基于XGBoost集成模型的社会基本医疗保险参保人欺诈风险预测研究*
2019-03-19河北工业大学经济管理学院信息管理与信息系统系300401兰巧玲
河北工业大学经济管理学院信息管理与信息系统系(300401) 李 杰 兰巧玲
社会基本医疗保险制度是社保体系的重要组成部分,医保基金则是其物质基础。医疗保险欺诈是指个人或组织故意欺骗或歪曲事实以使其本人或组织获得不法医疗保险资金的行为[1],它会对医疗保险基金安全构成巨大威胁。然而,传统的欺诈风险识别主要依靠人工审核,成本高、效率低且准确率偏低。因此,科学高效地预测欺诈风险对于反欺诈工作的展开具有重要意义。
随着大数据技术的发展,数据挖掘方法因其从海量数据中高效提取有价值信息的优势,逐渐被应用到疾病诊断、欺诈和异常检测等医疗卫生领域[2]。国内外许多学者已采用决策树[3]、神经网络[4]和贝叶斯[5]等数据挖掘的方法来构建预测模型。XGBoost(eXtreme Gradient Boosting)算法[6]通过集成多棵决策树并使用梯度提升方法进行了改进,其运算速度快、预测准确且不易过拟合。由于现实中欺诈数据与正常数据比例通常差距较大,因此需借鉴EasyEnsemble方法[7],利用集成学习机制进行数据平衡处理。因此,本文旨在通过建立基于EasyEnsemble方法的XGBoost集成模型对社会基本医疗保险参保人进行欺诈风险预测,从而有效控制医疗保险欺诈行为,节约医保费用,并为审核专家的后续处理提供科学的决策支持。
资料和方法
1.资料来源与数据处理
数据来源于2017年阿里巴巴天池大数据竞赛的“精准社保”赛题,其包括2016年6至12月20000名参保人员的183万条医疗费用记录和653万条消费金额明细与消费内容,以及参保人员的欺诈标签(0-正常;1-欺诈)。其中包含欺诈参保人1000个,正常参保人19000个,欺诈与正常样本比例为1∶19,具有严重不平衡的特征。医疗费用记录表包括各项费用发生、申报和审批金额等69个特征变量。消费金额明细与消费内容表则包含服务项目、单价和数量等11个特征变量。
通过剔除无效变量、缺失值填充以及数据整合等预处理,将每名参保人的记录合并为一条数据,得到20000名参保人的数据。参考以往研究并考虑现实欺诈行为表现形式,构造基于不同维度下诊疗费用或项目数量的总和、均值等统计量的特征变量并进行标准化处理。最终得到827个特征变量,加上标签变量,与20000个训练集样本构成维度为20000×828的样本-特征矩阵。
2.社会基本医疗保险参保人欺诈风险预测模型建立
社会基本医疗保险参保人欺诈风险预测模型建立的主要步骤为:(1)将数据集D通过分层抽样随机划分为5个大小相同的互斥子集Dn(n=1,2,…,5),每次用1个子集作测试集,其余作测试集,得到5组数据集Di(i=1,2,…,5),各组测试集和训练集分别表示为Dxi和Dci;(2)基于EasyEnsemble思想对每组训练集Dxi中的正常样本应用Bootstrap法进行10次欠采样,每次抽取与欺诈样本数量相同的样本数,并分别与欺诈样本集组合得到10个训练子集Dxij(j=1,2,…,10);(3)分别运用Dxij进行XGBoost模型训练,得到10个基评估模型,并将该模型用于预测各组测试集Dci的欺诈概率,最后通过求均值进行模型集成,得到各组Di的测试结果;(4)返回5组数据集Di的测试结果均值;(5)重复上述步骤10次,返回10次测试结果的均值。
