潜在类别分析在精神分裂症患者焦虑情况研究中的应用*
2019-03-19汤艳清
刘 壮 张 悦 汤艳清 王 菲△
【提 要】 目的 探讨潜在类别分析在精神分裂症患者焦虑情况研究中的应用。方法 运用LatentGold 4.5软件,根据精神分裂患者的焦虑情况调查结果,对其进行潜在类别分析。结果 本研究发现3类别模型能够较好地解释精神分裂症患者的焦虑情况,即“焦虑低危组”、“焦虑中危组”和“焦虑高危组”,每个类别的人数分别为52人、48人和17人。结论 潜在类别分析可用于精神分裂症患者的焦虑情况研究,揭示精神分裂症患者的焦虑分类情况,为针对性地制定精神分裂症患者焦虑症状的临床治疗方案和干预措施提供参考依据。
精神分裂症(schizophrenia,SZ)是一组病因未明的重性精神疾病,多在青壮年缓慢或亚急性起病,临床上常见的表现为幻听、妄想、胡言乱语,从而造成思维、感知、行为和情感等多方面的障碍以及精神活动的不协调[1-2]。精神分裂症由于病程长、复发率较高,伴有后遗症和不完全的社会行为的恢复,导致患者劳动能力降低,给患者家庭及社会带来较大的经济负担[3-4]。精神分裂症患者由于长期的治疗、经济上的困难、负面情绪等影响,易产生巨大的精神压力,导致各类精神疾病的发生[5]。焦虑和抑郁情绪是精神分裂症最常见的精神障碍表现。焦虑情绪是影响疾病临床过程和恢复的重要因素,严重影响着病人的生活质量[6]。
目前,关于精神分裂症患者焦虑情况的研究多集中于临床治疗效果评价和心理干预[7-8],对于焦虑内在本质的探究较少。潜在类别分析是通过潜在类别模型(latent class model,LCM)实现的,通过潜在的类别变量诠释外显的类别变量之间的关联,使外显变量之间的关系可以利用潜在类别变量来估计,进而维持其外显变量之间的局部独立性。LCM综合了结构方程模型与对数线性模型思想,形成了自身的优势,目的在于以最少的潜在类别数目来解释显变量之间的关联,达到局部独立性。LCM的分析技术不但弥补了因素分析仅能处理连续潜在变量的不足,而且分类潜变量的引入提高了其分析价值,使研究者能够透过概率更加深入地了解分类变量背后的潜在影响因素[9-11]。因此,本研究拟探讨潜在类别分析在精神分裂症患者焦虑情况中的应用,进一步分析不同焦虑类别人群的特征和心理差异,揭示心理行为干预和临床治疗的重点人群,为针对性地制定精神分裂症患者的临床治疗方案和干预措施提供理论依据。
研究对象与方法
1.研究对象
本研究对象选自2012年2月-2018年3月在中国医科大学附属第一医院精神医学科和沈阳市精神卫生中心就诊的门诊患者和住院患者,并由两名副教授以上级别的精神科医生通过一致性检验后进行诊断。
纳入标准:对先证者及其家属通过结构式临床会谈确定患者符合《精神疾病诊断与统计手册》(The Diagnostic and Statistical Manual of Mental Disorders,DSM-IV)的SZ诊断标准。排除标准:(1)重大疾病史,包括可能引起脑组织改变的疾病,如高血压、糖尿病、肿瘤转移性疾病;(2)神经系统异常的疾病史,包括头部创伤、癫痫发作、脑血管性疾病或脑瘤,以及神经变性性疾病;(3)可能引起精神障碍症状的躯体疾病;(4)IQ总分低于70分;(5)实验前有酒精或毒品使用至少一周;(6)幽闭恐惧症。
