基于驾驶员避撞行为的行车风险判别方法的仿真研究∗
2019-03-11熊晓夏蔡英凤江浩斌
熊晓夏,陈 龙,梁 军,蔡英凤,江浩斌
(江苏大学汽车与交通工程学院,镇江 212013)
前言
在对本车和周围车辆运行状态感知的基础上,研究汽车未来行驶风险状态的预测方法,有助于实现辅助驾驶系统准确、及时的碰撞预警或干预机制。目前行车风险预警主要通过比较实时距离和计算安全距离的大小进行危险判别,用于计算安全距离的模型主要包括基于制动过程运动学分析的安全距离模型[1]、基于车间时间的安全距离模型[2]和基于碰撞时间的安全距离模型[3]等。而实际上,从行车风险形成开始到发生危险冲突的整个风险转化过程很难用单一的时空距离参数(实际车距、车间时间和碰撞时间等)进行描述,需要综合考虑多个时空距离参数并采用更复杂的模型和算法对车辆防碰撞预警进行研究。同时,目前国内外预警模型算法通常仅考虑车辆的运行特征(如车间距、速度和加速度特征等)[4-6],而忽略了动态驾驶员行为、道路和环境变化对行车风险状态的影响,不能全面反映行车状态之间的内在转化规律,不利于行车风险模型的准确性和预测精度。因此,有必要研究充分考虑驾驶员行为、道路和环境特征的行车风险预测方法。
自然驾驶学习(naturalistic driving study,NDS)近年来在车辆安全研究领域得到了广泛关注,它通过实时记录紧急情况或事故发生前后一段时间内的车辆运动状态参数和驾驶员及周围环境图像信息,为事故分析和车辆安全技术等研究提供了可靠的科学依据[7]。本文中为解决车辆防碰撞预警问题,拟在自然驾驶数据的基础上,提出基于驾驶员避撞行为的行车风险状态分类方法,并在此基础上通过机器学习建立反映不同驾驶员行为、道路和环境特征的行车风险判别算法,辨识和预测汽车未来运行风险状态,为研究防碰撞预警策略和控制方法提供新的思路。
1 数据来源
本文中的行车风险数据来源于美国弗吉尼亚理工大学于2004-2005年采集的“100-car”自然驾驶数据[8],其中包括68起事故数据和760起临近事故(即驾驶员采取了紧急制动或紧急避让行为的情形)数据,每组数据记录了事故(或临近事故)发生前30s至事故发生后10s内车辆的运行状态、驾驶员状态以及交通和环境状态等特征信息,可以满足研究反映动态驾驶员行为、道路和环境特征的行车风险预测方法的目的。由于该数据集对换道事故涉及的冲突车辆运动参数记录不完整,仅选取追尾事故和临近追尾事故作为行车风险事故观测样本,经过剔除观测值缺失和错误的无效样本,最终获取行车风险事故样本{X1,X2,…,XN},其中N=114,每个样本Xi(i=1,2,…,N)是时长为Ti的时间序列,包括筛选整合后的车辆、驾驶员、道路和环境信息变量,如表1所示。

表1 “100-car”自然驾驶数据集变量
其中层次-1中变量刻画了实时的车辆运动特征,将用于第3节进行行车风险状态划分;层次-2中变量表征了车辆运动数据记录时段驾驶员、道路和环境的特征,将用于第4节进行行车模式划分,如图1所示。第5节将通过机器学习分别对不同的行车模式建立行车风险状态判别算法。

