项目特色视角下的我国图书情报领域知识聚合研究进展
2019-02-25肖璐孙建军
肖璐 孙建军

摘要:[目的/意义]目前已有多个国家项目围绕知识聚合开展了一系列深入研究。基于各项目已发表论文.以项目为粒度系统化地归纳已有知识聚合研究进展,不仅可以揭示国内主要项目团队的研究特色,还能归纳出知识聚合在研究开展层面上的一般共性。[方法/过程]本文对2011年以来我国图书情报领域涉及知识聚合的国家项目所发的多篇论文进行了比较分析,归纳出9个国家项目在概念关联(含领域本体)、关联数据、分众分类、用户、社会网络分析、文献计量6种视角下的特色。[结果/结论]从研究共性上看,知识聚合的资源、方法及其所依据的知识关联均呈多维化发展,知识聚合所依据的知识关联向领域化与细粒度化发展。
关键词:知识聚合;项目分析;图书情报学;研究视角;研究进展
DOl:10.3969/j.issn.1008-0821.2019.01.004
[中图分类号]G254 [文献标识码]A [文章编号]1008-0821(2019)01-0029-08
网络信息技术的发展,促进了资源的增长与流动,但同时加剧了资源的“碎片化”利用问题,严重制约了用户获取与利用资源的效率。知识聚合旨在以资源内外部特征的语义揭示为基础,充分挖掘资源内部知识单元的关联,从而重新组织资源使之符合用户认知习惯与知识利用规律。在当前网络环境下,知识聚合是解决资源利用问题的重要方法。
知识聚合是图书情报领域(下文称“图情”)的核心问题,已连续多年有国家级科研项目围绕知识聚合开展,其中不乏重大、重点级项目。尽管目前已有不少学者对图情领域知识聚合相关研究进行梳理,但对于项目团队粒度的研究特色揭示尚未有人开展。实际上,以项目为粒度进行分析,更有助于从整体层面上厘清我国当前图情领域知识聚合研究特点,探析领域内重要研究团队在研究思路和问题解决上的特色,由此与已有综述研究所侧重的微观分析形成互补。基于项目特色这一新视角,本文以国家自然科学基金(下文称“自科”)与国家社会科学基金(下文称“社科”)项目为对象,以项目已发表论文为基础,对其研究特色进行梳理和分析,以期明晰该领域国内研究现状与特点。
1知识聚合国家级项目统计及其研究视角归纳
国家自科与社科基金项目代表国内高水平研究,对其中相关项目统计分析可初步探析知识聚合在图情领域受关注程度及主要研究方向;对其已发论文進行反推分析,则可归纳各项目的研究视角,进而作为厘清我国知识聚合研究主要模式与特点的基础。
1.1知识聚合国家项目统计
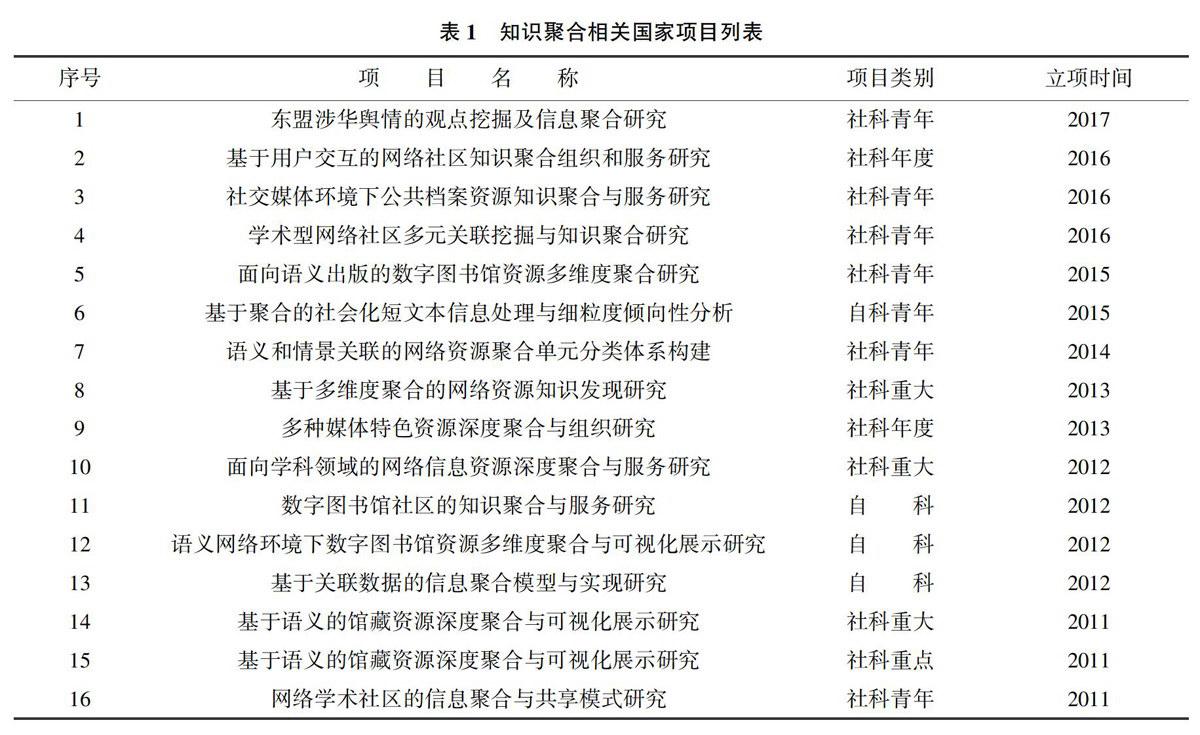
综合利用国家社科基金项目数据库与科学基金网络信息系统,查询国家社科与自科项目题目中包含“聚合”+“知识”、“聚合”+“资源”、“聚合”+“信息”的项目,考虑自科项目查询系统特点,检索类目包括“信息资源管理”、“图书情报档案管理”、“科学计量学与科技评价”、“信息系统与管理”、“信息系统及其管理”、“知识管理”、“数据挖掘与商务分析”,得到如表1所示的结果。根据表1可知,自2011年,每年都有关于知识聚合的国家级项目立项,共16个,包括3个社科重大、1个社科重点、2个社科年度、6个社科青年、3个自科与1个自科青年。
1.2知识聚合国家项目研究视角归纳
