基于多分类模型加权投票法的人脸微笑检测
2019-02-25冯泽安
冯泽安,王 鹏
(西安工业大学 电子信息工程学院,陕西 西安 710021)
0 引 言
对无约束面部图像的微笑检测是一个具有挑战性的问题。作为最具信息含义的表达之一[1],微笑表达了一些基本情绪,如快乐和满意度,于是在不同领域有多种应用,如人类行为分析[2]、照片选择[3]、患者监护[4]等。近年来,局部二进制模式[5](LBP)常用于微笑检测,在Viola-Jones级联分类器的微笑检测器[6]的分类准确率可达到96.1%。虽然分类准确性很高,但对所采用的图像样本要求同样非常高,比如必须使用面部正面照。还有使用AdaBoost来选择和组合弱分类器[7],并在GENKI-4K图像数据集上达到了88%的微笑检测率。一般用于微笑检测的面部信息[8]可以分为两大类:(I)几何信息和(II)纹理(或外观)信息。几何信息一般包含面部特征或头骨的形状,而纹理信息主要考虑面部图像像素强度或由像素构成的图案(像素图)。但在面部微笑检测的文献中,通常将几何信息与纹理信息相结合,而不是单独使用。最新的微笑检测算法是基于卷积神经网络(CNN)的算法,该算法可以对低级特征组成的高级特征的层次表示[9]进行学习,CNN实现的高分类精度使这种算法成为微笑检测领域中的先进技术,但需要更多的样本来训练网络。例如,对一个由4个卷积层和1个完全连接层组成的CNN架构[10]进行微笑检测,其准确率达到94.6%,这比先前在GENKI-4K数据集上使用的任何检测方法所获得的准确度都要高。文中应用了一种基于多分类模型加权投票的方法来进行人脸微笑检测。
1 多分类模型加权投票法
多分类模型加权投票法主要由3部分组成,即预处理,四种分类模型和最后加权投票,其总体结构如图1所示。其中Ri(i=1,2,3,4)分别表示各模型的分类结果。
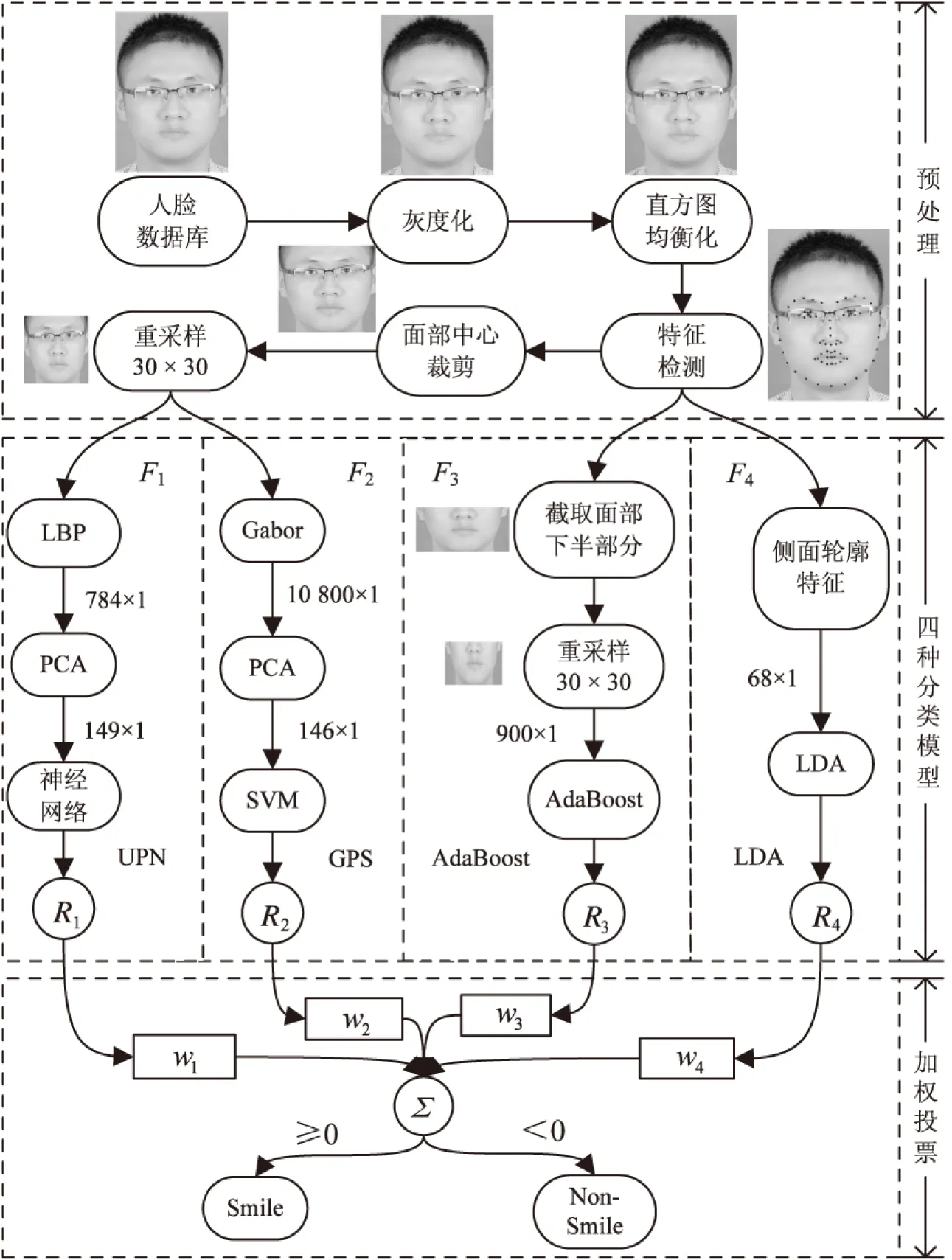
图1 总体结构
1.1 预处理
预处理阶段包括对面部图像进行灰度缩放和直方图均衡化,特征检测,并裁剪出面部的中心,最后按照30×30的均匀网格(1格等于1像素点)对其进行重采样。
(1)灰度和直方图均衡化:在图像处理算法中,为了加快处理速度(可减小后期的计算量),需将彩色图像灰度化,但为了获得更好的对比度[11],需将灰度图像进行直方图均衡化。这在此次检测中很重要,因为该方法可获得更多的面部图像细节。
(2)特征检测:特征检测方法ASM[12](active shape model)或CLNF[13](constrained local neural field)在人脸识别中应用广泛,文中选择CLNF方法;一张完整的面部图片上总共68个特征点(17个面部侧轮廓点,嘴唇有20个标记点,每只眼睛上6个点,鼻子9个点和每个眉毛上5个点)。图2为在几个面部样本上检测到的面部特征点。

图2 面部样本上的特征点
(3)截取面部中心图和重采样:文中检测的图像仅考虑脸部中心部位,以防止额外的信息被利用,从而影响检测结果。因此,得对图像进行裁剪。现今,对人脸进行检测和分割的方法有很多,例如Viola-Jones人脸检测器[14];同时还有利用肤色来对图像进行分割而得到脸部中心图。文中方法是根据面部侧面特征点形成的轮廓对人脸进行裁剪。
