Adaptive deep residual network for single image super-resolution
2019-02-27ShuaiLiuRuipengGangChenghuaLiandRuixiaSong
Shuai Liu, Ruipeng Gang, Chenghua Li, and Ruixia Song
Abstract In recent years, deep learning has achieved great success in the field of image processing. In the single image super-resolution (SISR) task, the convolutional neural network (CNN) extracts the features of the image through deeper layers, and has achieved impressive results. In this paper, we propose a single image super-resolution model based on Adaptive Deep Residual named as ADR-SR, which uses the Input Output Same Size (IOSS) structure, and releases the dependence of upsampling layers compared with the existing SR methods. Specifically, the key element of our model is the Adaptive Residual Block(ARB),which replaces the commonly used constant factor with an adaptive residual factor. The experiments prove the effectiveness of our ADR-SR model,which can not only reconstruct images with better visual effects, but also get better objective performances.
Keywords single image super-resolution (SISR);adaptive deep residual network; deep learning
1 Introduction
Single Image Super Resolution(SISR)is a very classic and important task in the field of computer vision.Its main purpose is to reconstruct High Resolution(HR)image from Low Resolution(LR)image through Super Resolution (SR) technology. SISR can be widely used in safety monitoring, medical treatment,and automatic driving, etc.
In essence, SISR is an irreversible process. At present,the simple and fast super-resolution methods mostly use light field, patch-based, and interpolation methods [1—6], all of which rely on the smooth transition assumption of adjacent pixels. However,the interpolation methods will cause aliasing and ringing effects because of image discontinuities [7].
With the development of deep learning in recent years, Convolutional Neural Network (CNN) has made breakthroughs in computer vision tasks such as classification [8], detection [9], and semantic segmentation [10]. In the field of Super-Resolution,the main feature of CNN-based methods can fit the complex mapping more directly between LR image and HR image, it enables better recovery of missing high-frequency information (such as edges, textures),so its performance goes beyond many classic methods.
Based on the EDSR[11]model,we propose a single image super-resolution model named ADR-SR, as shown in Fig.1(b),which is a new SR model with the same size of input and output. ADR-SR releases the dependence of upsampling layers compared with the existing deep learning SR methods, and constructs a one-to-one mapping from LR pixel to HR pixel. The Adaptive Residual Block (ARB) is embedded in the ADR-SR to enhance the adaptive ability and improve the objective performance.
In summary, the main contributions of this paper are as follows:
·We propose an Input Output Same Size (IOSS)structure for the same size super-resolution task,which releases the dependence of upsampling layers compared with the existing deep learning SR methods. IOSS can solve SR task with the same input and output size as the actual needs.

Fig. 1 Comparison of (a) EDSR-baseline structure with our (b) ADR-SR structure. Note that our ADR-SR does not have any upsampling layers and uses Adaptive Residual Block (ARB). The position of the global residuals is modified, and the depth and width of the network are also modified.
·We propose an Adaptive Residual Block (ARB)based on adaptive residual factor, which solves the problem of poor adaptability caused by constant residual factor. Each channel in ARB has a different adaptive residual factor,and both adaptive ability and learning ability improve a lot.
·We propose a new idea for Super-Resolution network design. In some cases, adding width of the network has a significant performance improvement, and the convergence speed is faster.
2 Related works
2.1 Super-resolution model
According to whether the input size and output size are the same, the Super-Resolution model based on deep learning is divided into two types: model with different input and output size and model with the same input and output size.
The first type task: model with different input and output size, such as SRResNet [12], LapSRN [13],EDSR [11], etc, which reconstructs large image from small image. The key operation is mainly to increase the image size by the upsampling layer, in order to obtain a high-resolution output image. Currently,the commonly used upsampling layers include pixelshuffle, transposed convolution, etc. The essence of the first type task is to build a one-to-many mapping from LR pixel to HR pixel. The upsampling layer of EDSR is set at the end of the entire network,the feature after upsampling layer is the output image, so the EDSR increases the dependence on the upsampling layer. It is very unstable for one-tomany mapping and it cannot be better adapted to the second type task.
