社会化标注系统中个性化信息推荐多维度融合与优化模型研究
2019-02-25武慧娟孙鸿飞金永昌
武慧娟 孙鸿飞 金永昌
摘要:[目的/意义]在社会化标注系统自组织运行的基础上,构建个性化信息推荐的多维度融合与优化模型.进而在大数据环境下.为用户提供精准的个性化信息推荐服务.从而进一步丰富个性化信息推荐的理论体系以及拓展个性化信息推荐的研究方法。[方法/过程]首先,对每一种个性化信息推荐方法的优点和不足进行深入分析;然后,将基于图论(社会网络关系)、基于协同过滤以及基于内容(主题)3种个性化信息推荐方法进行多维度深度融合,构建个性化信息推荐多维度融合模型:最后,对社会化标注系统中个性化信息推荐多维度融合模型进行优化,从而解决个性化推荐过程中用户“冷启动”、数据稀疏性和用户偏好漂移等问题。[结果/结论1通过综合考虑现有的基于图论(社会网络关系)、基于协同过滤以及基于内容(主题)的个性化信息推荐方法各自的贡献和不足,实现3种方法之间的多维度深度融合,并结合心理认知、用户情境以及时间、空间等优化因素,最终构建出社会化标注系统中个性化信息推荐多维度融合与优化模型。
关键词:个性化信息推荐;社会化标注;多维度融合;优化模型
DOl:10.3969/j.issn.1008-0821.2019.01.005
[中图分类号]G203;G252 [文献标识码]A [文章编号]1008-0821(2019)01-0037-06
社会化标注系统是一种由它组织向自组织渐进渐变的复杂系统,其内部的信息组织并不是由外部力量直接安排的结果,而是在其内部规律支配下的自身演进发展的结果。因此,在遵循社会化标注系统自组织运行的基础上,构建个性化信息推荐多维度融合模型,将目前现有的个性化信息推荐方法进行融合与优化,从而发挥每种方法的优点,回避它们的缺点,进而实现在大数据环境下,为用户提供精准的个性化信息推荐服务。
开展社会标注系统中个性化信息推荐的研究具有十分重要的理论价值和应用价值,具体地主要体现在两个方面:第一,从各类社会化标注系统的应用平台角度出发,机构可以掌握用户行为和用户偏好的特点,能够从宏观、中观和微观三个层次逐层向用户推荐个性化的信息,从而为政府部门、图书馆等信息服务机构更好地为用户提供个性化信息服务起到积极的理论与实践指导意义。第二,从社会化标注系统的使用用户角度出发,面对海量数据,用户可以更有效地享用自己需求和偏好的信息资源以及发现与自己需求和偏好相同的其他用户,从而为更有效率地使用网络信息平台起到积极的理论与实践指导意义。
1国内外相关研究现状及研究趋势
