虚拟光谱识别法快速测定LTAG原料与产物烃组成
2019-03-22李敬岩褚小立
李敬岩, 褚小立
(中国石化 石油化工科学研究院, 北京 100083)
中国石化石油化工科学研究院(简称石科院)开发的劣质LCO(轻循环油)转化为催化裂化汽油或轻质芳烃技术(LCO to aromatics and gasoline,LTAG),将低价值的LCO转化成为高附加值的高辛烷值车用汽油或芳烃[1]。LTAG将LCO中多环芳烃,尤其是大量的双环芳烃,选择性加氢饱和为单环芳烃。这一反应结果的好坏可以通过LCO加氢前后单环和多环(特别是双环)芳烃的含量变化来确定。因此,对LTAG加氢单元中LCO原料和产品的性质监控,尤其是对其族组成的监控,有利于及时调整加氢及催化裂化的工况,降低能耗并优化最终产品质量。
对LCO原料和产品性质的分析,特别是对其中芳烃组成的测定,目前主要分析方法是质谱法[2],能给出柴油的详细族组成信息,包括链烷烃、不同环数环烷烃以及不同环数芳烃的组成分布等,但该方法需要对样品进行预分离,将样品分离为饱和烃和芳烃后再分别进行质谱分析,分析时间较长。近红外光谱(NIR)分析技术是目前最有前景且应用最广泛的快速分析方法之一,近红外光谱主要反映含氢基团X—H(X=C、N、O)合频和倍频的振动[3-4],含有丰富的组成和结构信息, 非常适合于分析原油及油品[5-8]。
国外一些大型石化企业以及知名仪器公司都有自己的油品近红外光谱数据库,在先进过程控制和优化控制等方面发挥着重要的作用。石科院也开展了初步的探索工作,但尚未进行系统的研究和开发。近红外光谱快速测量油品组成以及物性是一种比较成熟的分析方法,但需建立较复杂的分析模型(也称光谱数据库),才能得到可靠的测量结果[9-10]。经典的多元校正方法有偏最小二乘(PLS)法,本课题组针对LTAG原料与产物也建立了PLS模型[11]。但限制近红外快速分析技术推广的一个难点是定量校正模型需要维护,当有待测样本的物性超出模型范围时,预测结果将出现较大偏差。