The second type task: model with the same input and output size, such as SRCNN [14], DRRN [15],VDSR [16], etc. They are more suitable for practical applications,such as mobile phone,camera,and other mobile devices. Due to the camera quality is low,the photos we take are not clearly, which means that Super-Resolution processing is needed. It is more in line with the needs of camera equipment that importing the captured photo directly into the network to reconstruct high-resolution photo of the same size. The second type task is the focus and difficulty of Super-Resolution research and application in the future, but there are few studies at present, and it has just begun to attract attention in recent years. When constructing a dataset, the high-resolution images are down-sampled and then up-sampled using bicubic interpolation to obtain lowresolution image of the same size. Since the input and output are the same size, no additional upsampling layer is needed in the network, and thus we can construct a one-to-one mapping from LR pixel to corresponding HR pixel, which is more stable compared to one-to-many mapping.
The comparison between the first type and the second type shown in Fig. 2 can clearly express that the first type of model reconstructs 4 output pixels from 1 input pixel, when the scale is 2. The pixel ratio of the input and output is 1:4 (the ratio is 1:16 when the scale is 4), the information of input is seriously insufficient, the spatial position information of the output pixel also needs to be trained, and the network pressure is large and unstable. The second type of model reconstructs 1 output pixel from 1 input pixel, ensures the spatial position, and reduces the pressure of the network. The overall performance of the network is greatly improved.
2.2 Residual block and residual scale factor
The residual block proposed by He et al. [17] adds the learned features to the residuals, further weakens the gradient disappearance and gradient explosion in deep networks, allows us to train deeper networks successfully, and has a good performance. SRResNet[12] uses the residual block in the SR task first and deletes the ReLU activation function layer between the connected residual blocks;EDSR[11]modifies the residual block based on SRResNet, deletes the batch normalization (BN) layer, multiplies the learned features by a constant residual scale factor (default is 0.1), and then adds it to the residual. They suppress the features to reduce the change of the residual,which is more conducive to the fast convergence in the early stage of training. However, multiplying all features by a constant residual scale factor forms a simple linear mapping, and the lack of nonlinear factor makes the network unable to handle more complex situations and reduces the learning ability.
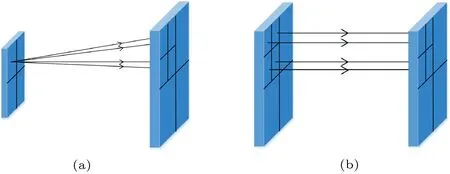
Fig. 2 Comparison of input and output between the first type and the second type of network. (a) The first type of network, which has different input and output sizes, reconstructs 4 output pixels from 1 input pixel. (b) The second type of network, which has the same input and output size, reconstructs 1 output pixel from 1 input pixel.
2.3 Squeeze and excitation module
CNN is characterized by a series of convolution layers, nonlinear layers, and down-sampling layers.This structural feature enables CNN to extract features with global receptive fields. Moreover,the performance of CNN can be greatly enhanced by adding multi-scale (Inception [18]), attention[19], context (Inside—Outside [20]), and other spatial feature enhancement mechanisms.
The Squeeze and Excitation Network (SENet [21])enhances feature extraction by building a Squeeze and Excitation (SE) module, which can clearly construct the relationship between different feature channels in the convolution layer. The SE module consists of two operations: Squeeze and Excitation.The squeeze operation compresses all 2-dimensional feature channels into 1-dimensional values by a global average pooling, in order to obtain an output vector with global corresponding features (dimensions are the same as the number of channels, assumingC). The excitation operation learns the relationship between each channels by learning a weight vector(the dimensions are stillC). Afterwards, the SE module uses weight vectors to enhance or suppress individual feature channels.
Since the different feature maps have different image feature coding characteristics [8] (such as contour, color, region, etc.), different features have different importance to the Super-Resolution task. Therefore, the characteristic of recalibration operation in feature map of the SE module is bound to improve the performance of the Super-Resolution model. This is one of the main motivations of this paper.
2.4 Deeper and wider model
For the classification task, the residual network(ResNet [17]) won the championship in ILSVRC [22],and the accuracy of the model has been greatly improved. The number of layers in ResNet is 152. A deeper layer means a deeper semantic feature which has a strong effect on the network’s understanding.In the Super-Resolution task, SRCNN [14] is the first network to use CNN, and it only has about 3 convoluation layers; SRResNet [12] embeds the residual block in the network, and it has 15 residual blocks; VDSR [16] uses the global residual structure to perform residual learning on the high-frequency information of the image, and uses gradient clipping to enhance the gradient transmission; meanwhile,they propose a theory of “the deeper, the better”,so the VDSR has 20 convoluation layers; EDSR [11]modifies SRResNet and has 32 residual blocks, but the training time also increases.
