微表情识别中面部动力谱特征提取的PCA改进*
2019-03-05刘本永
涂 亮 , 刘本永
(1.贵州大学大数据与信息工程学院,贵州 贵阳550025;2.贵州大学智能信息处理研究所,贵州 贵阳 550025)
0 引 言
表情作为一种有效的非语言交流媒介,是传播人类情感信息与协调人际关系的重要方式。近年来,人脸表情的研究范畴下又细化出了一个分支——微表情。与传统的宏观表情不同,微表情是一种非常短暂的、自发式的面部表情,持续时间仅为1/25~1/5 s[1]。 1966年,Haggard等[2]首次发现并提出了微表情概念。之后,Ekman等[3]在分析一段心理医生与抑郁症病人的对话视频时偶然发现了微表情。微表情能够揭示人们试图抑制的真实情感,为情感分析和谎言检测提供了重要线索,在国防、刑侦、医学、教育和商业等多个领域具有广阔的应用前景[4]。
早期对于微表情的研究多从心理层面入手,测量或训练个体的识别能力[5],但这种依赖肉眼的甄别方式费时、费力且可靠性低。微表情具有持续时间短和运动微小的特点,识别困难。近年来,人工智能的快速发展使微表情的自动识别成为可能,许多学者在这方面取得了一定的研究成果。Polikovsky等[6]将人脸划分为若干区域,使用3D梯度直方图描述各个区域随时间的运动特征,依靠聚类确定微表情起始、顶点和消逝三个阶段。Shreve等[7-8]从时空应变的角度展现脸部微表情变化的程度。Pfister等[9]使用时间插值模型归一化样本,用时空局部纹理描述子表征微表情随时间的变化。Wang等提出基于判别张量子空间分析的特征提取算法,在极端学习机中识别差异特征[10-11]。Peng等[12]提出一种称为双时间尺度卷积神经网络(DTSCNN)的双流模型,即应用不同的流用来适应微表情视频剪辑的不同帧率,并采用光流丰富数据特征。
对于传统人工特征方法,研究者很少关注人脸的精确对齐对微表情识别的影响。其中,要么假设所需的人脸已经精确对齐,要么比较依赖现有的人脸对齐算法,如主动形状模型(Active Shape Models,ASM)算法[13]。此外,现有的大多数方法都利用纹理特征来识别微表情,如Gabor滤波和时空局部纹理描述子,但这些特征并不容易直观地理解微表情。而基于深度学习的方法,虽然识别率上有所提高,但需要大量的样本,且模型训练比较复杂。
为了解决这些问题,Xu等[14]以光流场为描述微表情运动模式的基础特征,进一步精简表达形式,提出了面部动力谱特征(Facial Dynamics Map,FDM)。该算法能较好地捕捉细微的表情运动,为微表情提供直观有效的理解。同时,FDM算法把光流场进一步分割成小的时空立方体,在每个时空立方体中使用一种迭代算法抽取其主方向。该算法虽然能相对精确地找出时空立方体主方向,但复杂度高。