“社会化标注系统”最早引起国外学者的关注是在1999年,国内是在2008年。“个性化推荐”则是在20世纪90年代提出的这一概念。总结国内外关于社会化标注系统中个性化信息推荐方法,主要包括:基于内容(主题)的个性化推荐、基于协同过滤的个性化推荐、基于图论(社会网络关系)的个性化推荐以及其他个性化推荐方法(包括:基于知识的个性化推荐、基于关联规则的个性化推荐、混合推荐等)。
1.1基于内容(主题)的个性化信息推荐
基于内容的个性化信息推荐是指通过对用户的历史行为信息进行分析,提取用户需求和偏好特征并且构建相应的用户需求和偏好模型,由此向用户推荐与其需求和偏好模型相匹配的资源。该推荐方法的核心在于利用用户需求和偏好与目标资源的相似性来过滤信息,进而实现个性化信息推荐。基于内容的个性化信息推荐的不足之处在于虽然能够较为准确地获取用戶需求和偏好,但由于是根据用户的历史行为信息实现用户需求和偏好的提取,而用户的需求和偏好会随着时间的推移发生变化和漂移,因此该推荐方法很难发现用户潜在的需求和偏好以及难以实现所推荐资源的多样性。
基于主题的个性化信息推荐是指从社会化标注系统的语义角度对信息资源进行深度挖掘,并且在此基础之上再进行用户需求和偏好和目标资源之间的相似性判断,从而使得所推荐资源更加符合用户的个性化需求和偏好。基于主题的个性化信息推荐的不足之处在于由于该推荐方法需要机器学习各种精确的数学匹配算法,以及需要机器分析语义的概念,从低维主题到高维主题进行用户需求和偏好与目标资源之间的相似性检索和匹配,因此为了实现更有效地从海量数据中进行相似性检索和匹配,计算过程需要花费一定的时间才能够挖掘出有价值的个性化信息。
1.2基于协同过滤的个性化信息推荐
基于协同过滤的个性化信息推荐是指根据具有相似兴趣的用户的历史行为信息(例如以往的浏览记录等)来预测目标用户未来可能的需求和偏好,从而为之推荐相应的资源。类似地,用户对于相似标签的需求和偏好程度也在一定程度上反映了用户之间的相似度。可见,基于协同过滤的个性化信息推荐包括基于用户的协同过滤方法和基于资源的协同过滤方法。
基于协同过滤的个性化信息推荐的不足之处在于以用户过去的信息行为来计算相似度。因此需要大量的历史数据才能较好地衡量相似性以及挖掘出用户潜在的需求和偏好。同时,在海量数据的情况下计算相似度也是非常耗费时间的。此外,很多在线用户的信息行为并不十分明显(例如浏览过程中的关注和收藏行为等),甚至是“冷启动”,从而导致初始推荐质量较低、可扩展性较差等问题出现,因此如何准确判断这一类用户的信息行为还是一个研究难题。
1.3基于图论(社会网络关系)的个性化信息推荐