1.2 分类模型F1(UPN)
分类模型F1包括Uniform LBP,PCA和神经网络。
(1)Uniform LBP模式:LBP(local binary pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子[15],具有旋转不变性和灰度不变性等显著的优点,广泛用于图像局部纹理特征提取。其基本思想为:在3×3的窗口(以像素点为基准)内,以窗口中心像素为阈值,将相邻的8个像素的灰度值与其进行比较,若周围像素值大于中心像素值,则该像素点的位置被标记为1,否则为0。从而,3×3邻域内的8个点经比较可产生8位二进制数(通常转换为十进制数即LBP码,共256种),即得到该窗口中心像素点的LBP值,并用这个值来反映该区域的纹理信息。在像素3×3的邻域内,对于中心像素(强度为ic)和相邻的P个元素(强度为ip,p={0,1,…,P-1}),计算公式为:
(1)
其中,s(x)为符号函数,有:
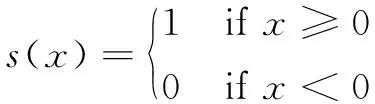
(2)
但由于图像的旋转会产生不同的LBP值,同时绝大多数LBP模式得到的二进制数大多只包含两次从1到0或从0到1的跳变,为了尽可能降低图像特征的维数,于是引入LBP的等价模式(Uniform LBP),计算方法为:
(3)
其中,U(LBP)表示二进制数从0到1或从1到0的跳变次数。
由于Uniform LBP比传统LBP效果更好[16];因此,在第一个分类模型中,使用Uniform LBP方法在30×30的面部图像上进行特征提取。
(2)主成分分析(principal components analysis,PCA):PCA是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用,顾名思义,就是找出数据里最主要的方面代替原始数据。由于图像数据一般都具有很高的维度,因此可以使用PCA进行特征提取和缩减。其降维方法为:
如果有m个面部样本,且每个训练样本i对应的LBPu被转换为一个向量x(i),n(n=28×28=784)维样本集D=(x(1),x(2),…,x(m))降维后为n'(n'=149)维样本集D'=(z(1),z(2),…,z(m)));样本的协方差矩阵为:
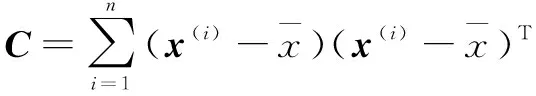
(4)
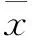
CPn'=λn'Pn'
(5)
其中,λn'为C的特征值。
取出最大的n'个特征值对应的特征向量(ω1,ω2,…,ωn'),将所有的特征向量标准化后,组成特征向量矩阵W;对样本集中的每一个样本x(i),转化为新的样本z(i)=WTx(i);最后得到输出样本集D'。于是n'个特征值对应的特征向量将原始样本转换到n'个特征向量构建的新空间中。在测试阶段,将转换后的LBPu投影到新的特征向量空间中,可以使图像的维度降得很低。