3 Proposed method
We choose EDSR-baseline [11] as the base model(As shown in Fig. 1(a)). EDSR is Enhanced Deep Residual Networks, and it has been modified on the basis of SRResNet [12]; not only the number of parameters is reduced, but also the performance is significantly improved. EDSR won the first place in the internationally renowned NTIRE2017 Super Resolution Challenge,representing the highest level of the current Super-Resolution field. However, EDSR cannot solve the same size super-resolution task and has poor adaptability. In order to make up the shortcomings of EDSR, we propose a new super resolution network named ADR-SR,which uses Input Output Same Size (IOSS) structure to ensure the same size of input and output (see more details in Section 3.1), embeds Adaptive Residual Block (ARB)into the network to enhance adaptive ability (see more details in Section 3.2), follows the new design idea and increases the width of the network(see more details in Section 3.3).
3.1 Network structure
In this paper, we propose an Input Output Same Size structure named IOSS for the second type task(Section 2.1). The upsampling layer in the base model is redundant because upsampling operation is not required. The convolution layer before the upsampling layer is used to expand the number of feature maps so that it can be better upsampled, but it is redundant after deleting the upsampling layer.The IOSS deletes the redundant layer, and it can not only reduce the complexity of the network, but also reduce the number of parameters. In addition, IOSS also modifies the global residuals from the first layer to the network input, in order to accommodate the second type task better. The gray layer of the base model in Fig. 1(a) is the redundant layer which is to be deleted. The IOSS structure can be applied not only to Super-Resolution task, but also to other image processing tasks.
3.2 Adaptive residual block
In order to increase the nonlinear mapping missing in the base model because of using a constant residual scale factor, we propose an Adaptive Residual Block named ARB.As shown in Fig.1(b),ARB uses the SE module to obtain the importance of different feature channels (adaptive residual scale factors), which are used to replace the constant scale factor, so that each channel has different adaptive residual scale factor to enhance adaptive and nonlinearity. Due to the feature suppression, the advantages of rapid convergence at the beginning of training are preserved.
Therefore, the ARB can be expressed as
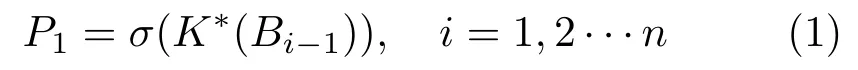
whereBi-1is the (i-1)-th output of the residual block,K*is a convolution operation whose channel width is 192,σmeans the activation function of
ReLU.

We have a 3×3 convolution operationKfor theP1inside the local residual block, and then mix and compress feature maps into 32 channels. The outputs above continue to enter the SE module which express asSE. Finally, its output is added to the output of the first residual block to obtain a local residual.
The global residual of this paper can be expressed as
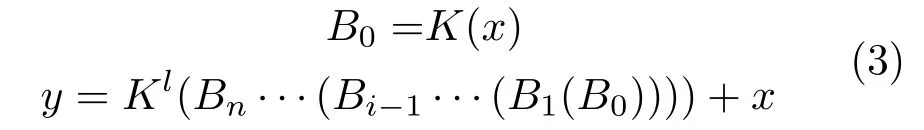
whereB0is the input of the local residuals,Klis a convolution operation with a feature channel number of 3. We add the output to the LR image to form a global residual to get the final super-resolution imagey.