图1 算法设计流程框架图
2 基于驾驶员避撞行为的行车风险状态划分
研究表明,行车风险等级可由驾驶员的避撞行为特征表征[7],其机理如下:在跟车过程中,驾驶员会根据车间距离过近或过远通过加速或减速操作调整车间距离,直至形成稳定的跟车状态(即稳态跟车),在该状态下驾驶员无需采取制动措施;若在跟车过程中前车出现制动,车辆间距离逐渐缩短,车辆间追尾碰撞风险逐渐增大(即险态跟车),当碰撞风险程度超过了驾驶员的风险感知阈值,驾驶员就会立即采取制动操作进行避撞。因此,可将追尾碰撞事故(或临近追尾事故)发生前跟车过程中自车制动开始时刻的车辆状态视为行车风险状态,并根据该时刻的自车速度、车间距离和相对速度等车辆状态参数特征对行车风险等级进行划分。
2.1 基于瞬时运动参数的行驶风险等级划分
碰撞时间TTC和车间时间THW均为衡量车辆运行风险的传统特征参数,为避免单一传统预警变量TTC对车间距离变小风险状况和单一THW对两车相对速度变大风险状况的评价不足,本文中结合两者优点,对“100-car”自然驾驶数据集中事故和临近事故样本中车辆在制动开始时刻的{-iTTC,THW}参数向量进行K-means聚类(为避免相对车速较小时TTC无限大的问题,取TTC的倒数iTTC进行分析;负号保证了其随风险变化的增减性与THW一致),通过elbow法[9]得到K=5个瞬时行车风险类别,各类别分布情况如图2所示。

图2 驾驶员制动开始时刻车辆运动参数分布
由图2可知,在(临近)追尾事故发生前驾驶员制动开始时刻车辆运动参数分布空间基本可由①iTTC=0.7s-1,②THW=0.9s,③THW=1.3s,④THW=1.8s以及⑤THW=2.5s 5条界线划分为5大区域。值得注意的是,在(临近)事故样本中驾驶员制动开始时,存在着iTTC为负数(根据传统TTC判别方法为无风险情况[10])但THW较小的iTTC-THW参数对,进一步表明了仅使用两个参数中的单个参数进行行车风险评估的局限性。同时,结合其它文献基于TTC的预警范围设定(1.0s-1≤iTTC,0.67s-1≤
iTTC<1.0s-1,iTTC<0 范围内对应的事故-冲突比分别预计为0.8,0.6和0)[10],本文中基于瞬时运动参数最终将行驶风险等级(risk level,RL)按表2进行划分。

表2 瞬时行车风险等级划分
2.2 基于时间窗行驶风险等级特征的行车风险状态划分
为克服单一观测点包含信息的局限性,进而提高预测算法的实时性和准确性,将瞬时的行驶风险等级信息按时间序列顺序合并划分为短时间的风险等级时间窗,如图3所示,其中“100-car”自然驾驶数据集中的每个采样时刻(采样间隔为0.1s,即10Hz)对应一个瞬时行车风险等级,例如图中时长φ=1.3s的时间窗由14个观测到的瞬时行车风险等级组成,时刻t的行车风险状态将由结束于时刻t的风险等级时间窗内所有瞬时风险等级的统计特征值通过聚类算法决定。

图3 行车风险等级时间窗示意图
选取时间窗内瞬时行车风险等级的平均值RLavg、时间窗内最后观测到的风险等级(即t时刻的瞬时风险等级)RLlast和时间窗内风险等级的趋势值CON作为每个时间窗的统计特征变量。其中趋势值CON源于图像分析领域表征灰度变化特点的统计量Contrast[11]。本文中针对风险预测问题,对时间窗内风险等级观测序列的趋势值CON定义如下:
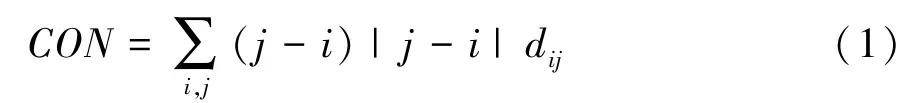
式中dij为风险度共生矩阵的第i行第j列元素(此处i,j代表瞬时行车风险等级)。dij的表达式为

式中:Nij为按时间窗内时间序列方向相邻时刻组成的风险等级对(i,j)出现的次数;N_pairs为所有相邻时刻风险等级可能组成的对数。以一个包含连续10个时刻瞬时行车风险等级的时间窗为例,dij的具体计算方法如图4所示。