由于社会化标注系统是一个复杂网络,所以许多学者利用图论的相关理论来描述和刻画标签,分别使用了3部分图、超图和社会网络分析等方法来描述社会化标注系统中的各种组成要素。特别是随着社会网络分析理论和方法的发展,从社会网络的角度分析社会化标注系统的网络结构,对其中的资源、标签、用户三者各自的网络结构进行数据挖掘。
基于图论(社会网络关系)的个性化信息推荐采用向量来表示用户—资源、资源—标签、用户—标签两两之间的关系,尤其是从社会网络分析的角度分析社会化标注系统的网络结构,分析用户所在的群体特征,进行群体用户行为的分析等。但是,其不足之处在于基于图论(社会网络关系)的个性化信息推荐是从宏观的角度来划分用户群体,而对于每一个具体用户行为的微观分析略显不足。
1.4其他个性化信息推荐
其他个性化信息推荐还包括基于知识的个性化推荐、基于关联规则的个性化推荐以及混合推荐等等。其中,基于知识的个性化信息推荐是指利用特定领域的知识或规则进行推理,不是通过挖掘用户的需求和偏好,而是通过用户知识和资源知识实现个性化信息推荐;其主要缺点在于特定领域的知识或规则难以获得而且属于静态推荐。基于关联规则的个性化信息推荐是指利用资源之间的某种关联规则,通过数据挖掘技术挖掘出用户已有资源与目标资源之间的相关性,从而实现个性化信息推荐;其主要缺点在于存在数据稀疏性以及用户“冷启动”等问题。
综上所述,每一种个性化信息推荐方法都有其优点和不足之处,因此如何选取每种方法的优点,进行相互融合与补充,从而规避它们的缺点,实现更加精准的个性化信息推荐,就成为当前个性化信息推荐领域亟待解决的重要问题。
2社会化标注系统中个性化信息推荐多维度融合与优化模型的研究框架
本文在利用自组织理论深度挖掘社会化标注系统内部演化机理和个性化信息推荐机理的基础上,多维度融合基于内容(主题)、基于协同过滤以及基于图论(社会网络关系)3种个性化信息推荐方法的优点,构建社会化标注系統中个性化信息推荐多维度融合与优化模型,以期解决社会化标注系统中个性化信息推荐的过程中有关用户“冷启动”、数据稀疏以及用户偏好漂移等问题,最终实现更加精准的个性化信息推荐。
具体地说,开展社会化标注系统中个性化信息推荐多维度融合与优化模型研究主要解决以下几个关键问题:
1)在用户没有留下任何历史记录的情况下,个性化信息推荐多维度融合模型如何实现精准的信息推荐,即如何解决系统中用户“冷启动”问题。
2)随着时间的推移,用户的需求和偏好会发生漂移现象,个性化信息推荐多维度融合模型如何适应用户的需求和偏好漂移现象,进而实现用户的需求和偏好的动态跟踪与信息推荐。