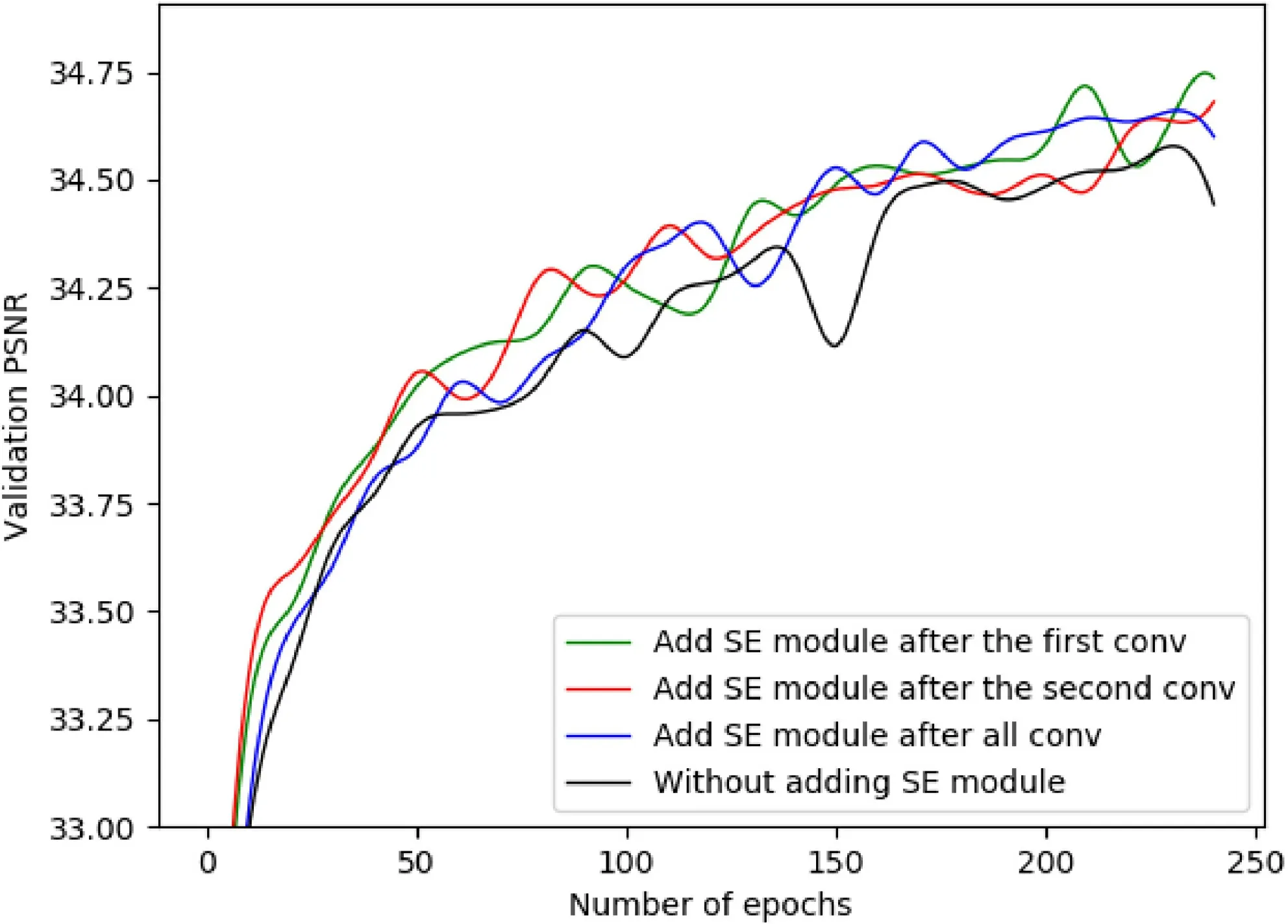
Fig. 3 Effects of adding SE module in different positions on the model.
Adding the SE module after both the first and second convolution layer in the residual block will have an effect of feature suppression, but for the former, the feature after suppression will also pass the activation function and the second convolution layer resulting in weakening the suppression effect again. For the latter,the SE module is added after the second convolution layer to suppress the feature,then we do the addition because of the residuals structure,and the suppression effect remains unchanged. The comparison of different situations is shown in Fig. 3.The performance of the SE module after the second convolution layer is a little different from other cases;however, the PSNR of the validation set is small at the initial stage of training, and the model converges are faster and more stably. Therefore, the SE module is set after the second convolution layer in our ARB.It is worth noting that the PSNR of the model without the SE module is relatively low, and the additional complexity brought by the addition of the SE module is minimal (2%—10% additional parameters,<1%additional computation [21]), which also verifies the effectiveness of our ARB.
As shown in Fig. 4, we compare the residual block structure of different models including the original residual block, the SRResNet residual block, the EDSR residual block, and our ARB.
3.3 The increase of channel width
For Super-Resolution task, a wider network can achieve similar or even better results than a deeper network in some cases, when we construct a mapping from LR pixel to HR pixel. Excessive network layers will not bring huge upgrades, but increase training costs.
In this section, we compare the effects of increasing the width and increasing the depth on the model,where the number of parameters is approximately the same (about 0.3M). As shown in Fig. 5(a), the horizontal axis represents the number of training epochs, and the vertical axis represents the PSNR of the validation dataset. The model curve with the depth of 16 and the width of 32 is a control group.It can be clearly seen that the effect of the model with the depth of 16 and the width of 64 (the depth remains unchanged and the width is expanded by 2 times) is significantly improved in numerical value.However, the effect of the model with the depth of 32 and the width of 32 (the depth is expanded by 2 times and the width remains unchanged) is slightly lower than the control group. In Fig.5(b),we provide another set of experiments to verify the above points.