图4 时间窗风险等级共生矩阵示意图
由式(1)和式(2)可以看出,CON不仅衡量了时间窗内每个观测数据点与其相邻数据点的对比强度关系,并反映了一个时间序列中数值的趋势变化特征(即当时间窗内瞬时风险等级呈上升趋势时CON为正值,反之为负值),故在此用于表征时间窗内风险等级的变化规律。
提取每个时间窗内风险等级的均值、方差和趋势值[RLavg,RLlast,CON]作为该时间窗的特征向量xi,对样本划分得到的所有时间窗特征向量{x1,x2,…,xn,…,xN′}进行 K-means 聚类,获取基于时间窗的K′类行驶风险状态。从理论上讲,时间窗长度越长,所涵盖的车辆行驶信息越多,预测准确率越高,但时间窗长度越长,更难突出反映车辆行驶最新的动态变化特征,预测及时性降低。因此,为满足预测的准确度和及时性要求,本文中折中选取时间窗时长φ=1.5s。同时,为获取尽可能多的时间窗观测样本进行风险状态聚类分析,此处按时间窗间隔δ=0.1s对所有时间序列样本进行划分,见图3。为便于未来构建行车风险预警策略,最终基于聚类划分K′=3个风险状态:1-高风险,2-中风险,3-低风险,风险聚类结果如表3所示,每个类别内聚类变量RLavg,RLlast,CON和运动参数iTTC及THW的分布情况如图5(各图横坐标代表每个聚类状态内时间窗样本的序列号)所示。