本文主要针对FDM方法中上述迭代算法的复杂性问题,采用PCA算法进行改进。由于它无需考虑迭代次数和是否收敛,成倍提升了算法的执行效率。
1 FDM算法
如图1所示,基于FDM的微表情识别的一般过程为:检测人脸的关键点;通过粗略对齐,检测并剪裁出人脸的区域;利用光流估计计算像素点运动;采用一维直方图统计实现光流场的精细化对齐,并描述不同尺度下的FDM特征;利用FDM特征和分类器进行微表情识别。由于微表情具有持续时间短和运动微小的特点,脸部精细化对齐显得尤为重要,而特征的描述也是准确识别的关键。

图1 人脸动态识别过程流程
1.1 精细化对齐
由于微表情涉及的面部肌肉较少,因此可以假设相邻帧中大部分面部区域保持不动。为了实现精细化对齐,需要抽取相邻两帧间的稠密光流场 (Ut,Vt),去除面部共同平移造成的误差[15]。具体地,定义误差为:
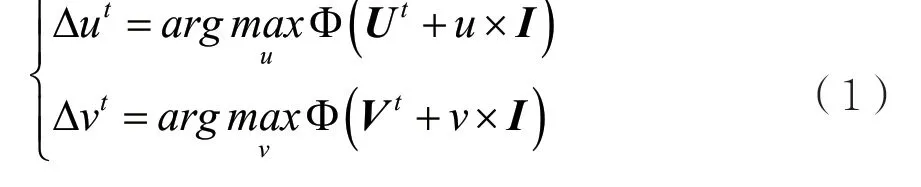
其中Ut和Vt分别是第t帧图像和第t+1帧图像之间光流场的水平分量和垂直分量。Φ(X)表示矩阵X中零元素的个数,I是全1矩阵。即要寻找水平和垂直方向的修正量,使得修正后的光流场矩阵中的大多数元素的值为0,这是基于相邻帧大部分面部区域保持不动的假设。为了解决这一优化问题,文献[14]采用一维直方图统计方法找到出现频率最高的值,即为水平和垂直方向的修正量。
1.2 FDM特征提取
将光流场进行精细化对齐后,需要描述特征提取FDM特征。因为面部表情是通过面部肌肉的运动产生的,所以可以做出两个合理假设:(1)当观察区域足够小时,面部表面在大致相同的空间方向上移动;(2)当观察时间足够短时,面部表面在大致相同的时间方向上移动。
考虑以上假设,当时空立方体相当小时,同一立方体中运动向量应大致处于相同方向。尽管光流估计会出现异常运动向量,但大部分被正确估计的运动向量具有相近的方向,从而可将光流场进一步分割成小的时空立方体,并使用迭代算法寻找主方向。用ωi,j表示立方体中i、j坐标处光流的运动向量,则主方向可由式(2)确定:
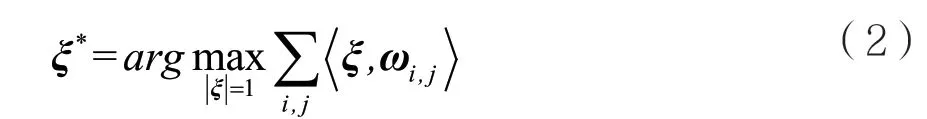
其中ωi,j取自τ个候选向量{ωti,j}τt=1,τ是时空立方体中的帧数。式(2)的目的是要找一个二维的方向向量ξ来描述时空立方体中最明显的运动。当ξ的长度固定时,ξ与ωi,j方向越接近,内积越大。但是,上述目标方程需要遍历所有的可能性,计算代价太大,因而采用迭代算法进行计算。
2 FDM算法的PCA改进
由于FDM中迭代算法复杂度高,在特征提取阶段,本文针对迭代算法进行改进,以提升FDM算法的效率。
2.1 PCA算法的核心思想