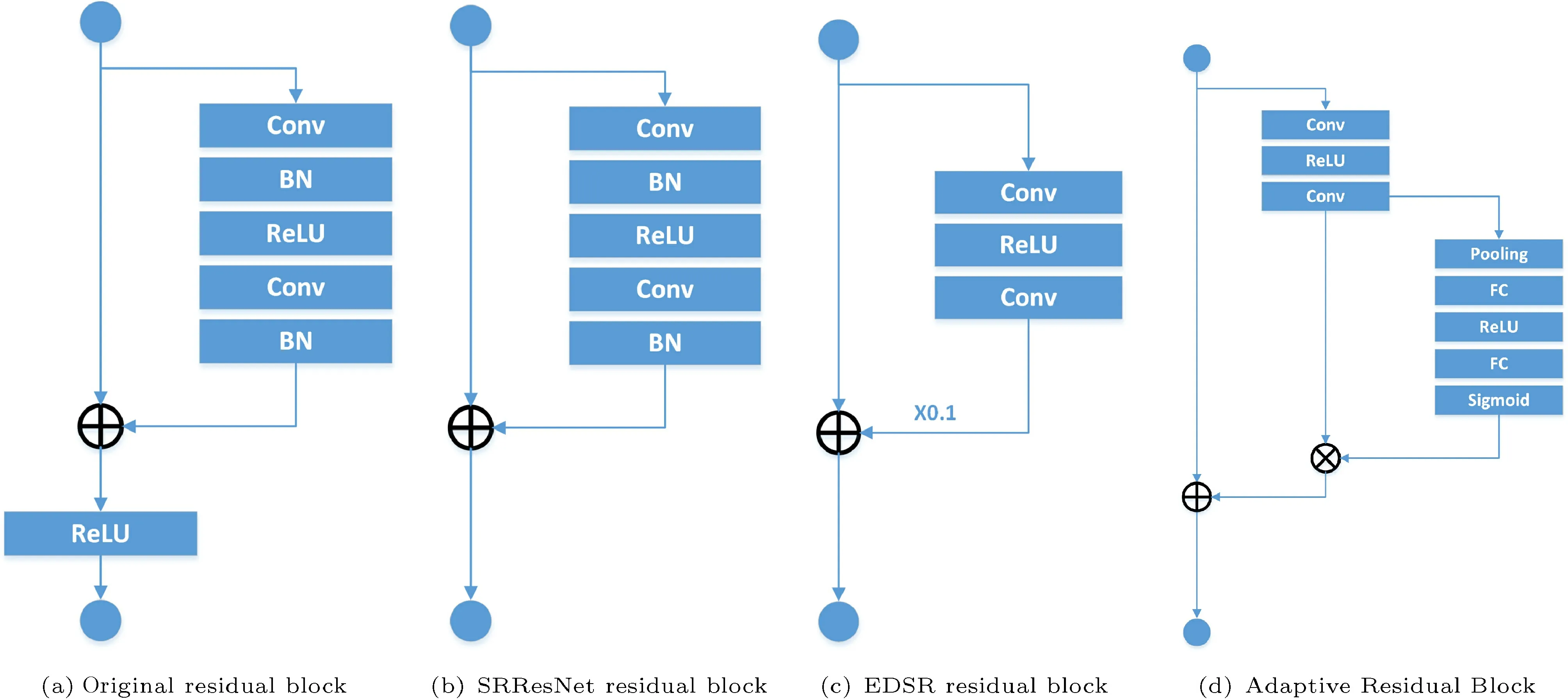
Fig. 4 Comparison of different residual block structures. (a) Original residual block, which is proposed in ResNet. (b) SRResNet residual block,which removes the last activation function from the original residual block. (c) EDSR residual block, which removes the BatchNormalization from the SRResNet residual block and adds a fixed factor of 0.1. (d) Ours Adaptive Residual Block (ARB), which replaces the fixed factor with the SE modules to increase adaptability.
