基于AdaBoost的核素识别方法
2019-03-06仝茵,刘丽
仝 茵,刘 丽
(1.中国原子能科学研究院,北京 102413;2.中国电子科学研究院,北京 100041)
0 引 言
核素鉴别具有实际应用意义。在多种的测量环境中,放射性核素经过γ能谱仪等核物理设备仪器进行鉴别,探测器接收发射的γ射线源生成能谱数据,能谱获取后通过特定的方法进行分析,实现对核素的种类鉴别。目前成熟的核探测解谱方法,通常采用全能峰法、逐次差引法等技术来进行核素分析解谱[1]。传统的方法存在的问题主要有:(1)获取到的能量峰值向量的峰值信息不能涵盖全部峰值,能谱的信息具有局部特征,或存在重叠峰值,从而可能导致核素判别出现错失、误判结果。(2)对于能谱随测量环境变化的动态改变,传统方法不具有强适应性,核素识别率会降低。
近年来核工业领域积极结合人工智能思想进行研究和应用,探索解决传统方法中存在的短板,结合机器学习算法,进行工业创新。本文的思想,介绍了一个基于AdaBoost算法的核素识别系统,将采样生成的能谱数据理解为向量和图片形式的数据,将原始的能谱数据处理为矩阵形式,然后通过SVD方法对能谱矩阵进行特征信息提取,得到能谱特征向量作为后续模型的训练数据,使用AdaBoost算法来建立训练模型识别核素种类,将每一轮弱分类器在训练数据集上的结果与实际真实的类别结果进行对比,根据每一轮对比结果的偏差度,复调下一轮整模型的参数,从而提高核素识别的准确度。
1 数据预处理
1.1 数据采样生成
核素识别需要以大量的样本为鉴别基础,得到包含更为全面的核素能谱数据的特征信息,从而提高核素识别准确度。此处使用MCNP(Monte Carlo N Particle Transport Code)基于蒙特卡罗方法模拟生成能谱数据样本,包括Eu152、AM241、Na22、I131等9种类别单一核素以及混合核素的能谱数据样本。MCNP是美国洛斯阿拉莫斯国家实验室开发的一个开源工具包,能够模拟比较逼真的物理实验过程[2],在本文应用中,用来模拟构建粒子类型、记录能谱及定义衰变链的过程,生成多个能谱数据集。能谱数据形态见图1。
图1为核素I131和AM241的混合能谱图,横轴是能量道址区间,纵轴是能量计数,每一个蒙特卡洛能谱数据集看做一个向量,γ能谱的道数作为向量的维度,每个能谱向量为:
Ui={u1,u2,u3…un}
(1)
式中,n∈{1,1500},共1500个波道。每个能量计数作为向量的一个维度,其中i∈{1,m},m是样本数量。本次共生成1100个能谱数据样本。
1.2 Z-score标准化
当γ能谱的能量计数取值范围较大时,比如计数的区间为几百甚至上千,为了减轻各个维度间取值的量纲影响,使得各维度的数值趋向同一数量级[3],我们对能谱数据集进行标准化处理如下:
