基于在线评论的直觉模糊TOPSIS商品购买决策方法
2019-02-25王梦娇张振宇
林 杰 王梦娇 张振宇
(同济大学 经济与管理学院,上海 200092)
0 引言
本文提出一种商品排序方法,首先运用Apriori算法对商品特征进行提取,并通过情感分析方法,建立商品各特征的情感词典并计算每条评论中商品各特征的情感倾向,再根据商品特征情感倾向建立直觉模糊决策矩阵,运用直觉模糊TOPSIS方法对备选商品进行排序。
1 基于情感分析和直觉模糊TOPSIS的购买倾向算法
1.1 问题描述及解决框架
假设消费者想要购买手机,并且通过初步调查,确定了几种可接受的商品,即备选商品。但是,由于时间和专业知识有限,消费者无法有效地得到需要的评论信息,于是在几种备选商品中摇摆不定,无法做出最终选择。本文从该问题出发,设计算法对备选商品进行排名,为消费者选择最满意的商品,其解决框架如图1所示。
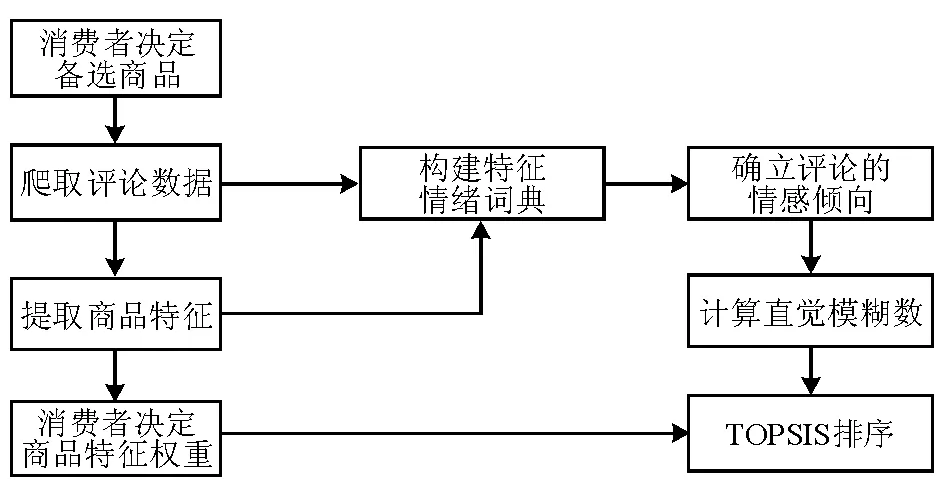
图1 在线评论商品排序问题解决框架
以下符号用于表示问题中的集合和变量,将在本文中使用。
A={A1,A2,…,An}:n个备选商品的集合,其中Ai表示第i个备选商品,i=1,2,…,n,集合A可由消费者决定。
F={f1,f2,…,fm}:m个特征的集合,从在线评论中挖掘的消费者所重点关注的商品特征,其中fj表示第j个特征,j=1,2,…,m。

Q={q1,q2,…,qn}:备选商品的在线评论数量,其中,qi表示关于备选商品Ai的在线评论数量,i=1,2,…,n。

本文设计的问题是如何根据在线评论Dik和特征权重ωj,对备选商品A1,A2,…,An进行排名,i=1,2,…,n,j=1,2,…,m,k=1,2,…,qi。
1.2 基于在线评论信息挖掘的商品特征
为了从在线评论Dik中提取出消费者所重点关注的关于备选商品的商品特征,这里根据文献,给出一种基于在线评论信息挖掘的商品特征确定方法,具体过程描述如下:
首先,对评论中涉及的在线评论信息进行分词,并对分词后的在线评论信息进行词性标注。为准确合理起见,这里运用中国科学院计算技术研究所开发的分析系统( ICTCLAS: Institute of Computing Technology, Chinese Lexical Analysis System) 进行在线评论信息的分词处理,词性标注采用二级标注方法。
其次,利用词性标注后的评论来创建关联规则事务文件,并基于关联规则Apriori算法来查找频繁项集。这里参照同类研究文献,最小支持度取值为1%,不考虑3项以上的频繁项。
在此基础上,将找出的频繁项集按照文献定义的邻近规则和独立支持度分别进行剪枝和修正,形成备选商品特征集合FTF。
然后,基于FTF分别构建包含常见中文频繁项名词却非商品特征的集合FFF(如一些常见商品品牌、口语化名词及人称名称等)和包含单字名词的备选特征的集合FSF,并将FTF过滤形成最终的商品特征集合F,即F=FTF-FFF-FSF。
1.3 基于商品特征构建积极、消极情感词典
通常情况下,不同特征的正向或负向情感词典是不同的。一个词可以同时属于一个特征的正向情感词典和另一个特征的负向情感词典。例如,“高”属于特征“像素”的正向情感词典和特征“价格”的负向情感词典。因此,有必要分别为每个特征建立正向和负向情感词典。
首先,依据1.2中词性标注后的评论集,创建评论中针对特征fj的关联规则事物文件,并基于关联规则Apriori算法来查找其中的频繁项集,形成特征fj的情感标注集合。
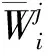
(1)
(2)
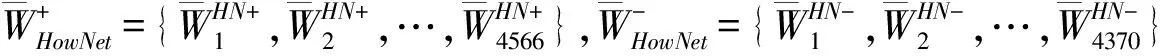
(3)