(3)反向传播神经网络:卷积神经网络广泛用于人脸识别,并且检测率非常高。但在该模型中,样本图像经PCA降维后输出为149×1的灰度值,因此,使用普通的反向传播神经网络即可完成分类。如图3所示,该神经网络由输入层149个神经元,隐藏层10个神经元和1个输出神经元所构成。微笑样本图像输出标签用1表示,而非微笑用-1表示,其他三种分类模型的标签表示方法与此一致。
1.3 分类模型F2(GPS)
分类模型F2由Gabor滤波,PCA和SVM组成。
(1)Gabor小波变换:对预处理后的图像进行Gabor小波变换,由于Gabor函数形成的二维Gabor小波变换具有在空间域和频率域同时取得最优局部化的特性,能充分对物体纹理特征进行提取;其属于加窗傅里叶变换,是Gabor理论和小波理论结合的产物。受其启发,Gabor小波变换在此模型中以4种尺度(7,12,17和21)同时从六个方向(角度分别为0°,30°,60°,90°,120°和150°)对灰度图像进行变换。二维的Gabor小波变换[17]的计算公式为:
x'=xcosθ+ysinθ
(7)
其中,λ,θ,φ和σ分别为波长(比例),方向,相位偏移和高斯标准差。

图3 反向传播神经网络
在该分类模型中,Gabor小波变换具有非常重要的作用。图4为对一个样本面部图像应用24个小波核卷积的结果;人脸的某些部分在特定的尺度和方向上呈现剧烈的变化趋势,通过Gabor小波变换之后,这些变化可以很直观地表现出来。

图4 图像卷积结果
(2)主成分分析:在进行Gabor滤波时使用了24个小波核,同时每个核的尺寸为30×30,因此,将滤波器结果连接起来并将其整合成一个矢量之后,该矢量维数将达到21 600(30×30×24);为了避免出现维度危机,与第一个模型中所述的一样,再次使用PCA进行降维。
(3)支持向量机(SVM):SVM基本模型为特征空间上间隔最大的线性分类器,即学习策略为间隔最大化,最终通过转化为一个凸二次优化问题的求解,或者是在高维空间中寻找一个合理的超平面将数据点分隔开来,其中涉及到非线性数据到高维的映射以达到数据线性可分的目的。在此模型中,经PCA降维后,其维数仍有146×m,属于高维空间。非线性SVM的决策函数[18]可以表示为:
(8)
其中,xi和xt分别表示训练和测试样本;b为偏差;αi为拉格朗日乘数;N为所有训练样本的总量;yi∈{+1,-1}为训练样本的标签。
支持向量机通过映射函数φ(x),将输入空间中的样本特征映射到高维特征空间,从而降低计算量;式8中K(x(i),x(t))为SVM的核函数,与映射函数的关系为K(x(i),x(t))=φ(x(i))φ(x(t))。在此模型中,选取径向基函数作为核函数:
K(x(i),x(t))=e-‖x(i)-x(t)‖2
(9)
1.4 分类模型F3(AdaBoost)
分类模型F3主要包括提取面部的下半部分,对裁剪后的图像进行重采样,然后使用AdaBoost进行分类。
(1)提取脸部的下半部分:脸部的下半部分[19],即从鼻尖到下巴,包含影响检测结果的关键信息。换言之,从纹理图案的平滑度或粗糙度的差异出发,仅脸部的下部就可用于微笑检测。该模型提取下半脸,鼻尖,下巴和两个侧面轮廓特征信息。
(2)重采样:为了减少数据样本维数和保持维数均衡,将提取的部分使用30×30均匀网格进行重采样。然后,将重采样后的数据重新调整为900×1维的矢量。