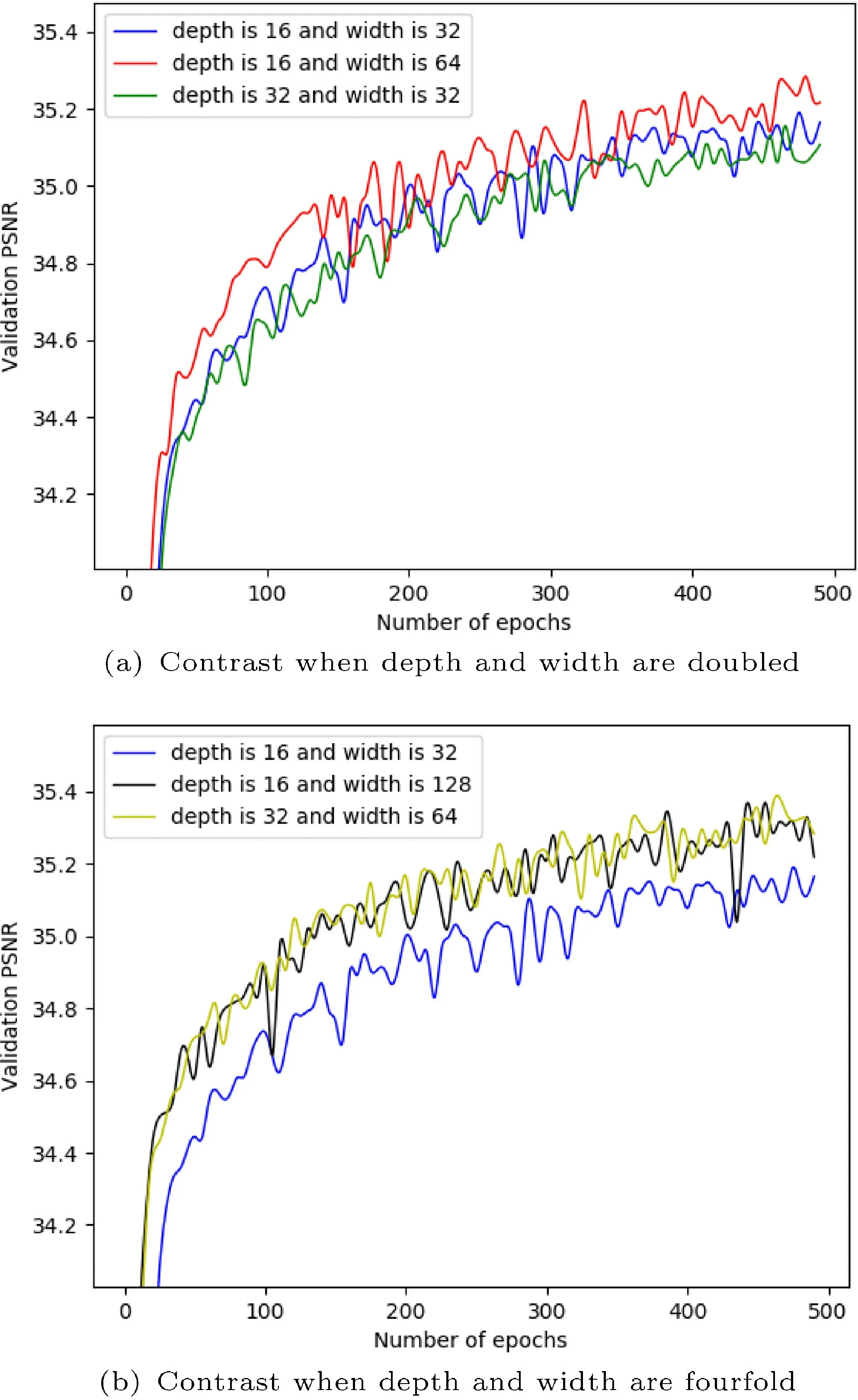
Fig. 5 Effects of increasing depth and increasing width on the model.
Based on the above conclusions, we propose a new idea for Super-Resolution model design. Compared with increasing the depth of the network, increasing the width of the network can better adapt to the image restoration task. Thus, the reconstruction task has equal or better enhancements than the deep features as the increase of the shallow features.Compared with the base model, we increase the width in the residual block about 3 times which is from 64 to 192, so that the model has more shallow features. In addition, in order to balance the number of parameters and training time, we also reduce the number of input feature channels of the residual block by half which is from 64 to 32. The constantnis the number of residual blocks, and our ADR-SR and the EDSR-baseline have the same number of residual blocks (n=16).