3.编程实现与性能度量
本文运用Python 3.6.1作为统计分析的工具,用其中的numpy、pandas、sklearn.model_selection和imblearn.ensemble等模块进行数据处理,xgboost模块进行模型训练与预测,sklearn.GridSearchCV进行网格搜索以确定模型参数。
医疗保险欺诈风险预测的实质是预测是否存在欺诈行为,这是典型的二分类问题。现实数据中欺诈样本远少于正常样本,而欺诈样本的误判成本远高于正常样本,研究的最终目的是要识别少数类欺诈样本。因此,定义预测结果真阳性为TP、假阳性为FP、真阴性为TN、假阴性为FN,则本文主要依据预测结果的准确性(accuracy,ACC),即全部预测样本中真阳性(欺诈)与真阴性(正常)的样本数所占比例,如式(1)所示;平衡预测值(balance predictive value,BPV),即阳性预测值(PV1)与阴性预测值(PV0)的加权平均值,如式(2)所示;平衡敏感性(balance sensitivity,BS),即敏感性(S1)与特异性(S0)的加权平均值,如式(3)所示;F1,即BPV和BS的调和平均数,如式(6)所示;AUC值(area under ROC curve),即感受性曲线(ROC)下的面积这四个指标来评估模型性能。
ACC=(TP+TN)/(TP+FN+FP+TN)
(1)
BPV=ω1×PV1+ω0×PV0
(2)
BS=ω1×S1+ω0×S0
(3)
其中,ω1、ω0分别为欺诈与正常的样本占总样本数比例权重,且:
(4)
(5)
F1=2×BPV×BS/(BPV+BS)
(6)
结 果
1.模型性能度量
为验证模型稳定性,本文对数据样本进行了10次5折交叉验证。该模型在10组测试集上预测结果的ACC、BPV、BS、S1、F1以及AUC评估指标如表1所示。

表1 10组测试集下各模型性能度量结果
由表1可知,该模型在10组测试集下的平均准确性、平衡预测值、平衡敏感性、F1和AUC值分别为0.83、0.95、0.83、0.89和0.92,表明模型整体性能良好。其中敏感性S1,即实际为欺诈的样本被正确判定为欺诈的比例为0.83。此外,识别出的欺诈样本的总报销费用占所有欺诈样本总报销费用的比例,即运用该模型进行预测总共能够预防的医保基金损失比例达到91.27%。上述指标的标准差均小于0.05,亦表明模型稳定性良好。由此可知,本文所构造的基于XGBoost算法的风险评估集成模型预测效果较好,且在不同测试集中模型稳定性表现良好,因此能够用于合理有效地预测社会基本医疗保险参保人的欺诈风险。