(3)AdaBoost:AdaBoost是一种迭代(集成学习)方法[20],既可以用于分类,也可以用于回归,其核心思想是针对不同的训练集训练同一个弱分类器,然后把在不同训练集上得到的弱分类器集合起来,构成一个最终的强分类器。该分类模型将用AdaBoost级联结构分类器(建立在弱分类器单层决策树之上)并对900×m维的样本进行二元分类,其流程为:
输入:样本集D=(x(1),x(2),…,x(m)),输出标签yi∈{-1,+1},弱分类器迭代次数K
过程:
2.fork=1,2,…,Kdo:
3:使用具有权重W(k)的样本集来训练数据,得到弱分类器Gk(x)
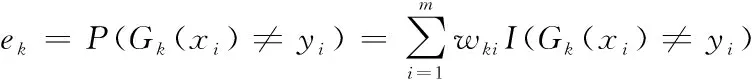
5:ifek>0.5 then break
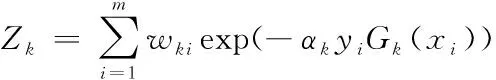
8:end for
1.5 分类模型F4(LDA)
分类模型F4直接使用线性判别分析(LDA)对面部的侧轮廓特征进行分类。
(1)侧面轮廓特征点:在预处理阶段已经对面部侧面轮廓特征进行了检测。而人类生物学[21]显示,人在微笑和非微笑时,面部的几何特征有着明显的差异,表现在脸部,眼睛,眉毛,下巴,眶上脊,颧骨,下颌骨,腭部,眼睛和鼻尖、眼睛和嘴唇中心之间的垂直距离,或者鼻子宽度,嘴唇宽度,脸部高度和脸部阴影的侧面轮廓。但是这些特征可能会受到外界因素的影响,如人的肥胖程度,同时面部侧面轮廓的上半部分可能会被头发覆盖,因此,在此模型中仅考虑从左耳到右耳的下侧轮廓。然后,将所有特征标记点的坐标整合成一个列向量送入分类器进行分类。
(2)线性判别分析:LDA(linear discriminant analysis)不但是一种监督学习的降维技术,同时也是一个强大的分类器[22],也就是说它的数据集的每个样本是有类别输出的。其思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。就是要将样本数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能接近,而不同类别的数据的类别中心之间的距离尽可能大。其二分类原理和流程为:
数据集D=(x(1),x(2),…,x(m)),其中任意样本x(i)为n(本模型中n=68)维向量,y(i)∈{-1,1};定义Nj(j=-1,1)为第j类样本的个数,Xj(j=-1,1)为第j类样本的集合,而μj(j=-1,1)为第j类样本的均值向量,定义∑j(j=-1,1)为第j类样本的协方差矩阵(严格说是缺少分母部分的协方差矩阵)。
μj的表达式为:
(10)
∑j的表达式为:
(11)
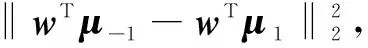
综上所述,最终的优化目标为:
(12)
一般定义类内散度矩阵Sw为:
(13)
同时定义类间散度矩阵为Sb:
Sb=(μ-1-μ1)(μ-1-μ1)T
(14)
然后优化目标重写为:
(15)
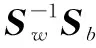
1.6 加权投票
加权投票是集成学习的一种方法,是一种很直观的方法,其给分类性能高的分类器赋予一个高的权值,投票结果往往能利用单分类模型间的互补功能来减少单个分类器的误差,提高预测性能和分类精度。其集成四个分类模型的加权投票流程[23]如下:
