大值聚类的奶酪风味鉴别模型
2019-03-25干佳俪谭励宁晓辉王蓓孙践知
干佳俪,谭励,宁晓辉,王蓓,孙践知
(1.北京工商大学计算机与信息工程学院,食品安全大数据技术北京市重点实验室,北京100048;2.火箭军总医院,北京100088;3.北京工商大学食品学院,北京市食品风味化学重点实验室,北京100048)
0 引 言
奶酪是盛行欧美的发酵乳制品,我国西式餐饮加速发展促进了奶酪市场需求。通常成熟的奶酪风味俱佳[1-4],目前西方的奶酪风味研究已成体系[5-8],而我国尚属积累阶段[9-11]。奶酪研究均关注风味组分萃取分离[12-16],高效利用风味组分区分样品鲜见报道[17-20]。
DBSCAN算法对密度不均的样本集聚类[21-23]效果较差,Rodriguez等在Science提出密度最大值聚类—DPC(Clustering by fast search and find of Density Peaks)[24],克服了基于距离聚类只能发现“类圆形”的缺点。模糊规则选择簇中心[25]、势熵提取最优阈值[26]、引入密度比例[27]、基尼指数的自适应截断距离[28]、密度差分聚类[29]等均有优化DPC算法。
鉴于国内奶酪基本依赖进口[30-31],本文将提出一种自动提取奶酪风味物质特征的密度最大值聚类算法,并采用支持向量机(Support Vector Machine,SVM)进行成熟级别分类。
1 实 验
1.1 材料与数据采集
本文实验材料样本库包括切达奶酪和马苏里拉奶酪,其中切达奶酪样本共21个,其产地分布如图1所示,马苏里拉奶酪样本共24个,其产地分布如图2所示,图1、2中数字标记均为样本编号。奶酪样本库的奶酪类别为:淡味、中味、浓味。奶酪样本库经北京工商大学奶酪风味研究室萃取、分离、定量及定性等分析手段获得奶酪样本库的挥发性风味物质信息,其中切达奶酪挥发性风味物质有28种,马苏里拉奶酪挥发性风味物质有23种,奶酪库风味组成具体信息如表1所示。将所得奶酪样本库的挥发性风味物质信息作为本文的研究对象。
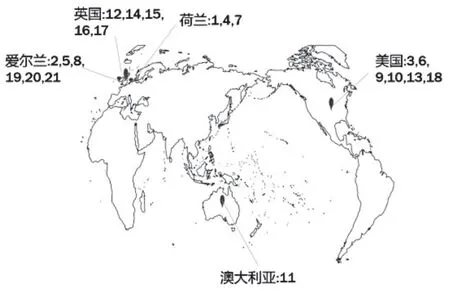
图1 切达奶酪样本产地分布
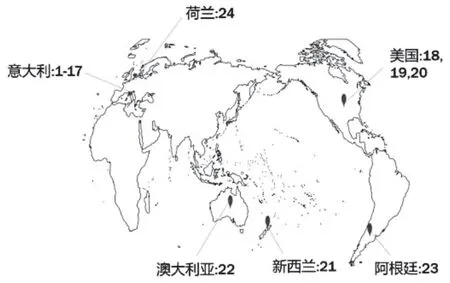
图2 马苏里拉奶酪样本产地分布

表1 奶酪库挥发性风味物质信息
1.2 DPC算法的食品鉴别模型
1.2.1 DPC算法自动提取特征风味物质
给定数据集Φ,数据点i,j∈Φ,DPC算法主要分两步:
(1)计算每个数据点的局部密度ρi
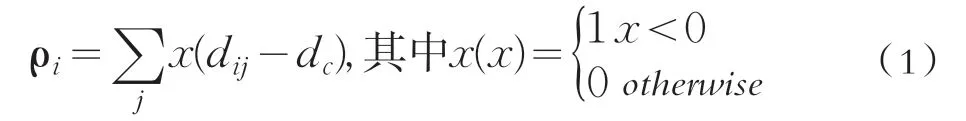
式中:dij为数据点i到其他数据点j的距离;dc为一个截断距离;ρi为到数据点的距离小于dc的数据点的个数。
(2)高局部密度点距离δi

式中:δi为数据点i到距离最近且比自身局部密度ρi大的数据点j的距离。当数据点i是数据集中局部密度最大的点时,高局部密度点距离δi为

最理想的簇中心同时具备以下两个条件:①局部密度大于周围邻居数据点的局部密度;②距离比自身局部密度大的簇中心的距离相对较远。因此本文中将每种化合物作为数据点,对每个数据点的局部密度和高局部密度点距离的乘积即ρiδi进行降序排列,ρiδi值越大越有可能是聚类中心[24],再结合ρi-δi决策图,确定聚类簇中心,即后续用于类别鉴定的特征风味物质,每种奶酪样本保留特征风味物质的数值,作为输入SVM算法的数据点,进行分类。
截断距离dc的选取决定了DPC算法聚类效果的好坏,如果过大会使得所有数据集归为一类,如果dc过小会使得每个数据点自成一类。另外,DPC算法需要通过ρi-δi决策图确定ρi和δi均较大的点作为聚类中心。DPC算法参数的阈值需要人工选择,在一定程度上影响了算法的客观性以及降低了算法的执行效率。本文将在DPC算法上进行改进,使其不需要通过决策图确定聚类中心,而是能够自动确定聚类中心提取奶酪特征风味物质,提高分类效率,达到更好地聚类效果和更高的分类准确率。
自动提取奶酪特征风味物质的算法如表2所示,最终输出的聚类中心即为奶酪特征风味物质。

