基于改进的Adaboost算法的人脸检测系统
2019-03-21冯小建马明栋王得玉
冯小建,马明栋,王得玉
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京邮电大学 地理与生物信息学院,江苏 南京 210003)
0 引 言
人脸检测是人脸识别技术的重要组成部分和关键技术基础。作为人脸信息处理中的一项关键技术,人脸检测技术在基于内容的检索、数字视频处理、视觉监测、身份验证、安全监测等方面有着重要的应用价值[1]。随着社会对人脸检测技术的需求越来越多,应用越来越广泛,针对人脸检测技术的研究也越来越深入。Viola和Jones共同提出的Viola-Jones检测器对Adaboost算法训练出的强分类器进行级联,极大提高了人脸检测的效率和准确率,受到了广泛的关注[2]。最初的Adaboost算法采用几种简单的Haar-Like矩形特征,用积分图的方法快速计算特征值,再将训练的最优弱分类器组合成强分类器,然后将强分类器级联便构成了Haar分类器。
虽然Viola-Jones检测器相比之前的各种人脸检测器有着更加优越的性能,但在实际应用中还是存在检测效率和准确率不足等问题[3]。因此,有必要对Haar分类器进行进一步的研究与优化。文中系统采用肤色检测技术对传统的Adaboost算法进行改进。肤色检测排除了绝大部分非人脸区域,有效提高了人脸检测系统的效率。由于传统的Haar-Like矩形特征会产生大量的特征值,导致训练过程效率太低,文中提出的两种新型Haar-Like特征,降低了训练过程所耗的时间,而且新特征符合人脸器官特征,提高了检测率和虚警率,对系统的综合性能进行了有效的优化。
1 肤色区域检测
文中用常见的阈值分割方法对图像进行肤色区域分割。阈值分割实际上就是对像素值进行判断,若像素的各通道数值都满足条件的阈值,则判定像素颜色为肤色[4]。阈值分割可以基于YCrCb、HSV或者RBG等颜色空间进行阈值判定。肤色的差异主要受亮度影响,色度对肤色的影响较小,所以光照强度是肤色的主要影响因素。在YCrCb空间中,Y表示亮度,Cr表示红色色度,Cb表示蓝色色度。在YCrCb空间中,利用对Cr和Cb颜色分量的阈值筛选即可判定肤色区域[5]。肤色分割先对图像进行颜色空间转换,从RGB空间转换到YCrCb空间,再利用先验统计的判别式进行区域筛选:77≤Cb≤127,133≤Cr≤173。
对于图像像素点,满足YCrCb空间判别条件的即为肤色像素,效果如图1所示。这就完成了初步的肤色区域检测。

图1 肤色分割效果
2 Haar-Like特征
Haar-Like特征通常就是一些包含黑色区域和白色区域的矩形特征[6]。其中白色区域的像素和与黑色区域的像素和之差便是特征值,用这种方法可以反映图像的局部灰度值变化。
2.1 基本的Haar-Like特征
Viola等使用了5种简单的Haar-Like矩形特征,如图2所示。

图2 基本Haar-Like特征
为了更好地适应不同检测目标的灰度分布,后来的研究者们在最初的矩形特征之外扩展了一些其他类型的Haar-Like特征,构成了目前常用的边缘特征、线性特征和中心特征,如图3所示。

图3 常用的Haar-Like特征
2.2 扩展的Haar-Like特征
在人脸图像中,眼睛、鼻子和嘴巴等器官区域的灰度值较高,其余区域灰度值较低。根据人脸图像中眼睛和鼻子的位置特征,引入了两种扩展的Haar-Like特征,如图4所示。