知识聚合的开展需要一定的聚合依据,例如用户关系、资源语义关联等。已有研究项目的聚合依据存在差异,即使采用同类聚合依据的不同项目之间,其关注的侧重点也可能不一样。因此可将项目研究中知识聚合开展的依据作为探析项目特色的研究视角。以研究视角为切入点,对项目进行归纳统计,有助厘清领域研究脉络,发现各研究项目的特色和一般共性。对表1所列项目发表的论文进行归纳,可得到表2所示结果。由于论文发表具有滞后性,这里仅对2014年之前立项项目的研究视角分析。此外,论文包含多个项目时,将论文作者与项目负责人匹配,计入最为匹配项目的成果。
2知识聚合国家项目的研究特色视角分析
利用中国知网与万方数据库检索表2中9个项目所发表论文,按照6个主要研究视角进行详细分析,以梳理知识聚合研究现状、明晰相关研究的重点与趋势。
2.1基于概念关联(含领域本体)视角的知识聚合研究
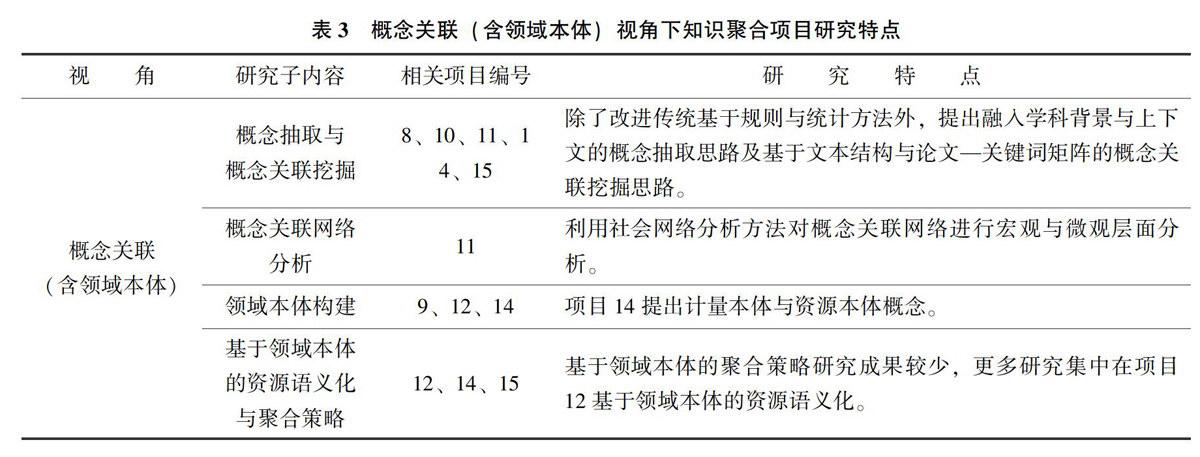
概念关联可从不同角度表征知识语义关系.为知识语义聚合提供背景知识,辅助资源语义化描述、语义相似度计算、潜在关联挖掘等。相关项目研究主要集中在:概念抽取与概念关联挖掘;概念关联网络分析;领域本体构建:基于领域本体的资源语义化与聚合策略设计。具体如表3所示。
1)概念抽取与概念关联挖掘。概念抽取方面,项目8中夏立新等改进了传统基于形式概念分析与描述逻辑的概念提取方法。项目11中胡昌平等采用定量方法论证共词分析中仅利用词频抽取的关键词难以全面表征领域知识。基于此,胡昌平等与陈果等考虑将分析领域融入更大背景学科中,分别提出采用词语贡献度与领域度、热度指标抽取特征。项目10中蒋婷等综合利用语言学与统计学方法,先利用语言学知识挖掘语术词性组合模板,并采用支持向量回归机构建术语概率预测模型。项目14中余凡等基于概念相关性、上下文与领域特性设计三层递进概念筛选流程,从文本与叙词表中提取领域概念。颜端武等提出利用N-gram复合分词抽取领域概念。
概念关联挖掘方面,项目10中王昊等采用形式概念分析抽取术语层次关系。蒋婷等根据文献结构特点挖掘概念非等级关系,并且设计包含术语类型提取、等级关系概念对识别等步骤在内的本体概念等级关系抽取方法。项目15中夏立薪等利用叙词表改进词间关联度计算算法。项目14中余凡等分别采用改进的相似度计算方法与自定义语法规则、改进关联规则进行文本等级关系与非等级关系抽取。
2)概念关联网络分析。项目11中陈果等以“数字图书馆”、“信息服务”与“知识管理”3个领域为例,分析科研领域关键词网络的整体结构与节点特征。胡昌平等利用社会网络分析中的K-core值对知识网络进行层次划分,实现知识网络微观层次分析。
3)领域本体构建。领域本体构建研究开展较早,资源聚合项目中较少直接涉及。但针对馆藏资源语义化与聚合,项目14的学者提出计量本体与资源本体概念,解决领域本体仅涉及某一领域内概念,无法满足馆藏资源多学科聚合需求。除此之外,张玉峰等利用本体工程与叙词表技术,复用已有本体,构建软件企业领域本体。项目12中毕强等利用维基百科中类别信息进行计算机科学的领域本体构建。项目9中张晗等以图书馆服务性资源为对象构建服务本体。