2.预测变量重要性测度
最终有203个特征变量被用于欺诈预警模型构造,根据“帕累托法则”,本文对该模型中排名前20%的重要特征变量进行分类汇总并计算其重要度均值,结果如表2所示。
由表2可知,重要预测变量主要可划分为“记录数量”、“消费金额”、“就诊规律”和“报销规则”四大类,其中“药品与治疗相关费用记录数量”、“月初、月中和月末药品、治疗等费用总额及其各阶段增长比例”以及“总费用”是最重要的特征。进一步对上述特征变量进行描述性统计分析以及独立样本T检验,比较欺诈与正常参保人的行为差异,如表3所示。

表2 特征变量重要度统计
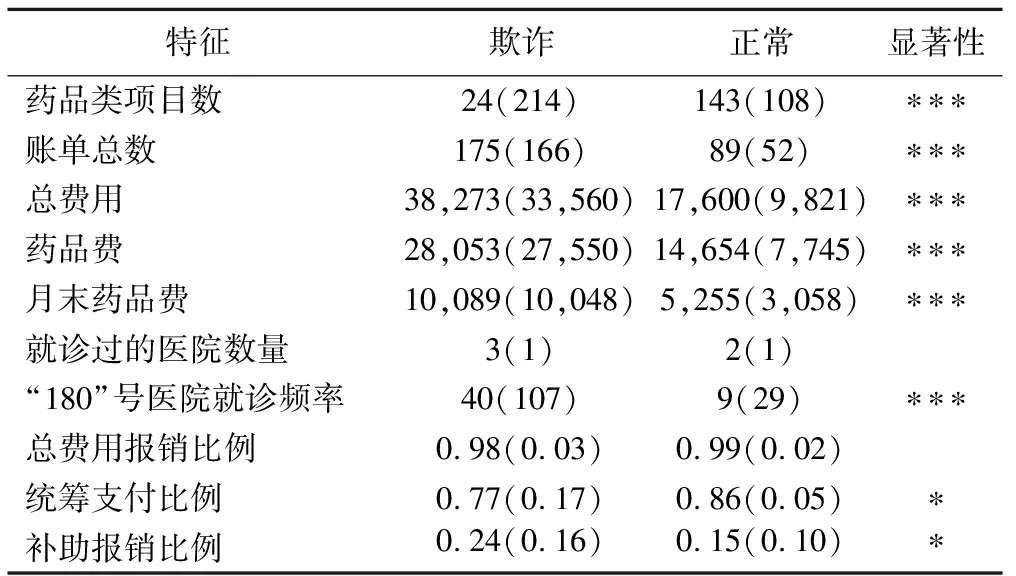
表3 欺诈与正常参保人特征差异
*:二、三列数据采用“均值μ(标准差σ)”形式表示,T检验显著性:*P<0.1,**P<0.05,***P<0.01。
由表3可知,从数据整体稳定性看,欺诈者的各项指标数据离散程度表现均相对较高,表明其行为特征未呈现出稳定的规律性,这也是导致欺诈行为隐蔽性较高,难以识别的原因之一。欺诈与正常者的行为模式主要在三个方面产生显著差异:(1)项目数量和账单数量;(2)总费用、药品费和月末药品费;(3)“180”号医院就诊频率。实际上,前两方面均显示欺诈者总体消费水平及频率,尤其是药品类项目数量少而费用高,存在开高价药的嫌疑,且可能月末集中消费。此外,欺诈者在“180”号医院就诊频率远高于正常者,意味着该医院可能存在监管漏洞或医患合谋欺诈行为。最后,欺诈者的补助报销比例略高于正常者,而后者的统筹支付比例略高于前者。两者就诊过的医院数、统筹报销比例等无差异。
讨 论
本文基于我国社会基本医疗保险诊疗历史记录的大规模真实数据,运用数据挖掘中的XGBoost算法构造社会基本医疗保险参保人欺诈风险预测集成模型,从而预测参保人的欺诈风险,进行参保人欺诈预警。模型预测结果准确率较高,且具有较强稳定性。
在该模型中,药品类项目数量、月末药品费和总费用等是重要的预测变量。实际上,参保人员实施欺诈行为的根本目的是为套取医保基金,因此其行为特征必定会通过诊疗费用记录显现。其中,欺诈人员所产生的药品类项目较多,尤其是月末药品费用明显高于正常人员。因此,有可能存在被他人使用保险证/卡非法申领保险金以及主动要求医院开具本人不必要的药品由他人代用等情况[8]。甚至可能存在诈骗团伙诱使参保人出借尚余报销额度的医保卡,从而在月末集中非法开药,倒卖医保药品的问题。此外,欺诈人员在某医院的就诊频率明显高于正常人员,因此可以合理怀疑医患合谋欺诈的情况。事实上,参保人想实施欺诈,往往需要医疗机构工作人员的支持、纵容和配合。其主要表现为大处方、人情方、营养方,以及为患者虚开发票骗取医保基金等[9]。
在本研究模型基础上开发智能化索赔欺诈识别系统,能够基于大量医疗保险数据进行科学分析,有效挖掘参保人的潜在行为模式。进而开展高效的审核工作,对欺诈人员进行有效预测,及时发出报警信息,防范欺诈行为的产生。从而有效保障医保基金安全,维护社会医保公平性,推动医保体系有效运行。