3)从现有的调研数据分析,目前的社会化标注系统中的标签数据呈现出明显的幂律分布,即大量的标签用户很少使用,而少量的标签受到大量用户的频繁使用,同时用户添加标签的积极性并不高,这便产生了系统中数据的稀疏性问题。在这种情况下,个性化信息推荐多维度融合模型如何进行精准的信息推荐。
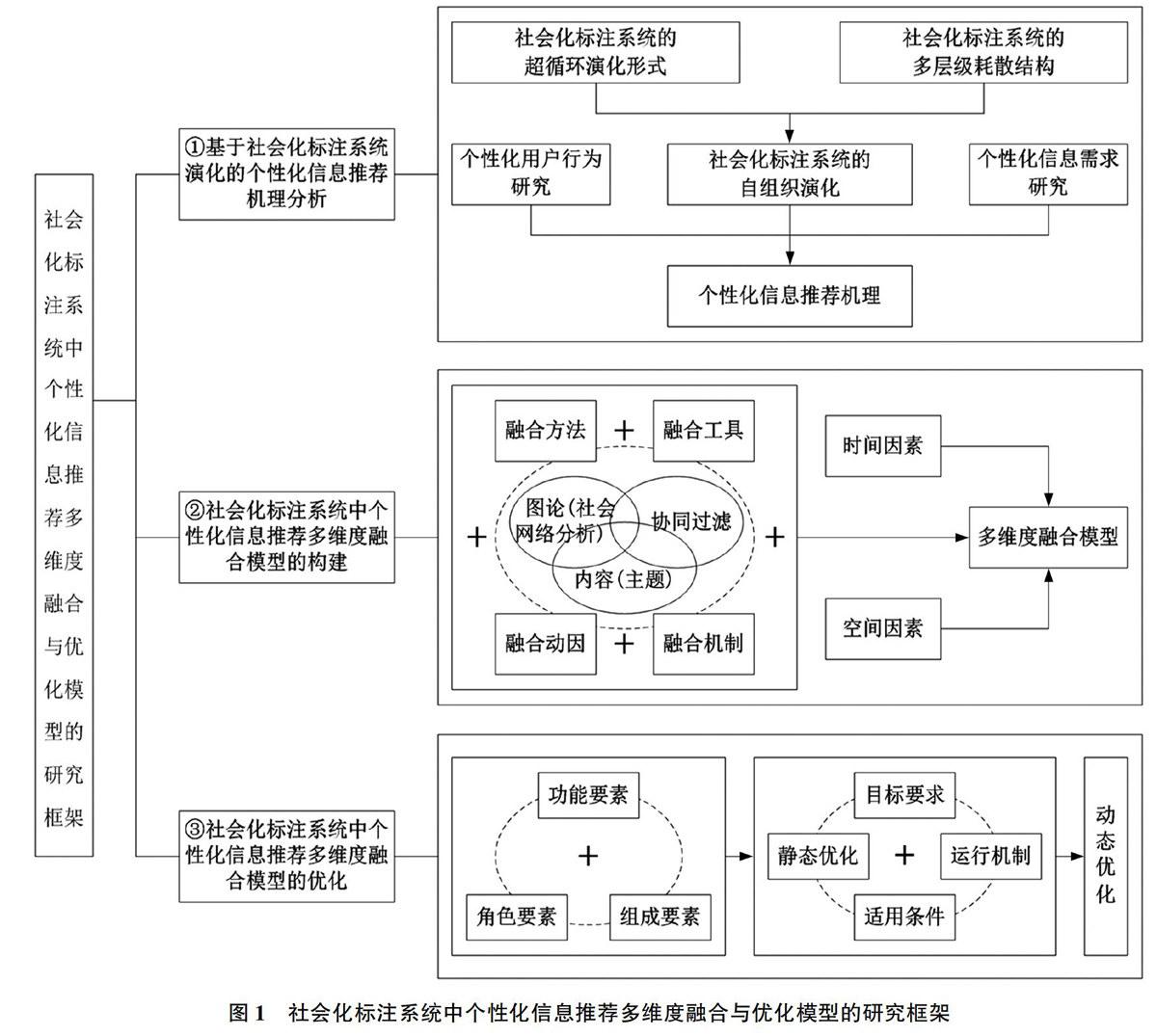
因此,本文首先提出社会化标注系统中个性化信息推荐多维度融合与优化模型的研究框架,如图1所示。
从中可以看出,社会化标注系统中个性化信息推荐多维度融合与优化模型的研究主要包括以下3个方面的内容:
1)基于社会化标注系统演化的个性化信息推荐机理分析
通过对基于社会化标注系统演化的个性化信息推荐机理进行研究,分析社会化标注系统的自组织超循环演化形式和耗散结构,从个性化用户行为和信息发现两个角度进行探讨。
第一,从系统演化的角度,分析社会化标注系统的结构特征,利用自组织理论分析社会化标注系统的自组织演化特性,借助超循环理论分析社会化标注系统以及3个集合(标签集、资源集、用户集)的自组织演化过程,构建社会化标注系统的自组织超循环演化形式。
第二,根据耗散结构理论,对社会化标注系统的耗散结构进行多层次研究,具体分析社会化标注系统的内部正熵和外部负熵之间的关系、系统整体熵的演化方向、系统的有序度和平衡态,构建社会化标注系统的多层级耗散结构。
第三,利用社会化标注系统中蕴含的大数据,从中挖掘出用户行为数据,进行深度分析,发现用户行为特征,归纳用户的个性化信息需求和偏好,揭示社会化标注系统中个性化信息推荐机理。
2)社会化标注系统中个性化信息推荐多维度融合模型的构建
对于现有的基于图论(社会网络关系)、基于协同过滤和基于内容(主题)的个性化信息推荐方法,通过深入分析这三种推荐方法各自的优缺点,充分考虑它们的主要贡献,规避它们的不足之处,寻找三者之间的融合点,采用适当的融合方法和融合工具,挖掘其内在的融合动因和融合机制,同时考虑社会化标注系统在结构演化过程中的时间因素,结合用户、资源、标签为一体的向量空间因素,充分发挥基于社会网络分析、内容(主题)本体、协同过滤等方法的特点和优点,实现3种方法的深度融合,最终构建社会化标注系统中个性化信息推荐的多维度融合模型,使其能够解决社会化标注系统中个性化信息推荐的过程中有关用户“冷启动”、数据稀疏和用户偏好漂移等问题,最终实现更加精准的个性化信息推荐。
3)社会化标注系统中个性化信息推荐多维度融合模型的优化