i∈{1,m},j∈{1,n}
(2)

1.3 零均值化
标准化能谱数据后,继续进行零均值化,得到标准差为1,均值为零的标准正太分布的能谱数据,如下:
i∈{1,m},j∈{1,n}
(3)
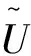
2 特征提取
2.1 能谱特征向量
在对γ能谱数据样本集进行预处理后,将其由原来的一维向量表示为二维的矩阵形式来应用AdaBoost算法进行分类,实际环境中,生成的全能谱数据由于存在仪器误差或环境干扰的原因,包含噪音和非特征因素,为了保证最终机器学习模型效果,需要对能谱数据维度规约,此处使用特征提取来减小特征的维度,提取到能谱数据中最明显的能量特征值,以更小数据维度更有效的表示AdaBoost模型的数据输入。矩阵形式如为:
(4)
SVD是机器学习中常用的线性回归问题去噪、降维方法,其原理是因数分解矩阵的线性代数[4-5]。被广泛的用在特征提取和矩阵压缩存储问题。本问题中考虑一个由m个样本的能谱数据集,每个样本包含n道数据维度。SVD对样本集进行特征抽取来获得奇异值特征分解向量ξi(i∈1,2,3,…m),SVD奇异值分解形式如下:
(5)
奇异值特征的权重下降的较快,奇异值矩阵ξi的前t个奇异值包含Ai矩阵的大部分信息量,对待不同核素形成不同的奇异值矩阵长度,我们统一抽取其奇异值长度的前t个奇异值构成t维奇异值向量,令t为10,提取到能谱的多于90%的能量,得到X1×10的特征向量。
2.2 特征向量有效性验证
将上节得到特征向量X1×10作为AdaBoost模型的输入样本特征,选取核素中的五种核素的特征向量,验证其做为输入样本的有效性,分别取向量t=2和t=3时,两维和三维子空间的空间分布状况。经过空间投射验证,多种类核素在降维子空间分布有显著不同,分布识别度高,由二维、三维推及更高维度,可以作为准确输入样本特征进行识别,部分核素的降维空间分布如图2。
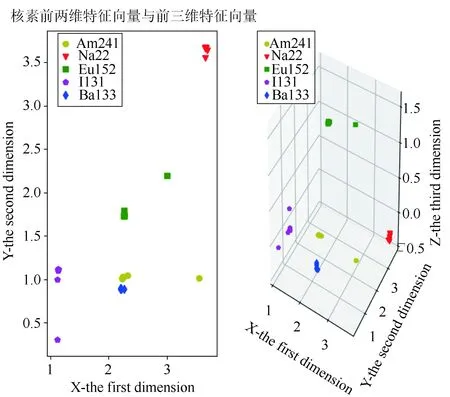
图2 核素前两维和前三维特征向量空间分布对比
图中坐标轴表示特征向量的前二维、及三维的维度,每一个种类的核素衰变仿真模拟生成100组数据,每组核素数据对应一个特征向量X1×10和核素标签y。组成数据(X(i),y(i))作为模型训练数据集。
3 核素识别算法
3.1 独立分类器做预测
为了对核素分类效果做区分对比,防止建立的模型对数据集数据过拟合或欠拟合等问题,影响模型的实际应用效果,将数据集分别应用到多个识别算法进行分析,多个独立分类器的对比效果见图3。
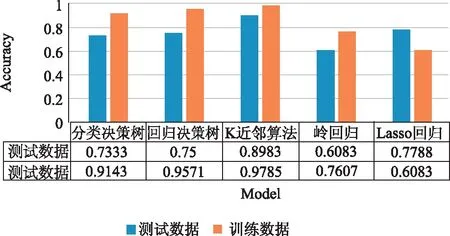
图3 多个分类器分类效果对比
