汉语词汇识别的声调时长效应 *
2019-03-12丁潼飞
于 秒 丁潼飞
(1 教育部人文社会科学重点研究基地天津师范大学心理与行为研究院,天津 300074)(2 北京外国语大学中国语言文学学院,北京 100089)
1 引言
默读时,人们能够听到自己大脑里发出所读文本的声音。这种声音一般被称为内在声音或内在言语。在科学术语里,内在言语一般指人们在阅读时激活的大脑中的语音信息表征(Huestegge,2010)。内在言语能够指导和帮助人们进行阅读,这种观点在差不多整个20世纪一直都被人们认为是正确的(Rayner, Pollatsek, Ashby, & Clifton, 2012)。
在过去的近30年中,心理语言学研究者们开始批判地审视阅读时内在言语的作用。研究者们关注的一个主要问题是内在言语是否只是阅读时听到的一个附带现象?还是它确实影响了读者对语言的加工和理解。一些研究认为,内在言语仅仅只是默读时听到的一种附带现象,其在默读时并非总是起作用(Carlson, 2009; Foltz, Maday, & Ito,2011; Halderman, Ashby, & Perfetti, 2012; Jun,2010)。而Fodor(1998, 2002)提出的内隐韵律假说(Implicit Prosody Hypothesis)坚持认为:即使在默读时,读者也可以产生句子语调、重音、停延和节奏等表征,这些表征均能影响读者对文本的理解。该假说提出后,得到了诸多研究的支持(如Ashby & Clifton, 2005; Breen & Clifton, 2011,2013; Drury, Baum, Valeriote, & Steinhauer, 2016;Hwang & Steinhauer, 2011; Jun & Bishop, 2015;Steinhauer, 2003; Stolterfoht, Friederici, Alter, & Steube,2007; Webman-Shafran, 2018; Yao & Scheepers, 2018)。
关于阅读中内在言语作用的研究主要聚焦在两种类型的语音表征上:音段语音和超音段语音。音段语音信息主要指的是影响词汇识别的元音、辅音等音素,而超音段语音主要指词层面以上的语音现象,如重音、节奏、语调等韵律信息。
1.1 音段及音段组合在语言加工中的作用
音段方面的研究主要集中在元音时长和辅音时长(指元音和辅音声学上的时长,元音时长指长元音、短元音时长,辅音时长指VOT长短)对词汇识别的影响(Abramson & Goldinger, 1997;Ashby, Treiman, Kessler, & Rayner, 2006; Lukatela,Eaton, Sabadini, & Turvey, 2004; Huestegge, 2010)。如Abramson和Goldinger(1997)比较了正字法长度相同但元音长度和词首辅音长度不同的词的词汇判断时间,结果发现,被试对含有长元音或长词首辅音的词(如wart、sake)的判断时间长于含有短元音和短词首辅音(如wade、tape)的词,这种时长效应发生在低频词条件下。这表明在词汇加工过程中,默读确实激活了内在言语。Lukatela等人(2004)在词汇命名任务中也报告了边缘的元音长度效应,也证实了元音长短影响词汇通达。Huestegge(2010)的眼动研究发现,元音长度影响词语的凝视时间。该研究中,被试阅读包括目标词(改变其元音长短和词频)的句子。结果发现,目标词为长元音时,被试对其的凝视时间大于含有短元音的目标词,证实了默读时语音信息扮演了重要角色。