4)基于领域本体的资源语义化与聚合策略。资源语义化方面,项目12中徐坤等利用本体对科学数据进行语义化描述与组织,提高数据的机器可读与可理解性。鲍玉来等利用领域本体对分散、异构的开放存取资源进行语义集成检索。
聚合策略方面,项目12中毕强等、14中何超等与项目15中李劲等分别基于领域本体与集成本体开展了馆藏资源深度语义聚合研究。
2.2基于关联数据视角的知识聚合研究
由于关联数据采用RDF对资源本身及其关联进行描述,在一定程度上实现资源及其关联的语义化,有学者认为可将关联数据看作是高度规范的“本体”。相关项目研究主要集中在:关联数据创建、发布与本体映射;基于关联数据的资源聚合策略。具体如表4所示:
1)关联数据创建、发布与本体映射。传统粗粒度对象关联数据创建与发布研究较为成熟,资源聚合项目主要针对细粒度对象开展。项目15中王忠义等分别对数字图书中层与深层关联数据创建与发布开展分析,前者以目录数据为对象,综合利用主题词映射、文本匹配等技术进行资源结构化表示与关联挖掘;后者基于分布式人类计算构建对应架构与平台,促进不同地域专家协同工作。此外,针对数据集关联数据创建主要考虑数据集之间关联而忽略数据集内部关联,王忠义等提出利用推导传递法挖掘内部关联,该方法对于多类型关联挖掘有较高适用性。项目8中夏立新等利用BIBFRAME对科技报告进行关联数据化处理。
基于关联数据的数据集常利用本体进行数据描述,导致数据集之间异构严重,关联表征受到影响,项目13中潘有能等考虑采用本体映射技术解决该问题,提出以WordNet为外部知识库辅助计算概念相似度,并通过设定阈值完成概念到本体的映射。
2)基于关联数据的资源聚合策略。项目12中牟冬梅等总结关联数据在数字资源多维度、多层次及深度聚合上的优势,提出包含系统内外资源、多粒度资源等在内的资源聚合策略。项目8中夏立新等将关联数据集抽象为分析单元,构建对应网络,采用复杂网络理论分析其网络结构以提高关联数据利用效率。项目10中孙建军等在对关联数据应用于学科网络资源深度聚合可行性分析基础上,提出具体聚合框架,设计关联数据发布流程。项目13中丁楠等基于关联数据构建了包含数据层、聚合层与应用层在内的政府信息聚合模型,以美国政府关联数据集为基础进行验证实验。
2.3基于分众分类视角的知识聚合研究
分众分类是一种以用户为中心的分类方法,对数量巨大、碎片化程度高的网络资源有较高适用性,是网络资源组织与聚合研究中常用数据源。标签是分众分类重要元素,为资源语义描述与关联挖掘提供数据基础,相关项目大多以其为研究对象,主要包括:标签语义关联研究;基于标签网络的研究;基于标签的资源聚合研究。具体如表5所示:
1)标签语义关联研究。项目12中黄微等利用共现原理设计关联标签语义距离计算算法,通過逐层统计目标标签与关联标签共现关系,定量衡量标签语义关联。毕强等将关联标签思想引入标签云,通过对用户标签网络定量分析,挖掘网络子群,构建具有表征语义关联能力的标签云。项目15中程秀峰等综合利用标签与社会网络分析技术改进计算舞蹈类非物质文化遗产资源关系强度,挖掘资源潜在关联。
2)基于标签网络的研究。项目12中滕广青等利用复杂网络中心性指标研究用户标签网络紧密性。项目15中夏立新等通过对非遗图片关联标签与共标签网络中心性与群聚性分析,挖掘资源主题特征。