将社会化标注系统中个性化信息推荐多维度融合模型进行静态优化和动态优化,从而揭示构成个性化信息推荐多维度融合模型中各个要素之间的联系以及动态变化。
第一,从系统学的角度,充分考虑所构建的个性化信息推荐多维度融合模型的系统结构是由许多要素组成的,要素是系统中对整体性质和体系结构起到主要和关键作用的主要元素,其中静态优化主要从功能要素、角色要素、组成要素3个方面对所构建模型展开优化。
第二,从系统动力学的角度,充分考虑所构建的个性化信息推荐多维度融合模型的时间适用性、用户偏好的漂移性,从模型的目标要求、适用条件,尤其是模型内部各个要素的运行机制,将静态优化转换成为动态优化,从而实现个性化信息推荐的动态适应性。
3社会化标注系统中个性化信息推荐多维度融合与优化模型构建
结合前文所述社会化标注系统中个性化信息推荐领域存在的问题以及社会化标注系统中个性化信息推荐多维度融合与优化模型的研究框架及其内容,本文提出构建社会化标注系统中个性化信息推荐多维度融合与优化模型。
首先,以个性化信息推荐领域存在的问题为导向,将基于图论(社会网络关系)、基于协同过滤和基于内容(主题)的个性化信息推荐方法相融合,从而发挥社会网络分析的宏观作用,协同过滤算法的中观作用以及本体语义分析的微观作用,彼此之间相互融合,以解决个性化信息推荐过程中用户“冷启动”的问题。
其次,在构建社会化标注系统中个性化信息推荐多维度融合与优化模型的过程中需要着重考虑:在时间方面,需要考虑在社会化标注系统自组织演化的过程中,用户信息行为以及用户信息需求和偏好所发生的变化;在空间方面,需要考虑用户、资源、标签三者在空间某一点进行统一的问题,即如何构建用户的个性化信息点。由此,使得所构建的社会化标注系统中个性化信息推荐多维度融合模型,能够解决个性化信息推荐过程中用户偏好漂移的问题。
再次,在实现将3种个性化信息推荐方法深度融合的过程中,需要发现社会化标注系统在自组织演化过程中的平衡极点。社会化标注系统在有序度最高的时候,平衡达到极点,在此时对社会化标注系统进行用户行为分析、资源相似性分析以及用户信息需求分析,将会准确地分析出用户的行为特征和偏好特征,準确地实现资源与偏好相匹配,使得个性化信息推荐的准确率更高。
最后,对个性化信息推荐多维度融合模型进行静态优化与动态优化,既要体现出多维度融合模型的运行机制,展示其结构特征——功能要素、角色要素、组成要素,以及各要素之间的内部本质联系;又要体现出多维度融合的过程和个性化信息推荐的过程,遵循社会化标注系统自组织演化的过程,从而揭示出构成个性化信息推荐多维度融合模型中各要素之间的动态变化。同时,结合用户标注过程中的偏好漂移、信息推荐的目标要求、融合模型的运行机制等因素,从而解决幂律分布问题,突破用户“冷启动”和用户偏好漂移的问题。