图4 扩展的Haar-Like特征
文中引进的两种Haar-Like特征是根据人脸的特征设计的。由人脸检测的先验知识可知,人脸中眼睛、鼻子和嘴巴等器官的位置是相对固定的[7]。文中主要研究正脸的识别效果,人脸正面的主要器官双眼、鼻子和嘴巴构成的几何形状便大致为图4(a)的黑色区域分布情况。图4(b)的新特征是针对稍微倾斜的人脸设计的,以提高系统的鲁棒性。从理论上说,扩展的两种新Haar-Like特征能有效提高对人脸图像的检测率,并降低虚警率。
2.3 特征值的计算
Haar-Like特征值的计算采用积分图方法,以提高计算效率。积分图方法先记录像素矩阵的起点到每个像素点之间的像素和,计算某个区域的像素和便只用执行简单的像素和相减。因此只需遍历一次图像,而不用每次对矩阵重新累加计算[8]。
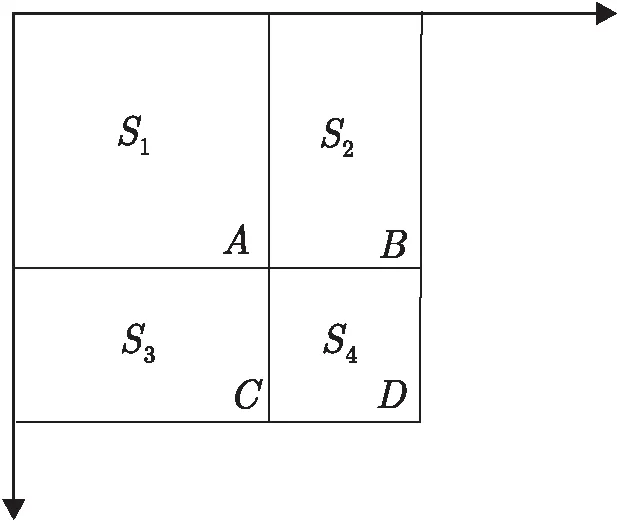
图5 积分图描述
如图5所示,图像中有S1、S2、S3和S4四个区域,假设A、B、C、D四点的左上角区域像素和分别为S(a)、S(b)、S(c)和S(d)。则四个区域的像素和计算公式分别为:
S1=S(a)
S2=S(b)-S(a)
S3=S(c)-S(a)
S4=S(d)-S(c)-S(b)+S(a)
3 Adaboost算法
文中研究的Adaboost算法是一种分类器训练算法,核心思想是通过大量训练样本训练出若干个弱分类器,由这些弱分类器叠加构成一个强分类器,再由多个强分类器级联构成最终的Haar分类器[9-11]。
3.1 强分类器和弱分类器
在训练过程中,每个简单的特征对应一个弱分类器,弱分类器的判定公式为:
(1)
其中,x为待检测窗口;fj为窗口区域的特征值;θj为此弱分类器的阈值;pj用来控制不等式方向;hj(x)是判定结果,1表示判定为人脸,0表示判定为非人脸[12]。
每个训练样本都有自己的权重,而此权重会根据上一轮判定的准确率和每轮样本分类是否正确而发生改变。分类错误的样本会在下一层分类器中加大训练权重,反之减小权重,如此反复迭代训练,得到若干个弱分类器,再将这些弱分类器按权重叠加成最终的强分类器[13]。
对于样本集S={(x1,y1),(x2,y2),…,(xn,yn)},x1,x2,…,xn表示样本,y1,y2,…,yn={0,1}表示样本的正负。则其具体的训练过程如下[14-15]:
(1)初始化样本权重为1/n,使每个样本的权重均匀分布。
(2)将t作为循环因子进行从1到T的循环;

(3)按更新的权重叠加弱分类器得到强分类器:
(2)

3.2 强分类器级联
由多个弱分类器组合起来的强分类器便有很高的检测率和低的误警率[16]。但由于在检测过程中要以不同尺寸的窗口遍历扫描待检测图像的任意位置,所以会花费很多检测时间。强分类器级联的思想便解决了这一问题[17]。在级联结构中,只有被所有强分类器都判定为人脸的才会最终判定为人脸,否则为非人脸,强分类器的复杂度也会逐级增强。每个强分类器经过阈值的调整使得人脸图像几乎都能通过,而大多非人脸图像不能通过。这样级别较高的强分类器虽然检测效率较低,但由于低级别的分类器筛选拒绝了大多非人脸图像,高级别分类器的工作量会很小,这样便有效提高了系统的检测效率,实现了实时检测[18]。
4 实验与结果分析
实验的软件环境为Windows 10,Visual Studio 2013,OpenCV3.0,使用了来自MIT人脸库的2 028个正样本,4 216个负样本,样本皆为20×20的灰度图。分别训练了OpenCV原有的Haar分类器和改进的Haar分类器。从YaleFaces数据库挑选共500张图像,都归一化为20×20像素图片作为测试样本,对两种不同的Haar分类器进行性能测试,并从检测率、虚警率、检测耗时三个方面进行比较。测试结果如表1所示。

表1 测试结果
表1中,改进Adaboost算法的检测率略高于原有的Adaboost算法,虚警率得到大大降低,这是由于新的Haar-Like特征更加符合人脸的特点,也使系统有更好的鲁棒性,改善了误判情况。改进Adaboost算法节省了大量检测时间,一方面是因为肤色筛选技术排除了大量非肤色区域,降低了待检测窗口量;另一方面是因为新特征的最小检测窗口较大,检测耗时少,提高了检测效率。
5 结束语
研究了Haar-Like特征、积分图计算方法、Adaboost算法原理以及级联分类器等技术,在原有的Haar分类器中融入了两种新的Haar-Like特征,新特征根据人脸五官分布特点而提出,有效提高了检测率,降低了虚警率;引进的肤色检测技术先筛选肤色区域,拒绝了大量非人脸区域,显著提高了系统的检测效率。将改进的Adaboost算法与原有算法进行性能数据比较,结果表明人脸检测系统的虚警率和检测效率都有大幅度的改善,检测率也有一定的提升。