本研究中,笔者提出一种根据已有的LTAG原料与产物近红外光谱数据库,通过产生虚拟样本的方式,对原有的LTAG原料与产物近红外数据库进行密化处理的方法,得到虚拟LTAG原料与产物库。将待测LTAG原料、产物样本和虚拟LTAG原料与产物库进行比对识别,找到最相似样本进而得到评价数据。该方法无需模型维护,只需要不断加入新样本更新数据库,是开放性的、可扩展样品数量的数据库技术。随着使用过程校正集样本数量的不断增加,其适用范围将越来越宽,分析准确性和稳健性也将越来越高。
1 实验部分
1.1 LTAG原料与产物样本
从石科院以及各大炼油厂收集LTAG原料与产物总计468个,性质数据包括链烷烃、环烷烃、烷基苯、茚满或四氢萘、单环芳烃、双环芳烃、三环芳烃等详细烃组成。LTAG原料与产物样本的收集时间为2016年6月至2017年12月。所有样本用20 mL 密封小瓶封装,放置于冰柜中保存。LTAG原料与产物烃族组成由质谱法测定。其性质和组成分布情况的统计数据见表1。

表1 LTAG原料与产物烃组成统计结果Table 1 Hydrocarbon composition of raw materials and products of LTAG
1.2 近红外光谱仪与光谱采集
使用Thermo Antaris II傅里叶变换型近红外光谱仪采集近红外光谱数据库。选用一次性玻璃小瓶(带聚乙烯塞一次性透明0.7 mL圆筒玻璃小瓶,35 mm×7.8 mm,光程6.5 mm)和透射方式采集LTAG原料与产物近红外光谱,在光谱采集过程中,以空样品瓶做参比,消除一次性玻璃小瓶在材质和尺寸上存在的微小差异。相比于传统的比色皿采样方式,其具有如下技术优势:不用清洗,测量方便;样品用量小,且环境污染小;小瓶密封性好,有利于提高光谱测量重复性。
采集近红外光谱参数如下:光谱分辨率:8 cm-1;累计扫描次数:128次;光谱范围:3800~10000 cm-1。典型LTAG原料与产物的近红外光谱见图1。
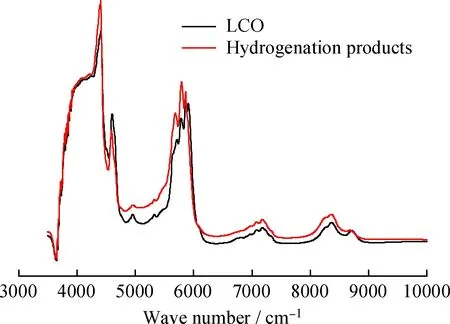
图1 LTAG原料与产物的近红外光谱Fig.1 Near infrared spectra of raw materials andproducts of LTAG