一些研究发现预视信息与目标词词首音节信息一致时词汇识别更快(Ashby, 2006; Ashby &Martin, 2008; Ashby & Rayner, 2004)。如 Ashby(2006)通过操控预视词与目标词词首音节重音位置一致或不一致来考察重音位置对词语加工的影响。研究发现,在低频词条件下,与词首音节重音位置不一致(如预视词为“pos_zvzv”, 目标词为“position”)条件相比,当预视词词首音节重音位置(如“po_ zvzvz”)与目标词词首音节重音位置(如“position”)一致时,被试对目标词的加工时间更快。Ashby和Rayner(2004)使用带有CV起始音节 (如DE.MAND) 或者CVC起始音节 (如LAN.TERN) 的目标词,操控启动词与目标词起始音节匹配或者不匹配。研究也发现,与词匹配的预视的首次注视时间短于不匹配的预视的首次注视时间。这些研究为默读时的内在言语作用提供了来自多层次语音表征的证据。
1.2 超音段信息在语言加工中的作用
大量研究发现,内隐韵律边界(Hirose, 1999;Hwang & Schafer, 2009; Luo, Yan, & Zhou, 2013;Quinn, Abdelghany, & Fodor, 2000; Swets, Desmet,Hambrick, & Ferreira, 2007; Traxler, 2009)、内隐重音(Ashby & Clifton, 2005; Breen & Clifton, 2011,2013; Speer & Foltz, 2015)、内隐语调(Abramson,2007)等均影响语言加工。
很多研究考察内隐韵律边界在语言理解中的作用,如Hwang和Steinhauer(2011)采用ERP技术考察韩语歧义句加工时发现,主语是长名词短语时诱发了韵律边界成分CPS,名词短语后的内隐韵律边界的延迟插入会诱发P600成分。Steinhauer和Friederici (2001)让被试默读局部歧义句,当解歧的韵律边界出现时诱发了CPS成分。一些研究通过在句法歧义句和非歧义句中插入逗号的方法来探讨内隐韵律边界的作用。如Luo等人(2013)使用逗号作为韵律边界标记,放置在歧义句的解歧位置,结果发现,逗号和韵律边界线索一样,影响词汇加工。
有些研究通过眼动实验来考察默读时词汇重音对词汇识别影响。研究发现,读者默读时也激活了词汇水平的韵律信息。如Ashby和Clifton(2005)考察被试阅读带有一个或两个重读音节的目标词的眼动差异。研究发现,与有一个重读音节的词(如intensity)相比,被试加工拥有两个重读音节的词(如radiation)花费的时间更长。Breen和Clifton (2011) 在被试阅读打油诗的同时测量被试的眼动情况。打油诗中末尾词为重音交替变化的名动或名形同音异义词 (如PREsent, preSENT),词的重音通过匹配或不匹配的打油诗韵律模式来实现。研究发现,读者阅读不匹配末尾词重读模式时花费了更多的加工时间。表明读者在默读时,产生了一种内隐的重读模式,影响同音异义词的加工。
另外,Abramson (2007)通过听觉呈现一个语调模式与句末词一致或不一致的词,考察被试加工陈述句或疑问句句末目标词的情况。研究证实了听觉呈现词的语调模式与视觉呈现的句末词语调匹配时加工更加容易。
前面我们已经从音段及超音段两个大方面回顾了内在言语作用的一些证据。学者们从不同层面探讨了内在言语在语言加工中的作用,取得了很多研究成果,但关于内在言语作用的研究还存在一些有待于继续深入探讨的问题:(1)现有的有关内在言语作用的研究绝大多数均是在拼音文字体系的语言中发现的,而对汉语内在语言作用的研究较为少见。拼音文字体系的语言多属于表音体系的语言,语音与正字法的关系相对透明,而汉语属于表意体系的文字,其正字法与语音本身不如拼音语言那样透明。因此,内隐韵律是否对汉语这种表意体系的语言的加工也同样起作用?(2)在词汇识别层面,以往研究多集中在元音和辅音时长对词汇识别的影响,声调时长信息是否也影响词汇识别?汉语与印欧语系在音系上的一个重大差别即是汉语是有声调语言。声调不仅是汉语音节结构的重要组成部分,同时它又像英语等语言的词内重音一样,属于超音段信息,韵律信息。声调是否影响汉语词汇识别是一个值得研究的问题。