表3 基于时间窗的风险状态聚类结果
如表3所示,当风险状态由状态1→状态3变化时,-iTTC和THW的平均值均呈下降趋势,说明行车风险状态正在向更危险的状态演变,因此定义状态1为低风险状态,状态2为中风险状态,状态3为高风险状态。图5有两点值得注意(与传统的基于TTC的风险评估不完全相符):
(1)在图5(i)和图5(l)中,一些TTC平均值高(iTTC∈(0,0.4),即TTC>2.5s)但THW平均值低(<2s)且CON为正(表明在时间窗内的风险等级序列呈上升趋势)的时间窗被分配到高风险状态而不是低风险状态;
(2)在图5(h)和图5(k)中,一些TTC平均值低(iTTC>1s-1,即TTC<1s)但CON为负(表明时间窗内的风险等级序列呈下降趋势)且窗内最后观测到的瞬时风险等级低的时间窗被分配到中等风险状态而不是高风险状态。
以上两点表明本文中提出的行车风险状态分类与传统的基于TTC阈值的风险评估存在差异,原因在于本文中定义的风险状态是基于TTC-THW的二维平面而不是基于TTC的一维空间。注意到本文中高风险类的平均TTC值约为2.3s(表3状态3中iTTC_avg=0.438s-1),接近于NHTSA的TTC=2.4s的警告阈值[12],表明此处的风险聚类结果是可信的。
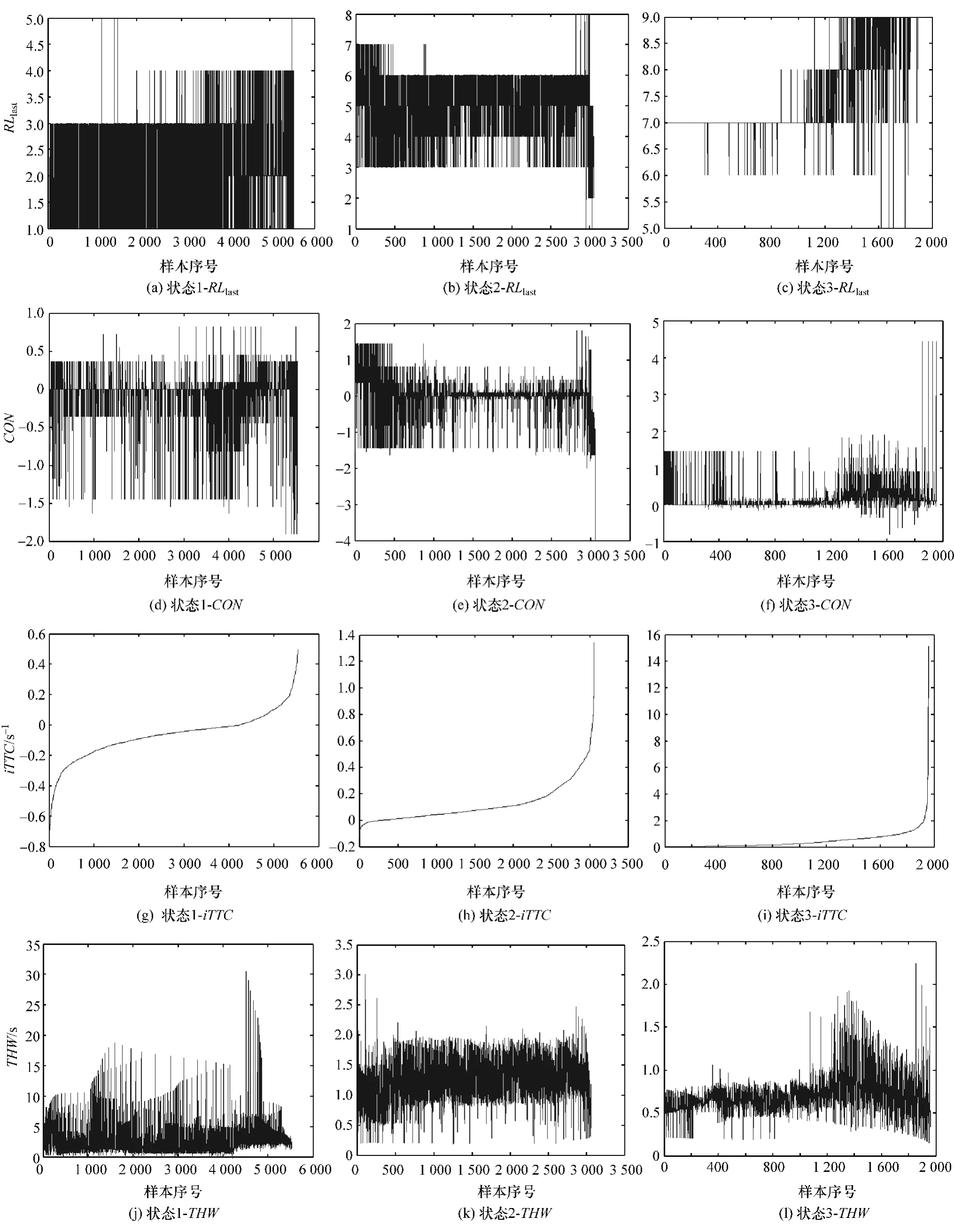
图5 各风险状态类别内聚类变量RLlast,CON和运动参数iTTC及THW的分布情况
3 基于驾驶员、道路和环境状态的行车模式分类
研究表明,驾驶员和道路环境状态对行车风险有显著影响[13],因此在建立行车风险状态预测算法过程中,需考虑相关因素变量影响。考虑到驾驶员、道路和环境变量维数多且复杂,不利于预测模型的预测效果[14],因此对其进行降维处理并进行聚类分析,提取不同驾驶员-道路-环境因素下的行车模式(driving mode,DM),为第4节基于不同行车模式下的行车风险状态SVM模型预测奠定基础。
通过计算各变量Spearson相关系数对变量进行初步筛选(剔除相关度低的变量),并通过主成分分析(principle component analysis,PCA)试验变量组合,最终获得对样本数据变异解释程度最大的变量组合,如表4所示。其中驾驶员“非驾驶任务”指驾驶员进行的与驾驶任务无关的任意其它行为(如打电话或饮食等),可按实现该行为的复杂程度进行等级划分,按文献[15]中的分类标准将驾驶员的非驾驶任务行为分为简单、中等和复杂3大类。注意到所有变量均为多类别离散变量,而传统PCA分析仅适用于连续变量,因而在此采用改进的非线性PCA方法进行主成分分析:首先采用最佳量化非线性方法将离散类别转化为连续值,然后再对转换后的变量连续值进行传统主成分分析[16]。非线性PCA算法由SAS中Prinqual和Princomp过程实现[17],得到选择变量(表4)的主成分分析结果如表5所示。

表4 最大样本数据变异解释程度变量列表

表5 所选变量主成分分析结果
有文献表明,各成分特征值达到1以上,累积贡献率达到60%以上,即可基本满足分析要求[18],因此选取前5个成分代替原多维变量对行车模式进行K-means聚类划分,最终得到KDM=3个行车模式(DM1,DM2,DM3),各行车模式聚类中心的原始变量值如图6所示。
值得注意的是,由图6中IAT,NST,HST的中心值可以看出,从行车模式DM1到DM3驾驶员驾驶分心状态的范围和程度呈明显下降趋势(DM3内驾驶员未观测到驾驶分心行为),而其它变量没有观测到明显的变化规律。结果反映驾驶员分心状态变量(IAT,NST,HST)对样本数据变异解释程度最大,是行车模式聚类最主要的特征变量。