仪器采集的近红外光谱信号除样品信息外,还包含来自各方面的噪声。光谱预处理的目的是滤去噪声,提取有用信息,方便后续处理。常用的光谱预处理方法有小波变换、平滑、归一化和微分等。其中微分是一种常用的光谱预处理方法,可以有效消除样本颜色、基线和其他背景干扰,分辨重叠峰,提高分辨率和灵敏度。本研究采用二阶微分处理,以解决LTAG原料与产物样品在颜色上的差别引起的光谱基线偏移和漂移问题。图2为LTAG原料与产物的二阶微分光谱。
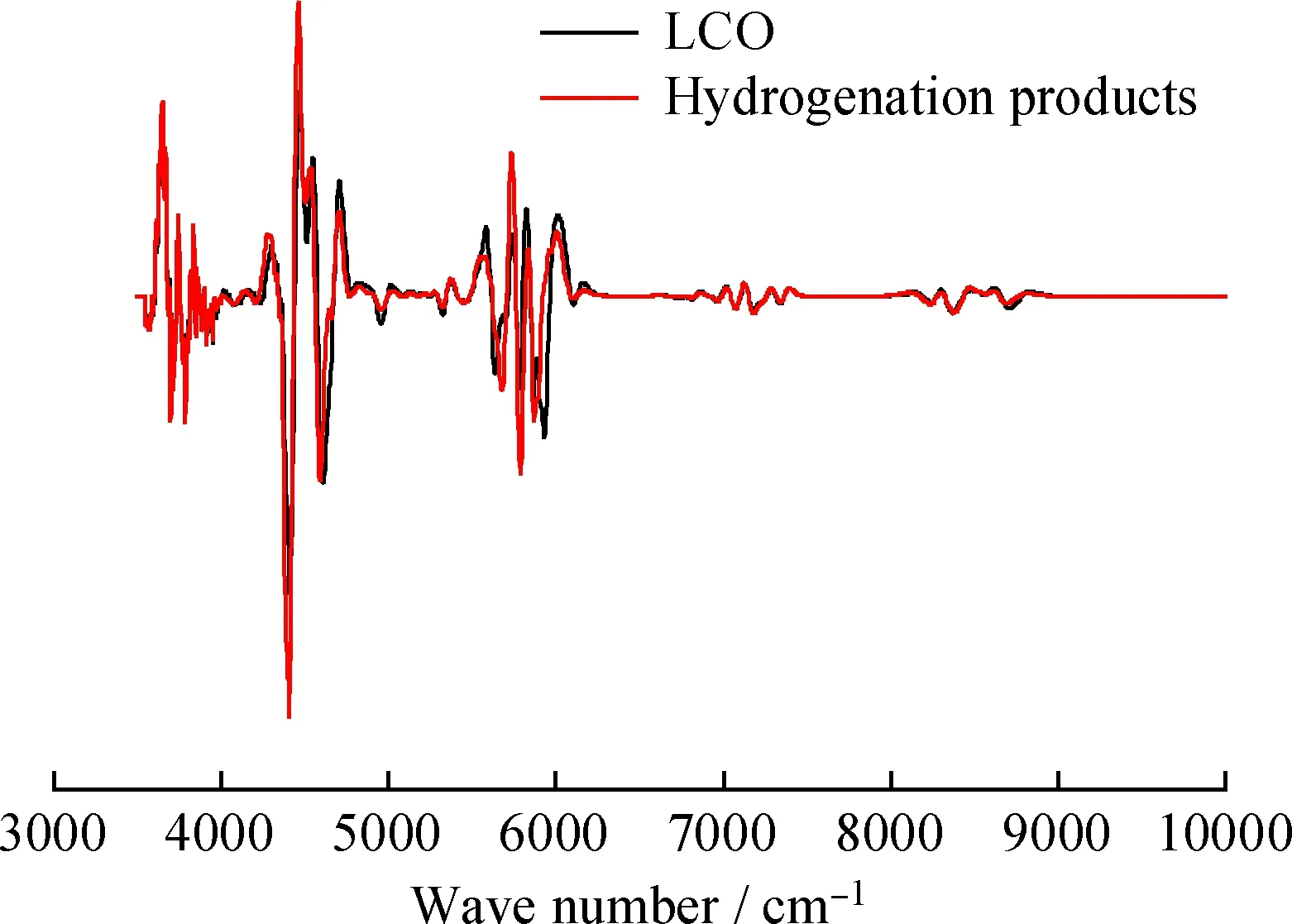
图2 LTAG原料与产物的二阶微分谱Fig.2 Second-order differential spectra ofLTAG raw materials and products
1.3 化学计量学方法
采用石科院“化学计量学光谱分析软件3.0”,对样品光谱和标准方法测得的LTAG原料与产物烃组成数据进行编辑,生成标准矩阵式数据库。程序运行平台:ThinkPad T440p,i5(2.50 GHz),4 GB RAM。
本研究所采用的偏最小二乘(PLS)定量校正方法基本模型为:
Y=UQt+EY
(1)
X=TPt+EX
(2)
式(1)和(2)中,X为光谱矩阵;Y为烃组成矩阵;t为转置;T和U分别是X和Y矩阵的得分矩阵;P和Q分别是X和Y矩阵的载荷矩阵;EX和EY分别是X和Y矩阵的PLS拟合残差矩阵。将T和U作线性回归:
U=TB
(3)
B=(TtT)-1TtY
(4)
式(3)和(4)中,B为回归系数。在预测时,首先根据P求出未知样品光谱阵Xun的得分Tun,然后根据式(5)得到浓度预测值Yun:
Yun=TunBQ
(5)
本研究建立的油品近红外光谱数据库所采用的无监督模式识别方法为移动窗口相关系数法[12-13],其原理如下:在特征光谱区间,从波数最低的采样点选择一个移动窗口的宽度w,计算该窗口内的待识别LTAG原料、产物样品与数据库中每个样品的吸光度的相关系数,然后将移动窗口向波数高的方向移动若干个采样点,作为下一个移动窗口,计算此移动窗口内的待识别LTAG原料、产物样品与数据库中每个样品的吸光度的相关系数,方法原理如图3所示。