因此,为了进一步探讨内在言语的作用及其跨语言的普遍性,本研究拟通过两个实验来探讨这一问题。实验一从声学角度探讨汉语四个声调的时长是否存在差异;实验二在实验一的基础上探讨声调时长对词汇识别的影响。
2 实验一: 汉语声调时长差异的声学分析
2.1 研究方法
2.1.1 被试
被试为15名普通话流利(普通话水平二级甲等及以上)的大学生,视力或矫正视力正常。被试实验后均获得一份礼物。
2.1.2 实验设计
实验采用单因素四水平被试内设计。四个水平为普通话的四个声调调类,即阴平、阳平、上声和去声。
2.1.3 实验材料
从国家语委语料库中随机选择各类调类单音节词若干,控制各类调类词中送气擦音,塞擦音的数量以及各类调类词的词频和笔画数,最后选定80个单音节词,每个调类(阴平如“多”“包”,阳平如“拔”“夺”,上声如“宝”“百”,去声如“报”“拜”)各20个。词频(次/两千万)及笔画数均值见表 1。
统计分析发现,词频主效应不显著,F(3,57)=0.76,p>0.05,η2=0.04,笔画数主效应也不显著,F(3, 57)=0.36,p>0.05,η2=0.02。

表 1 80 个单音节词的词频和笔画的均值及标准差(括号内)
2.1.4 实验程序
将80个单音节词(每个调类20词)打乱呈现给被试。请被试事先熟悉实验材料,确认每个单音节词的发音,然后大声朗读每个单音节词。采用praat声学软件对被试的朗读进行录音,采样率为11025 Hz,单声道。录音后采用praat进行语音标注并采集被试朗读的80个单音节词的时长数据。
2.2 结果
统计分析发现:四个声调时长被试分析和项目分析差异均显著,F1(3, 42)=236.04,p<0.001,η2=0.94,F2(3, 57)=978.81,p<0.001,η2=0.98。两两比较发现,上声时长均长于其它三个调类的时长,ps<0.001,去声时长均小于其它三个调类的时长,ps<0.001,阴平时长与阳平时长无显著差异。这表明,在普通话的声调时长中,上声时长最长,去声时长最短。
2.3 讨论
实验1研究发现,普通话的四个声调中,上声时长最长,而去声时长最短。这与刘复(1924)、白涤洲(1934)、石锋(1991)等对北京话单字调调长差异的研究结论一致。与邓丹,石锋和吕士楠(2006)、冯勇强,初敏,贺琳和吕士楠(2001)以及宋雅男,何伟(2005)研究结论略有不同,造成结论不同的主要原因之一是采用的统计方法不同。前人研究多数仅是对声调时长均值的比较,而非进行统计分析,这在一定程度上影响了研究的科学性。为了较为准确地判定汉语声调的时长差异,实验1采用统计分析方法重新分析了汉语四个声调调长的差异。另一原因是是否在自然语流中测量声调时长。由于实验1主要探讨声调时长在词汇识别时的差异,暂不关心单音节词处于语流中的情况,从单音节词的声调时长判断来看,邓丹等人(2006)研究也发现上声词时长最长,冯勇强等人(2001)在自然语流中也发现去声词时长最短。冯隆(1985)研究发现目标词处于句末时上声词时长最长,阳平词时长次之,阴平词时长较短,去声词时长最短,与本研究结论大致一致。
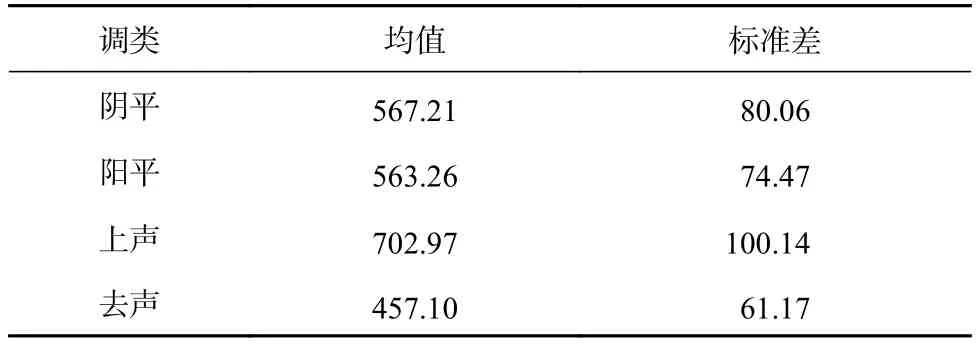
表 2 普通话四个声调时长均值(ms)及标准差
实验1的结果显示,在朗读时,上声词时长长于去声词时长。那么,在默读时,是否也存在如此差异?这种差异与词频间是否存在交互作用?实验2将在实验1的基础上,选择汉语单音节的上声词和去声词作为实验材料,探讨词汇识别中上声词时长和去声词时长在不同词频下的差异。