2.调查工具
汉密尔顿焦虑量表(Hamilton Anxiety Scale,HAMA)由Hamilton于1959年编制,主要用于评定精神症患者的焦虑症状的严重程度。HAMA量表共14个条目,包括焦虑心境、紧张、害怕、失眠等,采用李克特五级评分。0~4分分别表示无、轻、中、重和严重,总分如小于7分,病人就没有焦虑症状;超过7分,可能有焦虑;超过14分,肯定有焦虑;超过21分,肯定有明显焦虑;超过29分,可能为严重焦虑。
调查开始前,进行调查员集中式培训,并对调查问卷统一编号。现场调查时,由调查员指导问卷的填写;问卷回收过程中,及时检查问卷的完整性,提高问卷的应答率。采用两名经过培训的调查员进行双人录入,确保数据资料的真实可靠。
3.统计方法
调查数据采用Epidata 3.1软件录入并逻辑校正,数据的潜在类别分析采用LatentGold 4.5软件进行。
(1)潜在类别分析基本模型
LCM假定任意两个观测变量之间的关系可以由潜变量解释。假设潜变量X有t个潜类别;A、B、C为3个显变量,其水平数分别为I、J、K。
最基本的LCM为:

(2)模型拟合与参数估计
在LCM中,模型求解的方法主要是极大似然法,迭代过程中常用的算法有EM(expectation-maximization)、NR(newton Rapson)等不同算法。其中EM算法最为常用。LCM模型适配检验方法主要有Pearson检验、似然比卡方检验以及信号评价指标,其中,AIC准则(akaike information criterion)和BIC(bayesianinformation criterion)是LCM选择中广泛使用的信号评价指标[12]。两者均建立在似然比卡方检验的基础上,可用于比较对参数进行不同限制的模型,两者值越小,表明模型适配度越好[13]。
(3)潜在分类
在确定最优模型以后,需要将各个观察值归类到适当的潜在类别中,说明观察值的后验类别属性,即潜在聚类分析。潜在分类依据贝叶斯理论,分类概率的计算公式如下:
结 果
1.探索性潜在类别分析
本研究纳入精神分裂症患者121人,剔除问卷质量不合格者4人,共纳入研究117人。患者年龄11~51岁,其中,男性患者37人,女性患者80人。应用LatentGold 4.5 软件,对117名精神分裂症患者的焦虑情况进行分析。通过探索性潜在类别分析,拟和1~5个类别模型,结果见表1。根据模型适配指标及理论,BIC从1分类模型到3分类模型逐渐减少,到4分类模型开始上升。在5个模型中,选择BIC值最小的3分类模型为最佳模型,因此本研究可构建一个表示精神分裂症患者焦虑情况的3分类潜变量。

表1 精神分裂症患者焦虑情况潜在类别模型的适配指标
2.潜变量各类别命名
根据选定的精神分裂症患者焦虑情况3分类潜在类别模型,分别计算出每个潜在类别对应的条件概率,对患者的焦虑情况进行评价。
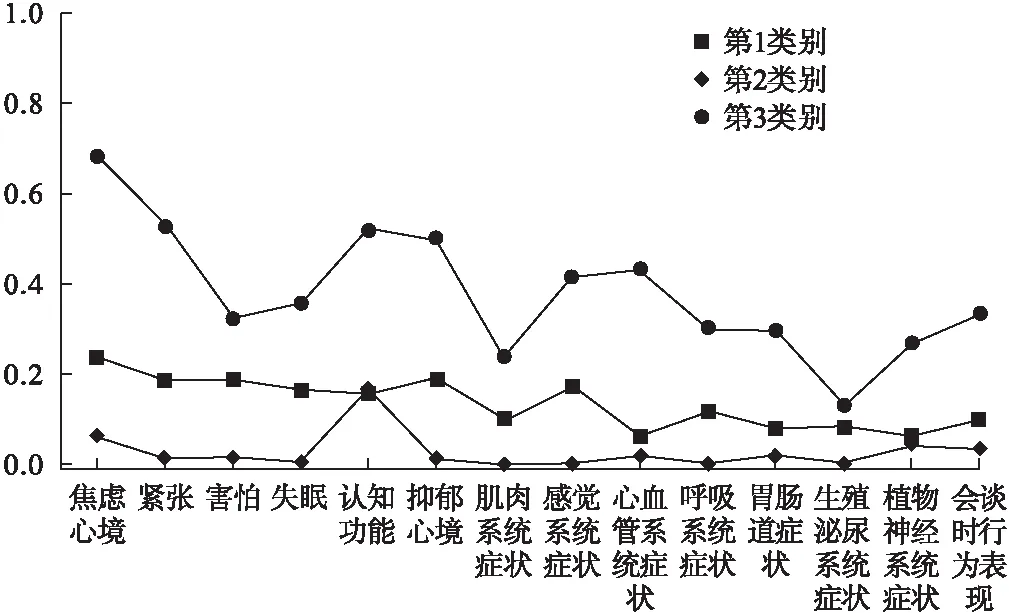
图1 精神分裂症患者焦虑情况3个潜在类别的条件概率分布图