按上述方法连续移动窗口,计算每个移动窗口内待识别LTAG原料、产物样品与数据库中每个样品的吸光度的相关系数。将得到的相关系数值与对应移动窗口的起始位置作图,即得到移动相关系数图。从移动相关系数图中可以方便地看出两个光谱之间的相似程度。若两个光谱完全相同,则在整个光谱范围内的移动相关系数值都为1;若两个光谱只是在某一区间存在差异,则该区间的相关系数值将明显下降。

图3移动窗口相关系数方法原理
Fig.3Principleofmovingwindowcorrelationcoefficientmethod
利用上述的识别参数进行LTAG原料与产物种类识别的方法为:计算光谱数据库所有样品、待识别LTAG原料与产物样品的移动相关系数;将所有移动窗口的相关系数相加,得到每个数据库样品的识别参数Qi;将Qi与阈值Qt相比较,如果所有的Qi都不大于阈值Qt,说明数据库中不含待测LTAG原料与产物样本的种类。
用于识别的虚拟样本采用蒙特卡洛方法实现,首先用数学递推公式的方法产生一组随机数符合(0,1)上的均匀分布。蒙特卡洛虚拟光谱识别方法的具体过程为:首先使用移动窗口相关系数法从校正集中识别出与待测样本最相似的N个样本;采用蒙特卡洛方法通过最相似的N个样本在待测样本周围生成M个虚拟样本;然后从这些虚拟样本中识别出与待测原油一致的一组样本,结合LTAG原料和产物性质与烃组成数据库可快速给出待测样本的烃组成。
在本文中,采用蒙特卡洛方法,首先产生一组随机数矩阵(N×M),矩阵大小为(10×10000),符合(0,1)上的均匀分布。方法是用数学递推公式产生,按列进行归一化处理。将识别出来的10个最相似样本叠成标准光谱矩阵,与随机数矩阵相乘即得到虚拟光谱矩阵,虚拟光谱数量为10000条。同理可得到虚拟光谱的性质与烃组成数据矩阵,即通过线性加和的方式得到虚拟光谱的烃族组成数据。
2 结果与讨论
