动态语言字符串连接方法的性能研究
2019-03-05郑明秀
郑明秀
(西南民族大学计算机科学与技术学院,四川 成都 610041)
Python是一个有条理且强大的面向对象的程序设计语言[1].目前进入TIOBE世界编程语言排行榜前三名[2].Python正变得越来越普遍,它已经是各高校对于需要编程的所有科目的第一选择,并且现在也得到了工业世界的青睐.它的可扩展性,可嵌入性,丰富的库等特点,使其广泛应用于系统维护、图形处理、数据分析,文本处理,数据库编程,网络编程,机器学习,人工智能等方面[3-7].
Python具有高度的表现力且容易上手,其核心运行于一组非常优化的指令上,编程人员无需考虑底层计算元素,而专注于算法实现,这使得高度抽象化的软件在高度复杂化的硬件平台上较低的执行效率[8-11],其巨大的性能代价包括:Python虚拟机抽象让矢量操作不能直接可用,还影响了保存L1/L2缓存中相关数据的优化,最本质的因素是其动态类型以及并不是一门编译性的语言[12].其性能代价已成为业界的最大诟病,但是它能快速实现原型,若能根据操作对象做适当的代码优化,则能大幅提高代码运行效率.
Python应用于各领域,其中有大量的信息处理,信息处理中对字符串的处理占很高的比例,本文针对字符串操作方法性能作实验对比研究.
1 Python内存管理机制
Python是一种动态类型语言,采用基于值的内存管理机制,变量中并不直接存放值,而是存放值的引用[13-14].在程序执行过程中,变量名被绑定到不同的值,赋值运算符只是创建变量名称和值之间的关联.每个值都有自己的类型,但是变量名称是没有类型的,执行过程中,一个变量名可以绑定任意类型的值[15].
Python有两种共存的内存管理机制:引用计数和垃圾回收.引用计数是一种非常高效的内存管理手段,当一个Python对象被引用时其引用计数增加1,当其不再被某变量引用时则计数减1,当引用计数等于0时对象被垃圾回收器删除.
字符串是Python中不可变序列,不能直接对字符串对象进行元素的增删改操作.因此对字符串的增删改操作都将产生一个新的字符串,即在内存中重新分配内存空间并进行复制操作.
2 研究方法
2.1 基本假定
实际场景中对字符串的操作需求纷繁复杂,可能包含字符串的索引、切片、拼接、复制、搜索、统计、修改等等,为便于获取实验对比数据:
a)本实验仅研究字符串的拼接效率;
b)为简化实验,拼接对象假定为一个简单的短字符串;
c)实验研究三种字符串拼接方式:+运算符,join()函数以及推导式应用
2.2 研究内容
实验中需要处理时间,time库是python提供的处理时间的标准库,它提供系统级精确计时器的计时功能,可以用来分析程序的性能.本实验中仅需要使用其time()函数获得程序运行起始时刻和终止时刻,从而取得程序的运行时间.
使用如下代码计算连接运算符+的运算时间:

join()函数拼接字符串时需要生成列表,采用append()函数生成列表后使用join()连接字符串的代码如下:

采用列表推导式生成列表,再使用join()函数连接字符串的代码如下:

为了保证实验结果的稳定性,避免因计算机内随机因素导致的测试误差偏移过大,代码中的n值取1000000~100000000.

3 实验方法
3.1 实验环境
本实验在如下约束条件下进行:
·编程工具:Pycharm;
·解释器版本:python 3.7.0
·测试数据
√数据属性:字符串;
√数据规模:1000000~10000000;
√数据组数:10∗10组,即10个不同规模的数据组,每个不同规模的数据各自10组;
·实验环境
√OS:windows8.1中文版;
√处理器:Intel(R)CoreTMi7 4710MQ@2.50GHz 2.50GHz
√RAM:8G
√系统类型:64位操作系统,基于x64的处理器
3.2 补充说明
实验是由代码运行的起始时刻点与终止时刻之差表示代码运行的时间,系统中其它程序对CPU的占用将对实验结果产生较大的影响,因此实验开始前尽量关闭其它应用软件,降低计算机内部随机因素对实验结果可靠性的影响.另外需要多次实验采集实验数据样本,以提高实验结果的可信度.此研究对字符串连接进行了10次百万次级到千万次级运行时间的数据采集.
4 实验分析
4.1 基础数据分析
为避免实验受随机因素影响,上述实验共进行10次,下面从三个角度展示实验数据.表1是其中一次一百万次级到一千万次级字符串连接,三种连接方式的运行时间数据样本.数据显示连接运算符“+”需要的运行时间明显高于另外两种连接方式.