(1)计算每个分类模型的正确率:
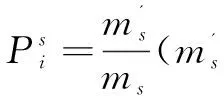
(16)
其中,i=1,2,3,4;s=Smile,Non-Smile。
(2)计算每个模型的权值wi为:
(17)
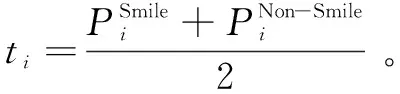
(3)将各模型得到的检测结果分别与所对应的权值wi相乘,得到sumi。
(4)将各结果的sumi相加,得到sum,然后将sum与阈值0相比,即根据式18得到最终的检测结果。
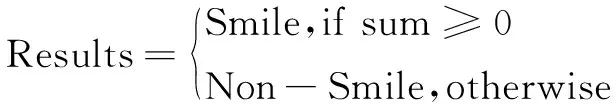
(18)
每个分类模型的权重可以认为是在一个训练子集上的检测率。换句话说,权重可以展现其相应模型的检测的准确度。加权投票步骤如图1所示。
2 实 验
2.1 实验数据
实验在GENKI-4K[24]人脸数据集上进行,该数据集中图片是在不同的成像条件下拍摄的,无论室内还是室外,姿势(大部分的头部的偏转,俯仰和滚动参数图像距离正面位置在20°以内),年龄,性别,或是否戴帽子或眼镜;而且所有图像都是手动标记。GENKI-4K分别包含的微笑和非微笑面部图像分别为2 162和1 838个。文中在数据集中随机选用了200张图片进行实验,100张微笑的,100张非微笑的。75%的图片用于训练,其余的用于后期测试验证。在训练和测试阶段,微笑与非微笑照片的比例一样。
2.2 结果分析
从表1可得四个分类模型对微笑,非微笑和整体的检测率,以及最终经过加权投票后的检测率。可以看出,表现最好的和最差的分别为模型F3和模型F1。此外,一些模型对微笑的检测率更好,一些对非微笑的检测率更为准确。最后表明不同模型的加权投票可以产生一个完全适用于微笑和非微笑检测的整体模型(见表1的最后一列,其中对微笑和非微笑的检测都非常好且非常接近)。对于GENKI-4K人脸数据集,基于加权投票的方法的整体识别率为95.8%。表2为文中所用方法与GENKI-4K数据集中的其他微笑检测方法进行比较的结果。
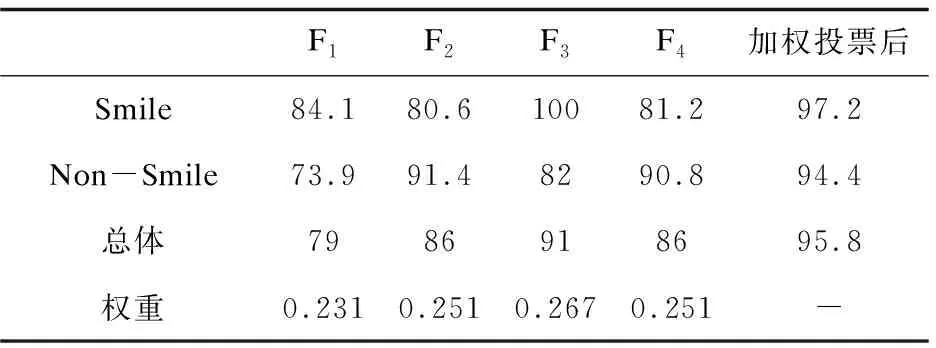
表1 微笑检测率 %
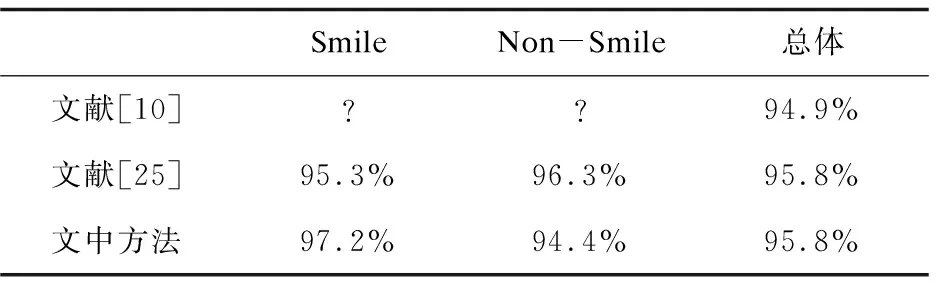
表2 比较结果
注:?表示没有相关的检测率。
3 结束语
应用了一种基于多分类模型加权投票的方法对面部微笑进行检测识别,这些分类模型分别受现今最流行的人脸识别或性别检测方法的启发;首先对面部图像进行预处理,使之规范化并增强其对比度,然后利用各分类模型优势对图像进行检测分类,最后对各模型的结果进行加权投票。
显而易见,该方法包含了不同的分类检测方法,即神经网络,SVM,AdaBoost和LDA,使总体的分类能力明显提高。此外,运用不同的特征提取方法,如LBP,Gabor,PCA,面部下半部和特征标记检测,把基本能用于微笑检测所需的重要特征都使用了。文中纹理和几何信息均被用于面部微笑检测。第一和第二种模型使用纹理信息,第三和第四种模型使用几何信息。利用这两种类型的信息以及不同的分类模型使得运用的方法具有很强的分类检测能力。