如果存在声调时长效应,那么被试在汉语词汇识别时将会利用声调时长信息,对上声词的加工时间将会长于去声词的时间。如果不存在声调时长效应,那么,上声词的加工时间与去声词的加工时间将不存在差异。本研究假设,不管在高频词条件还是低频词条件下,上声词在默读时的加工时间均要长于去声词时长。
3 实验二: 汉语词汇识别中的声调时长效应
3.1 研究方法
3.1.1 被试
天津外国语大学学生27名,普通话流利,所有被试视力或矫正视力正常。参加实验的被试实验后均会获得一份礼物。
3.1.2 实验设计
实验采用2(调类: 上声、去声)×2(词频: 高频、低频)被试内设计。
3.1.3 实验材料
为了避免词性因素以及名词具体性对实验结果的影响,本研究仅选择具体名词作为实验材料。从国家语委语料库中搜索到359个上声和去声单音节名词。通过控制词频、笔画数和单音节词的辅音类型,最后确定了108个单音节名词(低频上声词,如“饼”“苯”、低频去声词,如“被”“弟”、高频上声词,如“笔”“板”、高频去声词,如“电”“报”,各27个)作为实验材料。108个单音节名词的词频及笔画信息见表 3。同时,我们又从国家语委语料库中搜索到52个单音节名词(阴平词和阳平词各26个)和120个单音节动词(每个调类各40个)作为填充材料。
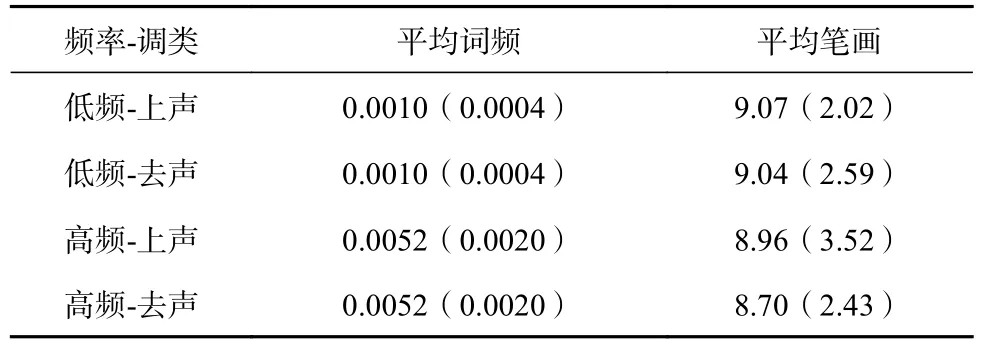
表 3 108 个单音节词的词频和笔画数的均值及标准差(括号内)
经检验,词频差异显著,F(3, 78)=81.58,p<0.001,η2=0.76,低频上声词的词频与低频去声词的词频差异不显著,p>0.05,高频上声词的词频与高频去声词的词频差异不显著,p>0.05,低频上声词的词频与高频上声词的词频差异显著,p<0.01,低频去声词的词频与高频去声词的词频差异显著,p<0.01。笔画数差异不显著,F(3, 78)=0.11,p>0.05,η2=0.004。
3.1.4 实验程序
实验使用DMDX实验软件编程。刺激呈现在电脑显示器上,呈现的字体颜色均为白底黑字。实验采用的是词性判断任务。被试坐在电脑屏幕前,眼睛距离屏幕约40厘米。实验要求被试尽量快而准确地判断屏幕中心出现的单音节词是名词还是动词,如果是名词按电脑键盘的“J”键,如果是动词按“F”键。实验开始时,首先在屏幕上出现一个十字形的注视点,持续时间为300 ms,然后空屏300 ms,刺激项目呈现的时间为300 ms。前后刺激项目的呈现时间间隔为3 s。计算机记录下刺激开始呈现到被试开始反应的时间。正式实验前,被试要进行10个刺激项目的练习,练习词中包括5个名词和5个动词。确认被试完全理解了实验任务后,开始正式实验。整个实验持续大约20分钟。
3.2 结果
被试的词性判断正确率均在90%以上。从结果分析中去掉平均数加减三个标准差之外的数据,这样有74个数据 (1.86%)从数据分析中去掉。平均反应时和正确率见表 4。
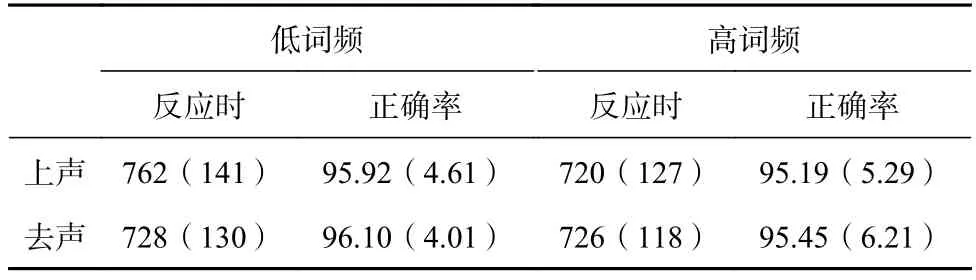
表 4 词性判断的反应时(ms)、和正确率(%)
反应时的方差分析表明:调类主效应不显著,F1(1, 26)=2.37,p>0.05,η2=0.08,F2(1,19)=1.74,p>0.05,η2=0.08。词频主效应被试分析显著,F1(1, 26)=11.83,p<0.01, η2=0.31,项目分析边缘显著,F2(1, 19)=4.32,p=0.05,η2=0.15。调类与词频的交互作用显著,F1(1,26)=23.49,p<0.001,η2=0.48,F2(1, 19)=5.13,p<0.05,η2=0.21。进一步简单效应分析发现,低频条件下,上声词的反应时长于去声词的反应时,t1(26)=3.40,p<0.01,t2(19)=2.70,p<0.05,高频条件下,上声词的反应时与去声词的反应时差异不显著,t1(26)=-0.59,p>0.05,t2(19)=-0.41,p>0.05;上声词条件下,低频词的反应时长于高频词,t1(26)=5.29,p<0.001,t2(19)=2.86,p<0.05,去声词条件下,低频词的反应时与高频词的反应时差异不显著,t1(26)=0.34,p>0.05,t2(19)=-0.15,p>0.05。