4 Experiment
4.1 Datasets and evaluation performances
Following the setting in EDSR[11],we train our ADRSR on the DIV2K[23]dataset,and evaluate it on four standard benchmark datasets (including Set5 [24],Set14[25],B100[26],and Urban100[27]). DIV2K has 1000 2K HD images, including 800 training images,100 validation images, and 100 testing images. In the process of constructing LR training images, we first use the bicubic interpolation function to reduce the original HR image to different scales, and then interpolate them to the original size. In this paper,the objective signal is evaluated by two performances:Peak Signal to Noise Ratio (PSNR) and Structural Similarity Index (SSIM).
4.2 Training details
In the training of this paper, the RGB image is randomly cropped into a 96×96 pixel frame as input. Data enhancement methods include: random horizontal flip, random vertical flip, and random rotation of 90 degrees. The pre-processing operations include: meanization(minus the mean of the training set to make the mean of the input is 0)and normalized(divided the variance of the training set to make the variance of the input is 1). The optimizer is Adam [28], where the hyperparameter is set to:β1= 0.9,β2= 0.999,∈= 10-8. The training batch size is 16, the learning rate is initialized as 0.001,which is reduced in 200k, 400k, 600k, and 800k iterations, and the scale of the reduction is 0.5. The loss function is L1 loss. The training environment is NVIDIA Titan XP GPUs and PyTorch framework.
4.3 Experimental results
As shown in Table 1, we test the performance of different algorithms on standard benchmark datasets and give quantitative evaluation results.The first line gives a comparison model, including LapSRN[13],VDSR[16],DRRN[15],SRResNet[12],SRDenseNet [29], CARN [30], MCAN [31], EDSRbaseline [11], and our ADR-SR. The first and second columns represent different benchmark datasets and corresponding scales. The table gives the quantitative value (PSNR/SSIM) results of the various models in different datasets and different scale settings, where the optimal results are shown in bold.
In order to ensure the fairness of the experimentdata, we reproduce the test results of the comparison model and obtain the relevant experiment data, and all the pre-training comparison models are derived from the network open source. The datasets are constructed by the bicubic interpolation function,and PSNR and SSIM are calculated on the three channels of RGB space. There is a slight deviation from the original data, due to the different construction methods of the partial comparison model and some of the original paper calculate PSNR and SSIM on the Y channel of the YCbCr space.
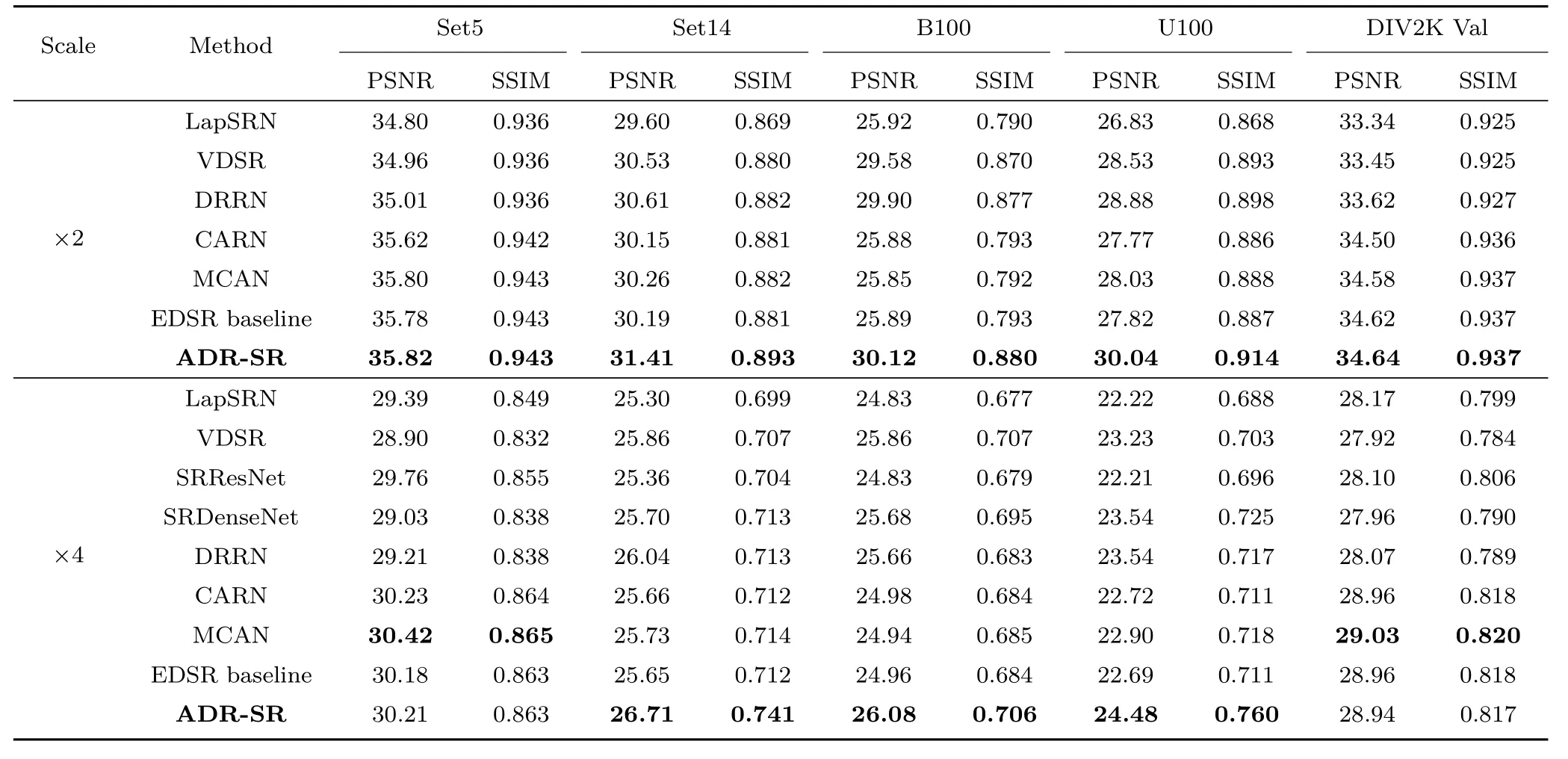
Table 1 Quantitative comparison with the state-of-the-art methods based on ×2, ×4 SR with bicubic degradation model
