基于改进位置成词概率的微博新词发现算法
2019-03-14邹志文朱红泽李玲张大秀
邹志文 朱红泽 李玲 张大秀


摘要:针对传统的新词的提取方法无法有效地提取组合词(常用词和常用词组合)的问题,该文提出基于改进位置成词概率和N元递增算法的微博新词的提取。算法的核心任务是通过改进位置成词概率和邻接对结合来有效地提取由几个毫无相关的常用词拼接而成的新词,即组合词,从而提高算法的准确率和召回率。首先,对由几个微博话题下的一段时间内评论所聚合成的微博长文本进行预处理;然后,在N元递增算法查询的过程中,通过改进位置成词概率判断频繁字串的扩展方向;最后,通过对频繁字串剪枝来减少冗余字串。实验结果证明本文所提出的算法能够有效地提取微博新词中的组合词。
关键词:微博新词;位置成词概率;N元递增算法;组合词;
中图分类号:TP3 文献标识码:A 文章编号:1009-3044(2019)01-0001-02
1 引言
在微博平台上,不同文化的碰撞导致了新词的产生。这些新词借助微博平台快速的传播,被人们迅速熟知并加以应用,也会因此引发热议。在微博平台上,新词大部分是通过拼接几个毫无相关的常用词,以用来表达新的含义。
因此如何快速地提取组合词是微博新词的提取的一个研究热点。然而,由于微博文本与传统的文本有着很多不同,比如其具有文本短小、信息片段化、语言随意性等方面,所以传统的新词的提取方法可移植性差以及缺乏對组合词(常用词和常用词组合) 识别。
针对上述问题,本文提出基于改进位置成词概率和N元递增算法的微博新词的提取。首先,对微博文本进行预处理,去除和本文研究无关的内容,如停用词、链接、表情等。然后,在N元递增算法查询的过程中,通过对已找到的频繁N字串右邻接集合中的元素通过改进位置成词概率判断扩展方向。若大于预设的阈值,将其元素和频繁[N]字串组合成频繁[N+1]字串。最后,对频繁字串集进行剪枝。若集合中的元素的子集也存在于集合中,在集合中删除其元素的子集。
本文的组织如下:第2节介绍基于改进位置成词概率的微博新词发现算法的相关工作;第3节提出基于改进位置成词概率的微博新词发现算法;第4节对本文算法进行实验;第5节对本文进行总结。
2 相关工作
对于本文的微博新词的提取工作,国内外已有多数学者在此方面有过深入研究。梅莉莉[1]基于统计语言知识(包括词频、内部结合紧密性)对新词进行抽取。雷一鸣等[2]提出一种基于词语互信息模型和外部统计量的新词发现方法。夭荣朋等[3]提出了基于改进互信息(MI) 和邻接熵(BE) 的微博新词发现算法(MBN-Gram),解决了目前微博新词发现算法中缺乏对多字词(大于三字) 识别的问题。Shuai Zhang等人[4]提出了一种基于语法规则和统计信息新的词提取方法。为解决经典的统计量无法有效地区分新词与非新词的问题,SuQilong等[5]提出基于邻接熵改进的一种新统计量-加权邻接熵。
3 本文算法
3.1 微博文本预处理
由于单个微博文本短小、信息碎片化,所以各个词语统计量相近,从而无法有效地提取新词。为了避免这一问题,本文将单个主题下的一段时间内的微博文本拼接成微博长文本。然后删除微博长文本中与本文研究没有实质性影响的内容:1)删除微博长文本中含有“@用户名”字段。2)删除符号“#主题#”。该符号中的字段是用户的话题讨论点。3)对微博文本中的繁体字转换为简体字。4)停用词无法成为新词,故删除即可。
3.2 N元递增算法
N元递增算的基本算法思路:首先对文本进行扫描,统计单字字频。若大于阈值,将其字存放到频繁单字集。然后根据每个频繁单字的地址信息扫描语料并统计字频,若大于阈值,将其字存放到频繁二字集。最后,新产生的频繁字串写入文件后继续扩展,反复迭代,直到出现间隔符号或长度达到阈值。
由于N元递增算法仅仅通过字频获取频繁字串,所以需要对频繁字串进行统计量分析,以达到去除垃圾串(没用完整意义的字串)的目的。然而由N元递增算法所发现的频繁字串中垃圾串占绝大部分,这造成了搜索时间的极大浪费。为了解决这一问题,在N元递增算法扩展时通过统计量判断并对扩展集进行过滤。在搜索过程中删除垃圾串使得下一轮搜索规模变小,从而减少搜索时间。
3.3 改进位置成词概率
然而传统的统计量如“邻接熵”“双字耦合度”“位置成词概率”等无法很好地过滤垃圾串。若单凭借位置成词概率扩展字串并且过滤垃圾串,新词中组合词会被划分成两个常用词。为了解决上述问题,对位置成词概率和邻接熵进行改进。
定义1:邻接字概率
记频繁字串的右邻接集合[wordright=r1,r2,…rrightm]的统计字频为[fi,i=1,2,3…m],因此邻接字概率公式为:
[Pi=fifw] (1)
式(1)中的[fw]是频繁字串的字频。当右邻接集合中某个元素占有很大比例时,即邻接字概率很大,这表明此元素极有可能和频繁N字串组合成为频繁[N+1]字串。