正确率的方差分析表明:调类主效应、频率主效应以及二者的交互作用均不显著,ps>0.05。
3.3 讨论
实验2使用上声单音节词和去声单音节词作为实验材料,使用词性判断任务考察了汉语词汇识别过程中声调的时长效应。研究结果表明:高频词条件未发现声调的时长效应,而在低频词条件下,出现了声调时长效应:即上声词的反应时长于去声词的反应时时长。本实验的研究结果与以往在音段信息(Abramson & Goldinger, 1997;Huestegge, 2010; Jared & Seidenberg, 1991; Lee,Binder, Kim, Pollatsek, & Rayner, 1999; Lukatela et al.,2004)以及超音段信息(Ashby et al., 2006; Ashby &Clifton, 2005; Breen & Clifton, 2011, 2013)对词汇识别的作用的研究类似。尤其与Abramson和Goldinger(1997)在低频词条件下发现元音音段的时长效应类似。Abramson和Goldinger发现,低频词下长元音的词汇判断时间长于短元音的判断时间,这种时长效应恰恰反映了默读时声学表征的激活,即内在言语的激活,而不是抽象的语音编码的激活。Jared和Seidenberg(1991)的实验也发现在低频词条件下,语音对词义的通达起促进作用。
本实验仅在低频词条件下发现了声调的时长效应。显然,这一结论与之前的假设不完全一致。这与我们的实验任务以及声调本身具有区别意义的特点相关。本实验为了使被试能够通达词汇的意义,采用的是词性判定任务,被试需要对刺激进行词性判断。汉语是一种缺乏形态变化的语言,被试在实验过程中无法从词形上判断出一个词的词性,又因为本实验采用孤立词呈现,被试也无法从语法功能上判断词性,而仅能通过意义来判断刺激为何种词性。James(1975)词汇判断实验发现,在一定程度上,对于不常见的低频词,人们更倾向于在语义水平上对其进行加工。闫国利,杜晨,卞迁和白学军(2014)也发现了低频词条件的名词具体性效应。具体性效应实际上也是一种语义效应。因此,低频词使被试能够加工到语义水平。这成为区别上声词和去声词时长效应的条件。高频词情况下没有发现声调的时长效应很可能与熟悉性相关。由于高频上声词和去声词在熟悉性上一样,因此,熟悉性很可能抵消了声调的时长效应。
本研究通过两个实验考察了汉语词汇识别时的声调时长效应。实验1为了验证前人对汉语声调时长研究的结论,重新从声学上测量了汉语四个声调的时长,并统计分析了四个声调时长的差异。研究结果确认了汉语上声词时长最长,去声词时长最短。在实验1的基础上,实验2重点考察了上声单音节词和去声单音节词在不同词频条件下是否存在声调时长效应。结果在低频词条件下发现了声调时长效应。一般认为,声调区别意义主要体现在音高上,但本研究结果表明,声调时长在区别词义时也具有重要的参考价值。尤其是对于上声和去声来说,对区别词义具有显著的作用。
本研究的两个实验明确地表明,汉语词汇识别在默读和朗读时一样,声调时长的声学表征被激活,即内在言语被激活。表明在默读情况下,汉语调类的时长差异在汉语词汇的识别中具有重要作用。被试需要利用声调时长这一语音信息来进行词汇通达。声调属于超音段信息,即韵律信息。因此,本研究的结论为词汇识别中内隐韵律作用提供了汉语的证据,支持了内隐韵律假说。
4 结论
在本实验条件下,本研究得出以下结论:(1)汉语上声词的时长长于去声词的时长。(2)低频词条件下,汉语上声词的加工时间长于去声词的加工时间。声调时长在汉语词汇识别中具有重要作用。