It can be seen from Table 1 that in the tasks of different training sets with scale 2, our ADR-SR is optimal in objective performances, and the PSNR and SSIM are higher than the second method. Due to the error caused by different data construction methods, in the DIV2K validation dataset of scale 4,ADR-SR has a small lower of 0.02 and 0.001 on the PSNR and SSIM compared with the EDSR-baseline model,but on other datasets,our ADR-SR are higher obviously.
Experiment shows that our ADR-SR achieves relatively good visual effects and objective performances on different scale tasks of different standard benchmark datasets, and ADR-SR has obvious advantages in image clarity, spatial similarity, and image texture details.
In order to verify the validity of the ADR-SR, we take the Urban100 and DIV2K datasets as examples to select some images, and compare them with LapSRN,VDSR,DRRN,CARN,MCAN,and EDSRbaseline. The bicubic interpolation method is also shown as a reference. As shown in Fig. 6 and Fig. 7, the red dotted box highlights the obvious advantages of our ADR-SR. It can be clearly seen from the experiment results that our ADR-SR has a better Super-Resolution effect than other models when dealing with the edge of the object. The edge distinction is more significant, the detail information missing from many other models is reconstructed,and the visual effect is greatly improved.
5 Conclusions
In summary, we proposes a single image superresolution model named ADR-SR based on adaptive deep residual, which can be used for super-resolution task with the same size of input and output image.The visual effects and objective performances of the experiment demonstrate the effectiveness of our ADR-SR. The specific innovations are: (1) Input Output Same Size structure (IOSS) for same size super-resolution task. (2) Adaptive Residual Block(ARB), the adaptive ability and convergence speed improve a lot. (3) A new idea for super-resolution network design increases the width of the network instead of the depth to obtain additional performance improvements.

Fig. 6 Comparison of experimental effects of Urban100 dataset.
Acknowledgements
This work was supported in part by National Natural Science Foundation of China (No. 61571046)and National Key R&D Program of China (No.2017YFF0209806).
Open AccessThis article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format,as long as you give appropriate credit to the original author(s)and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use,you will need to obtain permission directly from the copyright holder.
To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095.To submit a manuscript, please go to https://www.editorialmanager.com/cvmj.
杂志排行

Computational Visual Media的其它文章
- Computational Visual Media TOTAL CONTENTS IN 2019
- SpinNet: Spinning convolutional network for lane boundary detection
- A three-stage real-time detector for traffic signs in large panoramas
- InSocialNet: Interactive visual analytics for role–event videos
- Mixed reality based respiratory liver tumor puncture navigation
- Evaluation of modified adaptive k-means segmentation algorithm