PCA是一种非监督学习算法,常被用来进行数据降维、有损数据压缩、特征抽取和数据可视化[16]等。PCA的主要目的是通过分析发现数据的模式来缩减维度,以此去除冗余数据并降低计算复杂度。这个过程的原则是使信息损失最小化。简单说,就是将数据从原始空间转换到新的特征空间,寻找出使数据方差都尽可能大的坐标轴。
PCA可以从两个等价视角进行解释:最大方 差[17]和最小重构误差[18]。这两种视角都希望找到一组正交投影,把原始数据投影到低维的线性子空间。但是,最大方差视角是希望数据投影后在投影方向上有最大方差,而最小重构误差视角是希望投影后的数据和原数据之间的均方差最小。
2.2 FDM迭代算法的PCA改进
本文提出利用PCA算法对FDM算法进行改进,即用PCA算法替代FDM中的迭代算法,抽取时空立方体主方向。以光流场的一个时空立方体中数据为例,数据和PCA特征向量的关系如图2所示。
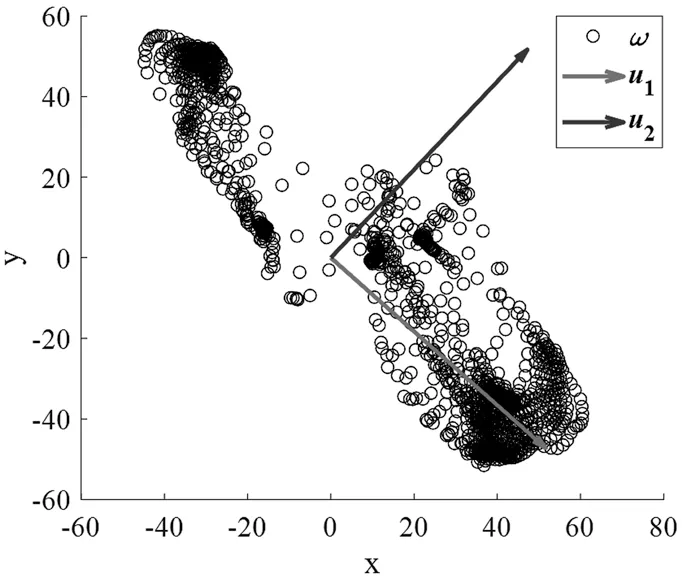
图2 时空立方体中数据和特征向量的关系
图2中,ω表示时空立方体中一个像素点处光流的运动向量,u1是最大特征值对应的特征向量,u2是第二个特征值对应的特征向量。一般情况下,PCA用来对高维数据进行降维,但这里是要找时空立方体主方向,不需要对数据降维。也就是说,不需要将数据投影到新的特征空间,只需求出PCA的第一主成分,即最大特征值对应的特征向量,也就是时空立方体的主方向。
作为无监督学习算法,PCA完全无参数限制,计算过程不需要人为的设定参数或是根据经验模型干预计算,最后结果只与数据相关,与用户是独立的。因此,在寻找主方向时,它不受其他参数的影响,只与数据本身有关。而迭代算法则与时间多样性、迭代次数和主方向向量是否收敛等有关。
3 对比实验
3.1 实验数据和参数设置
本实验采用芬兰Oulu大学2011年发布的数据库SMIC[9]作为实验样本。该数据库包含6个受试者的152段微表情连续的图像序列,这些图像序列是从通过短片诱发形式采集的视频中抽取获得的。用Si表示第i个受试者。SMIC数据库中不同受试者在不同类别下的样本数如表1所示。
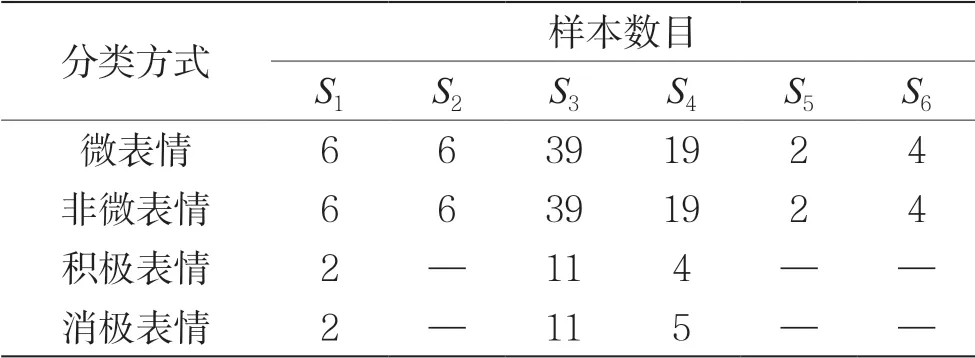
表1 不同受试者在不同类别下的样本数
先对图像序列作粗对齐、剪裁等预处理。提取特征后,采用SVM作为分类器。核函数使用径向基核函数,SVM分类器中的参数利用网格搜索方 法[19]进行估计。
由于数据库中图像序列的长度不一致,因此对每个图像序列进行等间隔采样,抽取10帧图片进行实验。根据文献[14],将光流场按(n×m,τ)的结构划分成小的时空立方体。其中,n×m表示光流场的空间划分,即每帧光流划分的区域数,取值为16×16;τ表示光流场的时间划分,即时空立方体包含的光流帧数。实验中算法的评价准则为识别率和计算时间。
3.2 实验结果分析