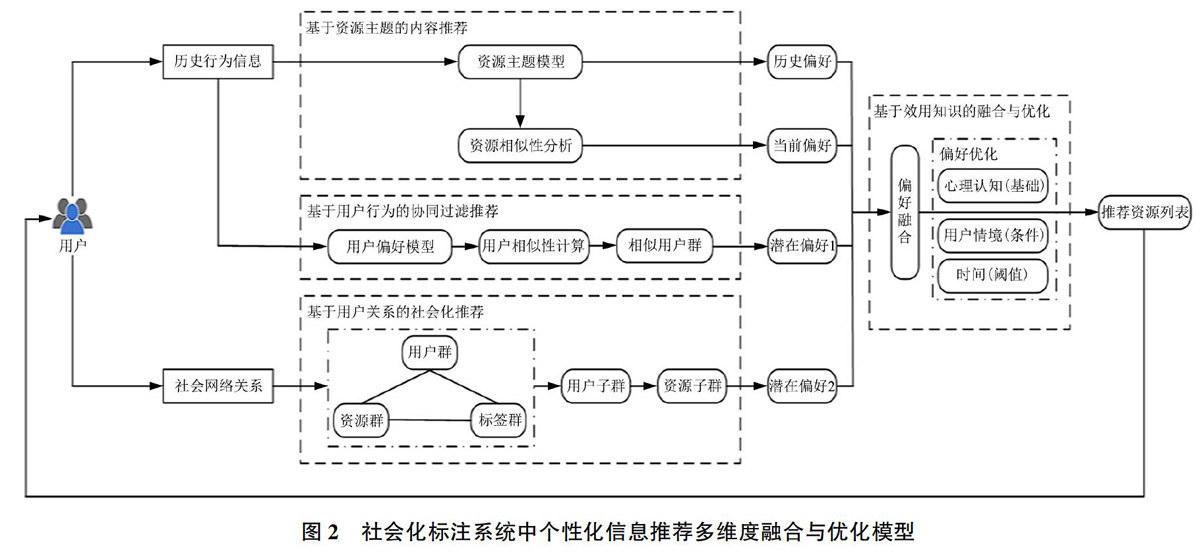
综上所述,本文所构建的社会化标注系统中个性化信息推荐多维度融合与优化模型,具体如图2所示。
从中可以看出,社会化标注系统中个性化信息推荐多维度融合与优化模型主要包括以下几个方面内容:
1)通过对目标用户的历史行为信息进行深度挖掘,根据基于资源主题的内容推荐方法形成资源主题模型,从中获取用户的历史偏好;此外,对资源主题模型进行资源相似性分析,从中获取用户的当前偏好。利用基于资源主题的内容推荐方法,结合用户的历史偏好和当前偏好,从而有效解决个性化信息推荐过程中用户“冷启动”的问题。
2)通过对目标用户的历史行为信息进行深度挖掘,根据基于用户行为的协同过滤推荐方法形成用户偏好模型,同时进行用户相似性计算,找出相似用户群,从中获取用户的潜在偏好。利用基于用户行为的协同过滤推荐方法,结合用户的潜在偏好,从而有效解决个性化信息推荐过程中数据稀疏的问题。
3)将目标用户的社会网络关系中的社会化行为及其所产生的社会关系网络引入信息推荐之中,根据基于用户关系的社会化推荐方法,对用户群、资源群和标签群进行深度挖掘,找出相应的用户子群和资源子群,从中获取用户的潜在偏好。利用基于用户关系的社会化推荐方法,结合用户的潜在偏好,从而有效解决个性化信息推荐过程中数据稀疏的问题。
4)结合用户的历史偏好、当前偏好以及潜在偏好,基于效用知识理论进行用户偏好的融合与优化,在以用户心理认知为基础、用户所处情境为条件以及信息发布时间与当前之间的差值小于某个阈值、在特定空间范围之内等优化因素的作用下,形成推荐资源列表并且对目标用户开展个性化信息推荐,从而有效解决个性化信息推荐过程中用户偏好漂移的问题,最终实现更加精准的个性化信息推荐。
4结语
鉴于当前关于社会化标注系统中个性化信息推荐过程中所存在的主要问题:即用户“冷启动”问题、数据稀疏性问题以及用户偏好漂移问题,本文深入探讨了社会标注系统中个性化信息推荐多维度融合与优化模型研究的总体框架并且构建了社会标注系统中个性化信息推荐多维度融合与优化模型。
利用本文所提出的社会化标注系统中个性化信息推荐多维度融合与优化模型,能够有效解决个性化信息推荐过程中所存在的问题,不仅在一定程度上丰富了个性化信息推荐的理论体系,而且也将在一定程度上拓展了个性化信息推荐的方法,从而实现在大数据环境下,为用户提供更加精准的个性化信息,为信息资源的有效开发与利用提供借鉴意义。