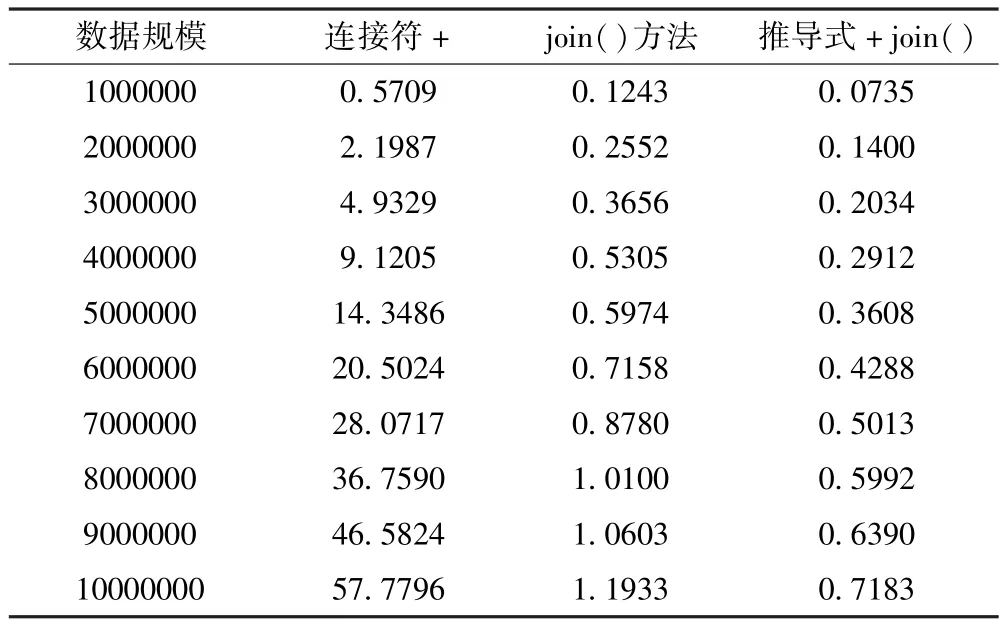
表1 三种连接方式的运行时间Table 1 Running time of three connection modes
表2是各种规模数据10次实验运行时间均值.表2于表1数据对照,可以看出同等数据规模的单次实验数据与均值之间差距不大.表3是数据规模500万次级的10次实验数据,可以看出10次同等数据规模的三种不同连接方式的自身的运行时间相近.因此可以认为本次实验数据样本是可信的.
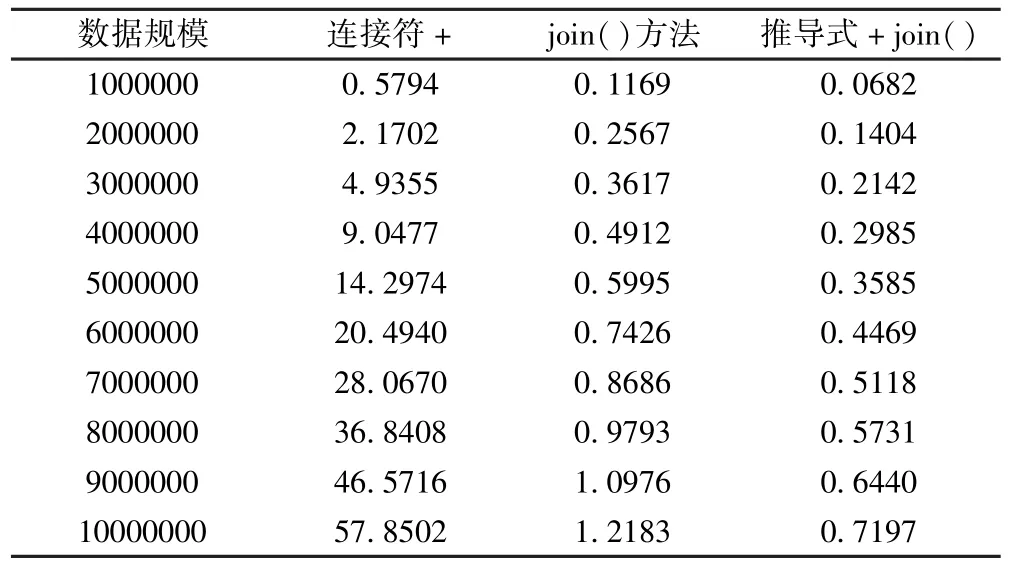
表2 10次实验数据均值Table 2 Mean value of 10 times experiment
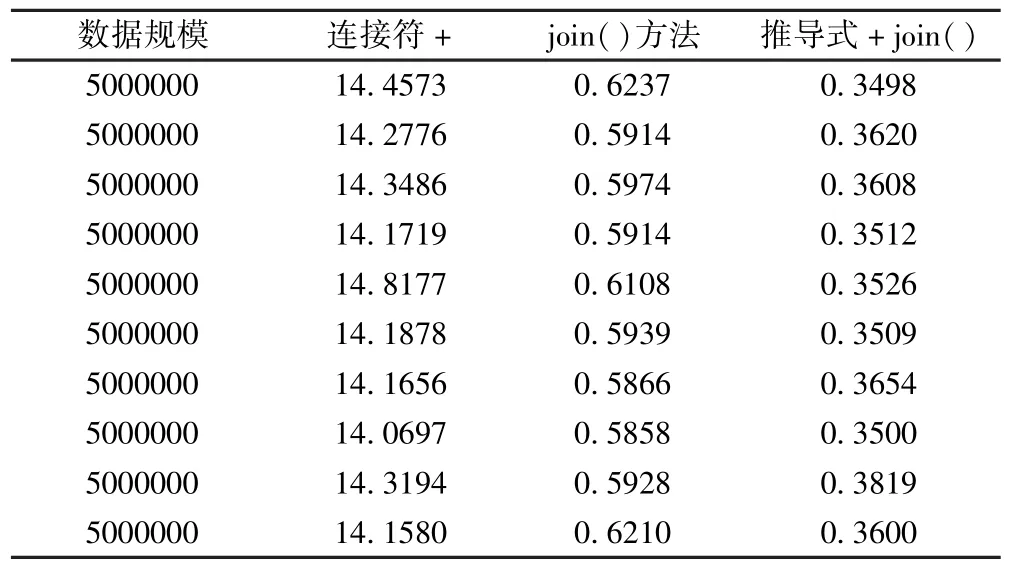