本实验采用留一样本评估方法进行交叉验证,即一个受试者作为测试样本,剩余5个受试者作为训练样本。用T表示测试样本,T=1代表用第一个受试者作为测试样本。同时,采用libsvm[19]自带的n-fold交叉检验模式作为参照。该模式随机地将数据剖分为n个部分,并计算交叉检验的平均识别率,此处n取值为6。由表1可知,SMIC数据库分为识别数据集和分类数据集。识别数据集包含微表情和非微表情,分类数据集包含积极表情和消极表情。在两个数据集下,微表情识别率如表2和 表3所示。

表2 识别数据集下微表情的识别精度

表3 分类数据集下微表情的识别精度
表2、表3的结果表明,在识别数据集下,原算法的识别率要高于改进算法;而在分类数据集下,改进算法的识别率比原算法高。这说明在寻找主方向时,迭代算法要比PCA算法更精准。从表2中T=5、T=6与其他取值的对比可以看出,用测试样本相对较少的受试者进行测试,即训练样本较多时,识别率越高。这说明训练样本越多,模型训练越充分,分类器的泛化能力越强。但是,训练样本过多,会导致模型的训练时间过长,不利于实时性要求。
算法的精确度需要牺牲算法的学习时间,两者难以兼顾。虽然改进算法在识别率上比原算法低,但算法效率更优。以两个数据集的前12个样本为例,PCA算法和迭代算法在计算时间上的对比,如图3和图4所示。

图3 识别数据集下主方向的计算时间
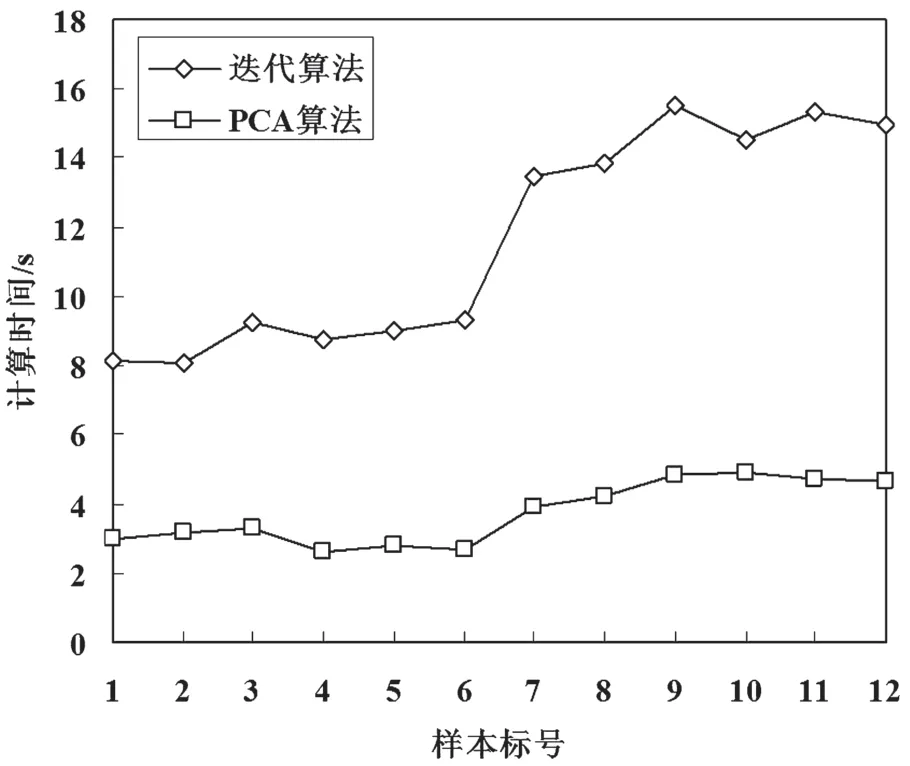
图4 分类数据集下主方向的计算时间
从图3、图4可以看出,迭代算法的计算时间远远长于PCA算法,时间成本高。分析算法的复杂度可知,PCA算法的时间复杂度为O(p2N+p3),p为光流向量的维度,且p=2。因为p的值较小可忽略不计,故PCA算法的时间复杂度约为O(N),而迭代算法的时间复杂度为O(Nτ+1)。其中N为时空立方体中光流向量的个数,τ为光流场的时间划分,最小取值为2,否则时空立方体就退化为单帧的光流,本实验中τ取值为3。显然,迭代算法的计算复杂度远比PCA算法高。综上所述,改进算法在识别率上与原算法相近,但效率显著提高。
4 结 语
微表情识别是近几年人工智能领域比较热门的课题,由于微表情具有持续时间短和运动微小的特点,识别难度较大。本文从微表情的特征提取环节入手,针对现有寻找时空立方体主方向的基于光流特征的FDM算法时间成本高的缺陷,探讨了基于PCA的改进算法。在相同的实验条件下,改进算法与原算法识别率相近,但运行速度远快于原算法。
FDM算法能很好地表达微表情的运动,易于可视化,便于深层次理解微表情。但是,除了寻找时空立方体主方向的计算时间长,稠密光流场的计算时间也较长,不适合作实时性的微表情识别。在后续微表情研究中,应考虑从提高识别率和降低时间成本两方面入手,研究如何提升像素级运动的估计效率,实现实时性、大规模的微表情识别。