在不同波长范围的近红外光谱所含的信息量不同。要建立稳健的校正模型需要选择与具体性质相关的谱区,因为如果没有显著吸收特征峰与其他官能团吸收峰重叠的光谱区间,将会降低校正模型的预测能力。以辛烷值为例,考察不同波长范围与辛烷值的相关性。通过比较,7000~7400 cm-1和8100~8600 cm-1范围内光谱与辛烷值具有较高的相关性,可以作为建模的区间。选择最有用的光谱信息建立校正模型,不但可以提高模型预测能力,而且由于剔除了信息弱的光谱区域,减少了光谱数据量,也能够提高计算速率。
2.1 PLS分析方法
采用石科院“化学计量学光谱分析软件3.0”中的偏最小二乘(PLS)方法建立校正模型。模型建立前,首先从LTAG原料与产物库中选取其中68个LTAG原料与产物样本作为验证集样本,剩余400个样本构成校正集。所有样本均在常温下采集光谱。光谱首先经二阶微分处理,以消除样品颜色、温度及基线漂移等因素的影响,选择近红外光谱波段区间(7000~7400 cm-1和8100~8600 cm-1)作为特征谱区,将特征谱区内的吸光度与标准方法测定的烃族组成相关联,建立LTAG原料与产物烃族组成的校正模型。光谱最佳主因子数采用交互验证所得的预测残差平方和(PRESS)确定。模型通过校正标准偏差(SECV)和预测标准偏差(SEP)来评价。表2为LTAG原料与产物验证集样本的预测统计结果。

表2 PLS方法模型统计Table 2 Model parameters of PLS method
从表2可以看出,验证集的预测标准偏差与校正标准偏差基本吻合,说明所建PLS校正模型可以对LTAG原料与产物样本的辛烷值以及烃族组成进行快速准确的预测分析。
2.2 蒙特卡洛虚拟光谱识别法
校正集与验证集样本选取方法同2.1节,首先从校正集中识别出与每个验证集待测样本最相似的N个样本,然后通过该N个样本在待测样本周围生成M个虚拟样本。如果从校正集中识别出的相似样本太少,产生的虚拟样本差异性很小,识别效果差;若识别出的相似样本过多,会把与待测样本差异性较大的样本选进来,同样会导致评价结果变差。综合考察后选择N=10。一组10个待测样本和从校正集中识别出的10个与其最相似样本通过主成分分析提取前3个主因子在三维空间分布见图4,图中PC1、PC2、PC3分别为前3个主因子。对某待测样本,识别出的校正集样本序号见表3,表3中距离表示10个最相似样本与某待测样本在三维空间中的距离。