图6 各行车模式聚类中心变量值
4 基于SVM的行车风险状态预测
4.3 SVM基本原理
SVM(support vector machine)为机器学习的代表算法之一,对分类预测问题具有较好的预测效果(文献[4]和文献[19]中利用SVM对换道安全性进行预测并获得了较高的预测准确率),因而被本文中用于行车风险状态类别预测。给定样本数据,其算法主要通过高维空间变换(即将原输入空间的样本映射至高维的特征空间)在高维特征空间中寻找间隔最大的超平面将样本进行分类,且保证该超平面具有最好的泛化能力,其数学表达式为

式中:φ(x)为特征空间;w为权重向量;b为偏置项。该问题可由如下表达式求解:
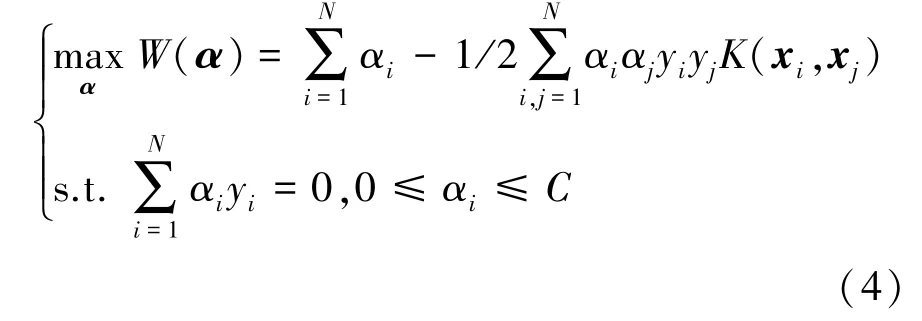
式中:{xi,yi}为给定N组带标记的训练数据,i=1,2,…,N;C为选用值惩罚参数;K(xi,xj)为核函数,即将原始向量xi和xj投影至特征空间后作内积。则给定新的观测向量z,SVM的判别函数D(z)为

式中为式(4)的最优解。
4.2 模型构建
以t时刻时间窗内行车风险等级统计向量[RLavg,RLlast,CON]为输入特征变量,以t+δ时刻(δ为时间窗滚动间隔,见图3)时间窗内的行车风险状态类别为SVM输出预测类别(即δ为基于SVM的行车风险状态类别预测区间),综合考虑驾驶员和环境状态(即第3节中定义的行车模式)对行车风险的潜在影响,利用SVM对不同的行车模式分别建立基于时间窗行车风险等级统计特征的行车风险状态预测模型。为不失一般性,按行车模式随机选取60%时间序列样本(共68个)内划分的时间窗作为SVM判别器训练集,剩余的40%时间序列样本(共46个)划分的时间窗作为测试集。根据训练集数据试验,不同行车模式SVM的平均正确率随δ时长的变化趋势如表6所示。

表6 不同预测区间下SVM的平均预测准确率
由表6可以看出,随着预测区间δ的增大,SVM的平均正确率呈递减趋势,这可能是由于随着预测视距变长,车辆动态变化存在的不确定因素更多,预测难度亦更大。考虑到预测区间为1.0s时模型平均预测准确率可达90%水平,且研究表明若驾驶员能在碰撞风险发生前1.0s得到风险预警,则90%左右的追尾事故可以避免[20],因此综合考虑防碰撞预警的准确性和实时性要求,最终选择δ=1.0s作为SVM行车风险预测模型的预测区间。
4.3 结果分析
对于风险类别预测问题,通常需要考虑预测结果的真正率(true positive rate,TPR)和假正率(false positive rate,FPR)问题。结合本文中行车风险状态的划分类别,预测结果的真正(TP)、假正(FP)、真负(TN)和假负(FN)的定义见表7,低、中、高风险状态类别的预测正确率Acc1,Acc2和Acc3也如表7最后一行所示。