3)基于标签的资源聚合研究。项目12中毕强等综合运用标签云与社会网络分析对社会化标注系统进行资源聚合研究,并引入本体与主题词表描述标签语义与层级关联。
2.4基于用户视角的知识聚合研究
用户视角主要用于网络社区资源,通过对用户行为与关系分析,获取知识认知与利用规律,实现知识利用角度的资源聚合。由于加入用户因素,该类聚合有助于资源潜在关联挖掘。相关项目研究主要集中在:用户行为与关系研究;知识服务与共享研究。具体如表6所示:
1)用户行为与关系研究。项目11中胡昌平等利用结构方程模型对高校图书馆信息共享空间的用户交互学习行为与虚拟知识社区中用户关系对知识共享行为的影响进行分析,前者运用了扩展技术接受模型,后者构建了包含个人、情境、知识及成员行为4个维度的影响因素模型。林鑫等分析用户认知对标签使用的影响,实证得出认知难度与认知风格都会对标签使用行为产生显著影响。胡潜等对比社会化标注系统中基于用户标签与基于用户行为两种兴趣建模方式,认为基于行为的传统兴趣建模效果优于基于标签的建模。
2)知识服务与共享研究。知识服务方面,相关研究主要集中在用户满意度与使用意向上。除此之外,项目11中王鹏程等将社交网络服务融入图书馆信息服务平台中,构建包含图书评价与学科建设交流模块在内的系统架构。胡昌平等基于技术接受模型与“感知交互性”设计了可用于社会化推荐服务的用户体验模型。
知识共享方面,项目16中张敏等与程莉等分别对微信中知识共享行为与威客中知识共享模式进行分析。蔡小筱等从个人、人际与社区人手综合分析影响虚拟学术社区知识共享的各种因素。
2.5基于社会网络分析视角的知识聚合研究
社会网络分析以社会网络中的结点及其关系为研究对象,通过定量分析,探析网络整体结构、挖掘关键结点、发现子群网络。构建不同粒度资源网络是资源聚合基础,重点关注网络关联结构的社会网络分析方法则为基于资源网络的多维度语义聚合研究提供新视角。具体如表7所示:
社会网络分析直接应用于资源聚合研究时间较晚,涉及该视角的研究较少。首先,项目12中邓君等以数字资源聚合领域的关键词共现网络为基础对社会网络分析工具Ucinet与Gephi对比分析,认为Ucinet在多重关系的大量数据上适用性更高,Gephi在动态数据处理方面性能更强。其次,姜毓锋等以专利说明书中的“发明名称”为数据源挖掘专利之间关联,构建专利关联网络,利用社会网络分析中的网络结构、节点度及结构洞分析对其进行聚合研究。再者,黄微等通过用户显性知识挖掘用户关系,利用社会网络分析方法挖掘用户子群与核心用户,完成用户隐性知识发现与推送。项目8中易明等认为网络分析包含网络结构计量分析与网络动态演化分析,通过对社会化标签系统中社会网络进行内生与外生演化动力分析,构建对应网络知识推送网络演化模型。夏立新等基于用户、资源的异质网络关联,综合考虑情感分析等其他方法,进行用户与资源的多维度推荐研究。
2.6基于文献计量视角的知识聚合研究
由于文献计量主要以文献内外部特征为分析对象,因此该方法主要运用于馆藏资源聚合研究。该视角研究主要由项目14的研究团队采用。
