基于k-means算法的网络数据库入侵检测技术
2019-03-14高彩霞
高彩霞

摘要:信息化時代下网络已经全面覆盖人们的日常生活、工作各个方面,网络技术的不断发展极大地促进我国各个行业的发展,网络办公已经成为企业工作的常态,但也由于网络技术的发展各种网络病毒与黑客攻击、入侵技术也随之增长,对网络环境的安全危害性较大,优化网络安全的防御工作,是当下网络技术发展的新方向。笔者以基于k-means算法的网络数据库入侵检测技术为目标,从现阶段入侵检查技术与传统聚类算法存在的问题入手,通过实验反映改进进K-means算法,旨在为现阶段网络入侵提供新的研究反向与视角。
关键词:k-means算法;网络数据库;入侵检测技术
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2019)01-0034-02
1 入侵检测技术现状与数据挖掘
网络技术的飞速发展既为人们生活带来了便利,也出现了安全问题,目前入侵检测与预防基本都是依靠防火墙技术,但日趋复杂的网络环境,对入侵检测技术的要求更高。不仅要实施监视网络流量,还要依据网络数据传输节点对怀疑数据进行标准对比,及时发现系统漏洞以及网络攻击行为。还要承担起阻断危险来源节点,保护自身网络安全的职责,提高网络安全等级。就近年来电网企业所遭受的公网IP与内网IP恶意攻击来看,只依靠各个城域网与广域网之间的防火墙与IPS等安全设备,无法全面检测信息网络技术的中的异常行为,反应速度,也达不到防护要求。因此近年来,k-means算法、BP神经网等逐渐应用到入侵检测中,在数据流量包的基础上甄别各种攻击行为和危险语句段,避免网络信息运行泄露问题。保障信息网络的安全运行。数据挖掘,是从数据库中知识挖掘,提取出大量的未知且具有用户期望价值的信息,现阶段数据挖掘也成为如今检测技术之一,通过数据挖掘结果调整策略,减低风险,提高决策的正确率。传统入侵检测系统中植入数据挖掘技术,是利用数据挖掘算法,在网络海量数据中,过滤掉多数正常数据模式,针对异常要入侵模式构建入侵检测模型,以提高检测效率,优化检测效果,减少误检率[1]。
2 基于K-means 算法的检测入侵系统结构
基于k-means算法的检测入侵系统,是新时代网络环境下安全防御提出了的新型网络安全保护技术,从网络系统中运行数据,监控和与保障安全性如入手,依据k-means算法的聚类算法、迭代算法,更加有效提取网络信息,深入到统计学、电子计算以及数据库信息整合等多个领域,对网络运行状态进行策略,构建网络正常状态下的模,一旦用户超出了预设的模型,就被定位网络入侵,以此提高网络入侵检测的效果,设置好正常状态的行为模式以及预设模式,基于K-means 算法构建网络异常检测模型,在大数据环境下以提高数据选取的准确性和误报率,缩短数据选择时间。主要的K-means 算法的检测入侵系统构建框架图1:
k-means算法主要应用于数据审计中,利用模式识别方法分析数据库,构建模式系统图,在海量网络数据中辨认出有效的出具,提取出特征码,并按照类型标准进行分类。聚类算法在应用中,将数据输出转变为若干个聚类,计算各个数据之间的差异,用d(i,j)= |x i1 -x j1 | 2 +|x i2 -x j2 | 2 +...+|x ip -x jp | 的算法公式,计算数据间的距离。然后再假设数据集变量为i,j,具有P个属性赋权值,用d(i,j)= w 1 |x i1 -x j1 | 2 +w 2 |x i2 -x j2 | 2 +...+w p |x ip -x jp | ,计算出数据差异距离[2]。
从基于K-means 算法的检测入侵系统的发生器、分析器、响应元件及事件信息数据库为主,对入侵网络中的数据库进行检测,通过检测途径获取确切的信息,对用户的一系列活动进行监控,从而获取系统运行结构与网络数据库中的弱点进行识别与反馈,更便于入侵信息检测,解决网络运行中的异常问题,保障网络系统的安全性运行和信息完整性、准确性。所以 K-means算法在应用中,要明确其基本思想,以便于切实监控各种违反系统的行为,实现控制与株洲西,对网络段中发生的入侵实现尽早控制。 K-means算法的本质是采用包含n个数据的数据集和产生类聚的个数,把n个数据化分成K个子集,针对不同的类聚之间的数据进行计算,划分出同类聚类以及不同类聚,每个聚类以中心值的形式进行表述,通过计算聚类的所有数据平均值,获取中心值。
3 基于K-means 算法的检测入侵系统的构建