通过核素测试数据集与训练数据集在不同分类方法上产生效果的对比,可以看到决策树方法和K近邻方法在核素数据集上的拟合效果方面和数据预测方面都有出色表现[6],考虑到k近邻方法分类效果较依赖初始中心值参数的设置[7],并且无法作为弱分类器进一步应用到AdaBoost集成算法中提升模型的性能,兼顾核素特征样本数据为离散值的特性。本文选择分类决策树方法对核素识别处理。分类决策树CART算法建立决策树算法描述如下:
算法1:分类决策树CART算法
输入:D=(X(i),y(i))i∈{1,m},y(i)∈{1,8},特征属性A=ajj∈{1,n},样本类别k∈{1,K},aj特征取值v∈{V}={1,V}
初始化:基尼系数阈值εGini, 样本个数|m|阈值εm,
输出:决策树T
1.当前节点node,if|m|<εm||{A}=φ,返回决策子树T,当前节点停止递归
2.对于样本集D,IfGini(D)<εGini,返回决策子树T,当前节点停止递归
3.当前节点node,为node选择最优属性a*,a*对应的最优值vbest,将数据集D划分为子数据集{DVbest}和{DV*}
4.a*取值v∈{1,V}其中,a*=argmin Gini(D,aj)
5.While ∀v∈{V}={1,V} ∀v*∈{V*}={V}-v,|DV|为a*=v的样本个数 do
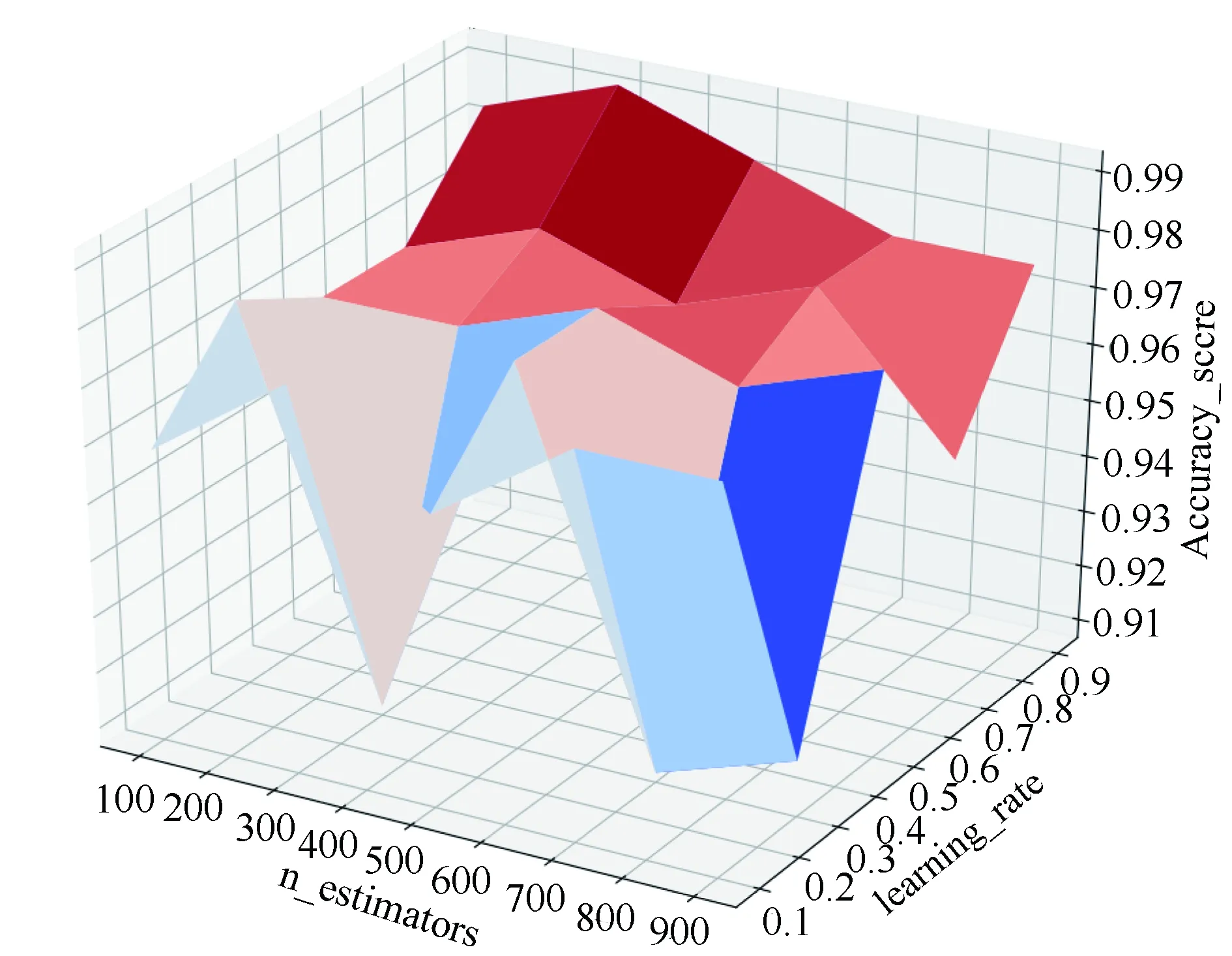
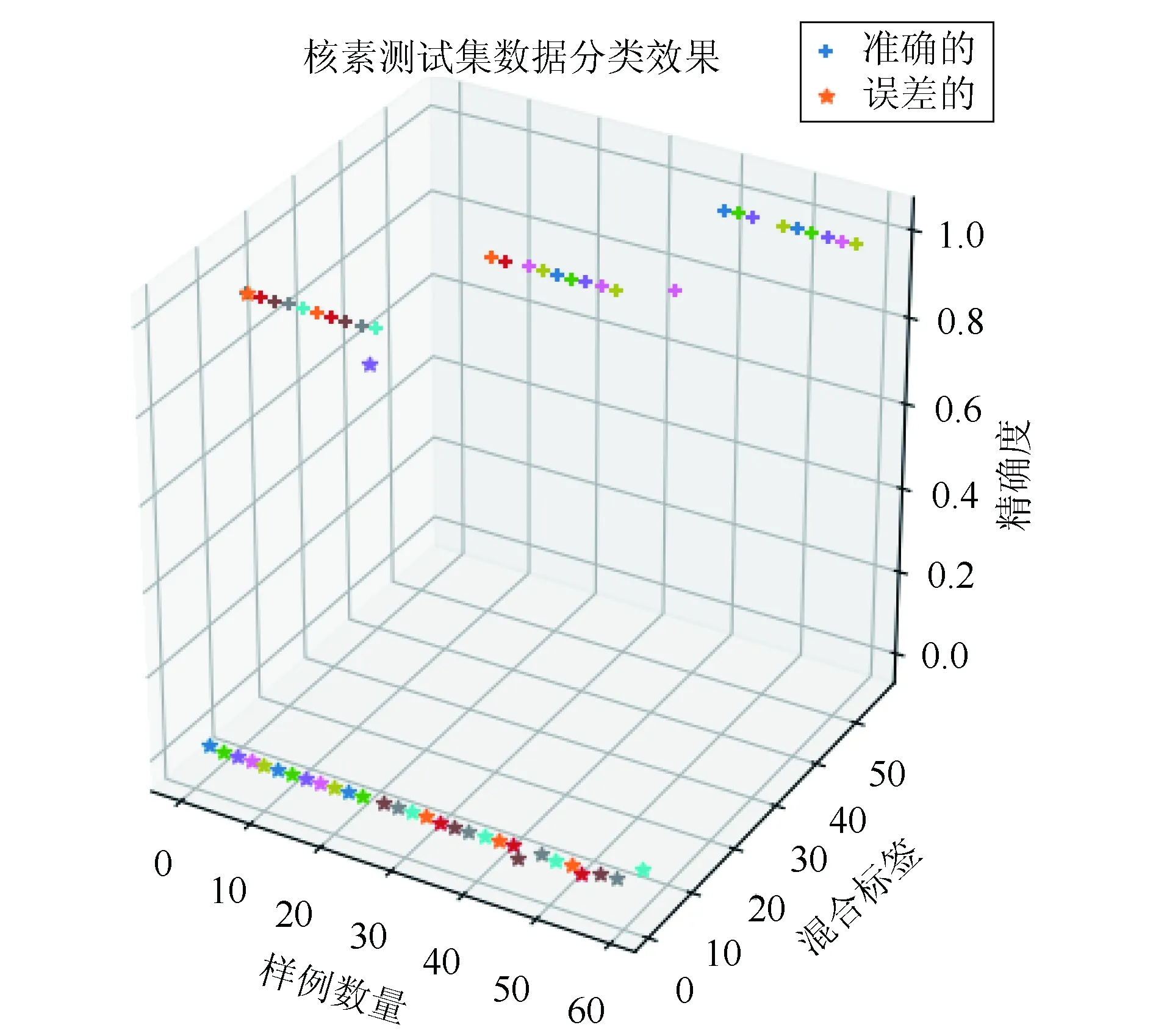
6. For (w=1, w {V*} -= {V}-vw If Gini(D,a*)w > Gini(D,a*)w+1 vbest=vw+1 else vbest=vw End if End For 7.End While 8.根据最优特征a*和a*对应的最优值vbest,生成二叉树节点Nsub(即第3步的节点node),并把数据集划分为两部分,建立Nsub节点的左右节点,左节点对应数据集{DVbest},右节点对应数据集{DV*},对左右节点重复调用1-7,生成决策树T v的数量由特征属性A的值个数决定,不同的特征值aj有不同数目的取值集合{V},当前核素识别任务中,每个样本的核素特征向量是十维,每个样本的特征属性A的数量为10,共有10类特征属性去计算基尼系数,取基尼系数最小的特征a*,对二叉树进行划分。K是核素标签的数量,此处K值取6,共6类单一核素标签。 分类决策树模型,使用多组核素数据进行训练,训练过程如下: (1)读取m组大小的核素特征向量,每条特征向量匹配实际的核素标签,形成数据集D(X(i),y(i))去做训练。 (2)确定算法1输入参数和初始化参数,调用算法1进行计算,得到决策树T。 (3)取非属于m组的,同样格式的一组核素特征向量作为测试数据集,在训练的决策树T上,测试生成决策树分类模型的准确率。核素测试集的是识别精度约为73.33。 (4)使用决策树T对训练数据集进行预测,精度为91.43。 在对生成的决策树做预测时,测试集的样本划分到某叶子节点后,如果该叶子节点里有多个训练样本,那么该测试样本取该叶子节点的概率最大的类别作为预测类别。 总结,决策树CART分类模型作为核素识别分类器,从预测结果来看,存在的一下问题: (1)决策树模型在核素数据的应用效果有轻度过拟合。该问题可以通过调节树深度或者计算决策子树的损失函数的剪枝算法来提高模型泛化能力。 (2)为了提高模型的准确率,也可以特征属性择优时,选择多变量特征属性组合来做最优划分属性。 (3)核素特征属性提取维数增加,样本结构发生变化,会导致决策树结构的改变,另外寻优决策树过程是NP-hard,得到的最优解有可能是局部最优解,影响精确率。这些问题可以通过集成学习改进。 单个决策树分类器在训练集样本上的结果表现出一定的错误率,如上节训练结果错误率为0.2666,集成算法AdaBoost集合了多个决策树分类器对核素数据集进行多轮训练,每一轮都根据单个决策树分类器的错误率不断修正核素数据集中样本的权值分布,增加分类错误的核素样本的权重,同时减小分类正确核素样本的权重,最后根据每一轮决策树分类器的权重系数,形成多轮形成的相应决策树分类器组合,构建一个泛化性能好的强分类器模型,降低单个决策树分类器的训练结果的偏差,从而提高集成模型的分类精确度[8][9]。 AdaBoost集成算法进行核素识别过程如下: 算法2:AdaBoost集成算法对核素的识别输入:D=(X(i),y(i))i∈{1,m} y(i)∈{1,8}弱分类器:算法1产生的分类器f(X(i))初始化:第一个决策树分类器的样本权重分布D(1)=(w11,w12,w13…w1m) ,w1i=1/m训练轮数:K输出:强分类器F(X(i))=sign(∑K k=1αkfk(X(i)))1.计算第一个决策树分类器在D上的加权误差率为e1=P(f1(X(i)-y(i))>0.5)=∑mi=1w1iI(f1(X(i)-y(i))>0.5)2.计算第一个分类器的权重系数为α1=1/2[log(1-e1)/e1]规范化因子Zk=∑m i=1w1iexp(-αkI(f1(X(i)-y(i))>0.5))3.更新第2个决策树分类器的样本集权重系数分布W2i=[w1iexp(-αkI(f1(X(i)-y(i))>0.5))]/Z14.If e1<0.5 重复1-3步,训练第2、3...轮决策树分类器,直到训练轮数到K次停止,最终得到对应的决策树分类器对应的权重系数αk和相应的分类器fk(X(i))结果5.