共现与耦合是该视角资源聚合最常考虑的两种关联。首先,邱均平等分别利用作者共被引及文献作者、关键词之间单一与交叉共现关系开展馆藏资源深度聚合研究,设计具体聚合流程与模型。瞿辉等利用共词分析技术进行馆藏资源聚合,引入主题图来提高传统共词分析的语义化程度。其次,邱均平等与赵蓉英等基于耦合关联进行资源聚合研究。邱均平等综合考虑共现与耦合两种关联构建包含数据层、分析层、聚合层与表示层在内的针对8种馆藏资源的聚合模型。
值得一提的是,除了上述6个主要研究视角,学者还尝试利用其它视角开展聚合研究,由于这些视角下的研究论文尚未形成体系,这里不再详述。
3知识聚合研究的共性特点分析
分析表1中所列项目研究成果,总结当前知识聚合共性特点,主要包括:
3.1知识聚合向多维度方向发展
网络环境下资源生产方式与交流渠道增加,为深入知识服务提供了数据保障,但传统单一维度的聚合方式无法有效将多源数据转化成可为用户直接利用的知识,影响知识服务效果。多维度聚合以用户需求为基础,考虑资源类别、关联类型、聚合方法之间差异,从不同维度聚合分析,综合多维度分析结果,满足新环境下知识服务需求。经总结笔者将其归为3类:1)聚合资源的多维化。聚合资源除了包括文本数据外还包括网页链接、用户行为等非本文数据,综合挖掘可提高知识聚合的广度。2)聚合方法的多维化。概念关联、关联数据、社会网络分析等聚合方法有各自优点与缺点,综合运用优势互补,可提高知识聚合的深度。3)聚合所依据知識关联的多维化。类型多样的知识关联从不同角度表征资源语义关系,例如标签共现关联与领域本体等级关联分别从用户角度与客观角度表征知识关联。融合多种关联构建更全面知识关联网络,可提高知识聚合的语义程度。
3.2知识聚合的语义关联向领域化与细粒度化发展
基于资源内在关联的语义聚合解决了传统关注资源内外部特征,无法从知识关联层面聚合资源的不足。构建关系明晰的概念关联网络是知识语义聚合基础,人工构建工程浩大、费时费力,利用语法规则或机器学习的半自动化构建成为研究主流。设计适用于多数领域的概念关联网络自动或半自动构建方法是图情领域研究热点。但随着研究深入发现,不同领域之间资源结构差异较大,根据领域特点设计针对性关联网络构建方案更为可靠,与之对应相关项目中逐渐出现融入学科背景的概念与概念关联抽取方法,取得较好效果。
已有项目的开展中.概念的共现关系是挖掘概念关联的重要依据,通过统计共现次数可定量计算概念关联强度,但仅根据共现关系无法获取概念关联类型,基于此构建的关联网络无法真实反映客观世界知识关联。有学者提出将具有明确关联类型的概念网络(如本体)与概念共现网络相融合的方法,将共现网络转化为有明确关联类型表征能力的知识网络,支持知识细粒度语义聚合。
4小结
网络环境下资源数量迅速增长,知识聚合研究重要性更加突显。近年来学者尝试了多种聚合方法,研究成果较为零散,有必要对其进行梳理与总结。国家自科与社科项目代表国内高水平研究,目前已连续多年均有国家级科研项目围绕知识聚合开展。本文首先对2011年以来我国图情领域与知识聚合相关的国家项目进行统计分析,总结出6个项目特色视角;其次重点分析2014之前立项的9个国家项目,根据其所发表论文,分析各个项目研究视角,探析主要项目团队的研究特色;然后以知识聚合的特色视角为维度,对9个国家项目的多篇论文进行归纳分析,明晰6个特色视角下知识聚合研究现状;最后总结已有知识聚合研究的共性特征,认为聚合内容、方法及依据知识关联呈多维化,知识聚合所依据的知识关联呈领域化与细粒度化。