基于K-means 算法的检测入侵系统的结构,在设计中采用了结构体系,是以三段式的入侵信息数据具体计算数据,依据统计学的信息保存库以及网络探寻信息搜索器、网络入侵信息分析数据库的控制器件构成,利用入侵信息,在网络检测系统中,依托于加密传输协议实现远程数据传输,将数值运输到总系统的信息库后,再利用数据审计与K-means 算法,对整个系统进行检测,从而实现整个检测系统。数据信息特征码提取,不能直接在海量数据中审计,要构建网络数值抓取库,依托于数据挖掘与 Snort 网络特征,用正常模式下新的数据进行比对,过滤掉正常数据,将异常数据通过Snort 网络数值抓取库的 Libpcap设置的网络数值,提取出特征码。数值抓取库的设置如下,先创建好Snort 网络数值抓取库以及数值保存库,然后对结构查询信息的校本类文件类型进行核查,设置好table后,再对snort 中的 conf 文件进行编辑,实现Plu-gin 中数据值的全面导出到保存库中,具体操作代码如下:#/usr/local/bin/mysqladmin-u root-p create snort
#/usr/local/bin/mysql admin-u
Root-p create snort archive
#/usr/local/bin/mysql-u
Root-D snort-p
#/usr/local/bin/mysql –u root -D snort_archive -p
utput database: alert, mysql, user=root password=abc123 db?name=snort host=localhost
构建好Snort 网络数值抓取库后,紧接着就要设置好web服务器的Apache。Apache设置一共有三步,一是扩展Apache的代码,通过代码设置,拓展mod_ssl代码,二设置好分析控制台的ACID的三个功能组间,将Adodb 数据库、ACID软件包、PHP图表类依次设置好,,三编辑ACID的配置文件,给Acid_conf.php赋予一定的变量。使用分析控制台程序ACID作为K-means 算法的使用器,对入侵事件和数据进行统计与分析,并将数据拓展到相关的数据库中,利用nmap工具对系统进行X-scan的扫描,将提取的特征码注入相关的入侵事件中[3]。
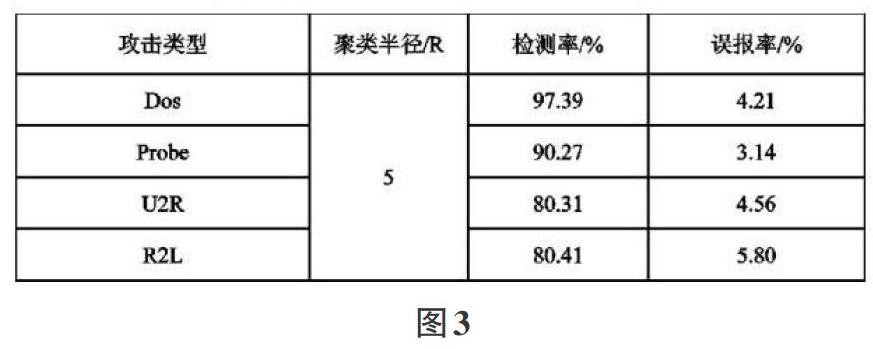
最后进行实验数据检测,笔者是采用 KDD Cpu99 网络攻击数据集,针对检测系统的运行对数据进行整理和分析,以MAT-LAB 软件的计算与仿真结果,分析利用 K-means 算法构建检测系统的检测率和误报率的影响因素。针对实验数据分析可知,适当聚类半径越大,误报率就越高,只有当阈值为5时,K-means 算法的检测率与误报率受聚类中心数量的影响,此时在四种不同类型攻击下,基于K-means 算法的检测入侵系统检测率较高。当聚类半径越大时,误报率就越大;由图 4 可得,当取阈值半径为 5 时,改的K-means 算法在检测率和误报率受到聚类中心数量的影响;由表1可得,当阈值半径为 5,在四种不同的攻击类型下,针对不同的攻击类型,改进的 K-means 在检测率和误检率上是有区别的[4-5]。
4 结束语
基于k-means算法改进现有的网络数据库入侵检测技术,是利用k-means的聚类算法、迭代算法,针对现阶段数据库入侵方式与入侵渠道,提出优化算法,以解决云改进传统聚类算法在伸缩性与数据定期更新中存在的问题,提高信息安全的防御效果,构建高效、科学、精准的数据入侵检测平台,优化网络入侵检测系统。
参考文献:
[1] 刘华春, 候向宁, 杨忠. 基于改进K均值算法的入侵检测系统设计[J]. 计算机技术与发展, 2016, 26(1): 101-105.
[2] 吴彦博. 基于数据挖掘的网络入侵检测关键技术的分析[J]. 职大学报, 2016(2): 101-103.
[3] 凤祥云. 基于K-Means聚类算法入侵检测系统研究[J]. 电脑知识与技术, 2016, 12(16): 49-51.
[4] 孙章才, 车勇波, 姚莉, 等. 基于改进K-means算法在电网企业网络入侵检测中的应用[J]. 信息通信, 2016(9): 12-13.
[5] 陈培毅. 基于K-means算法檢测网络安全可行性研究[J]. 自动化与仪器仪表, 2017(8): 102-103, 106.