表3 数据规模5000000时运行时间Table 3 Running time of data size is 5 millions
4.2 可视化分析
图1和图2是对表2数据的可视化展示,可以看出连接运算符+随着数据规模的增长,其运行时间增长趋势是非常明显的,其图形显示不是线性关系,而是某种指数关系.由于连接运算符+所用运行时间远远大于另两种连接方式,因此图1中看不出join方法和推导式&join方法连接方式的趋势,这两种方式的运行时间对于连接运算符而言微乎其微.
图2是join()方法和推导式&join()方法运行时间的对比图,图形显示这两种连接方式使用推导式产生字符串列表后进行字符串连接的运行时间明显更少,两种连接方式运行时间均伴随数据规模的增长呈线性趋势.
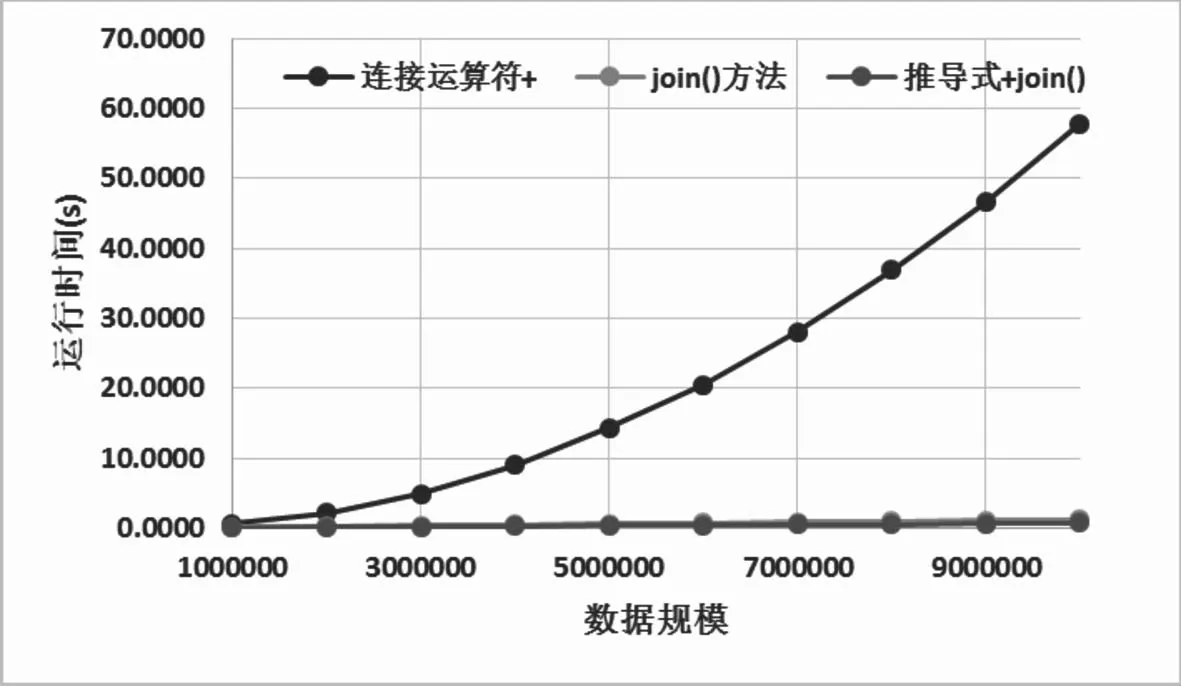
图1 三种连接方式运行时间曲线图Fig.1 Curves of running time of three connections