使用移动窗口相关系数法,从10000条虚拟光谱中找到与待测样本最相似的一组虚拟样本30个,经主成分分析提取前两个主因子,其空间分布如图5所示,图中PC1、PC2分别为前两个主因子。以该组虚拟光谱的均值谱作为待测样本的最临近光谱,其评价数据作为待测样本的性质与烃组成预测值。
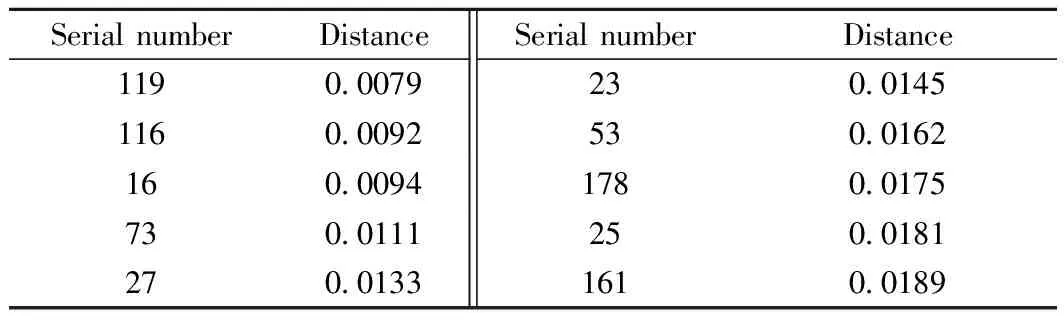
表3 与某待测样本最相似的10个校正集样本Table 3 Ten samples in the database most similarto the measured sample
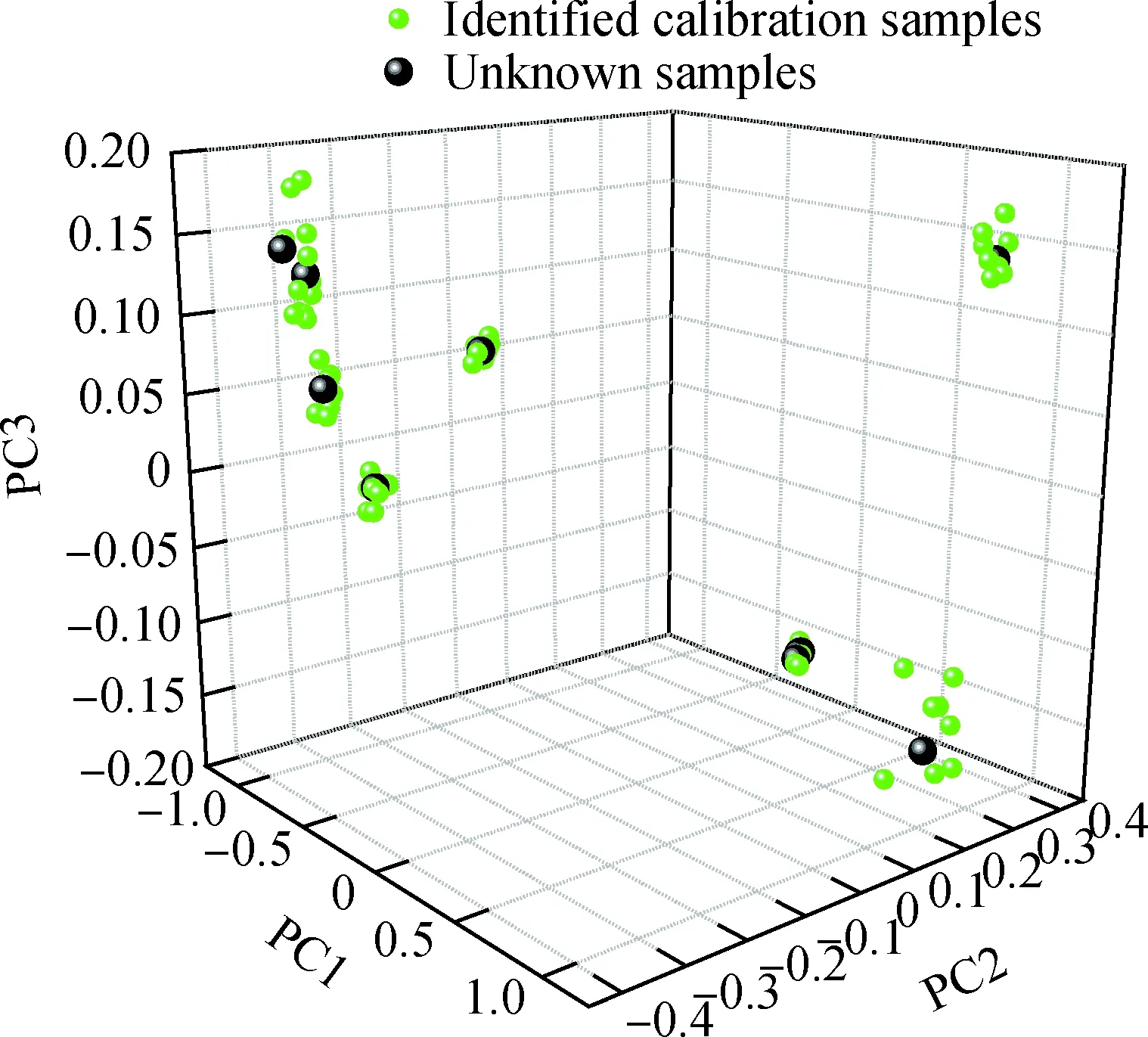
图4 10个待测样本与校正集最临近样本的空间分布Fig.4 Spatial distribution of 10 unknown samples andtheir 10 nearest samples in calibration set
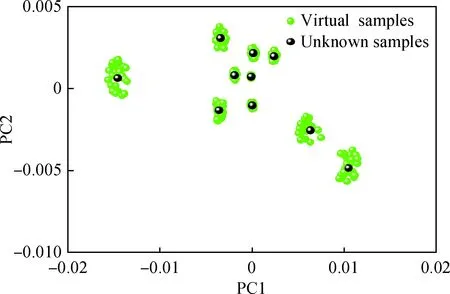
图5 10个待测样本与最临近虚拟样本的空间分布Fig.5 Spatial distribution of 10 unknown samples andtheir 30 nearest virtual samples
待测样本与最临近虚拟样本光谱在6200~10000 cm-1范围内的对比见图6所示。从图6可以看出,待测样本与最临近虚拟样本光谱几乎无差异。
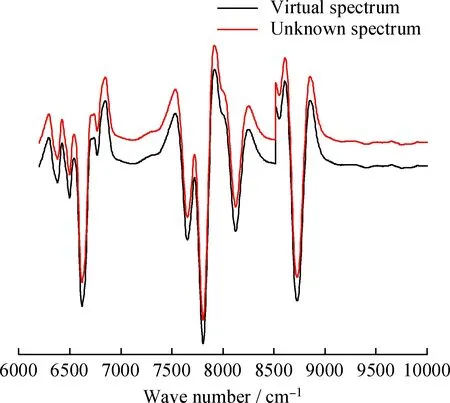
图6 某待测样本与最临近虚拟样本的近红外光谱对比Fig.6 Near infrared spectra comparison of an unknownsample with its nearest virtual sample