集成策略采用K轮类别投票法,得到样本X(i)的最终强分类器F(X(i)) 如果训练过程中,ei>0.5,导致整个强学习器没有循环到K轮就停止。如果出现未迭代完成就终止的情况,放弃当前决策树分类器,基于当前轮次的数据样本分布重新采样,生成新的核素样本数据集,重新训练决策树分类器,使得K轮迭代完成,不影响到最终强学习器的效果。 总结,AdaBoost集成模型应用在真实的能谱测量环境中,提高能谱数据分析识别分类的精准度。根据每一轮决策树分类器的错误率调整更新分类错误样本的权重值,最终将多轮的决策树分类器的的训练结果的融合。在存在噪音的真实衰减环境中,对能谱数据识别预测的训练结果有良好的泛化能力,经过检测,模型在核素测试数据集的预测精准度表现为98.33%。 在AdaBoost集成算法对核素数据建模阶段,使用交叉验证的方法[10],对模型参数学习率和训练器个数进行优化,设定模型的学习率范围为v:[0.1,1.0],模型进行迭代训练的决策树分类器个数为n:[100,1000],通过5折交叉验证调参来获得模型在测试样本集上的准确率表现,如图4,决策树分类器的个数为300,学习率取0.8,得到核素测试数据集的分类预测精确度为98.33%。 图4 AdaBoost算法参数寻优 模型对包含部分混合能谱向量的测试数据集进行预测,(混合核素的能谱数据样本包含三类混合数据,为AM241+Na22、Eu152+Na22、I131+AM241三组不同混合类别核素的能谱数据样本),AdaBoost模型在混合核素数据集上得到的预测效果如表1,可以看到,模型对多重核素混叠的能谱的识别效果,仍有较高的识别精确度,能够精准识别出单一核素和混合核素的区别,效果如图5所示(图中,三组不同混合核素种类的表示形式分别为12、34、56)。 表1 混合核素识别效果 图5 混合核素识别精准度 本文的工作内容包括:(1)对高维度能谱数据向量的降维处理,提取到包含大部分能谱数据特征的前十维数据,降低了高维能谱数据处理难度和存在的噪音问题,为核素识别奠定基础。(2)比较不同的建模算法,选择单元分类器决策树对核素数据集进行训练,进一步应用AdaBoost集成学习算法对单元分类器效果的弱性能进行提升,通过对学习步长和决策树分类器个数这两个参数的调优,构建一个在训练集和测试集上具有良好分类效果的模型,解决了传统能谱分析解谱方法中,重叠的能谱数据和能谱局部特征导致识别能谱精确度低的问题,可以高精确度的对核素识别分类。 本文不足处,在于样本数据集中的核素种类为9种固定类型,对于衰减生成的能谱数据中,能量复杂的未知能谱数据集的识别需要在下一步继续研究。3.2 AdaBoost集成算法对独立分类器模型的融合

4 测试结果及分析
4.1 模型参数寻优
4.2 多重核素鉴别结果

5 结 语