1.4 确定特征的情感倾向
本节采用一种算法计算每个评论的每个特征的正向、中性或负向情感倾向。该算法的主要思想如下:句子的情感倾向取决于句子中的情感词,如果句子中正向情感词的数量大于负向情感词,则句子的情感倾向被认为是正向的;如果句子中负向情感词的数量大于正向情感词,则句子的情感倾向被认为是负向的;如果句子中没有情感词或者正向和负向的情感词数量相同,那么句子的情感倾向被认为是中性的;如果句子中有否定词,则句子的情感倾向将被颠倒,具体操作如下。
1.5 基于直觉模糊数和TOPSIS对备选商品进行排序
1.5.1直觉模糊数的计算
直觉模糊集理论是处理模糊性和犹豫的有用工具,直觉模糊数可以同时反映评论的支持、犹豫和反对程度。基于直觉模糊集理论,备选商品在线评论的情感倾向可以通过直觉模糊数简单而完整地表示。

(4)

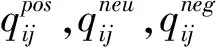
(5)
(6)
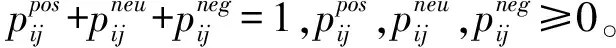

1.5.2TOPSIS方法
使用TOPSIS方法对备选商品进行排序,其基本思想如下:在确定各属性指标权重的基础上,归一化原始数据矩阵,分别计算备选商品与最优方案和最劣方案间的距离,获得各备选商品与最优方案的相对接近程度,作为评价优劣的依据。具体算法步骤如下:
①根据备选商品的整体模糊数构造决策矩阵A=(aij)n×m,其中aij=Yij,表示备选商品Ai的特征fj的直觉模糊数,n为备选商品个数,m为商品特征数。
②为了消除不同属性间的量纲效应,使每个属性特征都具有同等的表现力,首先对原始数据进行标准化处理。
(7)

(8)
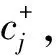
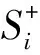
(9)
⑥计算各方案的贴近度(综合评价指数),并按照由大到小排列。
(10)
2 数据实验
2.1 数据源说明
本文选取了京东商城五款手机的在线评论作为数据进行实验。这五款手机分别是iPhone X、华为P10、美图T8、vivo X9、OPPO R11S。利用爬虫软件共爬取评论5000条(每款手机1000条),对评论进行处理,去除重复评论和垃圾评论,再对网络评论数据集进行降噪处理:将重复两次或者两次以上的商品评论语句全部删除;剔除评论字数小于5个的商品评论;删除含有大量特殊字符、表情的商品评论数据。最终,从获得的数据集中选取2000条评论(每款手机各400条)。
2.2 实验算法设计
步骤① 运用ICTCLA工具对评论数据进行分词处理和词性标注;
步骤② 创建关联规则事务文件,基于关联规则Apriori算法找出频繁项集,并对其进行剪枝和修正,形成备选商品特征集合;
步骤③ 由消费者给出关于商品特征的权重矩阵W;
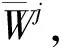