表2 自动提取特征算法
1.2.2 奶酪风味鉴别模型的建立
提取特征风味物质后,采用支持向量机建立快速鉴别模型。支持向量机中核函数的参数和误差惩罚因子C是影响SVM性能的关键因素,即对误差的容忍程度,C越小容易欠拟合,反之容易过拟合,泛化能力变差。核函数主要分为线性核、多项式核、Sigmoid核和Gauss径向基核。一般采用最广的是径向基函数。本文采用网格搜索GridSearchCV的方式调整SVM模型的参数,主要流程如图3所示。
1.2.3 实验设置
本实验特征提取环节分四组进行:第一组保留所有奶酪挥发性风味物质,第二组采用DBSCAN聚类提取特征风味物质,第三组采用K-Means聚类提取特征风味物质,第四组采用改进的密度最大值聚类(DPC)算法提取特征风味物质。其中第四组将设定不同的截断距离dc值,然后通过1.2.1中的方式自动获取局部密度ρi和高局部密度点距离δi,得到不同的特征风味物质组合。基于上述奶酪特征风味物质组合进行样本分类,评价指标采用精确率(precision)、召回率(recall)、f1-score(精确率和召回率的调和平均值)、准确率(accuracy)。
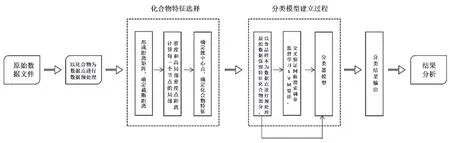
图3 DPC算法的奶酪风味鉴别模型流程
2 结果与分析
2.1 DPC算法提取风味物质特征参数设置
密度最大值聚类算法首先要确定截断距离dc的大小,文献[24]中提出设置dc使得每个数据点的平均邻居个数约为数据点总数的1%~2%。但是实际应用中面对不同数量级的样本,存在很大差异,不能有效的进行聚类,因此本实验中设置不同截断距离dc,使得数据点的平均邻居个数分别为数据点总数的5%~10%,10%~20%,20%~30%,30%~40%。
2.2 切达奶酪基于DPC提取特征的样本分类
切达奶酪在不同dc值的情况下,ρi-δi决策图如图4所示。根据1.2.1中算法自动选取聚类中心,即化合物特征如表3。分别将密度最大值聚类(DPC)提取到的切达奶酪风味物质特征输入支持向量机分类模型,进行cv=5折交叉验证,得到如图5在不同切达奶酪类别上的精确率、召回率以及f1-得分,f1-得分兼顾了分类模型的精确率和召回率,是精确率和召回率的一种调和平均数,f1-得分越高说明分类模型性能越好,越稳定。综合图4可以看出,当取值使得每个数据点的平均邻居个数约为数据点总数的20%~30%时,切达奶酪的特征风味物质组合为:丁酸乙酯、2-庚酮、柠檬烯、2-壬酮、辛酸乙酯、呋喃酮、δ-癸内酯、δ-十二内酯,分类模型性能最好,具有较高的精确率(96%)、召回率(95%)以及f1-得分(95%),能够很好的区分负样本和识别正样本。

表3 不同dc值的切达奶酪风味物质特征组合

图4 不同dc/%值的切达奶酪风味物质特征决策
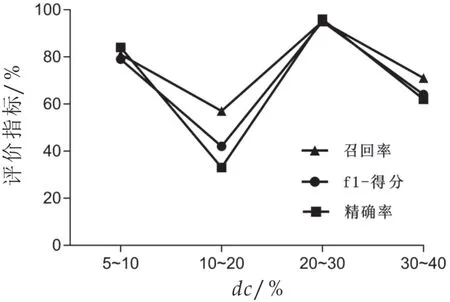
图5 不同dc值的切达奶酪分类评价指标
2.3 马苏里拉奶酪基于DPC提取特征的样本分类
马苏里拉奶酪在不同dc值的情况下,ρi-δi决策图如图6,根据1.2.1中算法自动选取聚类中心,即化合物特征如表4。将三组不同马苏里拉奶酪风味物质特征输入支持向量机分类模型,进行cv=5折交叉验证,每组分类结果的精确率、召回率、f1-得分如图7所示,可以看出当dc取值使得每个数据点的平均邻居个数约为数据点总数的10%~20%时,马苏里拉的特征风味物质组合为:苯甲醛、月桂醛、γ-十二内酯、癸醛、十一醛,分类模型性能最好,能够很好的区分负样本和识别正样本,f1-得分为96%。