同理得到预测集所有样本的预测值,模型统计参数见表4。对比表2可以发现,蒙特卡洛虚拟光谱识别方法的预测标准偏差均小于PLS,但差异较小,基本处于同一水平。蒙特卡洛虚拟光谱识别方法是一种定性方法,无需像PLS一样建立复杂的校正模型,操作人员无需掌握建模以及模型维护知识,只需向数据库中添加新的样本即可达到模型维护的目的。该方法产生的虚拟光谱是随机的,表5是对同一个待测样本连续5次重复测量的结果。从表5 可以看出该方法极大地满足了测量重复性的要求。
3 结 论
本研究建立了LTAG原料与产物包含468个样本的数据库,基于近红外光谱分析方法开发了通过模式识别方法预测分析LTAG原料与产物烃族组成的方法。
研究结果表明,传统的PLS方法建立LTAG原料与产物性质和烃族组成的定量校正模型,可以得到准确的预测结果,对LTAG原料与产物样本链烷烃、环烷烃、烷基苯、茚满或四氢萘、单环芳烃、双环芳烃、三环芳烃的预测标准偏差分别为2.4%、2.1%、1.3%、1.1%、1.9%、1.4%和0.6%。但模型维护始终是PLS定量方法推广的障碍。

表4 蒙特卡洛虚拟光谱识别方法的模型参数统计Table 4 SEP of Monte Carlo virtual spectrum identification methods
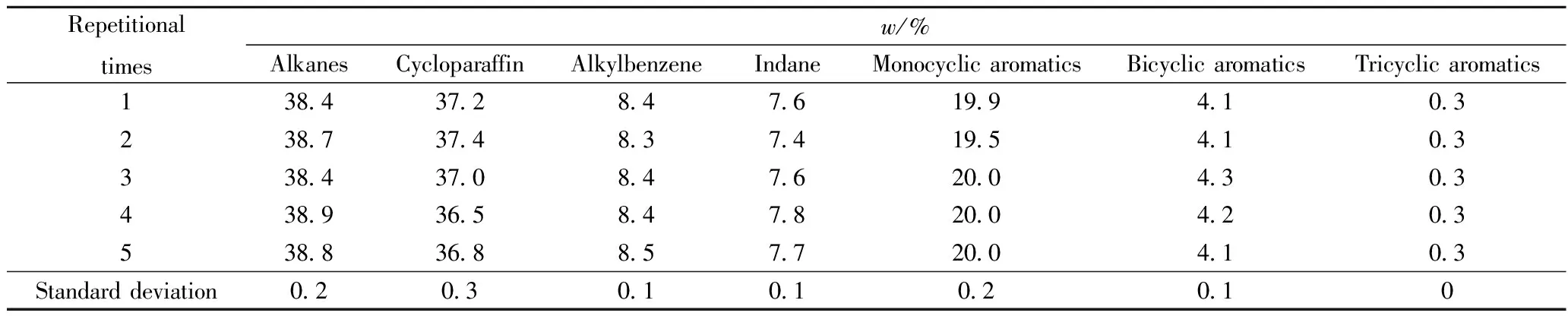
表5 蒙特卡洛虚拟光谱识别方法的重复性Table 5 Repeatability of Monte Carlo virtual spectrum identification method
同时开发了基于蒙特卡洛方法的虚拟样本识别方法,该方法对LTAG原料与产物样本链烷烃、环烷烃、烷基苯、茚满或四氢萘、单环芳烃、双环芳烃、三环芳烃的预测标准偏差分别为1.5%、1.4%、0.9%、0.8%、1.3%、0.8%和0.5%,预测准确性高于PLS方法,基本达到了标准方法(SH/T 0606中间馏分烃类组成测定法)的再现性要求。本方法节约了建模成本,减少了数据库维护的工作量。