步骤⑥ 构建每条评论、每个特征的情感倾向集合;
步骤⑦ 根据评论点赞数,计算每条评论的权重,确定每个备选手机的直觉模糊数;
步骤⑧ 构建直觉模糊决策矩阵,运用TOPSIS法对备选手机进行排序。
2.3 实验结果及说明
依据2.2节中设计的实验算法,确定关于备选手机的特征及其对应的情感词典,如表1 所示。
再由消费者根据提取的特征和自己的喜好来确定商品特征权重。假设消费者针对六个特征(外观、屏幕、拍照、电池、价格和系统)的权重分别为W=(0.2,0.1,0.1,0.1,0.3,0.2)T。
计算可得由备选手机的直觉模糊数组成的TOPSIS决策矩阵,如表2所示。

表1 特征情感词典部分展示

表2 直觉模糊决策矩阵A
根据TOPSIS算法,将手机整体直接模糊数进行无量纲处理,结合特征权重,计算加权规范矩阵,如表3所示。
所有备选手机特征的理想点如表4所示。

表3 加权规范矩阵C
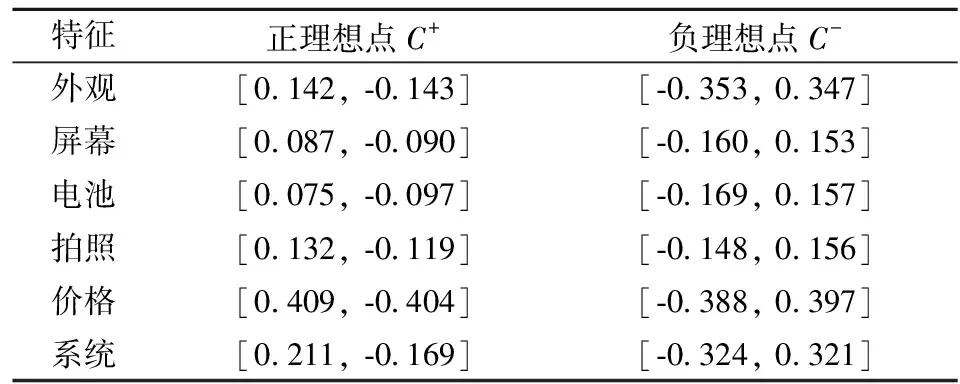
表4 TOPSIS算法的正、负理想点
再根据TOPSIS算法,求得每个手机的贴近度Ci,如表5所示。
由表5可得,在消费者给定商品特征权重W=(0.2,0.1,0.1,0.1,0.3,0.2)T的情况下,备选手机排序为华为P10>IPHONEX>OPPO R11S>vivo X9>美图T8, 即优先价格、系统性能和外观,最优的选择是华为P10。本方法建议消费者购买华为P10。

表5 商品贴近度
根据对华为P10的评论也可以看出,多数评论都注明该手机系统流畅、性价比高,符合实验结果。而对于iPhone X的评价大多比较苛刻,这可能是因为iPhone X的价格较高,用户对其要求更高,导致其排名靠后。
3 结束语
本文提出了一种关于商品排序的新的分析方法。该方法解决问题遵循的思路如下:针对某一类别商品,首先由消费者根据个人偏好给定备选商品集,通过爬虫技术得到备选商品的评论集合;再通过对评论信息进行信息挖掘和情感分析,确定备选商品的重要特征集合,构建关于各商品特征的正负情感词典,计算评论的情感倾向,得到商品直觉模糊数;最后结合消费者给出的商品特征权重,使用TOPSIS法确定备选商品的排序,得到最佳选择,帮助消费者做出购买决策。
本文所提出的方法按照商品特征对在线评论进行提取,可以直观展示每个商品特征的得分即排序情况,直接、快速地满足了消费者的需求,并且在消费者给出商品特征权重的基础上,给出了商品整体的排序结果。该方法充分考虑了消费者的主观需求和消费者对于各商品特征的不同程度情感(正向、中性、负向),利用直觉模糊数全面反映了消费者的不同情感向量,比以往研究更细,弥补了仅考虑消费者极性情感的不足。除此之外,本文还考虑了消费者对于特征的偏好情况,更符号消费者的实际购买需求。
总的来说,本文结合直觉模糊理论中的隶属度、非隶属度和犹豫度,提供了一种解决商品排序问题的有效思路。本文提出的方法具有可操作性和实际应用价值,为解决当前大数据时代普遍存在的使用在线评论信息的商品购买决策问题提供了一种新的决策技术或新途径。