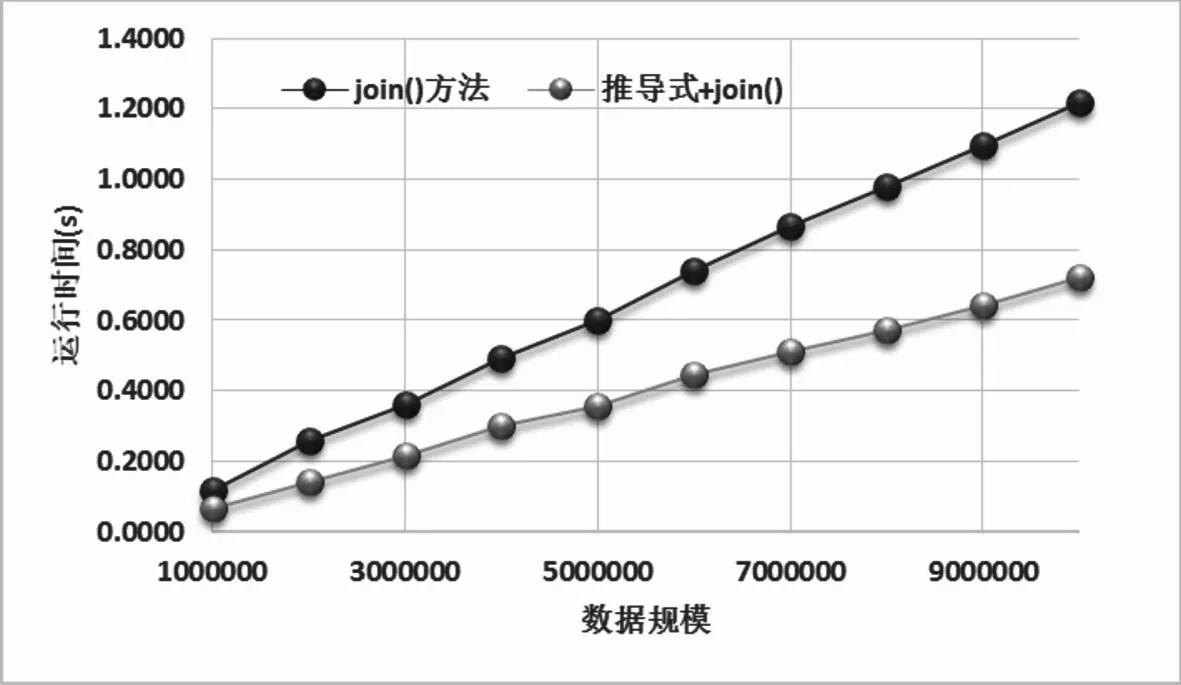
图2 Join方法与推导式&join方法对比图Fig.2 Comparison between join()and derived&join()
5 结论
本实验通过对三种不同连接方式的百万次级到千万次级数据规模的代码多次运行时间采样,从采样样本观察分析可知连接运算符“+”的代码运行效率极低,随着数据规模的增长,其运行时间呈指数级增长;join()方法连接字符串的运行时间远远优于使用“+”运算符连接字符串,对于大规模数据情况,join()方法的时间较“+”运算符,其耗时微乎其微.当推导式配合join()方法后,运行时间再次明显下降.
鉴于Python在如今大数据时代的流行趋势,这次实验研究对于使用Python作为大数据处理工具的代码优化具有一定的指导意义.