图6 不同dc值的马苏里拉奶酪风味物质特征决策
2.4 基于不同聚类算法提取特征的分类结果比较分析
为了验证改进的DPC模型提取特征的性能,本文将其与DBSCAN聚类、K-means聚类以及保留原始特征风味物质的样本输入支持向量机模型进行分类比较分析,评价指标采用f1-得分和准确率,f1-得分越高,说明分类模型越稳健,准确率是一个直观的评价指标,是对整体样本分类结果正确率的评价。

图7 不同dc值的马苏里拉奶酪分类评价指标

表4 不同dc值的马苏里拉奶酪风味物质特征组合
切达奶酪通过DBSCAN聚类提取的特征风味物质组合为:丁酸乙酯、2-庚酮、柠檬烯、癸醛、2-十一烷酮、癸酸乙酯、月桂醛、δ-癸内酯,通过K-means聚类提取的特征风味物质组合为:δ-壬内酯、2-甲基-丙酸、己酸、己酸乙酯、乙酸、2,3-丁二酮、壬酸,由表5可以看出切达奶酪原始挥发性风味物质、DBSCAN聚类特征以及K-means聚类特征在支持向量机模型上的分类f1-得分和准确率均在70%以下,而本文改进的自动获取聚类中心的DPC聚类特征在支持向量机上分类结果很好,特征风味物质组合为:丁酸乙酯、2-庚酮、柠檬烯、2-壬酮、辛酸乙酯、呋喃酮、δ-癸内酯、δ-十二内酯,f1-得分、准确率均高达95%,很大程度的提高了分类器的稳健性和分类果。
马苏里拉奶酪通过DBSCAN聚类提取的特征风味物质组合为:3-己酮、戊酸甲酯、苯甲醛、γ-十二内酯、乙酸乙酯、癸醛、十一醛,通过K-means聚类提取的特征风味物质组合为:乙酸乙酯、呋喃酮、壬醛、丁酸、2-壬酮、己酸乙酯、δ-十二内酯,分类结果的f1-得分和准确率对比如表5,可以看出马苏里拉奶酪原始挥发性风味物质、DBSCAN聚类特征以及K-means聚类特征在支持向量机模型上的分类f1-得分和准确率均在88%左右,本文改进的自动获取聚类中心的DPC聚类提取的特征组合为:苯甲醛、月桂醛、γ-十二内酯、癸醛、十一醛,将分类结果的f1-得分提高了0.9个百分点,为96%,准确率提高了0.8个百分点,为96%,使得分类器在马苏里拉奶酪样本上同样表现稳健,能够很好的区分负样本,识别正样本。
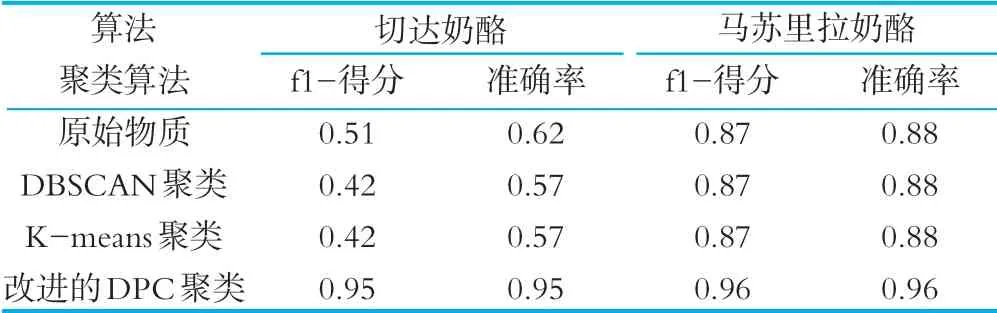
表5 不同聚类模型提取奶酪风味物质特征分类f1-得分以及准确率对比
3 结 论
综合以上实验,结合不同聚类算法的比较分析,本文改进的基于密度最大值聚类的奶酪鉴别模型,优势在于能够自动获取聚类中心,不需要输入划分簇的个数,当聚类间距相差很大时,也能够有很好的聚类效果,如果保留原始所有特征风味物质,将加大分类模型的运算空间,因此采用本文提出的模型提取风味物质特征后再分类,节省了运算空间,还提高了分类准确率以及f1-得分,而且分类效果均优于DBSCAN聚类和K-means聚类提取的风味物质特征,其中DBSCAN聚类和K-means聚类在切达奶酪样本上表现较差,马苏里拉奶酪样本表现一般,但是改进的基于密度最大值聚类的奶酪鉴别模型在两种样本上均表现良好,使得分类模型稳健、适用性强。
本文针对密度最大值聚类算法进行改进,使其能够自动获取聚类中心,适用于奶酪样本的风味特征提取,再结合支持向量机算法建立奶酪风味鉴别模型,在分类精确率、召回率、准确率及运算空间等方面比传统的奶酪类别分析方法都有所改善提升。