图1所示为3类别模型的条件概率分布情况。在第1类别中,精神分裂症患者在焦虑心境、紧张、害怕、失眠、认知功能、抑郁心境、肌肉系统症状、感觉系统症状、心血管系统症状、呼吸系统症状、胃肠道症状、生殖泌尿系统症状、植物神经系统症状和会谈时行为表现的得分中,多倾向于选择1分和2分,即此类别患者在14个条目方面症状轻微,但不影响生活和活动,因此我们将其命名为“焦虑中危组”。在第2类别中,精神分裂症患者在14个条目得分为0的可能性最大,即此类别患者几乎没有症状表现,因此我们将其命名为“焦虑低危组”。在第3类别中,患者在焦虑心境、紧张、失眠、抑郁心境、心血管系统症状、呼吸系统症状、胃肠道症状、植物神经系统症状和会谈时行为表现的得分中,多倾向于选择3分,在害怕、认知功能和肌肉系统症状中多选择4分,即此类别患者症状重、需加处理,已影响其生活或活动,因此我们将其命名为“焦虑高危组”。
3.精神分裂症患者焦虑情况的个体归类
潜在类别分析最后需求出HAMA量表14个条目的不同组合分配到每个潜在类别的概率,将117名精神分裂症患者的焦虑情况归类到适当的潜在类别群体中。
HAMA量表14个条目的不同组合归类结果见表2。以14个条目得分均为0的组合为例,被分到第1个潜在类别的概率为0.0126,被分到第2个潜在类别的概率为0.9874,被分到第3个潜在类别的概率为0,其中被分到第2个潜类别的概率最高,因此此变量组合被归类到第2个潜在类别群体。同理可知,117名精神分裂症患者的焦虑情况可以被分为3个潜在类别,每个类别的人数分别为48,52和17,即焦虑低危组52人、焦虑中危组48人、焦虑高危组17人。
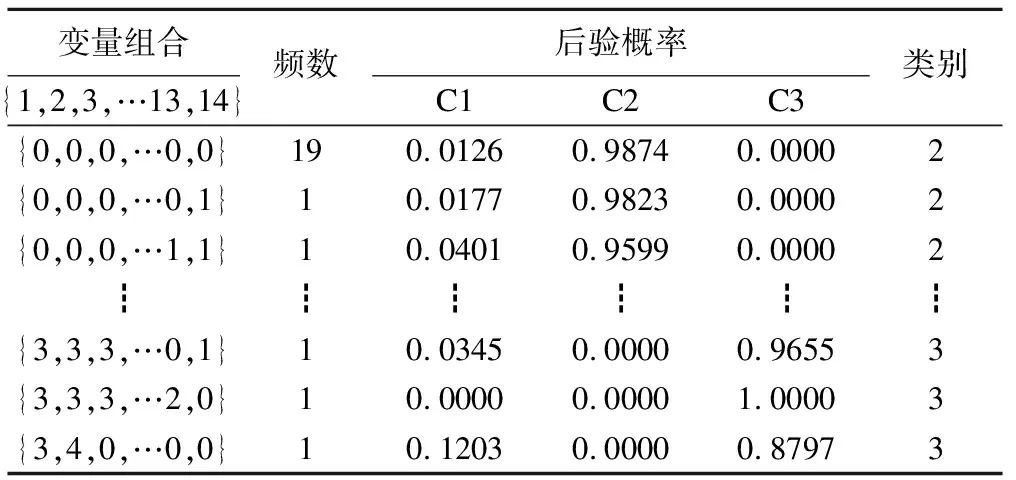
表2 潜在类别模型个体分类结果
讨 论
我国精神分裂症的患病率达1%,精神分裂症患者在工作和生活中很容易受歧视。患者长期遭受区别对待,和人们对精神疾病带有的强烈排斥心理,会使精神分裂患者与社会格格不入,产生焦虑的情绪。目前,我国对于精神分裂症患者的焦虑研究,多集中于临床用药和心理护理的效果评价分析。虽然药物治疗和心理护理可以有效改善多数患者的焦虑情况,但有部分患者的治疗效果并不令人满意,其原因可能是忽略了焦虑的其他因素。
潜在类别分析能对许多抽象且无法直接观测的指标进行测量与分析,将复杂的人类行为和社会现象进行数据化简和整合,有助于我们观察数据背后的潜在结构,发现积极的意义[14]。本研究基于潜在类别分析,将117名精神分裂症患者的焦虑情况分为3个类别,分别为焦虑低危组、焦虑中危组和焦虑高危组。其中,焦虑低危组有52人,占44.44%,这类患者的特点是几乎没有焦虑症状。针对此类患者,医护人员可以积极做好其心理疏导工作,加强患者的自我情绪控制,减少焦虑情绪的发生。焦虑中危组患者48人,占41.03%,此组患者有轻微的症状,但对其生活不产生影响。对于这类患者,积极的心理护理、有效的指引和鼓励可能有助于患者健康快乐的生活和工作。本研究中焦虑高危组有17名患者,占14.53%。他们的焦虑症状较重,已经影响了生活和工作。这类患者可能不仅需要心理护理,还需要联合药物的治疗。
本研究提示,潜在类别分析可以将精神分裂症患者的焦虑情绪分为不同的类别。每一类别的患者具有不同的心理状态,反映出的体征也不完全相同。临床医生可以针对不同患者采取不同的治疗方案,有效改善患者的心理状态,缓解患者的焦虑情绪。