表7 预测结果划分
相应的真正率(TPR)和假正率(FPR)定义为
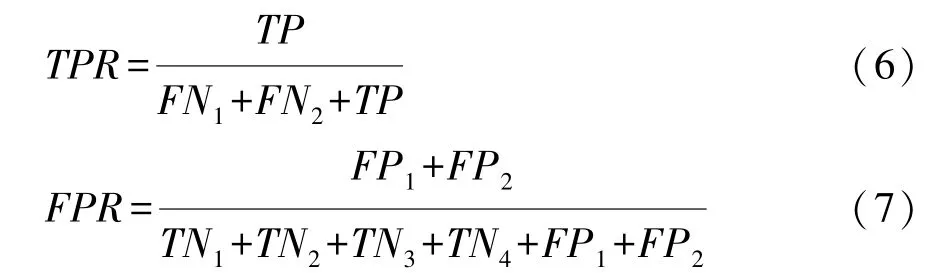
可以看出,该定义下TPR与高风险类别的预测正确率Acc3相同(即TPR=Acc3)。真正率TPR越高,说明高风险状态被提前预测的正确率越高,该预测系统的有效性亦越高。为了避免真正率越高可能带来的模型过拟合问题,一般同时需保证模型预测的假正率FPR(实际为中、低风险状态但被预测为高风险状态的比例)在合理范围内,考虑驾驶员对预测结果为假正的容忍限度,在实际应用中最高假正率FPR通常选为5%。
基于不同行车模式的训练集数据(即按行车模式将训练样本划分为3组),在风险预测区间δ=1.0s下,采用5-折交叉验证法得到不同行车模式下SVM的训练模型,利用训练得到的SVM模型对测试集数据进行预测,得到不同行车模式(DM)下基于SVM的行车风险状态预测正确率Acc(5%FPR条件下),如图7所示。

图7 基于SVM的行车风险状态预测结果
由图7可以看出,模型的预测正确率随行车模式变化DM1→DM3呈递减趋势,这可能是由于DM1表征的驾驶员分心状态对行车风险状态变化的影响规律能更好地反映在SVM模型中,因而该行车模式下SVM模型的预测正确率普遍更高;而DM3表征的其它道路、环境状态对行车风险状态变化的影响机理更为复杂,更难在相应SVM模型中得到全面反映,导致预测正确率降低。同时结果显示,对于每一种行车模式,建立的SVM模型对高风险状态的预测正确率(Acc3)最高(可达90%以上),中风险状态(Acc2)次之,低风险状态(Acc1)最低,说明基于SVM的行车风险状态预测模型能有效预测高风险行车状态。另外,基于所有训练样本得到的基准SVM模型(未按不同行车模式样本组分别进行训练)的预测总准确率(总Acc1,总Acc2,总Acc3)均低于按行车模式分别训练的SVM模型的平均预测准确率,说明驾驶员、道路和环境特征对行车风险状态预测有显著影响,在进行行车风险状态预测建模时应该考虑这些特征的差异化作用。
5 结论
针对行车风险状态预测问题提出了基于驾驶员避撞行为的风险状态分类方法,并综合考虑驾驶员-道路-环境因素的影响通过聚类方法对行车模式进行了划分,建立了基于不同行车模式的行车风险状态预测算法,最后通过美国“100-car”自然驾驶数据对预测算法进行了训练和验证。研究结果表明,驾驶员、道路和环境特征对行车风险状态预测的准确率有显著影响(特别是驾驶员分心状态),在构建行车风险状态预测算法时应该充分考虑这些特征的差异化作用;同时,不同行车模式下SVM模型对各风险状态的预测正确率均可达到80%以上,其中对高风险状态的预测正确率可达90%以上,且均能满足假正率FPR低于5%的要求。说明本文中构建的预测算法对未来行车过程中的高风险状态预测具有较高的准确率,有助于对临近危险状态的驾驶员给予及时的警告或者辅助纠正,为研究防碰撞预警策略和控制方法提供了新的思路。未来可通过获取更多实际的事故和临近事故驾驶数据对预测模型进行优化,通过实车试验考察模型的在线实时预测效果,将其应用到安全辅助驾驶系统中。