定义2:字扩展概率
为了上文提到的问题发生,对其划分根据增加依据邻接字概率,因此字扩展概率的公式为:
[Pcmcn=α×Pn+(1-α)Pwordcn,1] (2)
公式(2)[ Pcmcn]是频繁字串[cm]扩展到频繁字串[cmcn]的概率,[cn]是频繁字串[cm]的右邻接集合的元素。[0≤α≤1]为偏好参数,用来调节字扩展概率中字扩展概率和单字位置成词概率的权重。
3.4 擴展集剪枝
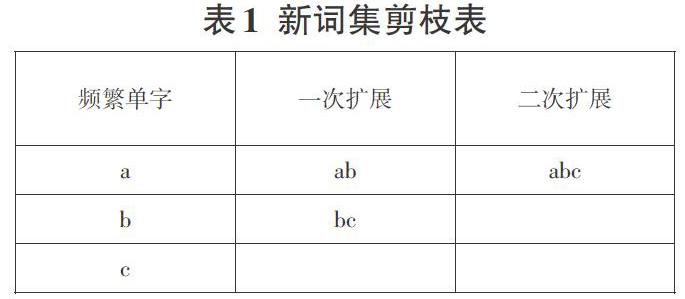
对新词“微信小程序”而言,“微信小程”“小程序”等均为垃圾串。在N元递增算法过程中,每次扩展词都放在扩展集,所以这类冗余字串在扩展集中很常见。针对这类垃圾串,文本通过删除子集对扩展集进行剪枝。如“abc”是新词,则“ab”“bc”是冗余字串,即新词“abc”的子集。具体扩展集剪枝的过程如下:
在第一次扩展后,扩展集为[a b c ab bc],对扩展集进行子集剪枝,扩展集为[ab bc]。同理,在第二次扩展后,扩展集为[ab bc abc],对扩展集进行子集剪枝,扩展集为[abc]。
3.5 算法流程
首先对单个话题下微博文本整合成微博长文本,对微博长文本预处理,去除停用词等。然后对微博文本扫描并统计其字频,查询出频繁字串,根据字扩展概率判断出频繁字串扩展方向。最后在每次扩展之后对扩展集剪枝,以达到删除冗余字串的目的。如此反复扩展迭代,直到无法继续扩展或长度达到阈值。所以基于改进位置成词概率的微博新词发现算法如下:
在上述算法中主要判断微博新词候选集中的频繁字串的扩展方向和进行子集剪枝。具体说明如下:
1) 步骤2到步骤4:判断单字是否是频繁模式,即判断单字字频是否大于预设的阈值,如果是,就将频繁单字存取下来。
2) 步骤6到步骤12:判断频繁字串的扩展方向,即右邻接集合中每个元素的字扩展概率是否大于预设的阈值。若是,频繁字串构和其元素成新的频繁字串;反之,将该元素从右邻接集合删除。
3) 步骤14到步骤16:对微博新词候选集进行子集剪枝。当候选集的每个词的字数大于5或者每个词的右邻接集合为空时,即每个词无法扩展,则停止扩展迭代。
算法的时间复杂度分析:
首先对微博长文本进行扫描,判断每个单字字频,此时时间复杂度为[On]。对每个字串分析每个右邻接集合中的每个元素,所以该算法的时间复杂度为[On2]。
4 实验分析
为了验证文本的提取微博新词的效果,本文从新浪微博上获取了关于某两个话题相关联的所有微博,将所有的微博文本拼接成长文本。应用本文算法对微博文本进行新词提取。实验结果如下表所示:
对于每个主题而言,提取的新词更多的是组合词,如“洪荒之力”“葛优躺”等。
5 总结
实验结果表明,基于改进位置成词概率的微博新词发现算法能够快速、准确地提取微博新词中的组合词,从而弥补传统的新词发现算法缺乏对组合词识别的空缺。
参考文献:
[1] 梅莉莉.基于领域特殊性和统计语言知识的新词抽取方法[D]. 北京理工大学,2006, 1.
[2] 雷一鸣, 刘勇,霍华. 面向网络语言基于微博语料的新词发现方法[J]. 计算机工程与设计, 2017(03):789-794.
[3] 夭荣朋,许国艳,宋健. 基于改进互信息和邻接熵的微博新词发现方法[J]. 计算机应用,2016,36(10):2772-2776.
[4] Shuai Zhang, Qianren Liu, Lei Wang. A Weibo-Oriented Method for Unknown Word Extraction[C]. 2012 Eighth International Conference on Semantics, Knowledge and Grids, 2012:209-212.
[5] Qilong Su, Bingquan Liu. Chinese new word extraction from MicroBlog data[C]. Machine Learning and Cybernetics (ICMLC), 2013 International Conference on,2013(04):1874-1879.
[6] Shunxiang Zhang, Yin Wang, Shiyao Zhang, and Guangli Zhu. Building Associated Semantic Representation Model for the Ultra-short Microblog Text Jumping in Big Data. Cluster Computing-The Journal of Networks Software Tools And Applications,2016,19(3):1399-1410.
